
- 1C#导入数据使用Task异步处理耗时任务_c# 耗时数据库任务
- 2从故宫修建看「软件物料清单」的重要性 @安全历史01
- 3真人动作捕捉系统 for Unity
- 4【2023/2/25 更新】Windows Server 2019 服务配置与管理汇总_windows server基本配置与管理实验总结
- 5Python学习-8.1.3 标准库(turtle库的基础与实例)_turtle库python
- 6flask_redis数据库_flask redis master slave
- 7android基础学习之二维码扫描zxing精简步骤_zxing need_result_point_callback
- 8Jetbrains ai assistant激活后仍无法使用,怎么回事?_ai assistant一直灰色
- 9python湖北武汉二手房数据可视化大屏全屏系统设计与实现(django框架)_二手房数据可视化大屏代码
- 10Unity 5.6中的混合光照(上)
neo4j用python导入Excel数据的方法_neo4j导入excel
赞
踩
目录
neo4j的下载
neo4j下载网址:Neo4j Download Center - Graph Database & Analytics
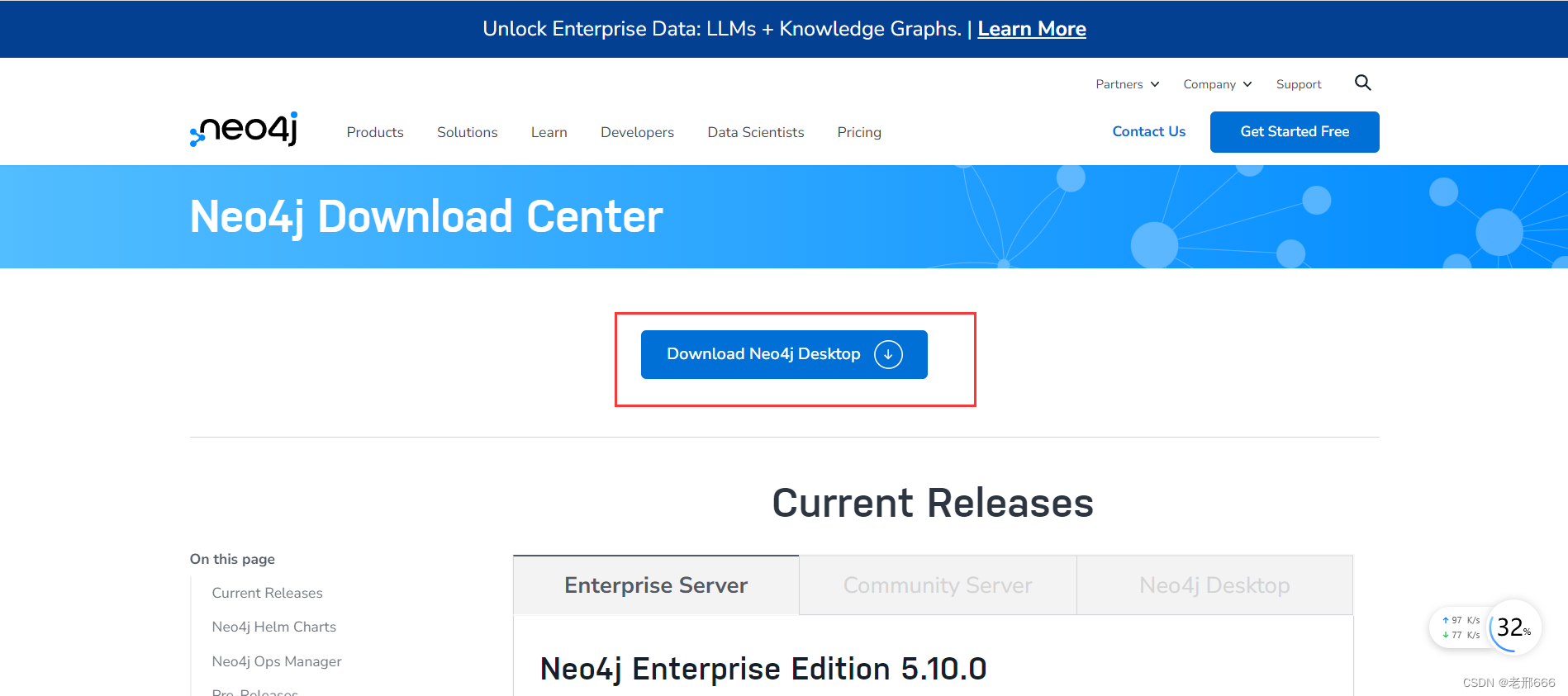
点击红框内的Download Neo4j Desktop
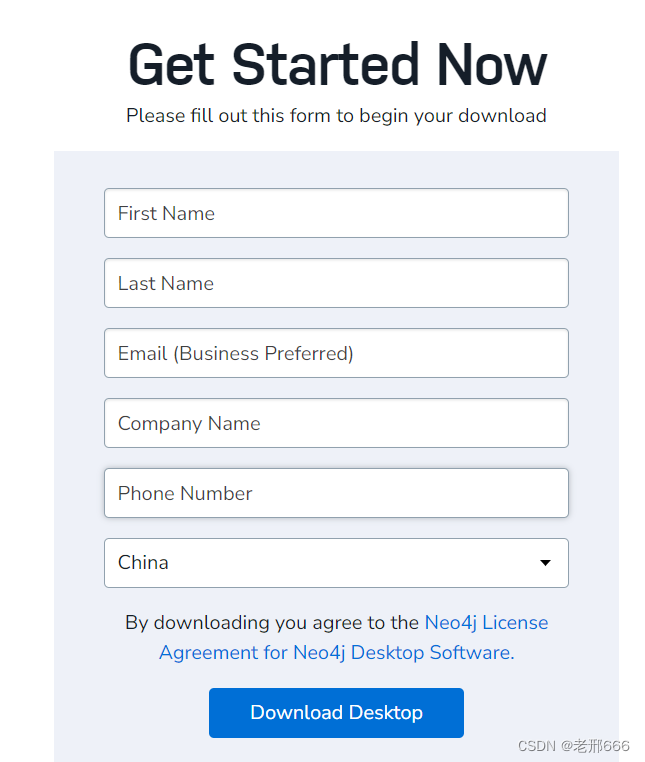
