
- 1【C语言】可变参数详解_c可变参数列表使用
- 22023年node.js最新版(18.15.0)详细安装教程(保姆级)_node最新版本
- 3网络各层协议_网络层协议
- 4SpringBoot实现自动配置(图解超详细)_springboot127个自动配置类
- 5给学生补充的markdown 编辑器_markdownpad要钱吗
- 6业务签署升级,君子签电子签章助推汽车融资租赁释放消费潜力
- 7python调用函数示例_Python 实现异步调用函数的示例讲解
- 8cesium图层管理_cesium 图层管理器
- 9Vue中级面试题汇总(二)
- 10Unity 问题 之 ScrollView ,LayoutGroup,ContentSizeFitter 一起使用时,动态变化时无法及时刷新更新适配界面的问题_unity content size fitter 高度不刷新
2022华为杯研究生数学建模竞赛E题思路解析_研究生数学建模e题
赞
踩
一、问题背景
沙漠化程度指数(SM)是从数学的范畴去界定沙漠化程度,采用一定的分级标准使得其与沙漠化程度相对应。把沙漠化程度划分为五类:非沙漠化、轻度沙漠化、中度沙漠化、重度沙漠化和极重度沙漠化,SM 采用 0~1 标度法。
沙漠化程度指数预测模型表达式[2]:
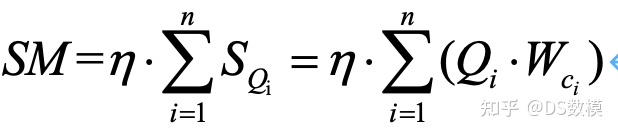
公式具体含义及其符号说明见文后扩展阅读。
土壤板结化与土壤有机物、土壤湿度和土壤的容重有关,目前还没有明确的定量表达式,其数学模型可定性描述为如下:
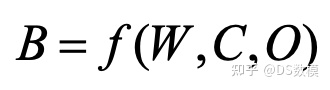
土壤湿度 越少,容重 越大,有机物含量 越低,土壤板结化程度 越严重。
土壤化学性质和物理性质是影响土壤肥力重要因素,土壤化学性质包括:土壤有机碳SOC、土壤无机碳SIC、土壤全碳STC、全N、土壤C/N比等;土壤物理性质包括:土壤湿度、土壤容重等。一般来说,在保持土壤化学性质等基本不变情况下,降水会增加土壤湿度,而土壤湿度增加会提高草场植被覆盖率,在良好的植被覆盖情况下可以适当提高放牧强度,在一定区域内,放牧强度越高意味着更多的放牧数量,在不考虑放牧补贴和价格波动情况下,更多放牧数量代表更高的放牧收益。
现代草地资源的经营应遵循可持续发展原则,在保证生态环境良性健康发展中寻求经济利益的最大化。美国著名生态经济学家赫尔曼·E·戴利给可持续发展的定义是:“可持续发展是经济规模增长没有超越生物环境承载能力的发展”。 其理念是“可持续发展的整个理念就是经济子系统的增长规模绝对不能超越生态系统可以永远持续或支撑的容纳范围”。在草原区域系统中,承载力是评价可持续发展的一种工具。在《远东英汉大辞典》中,承载力被定义为“某一自然环境所能容纳的生物数目(指最高限度)”。区域生态系统承载力和可持续发展是相辅相成的两个概念。
二、需解决问题:
请你根据附件数据以及收集有关草原数据(土壤容重、土壤PH等),由于历史原因,数据虽然并不充分,实际问题仍然需要解决。请通过数学建模完成下列问题:
问题1. 从机理分析的角度,建立不同放牧策略(放牧方式和放牧强度)对锡林郭勒草原土壤物理性质(主要是土壤湿度)和植被生物量影响的数学模型。
问题2. 请根据附件3土壤湿度数据、附件4土壤蒸发数据以及附件8中降水等数据,建立模型对保持目前放牧策略不变情况下对2022年、2023年不同深度土壤湿度进行预测,并完成下表。
问题3.从机理分析的角度,建立不同放牧策略(放牧方式和放牧强度)对锡林郭勒草原土壤化学性质影响的数学模型。并请结合附件14中数据预测锡林郭勒草原监测样地(12个放牧小区)在不同放牧强度下2022年土壤同期有机碳、无机碳、全N、土壤C/N比等值,并完成下表。
问题4、利用沙漠化程度指数预测模型和附件提供数据(包括自己收集的数据)确定不同放牧强度下监测点的沙漠化程度指数值。并请尝试给出定量的土壤板结化定义,在建立合理的土壤板结化模型基础上结合问题3,给出放牧策略模型,使得沙漠化程度指数与板结化程度最小。
问题5、锡林郭勒草原近10的年降水量(包含降雪)通常在300 mm ~1200 mm之间,请在给定的降水量(300mm,600mm、900 mm 和1200mm)情形下,在保持草原可持续发展情况下对实验草场内(附件14、15)放牧羊的数量进行求解,找到最大阈值。(注:这里计算结果可以不是正整数)
问题6、在保持附件13的示范牧户放牧策略不变和问题4中得到的放牧方案两种情况下,用图示或者动态演示方式分别预测示范区2023年9月土地状态(比如土壤肥力变化、土壤湿度、植被覆盖等)。
如下为初步的思路解析:
E题是今年最友好的一个题目,属于典型的评价+预测类问题,并且附件中给出了大量的数据,但是部分数据依然需要补充,整体可以开展的工作很多,有利于做成一篇内容丰富、详实的数学建模论文!整体的E题解题思路和流程如下:

