
- 1无人驾驶中常用的37个数据集以及每个数据集的亮点_traffic-net
- 2MyEclipse配置Tomcat最详细的图解教程_myelicpes配置tom
- 3Pycharm在线/手动离线安装第三方库-以scapy为例(本地离线添加已经安装的第三方库通过添加Path实现)_pycharm离线怎么加载已经安装好的库
- 4【C++】OpenCV:YOLO目标检测介绍及实现示例_opencv 目标检测yolo
- 5文件分块与合并_appendfilestorageclient
- 6Maven教程【整理】-(2)-资源库(本地资源库/ 中央资源库/ 远程仓库)_meavn central资源库
- 7链接: https://pan.baidu.com/s/1-DgIQmPNwGydAYYwA_fT5w 提取码: pq9q 复制这段内容后打开百度网盘手机App,操作更方便哦_pan baidu
- 8三种数据标准化方法的对比:StandardScaler、MinMaxScaler、RobustScaler_quantile 标准化计算公式
- 9阿里云服务器命令_阿里云命令码
- 10java第三次作业
大规模Kafka集群的管理利器: LinkedIn最新开源的Cruise Control带来了什么?
赞
踩
导读:最近几年kafka受到越来越多的关注,LinkedIn的Kafka规模已经非常庞大。如何运维如此大规模的Kafka集群是一个很有挑战的事情。针对这一问题,LinkedIn的团队交出了自己的答卷。
在过去几年中 Apache Kafka[1] 受欢迎程度日益高涨。 LinkedIn 部署的 Kafka 集群每天处理超过 2 万亿条消息。 虽然 Kafka 已被证明是非常稳定的,但运行如此大规模的 Kafka 仍然存在运维上的挑战。 Broker 每天都会失败,导致我们集群工作负载不均衡。 因此, SRE 花费大量时间和精力重新分配分区,以保证 Kafka 群集均衡。
智能自动化在这种情况下至关重要,这就是为什么我们开发了 Cruise Control[2] 。 Cruise Control 是一个用于持续监视 Kafka 集群并根据配置自动调整分配资源的系统。用户指定目标, Cruise Control 负责监控是否违反这些目标,分析群集现有工作负载,并自动执行管理操作以满足这些目标。 在去年秋天的流处理会议上,您可以看到有关 Cruise Control 的视频 [3]。
今天我们很高兴地宣布,我们开源了 Cruise Control,现在可以在 Github 上获得 [3] 该软件 。 在本文中,我们将描述 Cruise Control 在 LinkedIn 的使用,其架构以及创建时遇到的一些独特挑战。 如果对本文中使用的 Kafka 术语不理解,这份参考资料 [4] 将对您很有帮助。
设计目标
当我们设计Cruise Control时,我们有一些重要的要求:
可靠的自动化:Cruise Control应该能够准确地分析集群工作负载并生成可信赖的执行计划,而无需任何人为干预。
资源效率:Cruise Control应该足够聪明,在执行操作时会避免对集群可用性产生不利影响。
可扩展性: Kafka用户对其Kafka部署的可用性和性能有不同的要求,而且会使用各种部署工具,管理节点和数据收集机制。 Cruise Control必须能够满足任意用户定义的目标并执行用户定义的操作。
通用性:我们在早期就意识到,其他分布式系统也可以受益于类似的运维自动化(需要完成应用感知监控分析 - 动作周期)。 虽然现有的类似产品有助于均衡集群中的资源利用率,但大多数与应用无关,并通过迁移整个应用程序达到目的。 虽然这对于无状态系统来说工作的很好,但当涉及到有状态系统(例如Kafka)时,这些产品通常就无计可施了。 因此,我们希望Cruise Control成为在任何分布式系统中都可以使用的通用框架。
LinkedIn的Cruise Control
Cruise Control旨在解决以下关键的运维目标:
Kafka集群必须在磁盘,网络和CPU利用率方面持续均衡节点。
当broker失败时,我们需要自动将该broker上的副本重新分配给群集中的其他broker,并恢复原始的复制因子。
我们需要能够识别消耗群集最多资源的分区。
我们需要支持低接触集群扩展和broker停用。 从集群添加或删除代理程序后需要手动重新分配分区,这些操作非常繁琐。
能够使用异构硬件运行群集(例如,在缺少相同的硬件时快速修复硬件故障)。 然而,异构硬件增加运维开销,因为在均衡集群时,SRE需要精确地识别硬件差异。 Cruise Control应该能够支持异构机器的Kafka群集和单机运行多个broker。
它是如何工作的?
