
- 1目标检测应用化之web页面(YOLO、SSD等)
- 2docker-compose详讲_docker-compose ports
- 3关于YOLOv5的学习经验总结(保姆级讲解)
- 4element ui多选下拉组件(el-select)tag数量过多处理解决办法(二次封装)_element下拉框数据过多
- 5flutter更新后[VERBOSE-2:FlutterDarwinContextMetalImpeller.mm(35)] Using the Impeller rendering backend,_[error:flutter/shell/platform/darwin/graphics/flut
- 6基于JSDoc实现TypeScript类型安全的实践报告_jsdoc 断言
- 7springboot常用注解详解_spring boot注解
- 8数据分析系列3—matplotlib使用_import as plt
- 9SQL Developer 小贴士:PL/SQL语法分析
- 10Antd 级联下拉列表_ant design 级联如何可以选第一级
Stable Diffuse 之 本地环境部署/安装包下载搭建过程简单记录_stable diffusion一键本地部署安装包
赞
踩
Stable Diffuse 之 本地环境部署/安装包下载搭建过程简单记录
目录
Stable Diffuse 之 本地环境部署/安装包下载搭建过程简单记录
一、简单介绍
Stable Diffusion是一个文本到图像的潜在扩散模型,由CompVis、Stability AI和LAION的研究人员和工程师创建。它使用来自LAION-5B数据库子集的512x512图像进行训练。使用这个模型,可以生成包括人脸在内的任何图像,因为有开源的预训练模型,所以我们也可以在自己的机器上运行它,如下图所示。
Stable Diffusion是一个AI 绘图软件 (开源模型),可本地部署,可切换多种模型,且新的模型和开源库每天都在更新发布,最重要的是免费,没有绘图次数限制。
Github 网址:GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
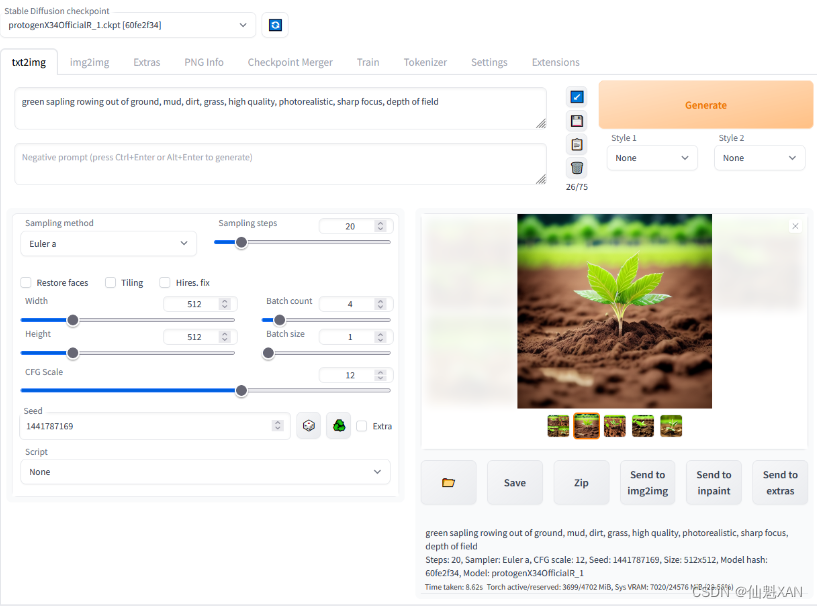
二、注意事项
1、电脑的显存至少2G以上
2、最好 python 3.10.x 及以上合适版本
三、环境搭建
这里操作案例环境:win 10
git 下载和安装
1、下载 git ,选择对应版本下载即可
git 下载地址:Git - Downloads

2、安装 git ,操作简单这里不再赘述,安装成功后,cmd 中 git --version 检测是否安装成功
能看到安装版本,说明安装及环境配置成功,如下图

python 下载和安装
1、在 python 官网下载对应版本,这里使用 3.10.9 版本
python 官网下载地址:Download Python | Python.org


2、下载好后,安装 python ,记得包 path 添加到环境变量中

3、在cmd ,测试是否安装成功,python --version
能看到安装版本,说明安装及环境配置成功,如下图

stable-diffusion-webui 下载和安装
1、打开 github 网址,搜索找到 stable-diffusion-webui
stable-diffusion-webui github 地址:GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI

2、获取下载地址,在 git 中 clone 克隆下来


3、下载好后,文件夹文件如下图

4、找到 webui-user.bat,运行 webui-user.bat
(安装过程较长,可能需要魔法上网)


5、中间可能出现,需要升级一下 Python 的 pip ,根据提示操作即可

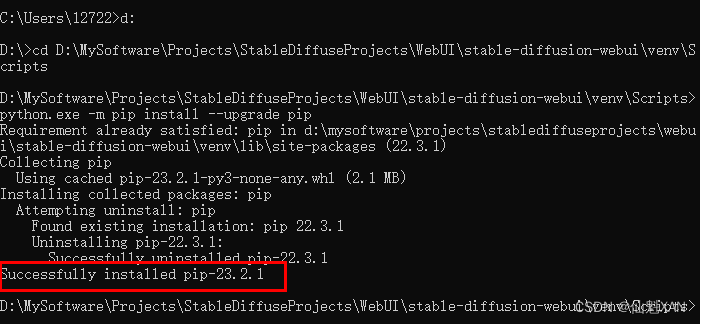
6、重复第4步骤,再次运行 webui-user.bat
中间可能会有 一些安装包安装(clip 、git clone 等)不上,魔法上网可以处理,
7、安装结束之后,会自动打开网页