填写信息后点击Download Desktop,即可下载安装包
安装步骤较为简单,此处省略
neo4j的介绍
neo4j简介
neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。
neo4j样本项目介绍
红框内的代表Projects,里面包含了所有的项目文件,刚下载好neo4j后,neo4j会给一个样本项目(Example Project),这个项目里的图数据库存储的是美国电影和影视演员之间的知识图谱关系:


neo4j修改密码
这个是图数据库的操作页面,其中比较重要的是下图红框内的内容,我们在以后的连接python和GraphXR时需要用到bolt连接、用户名neo4j和密码,密码的话修改过程如下:
先点击第一个红框的空白处,就会弹出图数据库的详细信息,然后里面有重新设置密码的地方,输入密码点击Apply就行,这里我设置的是123456789
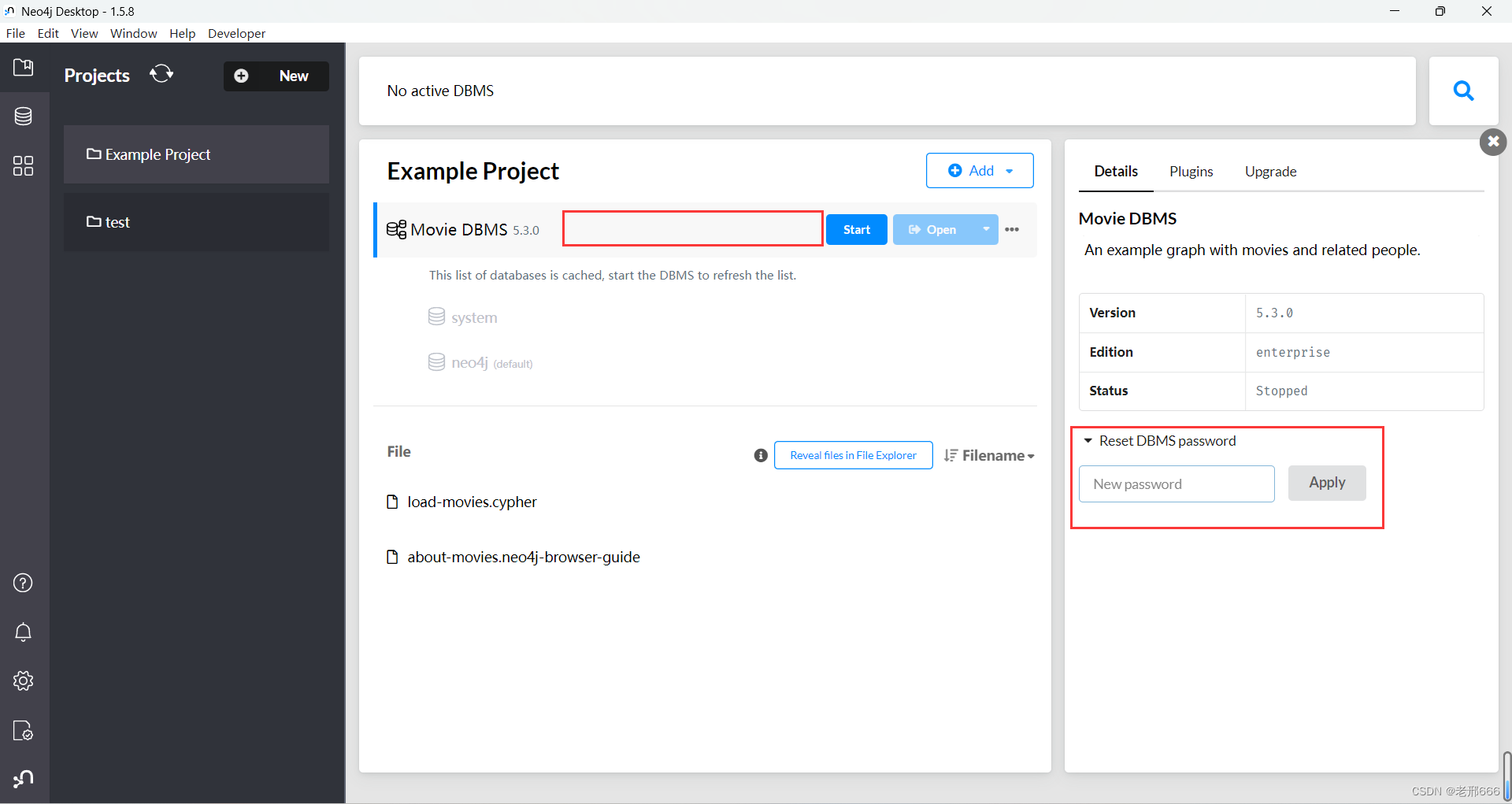
我们点击start启动图数据库
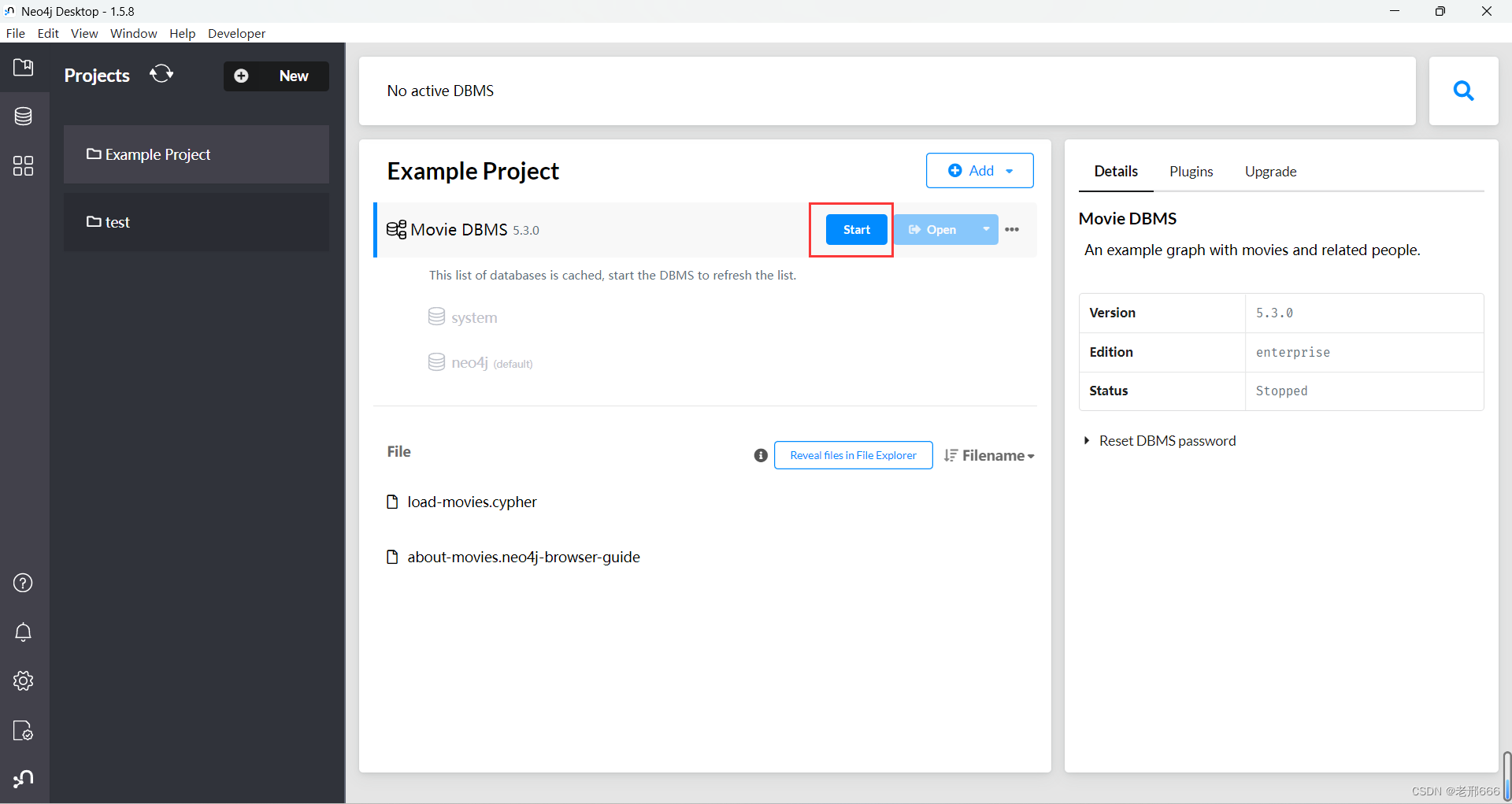
点击Open打开

弹出这个页面:
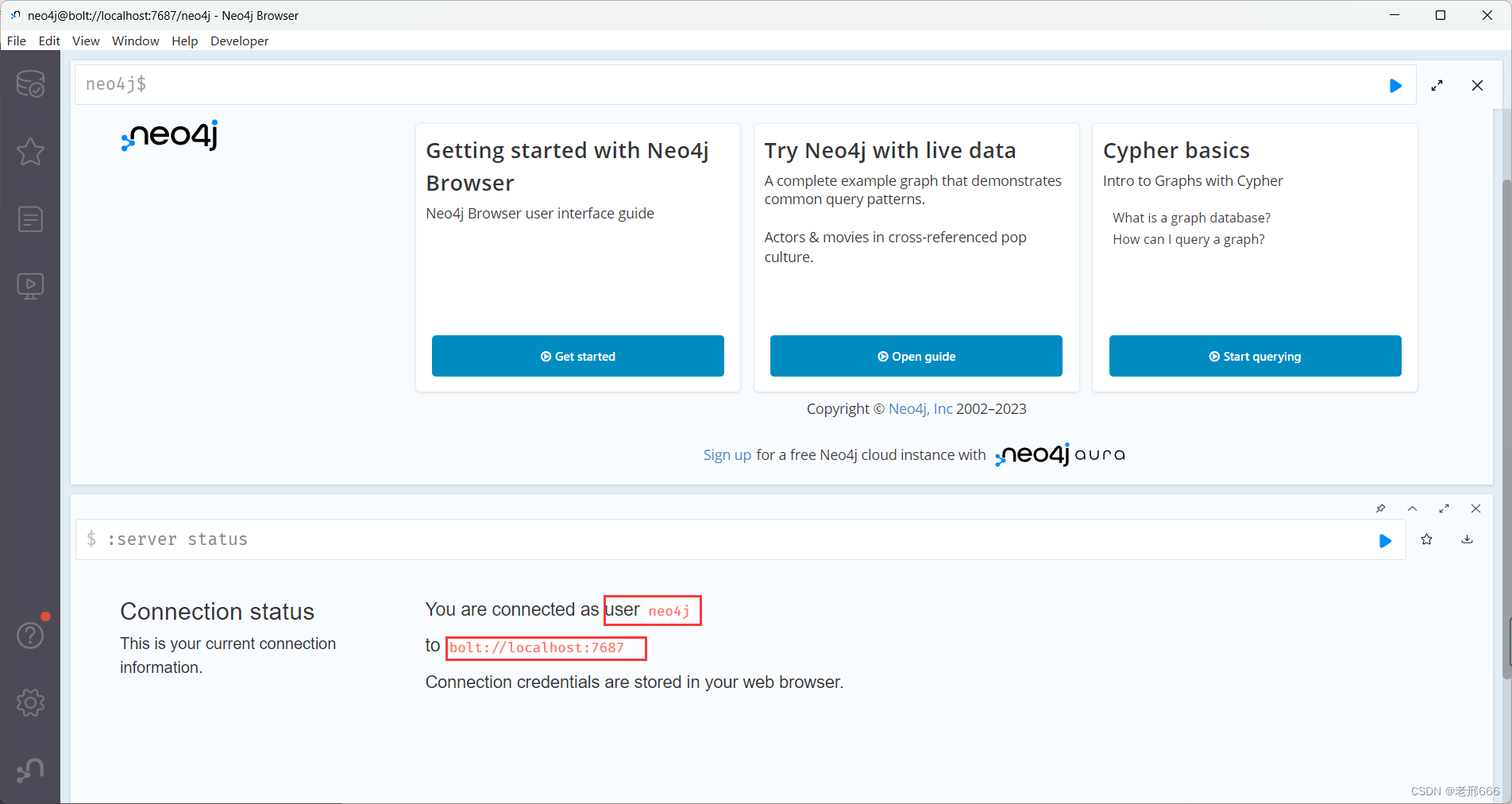
红框里的就是用于连接的bolt连接和用户名neo4j,密码我们之前已经修改为了123456789
连接GraphXR
neo4j数据库查看数据:

红框标注的三个都可以点击,点击Movie就是查看Movie类的结点,Person就是Person类的结点,*169是不论类别的结点, 我们点击查看时图中限制了大小(LIMIT 25),指的是查看25个结点的关系图谱,我们可以更改LIMIT后面的值,也可以直接删除LIMIT:
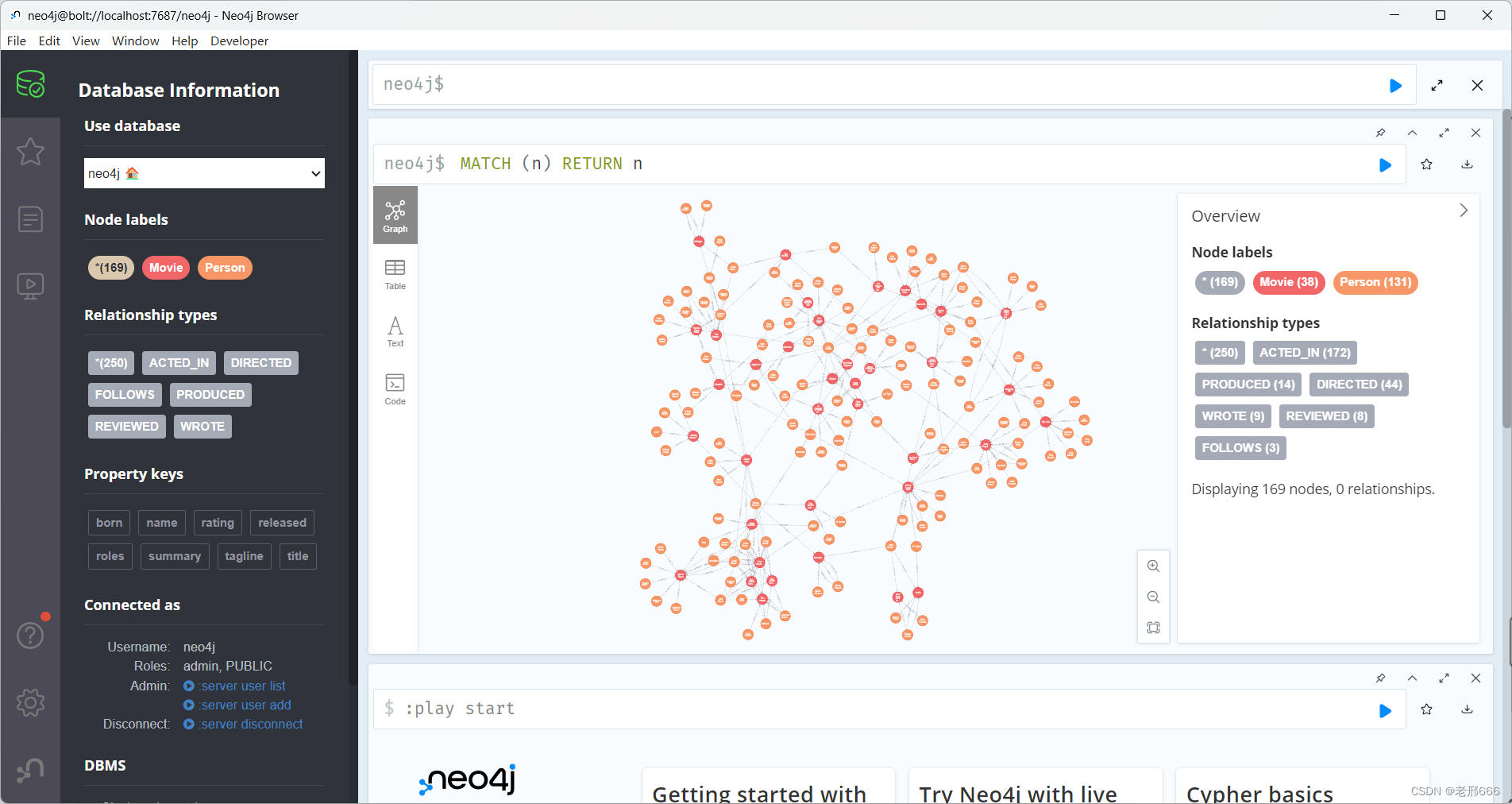
如果查看的数据量很大会造成neo4j卡顿,我推荐用GraphXR来进行查看
网址:上海图客科技有限公司

点击GraphXR试用,因为我已经注册过账号,所以可以直接进入,新人第一次点击试用后可以注册账号,然后免费试用,试用时间没说多少天......

我们点击新建:
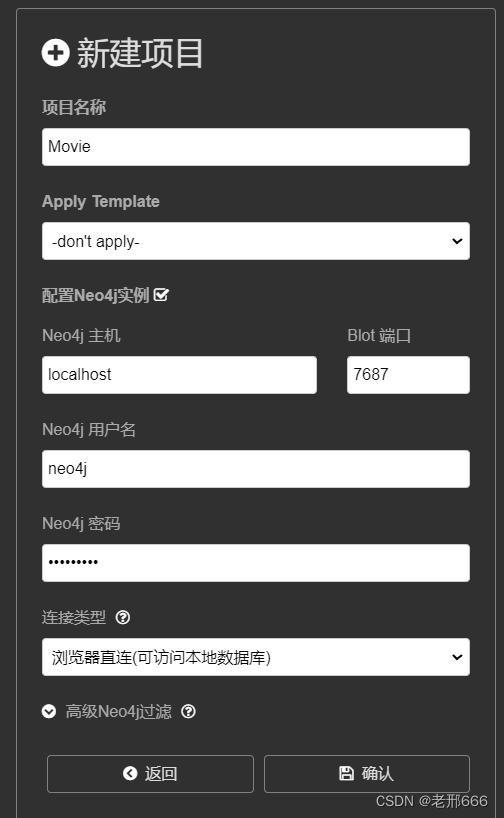
项目名称可以自己填,然后勾选配置neo4j实例,主机填localhost,端口就是7687,用户名就是neo4j,密码我们设置的是123456789,点击确认就行。(注意连接neo4j时neo4j的数据库要保持开着的状态,不能关了)

按照上图操作,点击提取所有:

其中类别和关系是主要的两个提取操作,我们可以都提取出来查看(如上图):
用Python往neo4j导入Excel数据
我们可以把Excel文件和python文件放在一个文件夹里(便于提取和操作):
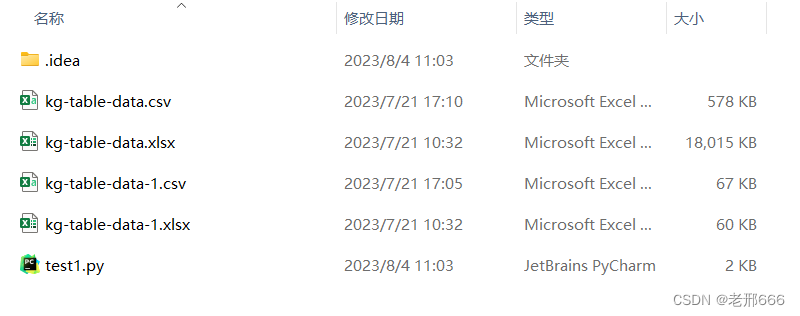
