
- 106 Python numpy matplotlib 绘制立体玫瑰花_python绘制立体玫瑰花
- 2vmware升级处理vib包冲突的问题
- 3基于深度学习的自动车牌识别(详细步骤+源码)
- 4软件测试面试题汇总_界面测试题及设计题。请找出下面界面中所存在的问题并分别列出;用黑盒测试的
- 5超简单: nexus3.13 安装 ---Windows服务器安装过程和基本使用_nexus安装报错could not open scmanager.
- 62021年不可错过的40篇AI论文!
- 7element UI 中表单输入框的样式修改,深度选择器_element ui :deep修改分页器中输入框的大小css
- 8点击别处不让input光标消失_使用onclick但不影响光标
- 9博弈论-策略式博弈矩阵、扩展式博弈树 习题 [HBU]
- 10jQuery简单的翻书特效插件-jBooklet_html 使用jquery插件booklet实现左右翻页
py2neo使用python操作neo4j_py2neo4j
赞
踩
首先安装py2neo库
pip install py2neo
- 1
连接数据库
g=Graph("bolt://localhost:7687",auth=("neo4j","123456"))
- 1
创建几个节点
Alice=Node('Chinese',name='Alice')
Bob=Node('Chinese',name='Bob')
Cindy=Node('Chinese',name='Cindy')
Doge=Node('Chinese',name='Doge')
g.create(Alice)
g.create(Bob)
g.create(Cindy)
g.create(Doge)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

r1=Relationship(Alice,'朋友',Bob)
r2=Relationship(Bob,'男女朋友',Cindy)
r3=Relationship(Cindy,'好朋友',Doge)
g.create(r1)
g.create(r2)
g.create(r3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
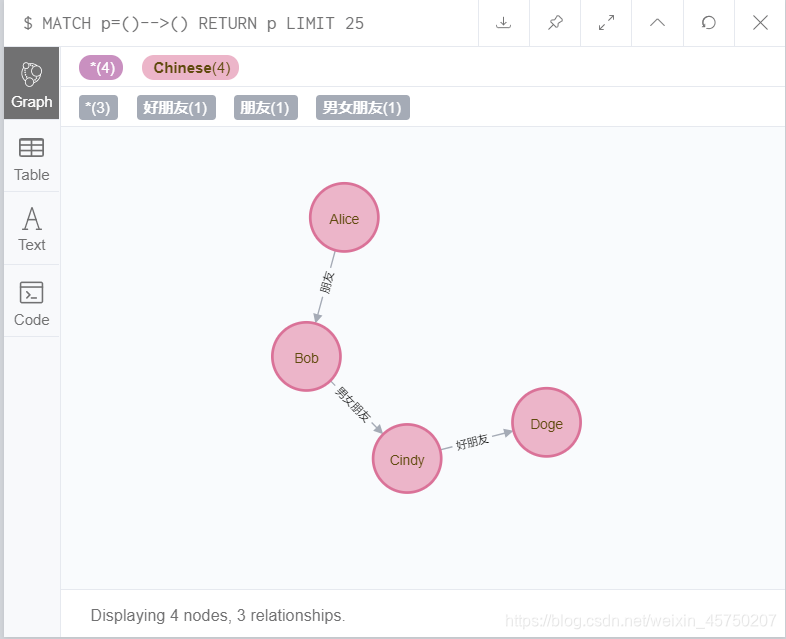
打印输出一下看看什么样子:
print(g)
print(Alice)
print(Bob)
print(Cindy)
print(Doge)
print(r1)
print(r2)
print(r3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

注意:
想要使程序代码执行起来必须使neo4j启动起来,不然会报错。
print(Alice,Bob,r1)
- 1

Node和Relationship都继承了PropertyDict类,类似于字典的形式,可以通过下面的代码对属性进行赋值操作:
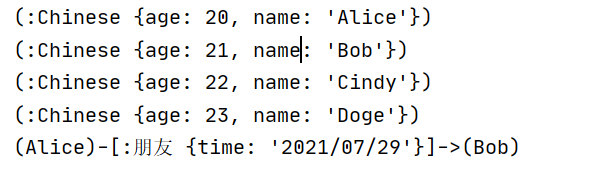
Alice['age']=20
Bob['age']=21
Cindy['age']=22
Doge['age']=23
r1['time']='2021/07/29'
- 1
- 2
- 3
- 4
- 5
运行结果:
Python 字典 setdefault() 函数和 get()方法 类似, 如果键不存在于字典中,将会添加键并将值设为默认值。
Alice.setdefault('age',18)
print(Alice)
#如果age不在Alice中,则在Alice中添加一个字典 'age':18
#如果在,则忽略默认值18;
# 这点与PropertyDict类中的get方法不同
Alice['age']='20'
Alice.setdefault('age',18)
print(Alice)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
setdefault() 方法语法:
dict.setdefault(key, default=None)
key -- 查找的键值。
default -- 键不存在时,**设置**的默认键值。
对比get() 方法语法:
dict.get(key, default=None)
key -- 字典中要查找的键。
default -- 如果指定键的值不存在时,**返回**该默认值。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

update() 可以实现对数据的批量更新,代码如下:
data={'name':'Alice','age':22}
Alice.update(data)
print(Alice)
- 1
- 2
- 3