(1)做好数据处理,数据中如果有缺失值,则要根据数据的特点进行补全,一般数据可以通过插值补全,包括平均值法、克里金插值、拉格朗日插值等。为了更好的解题,数据的可视化处理也是很有必要的,通过可视化处理,明确数据的变化趋势,为更好的解题做铺垫,同时,一些美观的图表,增加整体文章的质量,提升可读性,不要忽略这一点,华为杯针对的是研究生,要在作品中体现出一些科研素养。
(2)基础模型的选择奠定整体的解题基调,这一点很重要,针对此次的赛题,可选的基础模型很多,华为杯一般论文较长,可以多一些分析,常见的评价、预测类模型有很多,建议尽量选择能够自己做一些小的创新点、比较高端的模型!
(3)在基础模型之后,要考虑如何做出一些创新之处,比如模型之间的融合,举个例子:熵权法与Topsis的融合,做预测的时候,不同种方法之间的对比等等,这一部分,有利于提高作品档次,助力收获更高的奖项!
下面将针对具体的问题,提出解题思路:
一、问题背景
沙漠化程度指数(SM)是从数学的范畴去界定沙漠化程度,采用一定的分级标准使得其与沙漠化程度相对应。把沙漠化程度划分为五类:非沙漠化、轻度沙漠化、中度沙漠化、重度沙漠化和极重度沙漠化,SM 采用 0~1 标度法。
沙漠化程度指数预测模型表达式[2]:

公式具体含义及其符号说明见文后扩展阅读。
土壤板结化与土壤有机物、土壤湿度和土壤的容重有关,目前还没有明确的定量表达式,其数学模型可定性描述为如下:

土壤湿度 越少,容重 越大,有机物含量 越低,土壤板结化程度 越严重。
土壤化学性质和物理性质是影响土壤肥力重要因素,土壤化学性质包括:土壤有机碳SOC、土壤无机碳SIC、土壤全碳STC、全N、土壤C/N比等;土壤物理性质包括:土壤湿度、土壤容重等。一般来说,在保持土壤化学性质等基本不变情况下,降水会增加土壤湿度,而土壤湿度增加会提高草场植被覆盖率,在良好的植被覆盖情况下可以适当提高放牧强度,在一定区域内,放牧强度越高意味着更多的放牧数量,在不考虑放牧补贴和价格波动情况下,更多放牧数量代表更高的放牧收益。
现代草地资源的经营应遵循可持续发展原则,在保证生态环境良性健康发展中寻求经济利益的最大化。美国著名生态经济学家赫尔曼·E·戴利给可持续发展的定义是:“可持续发展是经济规模增长没有超越生物环境承载能力的发展”。 其理念是“可持续发展的整个理念就是经济子系统的增长规模绝对不能超越生态系统可以永远持续或支撑的容纳范围”。在草原区域系统中,承载力是评价可持续发展的一种工具。在《远东英汉大辞典》中,承载力被定义为“某一自然环境所能容纳的生物数目(指最高限度)”。区域生态系统承载力和可持续发展是相辅相成的两个概念。
二、需解决问题:
请你根据附件数据以及收集有关草原数据(土壤容重、土壤PH等),由于历史原因,数据虽然并不充分,实际问题仍然需要解决。请通过数学建模完成下列问题:
问题1. 从机理分析的角度,建立不同放牧策略(放牧方式和放牧强度)对锡林郭勒草原土壤物理性质(主要是土壤湿度)和植被生物量影响的数学模型。
问题2. 请根据附件3土壤湿度数据、附件4土壤蒸发数据以及附件8中降水等数据,建立模型对保持目前放牧策略不变情况下对2022年、2023年不同深度土壤湿度进行预测,并完成下表。
问题3.从机理分析的角度,建立不同放牧策略(放牧方式和放牧强度)对锡林郭勒草原土壤化学性质影响的数学模型。并请结合附件14中数据预测锡林郭勒草原监测样地(12个放牧小区)在不同放牧强度下2022年土壤同期有机碳、无机碳、全N、土壤C/N比等值,并完成下表。
问题4、利用沙漠化程度指数预测模型和附件提供数据(包括自己收集的数据)确定不同放牧强度下监测点的沙漠化程度指数值。并请尝试给出定量的土壤板结化定义,在建立合理的土壤板结化模型基础上结合问题3,给出放牧策略模型,使得沙漠化程度指数与板结化程度最小。
问题5、锡林郭勒草原近10的年降水量(包含降雪)通常在300 mm ~1200 mm之间,请在给定的降水量(300mm,600mm、900 mm 和1200mm)情形下,在保持草原可持续发展情况下对实验草场内(附件14、15)放牧羊的数量进行求解,找到最大阈值。(注:这里计算结果可以不是正整数)
问题6、在保持附件13的示范牧户放牧策略不变和问题4中得到的放牧方案两种情况下,用图示或者动态演示方式分别预测示范区2023年9月土地状态(比如土壤肥力变化、土壤湿度、植被覆盖等)。
如下为初步的思路解析:
E题是今年最友好的一个题目,属于典型的评价+预测类问题,并且附件中给出了大量的数据,但是部分数据依然需要补充,整体可以开展的工作很多,有利于做成一篇内容丰富、详实的数学建模论文!整体的E题解题思路和流程如下:

(1)做好数据处理,数据中如果有缺失值,则要根据数据的特点进行补全,一般数据可以通过插值补全,包括平均值法、克里金插值、拉格朗日插值等。为了更好的解题,数据的可视化处理也是很有必要的,通过可视化处理,明确数据的变化趋势,为更好的解题做铺垫,同时,一些美观的图表,增加整体文章的质量,提升可读性,不要忽略这一点,华为杯针对的是研究生,要在作品中体现出一些科研素养。
(2)基础模型的选择奠定整体的解题基调,这一点很重要,针对此次的赛题,可选的基础模型很多,华为杯一般论文较长,可以多一些分析,常见的评价、预测类模型有很多,建议尽量选择能够自己做一些小的创新点、比较高端的模型!
(3)在基础模型之后,要考虑如何做出一些创新之处,比如模型之间的融合,举个例子:熵权法与Topsis的融合,做预测的时候,不同种方法之间的对比等等,这一部分,有利于提高作品档次,助力收获更高的奖项!
下面将针对具体的问题,提出解题思路:(以下仅为部分)
数据补全—拉格朗日插值(方法很多,此处只是举例):

问题一:问题一要求从机理分析的角度,建立不同放牧策略对土壤物理性质和植被生物量的影响。问题一可以使用数据,也可以不使用数据,总之就是建立一个评价模型,评判不同放牧策略(放牧方式和放牧强度)对草原土壤和植被生物量的影响。针对使用数据和不使用数据,可以使用层次分析法、灰色关联、模糊综合评价、TOPSIS等方法,通过查阅文献,选取指标(为了避免重复,指标大家自己查,不用太纠结指标,不要因选择指标浪费时间),之后进行建模分析。
此处,提醒大家,整个评价过程一定要清晰!可以使用不止一种方法,建议不同评价方法相结合!比如熵权法与TOPSIS相结合,下面给出具体的步骤:
(1)判断输入的矩阵是否存在负数,如果有则要重新标准化到非负区间
将评价对象个数的最大值用n表示,m个评价指标构成的正向化矩阵如下:

那么,对其标准化的矩阵记为Z,Z中的每一个元素:
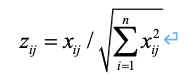
判断Z矩阵中是否存在着负数,如果存在的话,需要对X使用另一种标准化方法,对矩阵X进行一次标准化得到 矩阵,其标准化的公式为[8]:
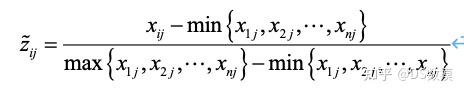
(2)计算第j项指标下第i个样本所占比重,并将其看作相对熵计算中用到的概率
假设有n个要评价的对象,m个评价指标,且经过了上一步处理得到的非负矩阵为:
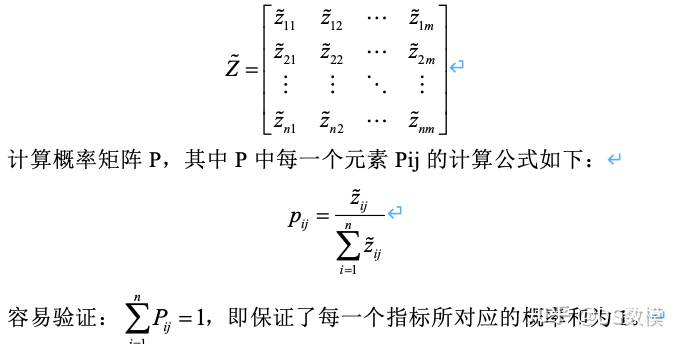


以上仅为第一问部分思路,剩余部分思路和其他具体代码,以及其他题目思路,可以点击下方群名片