Cruise Control遵循监控/分析/操作 这样的工作周期。 下图描述了Cruise Control的架构。 许多组件是可插拔的,如图所示(例如,度量取样器,分析器等)。
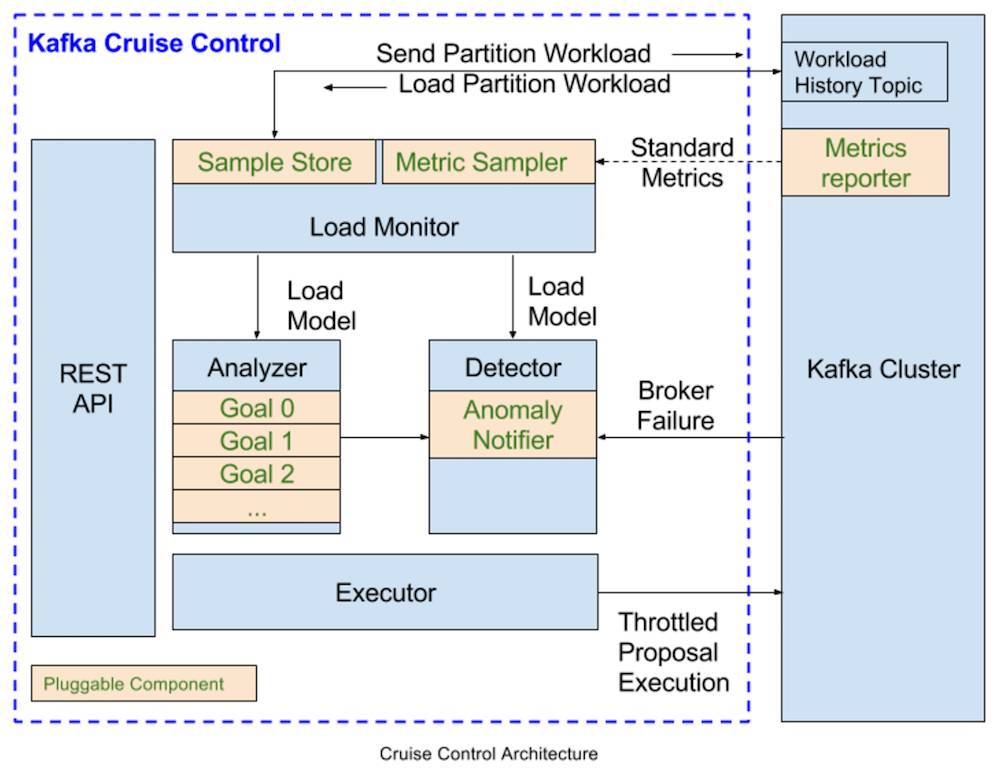
REST API
Cruise Control提供了REST API,允许用户与之进行交互。 REST API支持查询Kafka群集的工作负载和优化建议,并支持触发运维操作。
负载监视器
负载监视器从集群收集标准Kafka指标,并且可以获取每个分区资源指标(例如,每个分区的估计CPU利用率)。 然后生成一个集群工作负载模型,以准确捕获集群资源利用率,其中包括磁盘利用率,CPU利用率,字节输入和输出速率。 然后将模型反馈到检测器和分析器。
分析器
分析器是Cruise Control的“大脑”。 它使用启发式方法基于用户提供的优化目标和来自负载监视器的集群工作负载模型生成优化方案。
优化目标基于用户配置的优先级。 优先级较高的目标首先被保证。低优先级目标不能导致违反高优先级目标。
Cruise Control还允许指定硬性目标和软性目标。 硬性目标是必须满足的目标(例如,副本放置必须做到机架可识别)。 另一方面,如果可以满足所有硬性目标,那么软性目标可以不必达成。 如果优化结果违反了一个硬性目标,优化将会失败。 硬性目标将比软性目标具有更高的优先级。 到目前为止,我们实现了以下硬性/软性目标:
硬目标
副本配置必须是机架可识别的。 相同分区副本放在不同的机架上,这样当某个机架停机时,任何分区最多会有一个副本丢失。 这有助于控制故障边界,并使Kafka更加健壮。
broker资源利用率必须在预定义的阈值内。
即使broker上的所有副本都成为leader,也不能允许网络利用超出预先定义的容量。在这种情况下,所有的消费者流量将被重定向到该broker,这将导致比平常更高的网络利用率。
软目标
试图在所有broker之间实现一致的资源利用率。
试图在broker之间实现leader分区的均匀字节输入速率(来自客户端而非来自复制的字节输入速率)。
试图将特定主题的分区均匀分配到所有broker上。
试图将副本均匀分配到所有broker上。
在高层次上,目标优化逻辑如下:
For each goal g in the goal list ordered by priority* {
For each broker b {
while b does not meet g’s requirement {
For each replica r on b sorted by the resource utilization density** {
Move r (or the leadership of r) to another eligible broker b’ so b’ still satisfies g and all the satisfied goals
Finish the optimization for b once g is satisfied.