测试 stable diffuse webui 文生图功能
1、运行 webui-user.bat

2、打开的网页中,输入一些简单的提示词,效果如下
Vincent van Gogh’s painting of Emma Watson; prompt2: John Sargent’s painting of Emma Watson

3、每次的处理过程后台也会有进度
附录:Stable Diffusion 一些基础介绍
Stable Diffusion是一种机器学习模型,它经过训练可以逐步对随机高斯噪声进行去噪以获得感兴趣的样本,例如生成图像。
扩散模型有一个主要的缺点就是去噪过程的时间和内存消耗都非常昂贵。这会使进程变慢,并消耗大量内存。主要原因是它们在像素空间中运行,特别是在生成高分辨率图像时。
Latent diffusion通过在较低维度的潜空间上应用扩散过程而不是使用实际的像素空间来减少内存和计算成本。所以Stable Diffusion引入了Latent diffusion的方式来解决这一问题计算代价昂贵的问题。
1、Latent diffusion的主要组成部分
Latent diffusion有三个主要组成部分:
1)自动编码器(VAE)
自动编码器(VAE)由两个主要部分组成:编码器和解码器。编码器将把图像转换成低维的潜在表示形式,该表示形式将作为下一个组件U_Net的输入。解码器将做相反的事情,它将把潜在的表示转换回图像。
在Latent diffusion训练过程中,利用编码器获得正向扩散过程中输入图像的潜表示(latent)。而在推理过程中,VAE解码器将把潜信号转换回图像。
2)U-Net
U-Net也包括编码器和解码器两部分,两者都由ResNet块组成。编码器将图像表示压缩为低分辨率图像,解码器将低分辨率解码回高分辨率图像。
为了防止U-Net在下采样时丢失重要信息,通常在编码器的下采样的ResNet和解码器的上采样ResNet之间添加了捷径的连接。
在Stable Diffusion的U-Net中添加了交叉注意层对文本嵌入的输出进行调节。交叉注意层被添加到U-Net的编码器和解码器ResNet块之间。

3)Text-Encoder
文本编码器将把输入文字提示转换为U-Net可以理解的嵌入空间,这是一个简单的基于transformer的编码器,它将标记序列映射到潜在文本嵌入序列。从这里可以看到使用良好的文字提示以获得更好的预期输出。

2、为什么Latent Diffusion快速有效
Latent Diffusion之所以快速有效,是因为它的U-Net是在低维空间上工作的。与像素空间扩散相比,这降低了内存和计算复杂度。例如,一个(3,512,512)的图像在潜在空间中会变成(4,64,64),内存将会减少64倍。
3、Stable Diffusion的推理过程
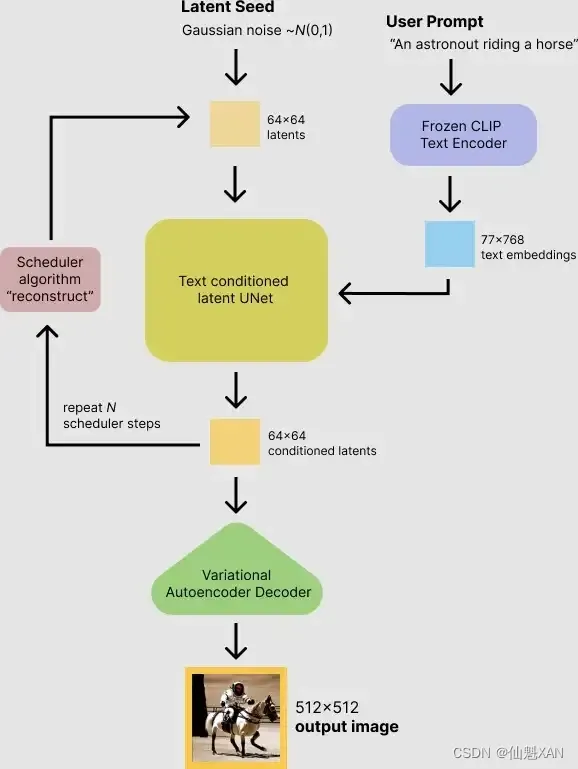
1)首先,模型将潜在空间的随机种子和文本提示同时作为输入。然后使用潜在空间的种子生成大小为64×64的随机潜在图像表示,通过CLIP的文本编码器将输入的文本提示转换为大小为77×768的文本嵌入。
2)然后,使用U-Net 在以文本嵌入为条件的同时迭代地对随机潜在图像表示进行去噪。 U-Net 的输出是噪声的残差,用于通过scheduler 程序算法计算去噪的潜在图像表示。 scheduler 算法根据先前的噪声表示和预测的噪声残差计算预测的去噪图像表示。
许多不同的scheduler 算法可以用于这个计算,每一个都有它的优点和缺点。对于Stable Diffusion,建议使用以下其中之一:
-
PNDM scheduler (默认)
-
DDIM scheduler
-
K-LMS scheduler
去噪过程重复约50次,这样可以逐步检索更好的潜在图像表示。一旦完成,潜在图像表示就会由变分自编码器的解码器部分进行解码。