其中我把Excel文件转换成了csv文件,一个是python对csv文件提取和操作都更快,另一个是我在操作Excel文件时会有一些编码错误,所以我用csv文件来导入数据
代码部分
下面是test1.py的代码:
- from py2neo import Graph, Node, Relationship
- import csv
-
- g = Graph("bolt://localhost:7687", user="neo4j", password="123456789", name="neo4j") # 连接数据库
-
- reader = csv.reader(open('kg-table-data.csv', 'r', encoding='utf-8')) # 读取csv文件
- reader1 = csv.reader(open('kg-table-data-1.csv', 'r', encoding='utf-8')) # 读取csv文件
-
- for item in reader: # 读取每一行
- if reader.line_num == 1: # 去除第一行
- continue
- print("当前行数:", reader.line_num, "当前行内容:", item) # 打印当前行数和当前行内容
-
- # 创建起始节点,并添加属性
- start_node = Node('Company', name=item[0]) # 创建节点
- start_node['role'] = '竞买方' # 添加属性
- g.merge(start_node, 'Company', 'name') # 以name属性为主键,如果存在则更新,不存在则创建
-
- # 创建结束节点,并添加属性
- end_node = Node('Company', name=item[4]) # 创建节点
- end_node['role'] = '出让方' # 添加属性
- g.merge(end_node, 'Company', 'name') # 以name属性为主键,如果存在则更新,不存在则创建
-
- # 为两个节点之间添加关系以及关系的属性
- relationship_type = '竞买' # 关系类型
- relationship_properties = { # 关系属性
- '交易标的': item[1],
- '首次披露日': item[2],
- '交易总价值(本币/万元)': item[3]
- }
- relationship = Relationship(start_node, relationship_type, end_node, **relationship_properties) # 创建关系
- g.merge(relationship) # 以关系为主键,如果存在则更新,不存在则创建

先在python终端或者cmd里面安装py2neo库:
pip install py2neo代码详解在注释里已经写得比较详细了,其中如果给结点添加属性的话,可以这样写:
start_node['role'] = '竞买方' # 添加属性中括号里是结点的属性,后面的赋值是属性的一个具体表现,role和竞买方这两个单词是可以换成其他东西的。
关系属性的添加的话可以这样写:
- relationship_properties = { # 关系属性
- '交易标的': item[1],
- '首次披露日': item[2],
- '交易总价值(本币/万元)': item[3]
- # 添加一个关系属性:
- '交易地点':item[5]
- }
着重讲一下item,这个是在for循环当中读取每一行的数组变量,它读取的是文件的每一行:
- for item in reader: # 读取每一行
- if reader.line_num == 1: # 去除第一行
- continue
- print("当前行数:", reader1.line_num, "当前行内容:", item) # 打印当前行数和当前行内容
根据我那个表格的话,item[0]是竞买方,item[4]是出让方,item[1],item[2],item[3]分别是交易标的、首次披露日、交易总价值(本币/万元)。
关于创建结点:
- start_node = Node('Company', name=item[0]) # 创建节点
- start_node['role'] = '竞买方' # 添加属性
- g.merge(start_node, 'Company', 'name') # 以name属性为主键,如果存在则更新,不存在则创建
其中Company是这个结点的一个大属性(大类),name=item[0]就是根据item[0]来为它创建名称,role就是它的一个小属性:竞买方,g.merge()这个函数表示如果没有这个结点,就创建这个结点并添加,如果有这个结点就不重复添加了。
关于创建关系:
- # 为两个节点之间添加关系以及关系的属性
- relationship_type = '竞买' # 关系类型
- relationship_properties = { # 关系属性
- '交易标的': item[1],
- '首次披露日': item[2],
- '交易总价值(本币/万元)': item[3]
- }
- relationship = Relationship(start_node, relationship_type, end_node, **relationship_properties) # 创建关系
- g.merge(relationship) # 以关系为主键,如果存在则更新,不存在则创建
关系的大类别为:竞买,关系的属性在relationship_properties里存储,item是读取每一行之后的数据,根据数组下标填进去就行,如果要添加属性就在relationship_properties里面继续添加,格式为:
- # 你要添加的属性
- '要添加的属性': item[5] # item[]中括号里面的数字看csv表格里的进行添加
结束
以上就是neo4j用python导入Excel或csv数据的方法,谢谢大家!