}
Fail the optimization if g is a hard goal and is not satisfied for b
}
}
Add g to the satisfied goals
}
* The high priority goals are optimized first
**The utilization density is Resource_Utilization / Partition_Size
异常检测器
异常检测器识别两种异常:
broker故障:即非空代理离开集群,导致分区副本数不足。 因为这可能会在正常的群集恢复期间发生,所以异常检测器在触发通知并修复群集之前提供可配置的宽限期。
目标违反:即违反优化目标。 如果启用自愈功能,Cruise Control将主动尝试通过自动分析工作负载并执行优化方案来解决目标违反。
执行器
执行器负责执行来自分析器的优化方案。 重新均衡Kafka集群通常涉及重新分配分区。 执行程序确保执行是资源可感知的,并不会压跨任何代理。 重新分配分区可能是一个长期运行的过程(在一个大的Kafka集群中可能需要几天的时间才能最终完成)。 有时,用户可能希望停止正在进行的分区重新分配。 执行器的设计就考虑到了在执行方案时安全中断。
有趣的挑战
我们在开发和使用Cruise Control时遇到许多有趣的挑战。 下面列出其中几个。
为Kafka构建可靠的集群工作负载模型
这并非像听起来那样简单。 有很多细微之处要注意。 例如,从broker收集CPU利用率指标非常简单,但是我们如何量化每个分区对CPU利用率的影响? 这个wiki页面[5]解释了我们是回答这个问题的。
您愿意为优化方案等待多久?
分析器组件已经取得了长足进步。 我们最初使用具有复杂参数化损耗函数的通用优化器。 在中型Kafka群集上获取优化方案需要几周时间。 后来我们切换到当前的启发式优化器,这可以在几分钟之内得到相当不错的优化方案。
内存还是速度?
因为我们必须保存一段时间(例如一个星期)的度量指标,以便分析Kafka群集中分区的流量模式,并且由于生成优化方案需要进行大量计算,所以Cruise Control同时是内存密集型和CPU密集型的程序。 但是这是相互矛盾的。 为了加快优化方案生成,我们希望使用更多的缓存和并行计算,但这样做会增加内存和CPU的使用。 我们最终做出了一些设计决策,以在两者之间取得平衡。 例如,我们预先计算优化方案并缓存起来,以避免用户查询到时的长时间等待。 另一方面,我们还错开了内存密集型任务的执行(例如,方案预计算和异常检测等),以避免高内存消耗操作同时执行。
未来的工作
更多Kafka集群优化目标!
由于Cruise Control的优化目标是可插拔的,因此用户可能会根据需要提出精密的目标来优化自己的Kafka群集。 例如,我们使用LinkedIn的Kafka Monitor[6]来监控我们的集群可用性。 由于Kafka Monitor根据其向“监控”主题发送消息的能力来报告每个broker的可用性,因此我们需要确保该主题分区的leader能够覆盖所有broker。 作为一个开源项目,我们也鼓励用户创造自己的目标,并为社区做贡献。
与云管理系统(CMS)集成
目前,Cruise Control系统通过迁移坏掉的分区代理来治愈集群。 我们设想,Cruise Control可以与其他CMS集成,以便在利用率达到一定阈值时自动扩展群集,必要时也可以从备用池用一个新代理替换故障代理。 如上所述,我们欢迎社区的加入和对未来功能的贡献。
通过深入了解操作
Cruise Control有助于深入分析从Kafka收集的指标。 我们相信,它将使SRE能够量化各种资源使用指标的影响,并获得有助于容量规划和性能调优。
概括 我们开发Cruise Control时认识到动态负载平衡器对任何分布式系统来说都是实用工具。 Cruise Control的度量指标聚合,资源利用率分析和优化方案的生成同样适用于其他分布式系统。我们想抽象出这些核心组件,并提供给其他项目。 我们对Cruise Control的愿景是以允许与任何分布式系统直接集成的方式构建,以促进特定于应用程序的性能分析,优化和执行。
致谢
Cruise Control开始于Efe Gencer[7]的实习项目。 Kafka开发团队的许多成员都参加了头脑风暴,设计和评论。 Cruise Control还收到了来自LinkedIn的Kafka SRE团队的许多宝贵贡献和见解。
[1]https://kafka.apache.org
[2]https://github.com/linkedin/cruise-control
[3]https://www.youtube.com/watch?v=lf31udm9cYY
[4]https://github.com/jet/kafunk/wiki/Kafka-Crash-Cource
[5]https://github.com/linkedin/cruise-control/wiki/Build-the-cluster-workload-model
[6]https://engineering.linkedin.com/blog/2016/05/open-sourcing-kafka-monitor
[7]https://www.linkedin.com/in/efegencer/
[8]https://www.meetup.com/Stream-Processing-Meetup-LinkedIn/
[9]http://samza.apache.org
英文原文:https://engineering.linkedin.com/blog/2017/08/open-sourcing-kafka-cruise-control
本文作者 Jiangjie Qin,由 Jesse 翻译,转载译文请注明出处,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
推荐阅读
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号