data中不包含的key/value将继续保留。
使用示例
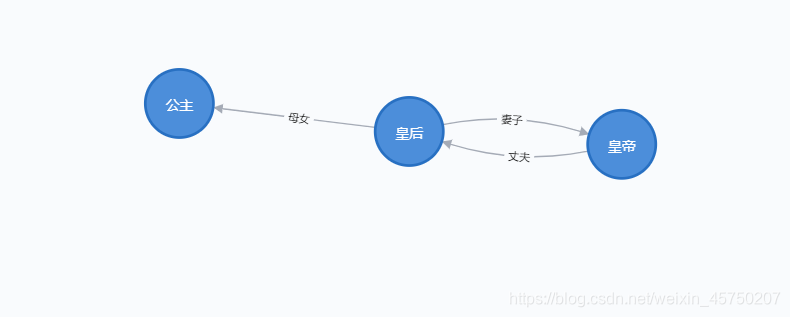
# coding:utf-8 from py2neo import Graph, Node, Relationship # 连接neo4j数据库,输入地址、用户名、密码 graph =Graph("bolt://localhost:7687",auth=("neo4j","123456")) graph.delete_all() # 创建结点 test_node_1 = Node('ru_yi_zhuan', name='皇帝') # 修改的部分 test_node_2 = Node('ru_yi_zhuan', name='皇后') # 修改的部分 test_node_3 = Node('ru_yi_zhuan', name='公主') # 修改的部分 graph.create(test_node_1) graph.create(test_node_2) graph.create(test_node_3) # 创建关系 # 分别建立了test_node_1指向test_node_2和test_node_2指向test_node_1两条关系,关系的类型为"丈夫、妻子",两条关系都有属性count,且值为1。 node_1_zhangfu_node_1 = Relationship(test_node_1, '丈夫', test_node_2) node_1_zhangfu_node_1['count'] = 1 node_2_qizi_node_1 = Relationship(test_node_2, '妻子', test_node_1) node_2_munv_node_1 = Relationship(test_node_2, '母女', test_node_3) node_2_qizi_node_1['count'] = 1 graph.create(node_1_zhangfu_node_1) graph.create(node_2_qizi_node_1) graph.create(node_2_munv_node_1) print(graph) print(test_node_1) print(test_node_2) print(node_1_zhangfu_node_1) print(node_2_qizi_node_1) print(node_2_munv_node_1)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34

数据对象详解
Node
node 是保存在Neo4j里面的数据存储单元,在创建node后,我们可以有很多操作,如下:
#获取key对应的property x=node[key] #设置key键对应的value,如果value是None就移除这个property #如 x=Alice['age'] node[key] = value #也可以专门删除某个property #如 Alice['age']=12 del node[key] #返回node里面property的个数 len(node) #返回所以和这个节点有关的label(List) labels=node.labels #删除某个label node.labels.remove(labelname) #将node的所有property以dictionary的形式返回 dict(node)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Relationship
对于relationship,也有很多相似操作,如下:
Relationship(start_node,type,end_node,properties)
#起始节点、关系类型、结束结点、关系的属性
Relationship[key]
#返回关系key的property
del Relationship[key]
#删除某个property
dict(relationship)
#将relationship的所有property以dictionary的形式返回
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Subgraphs
子图是节点和关系不可变得集合,我们可以通过 set operator来结合,参数可以是独立的node或relationship
subgraph1 | subgraph2 | subgraph3... 结合这些subgraphs
subgraph1 & subgraph2 & subgraph3... 相交这些subgraphs
subgraph1 - subgraph2 - subgraph3... 不同关系
- 1
- 2
- 3
查询Query
最新的版本中,对node的查询移除了原有的 find(),可以再nodes中使用match 来找点
graph.nodes.match(self, *labels, **properties)
- 1
或者使用py2neo.maching 包里面的NodeMatcher(graph) 函数构建个 matcher再查询(上面的方法也是这样的道理)
首先创建Matcher来执行查询,它会返回一个Match类型的数据,可以继续使用 where(),first(),order_by()等操作,可以用list强制转换
graph = Graph()
matcher=NodeMatcher(graph)
matcher.match("Person",name='Alice').first()
list(matcher.match("Person").where("_.name=~'A.*'"))
#正则匹配名字A字开头的
- 1
- 2
- 3
- 4
- 5
- 6
查询Relationship
graph.matche(nodes=None,r_type=None,limit=None)#找出所有的 relationship
- 1
批处理
首先,为了加快数据库进行大量插入删除的操作所需要的时间,我们可以采用事务加快一定的速度,那么为什么事务可以加快大量插入删除的速度呢?
如果没有采用事务的话,它每次写入提交,就会触发一次事务操作,而这样几千条的数据,就会触发几千个事务的操作,这就是时间耗费的根源。
我们生成每个Node后,先把他们放入一个List中,再变为Subgraph实例,然后再create(),耗时比一条条插入至少快10倍以上。(不太懂)
如何加快查找节点的效率呢?
如果在节点存进去之后,通过py2neo层面的"查找node,create"关系这样效率将不是很高,时间大量花在通过“reference id”去一个个查找对应的node,然后再和这个node建立关系,推荐使用原生语句。
graph.run("match(p:Post),(u:User)where p.OwnerUserId=u.Id CREATE (u)-[:Own]->(p)")
- 1

