
- 1内容消费的膨胀时代,虚拟化身的进化与机遇
- 2angular 事件绑定/属性绑定 @HostListener ,@HostBinding
- 3【跳数组】 Python_如果能跳到数组
- 4全球首发鸿蒙系统(HarmonyOS2.0)开发环境搭建图文教程(DevEco Studio IDE 安装及设置)_deveco studio如何设置node.js
- 5多级多卡分布式训练时,报错 RuntimeError: Socket Timeout
- 6Linux下阻塞IO驱动实验实例二的测试
- 7HarmonyOS应用开发者基础认证【闯关习题 满分答案】_鸿蒙端云一体化最低api版本
- 8电商数据分析18——电商广告投放的数据分析与优化
- 9利用IP地址识别风险用户:保护网络安全的重要手段
- 10今日arXiv最热大模型论文:北大发布,通过上下文提示,让大模型学习一门新的语言
数据结构初级<排序>
赞
踩
本文已收录至《数据结构(C/C++语言)》专栏!
作者:ARMCSKGT
你的阅读和理解将是我极大的动力!
目录
前言
生活中需要排序得到结果的地方有很多,例如:购物时按商品销售量降序显示,班级的成绩排名,世界500强企业等等,我们在对这些数据进行排序时需要借助各种算法实现。
本章将介绍常见的八大排序:直接插入排序,希尔排序,选择排序,堆排序,选择排序,冒泡排序,快速排序,二路归并排序,计数排序。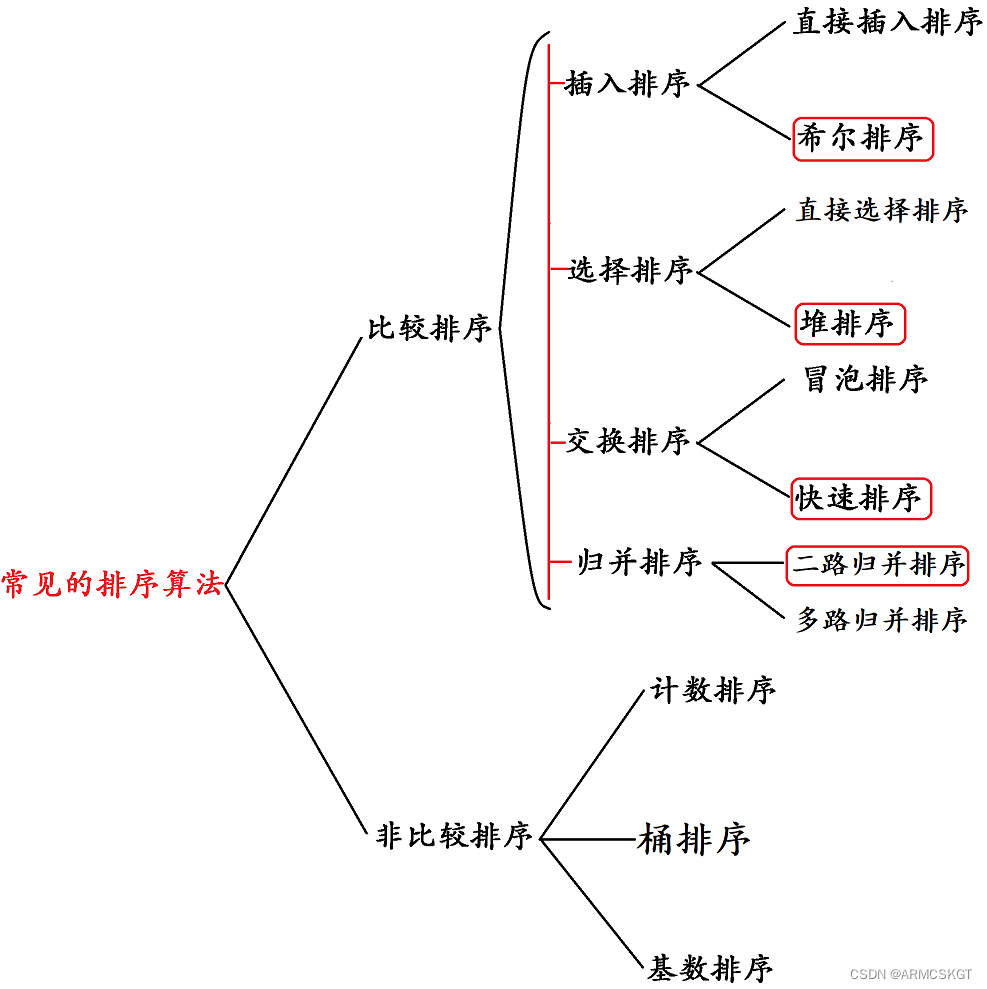
排序的概念
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次 序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排 序算法是稳定的;否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
常见排序简述
插入排序类:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为 止,得到一个新的有序序列 。
选择排序类:每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的 数据元素排完 。
交换排序类:所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排 序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
归并排序类:归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有 序,再使子序列段间有序。
正文
直接插入排序
原理
以升序为例,直接插入排序的原理是将序列中的第一个元素视为有序序列,随后将有序序列外的第一个元素插入到有序序列中的合适位置上,插入时与有序序列中最后一个元素进行比较,如果插入元素小于有序序列中的元素,则当前有序序列中的元素向后移动,然后插入元素继续与有序序列中的其他元素进行比较,直到插入元素大于有序序列中的元素时,将插入元素插入到该元素之后,这样就完成了一个元素的插入排序。依次这样插入所有元素就能完成直接插入排序。
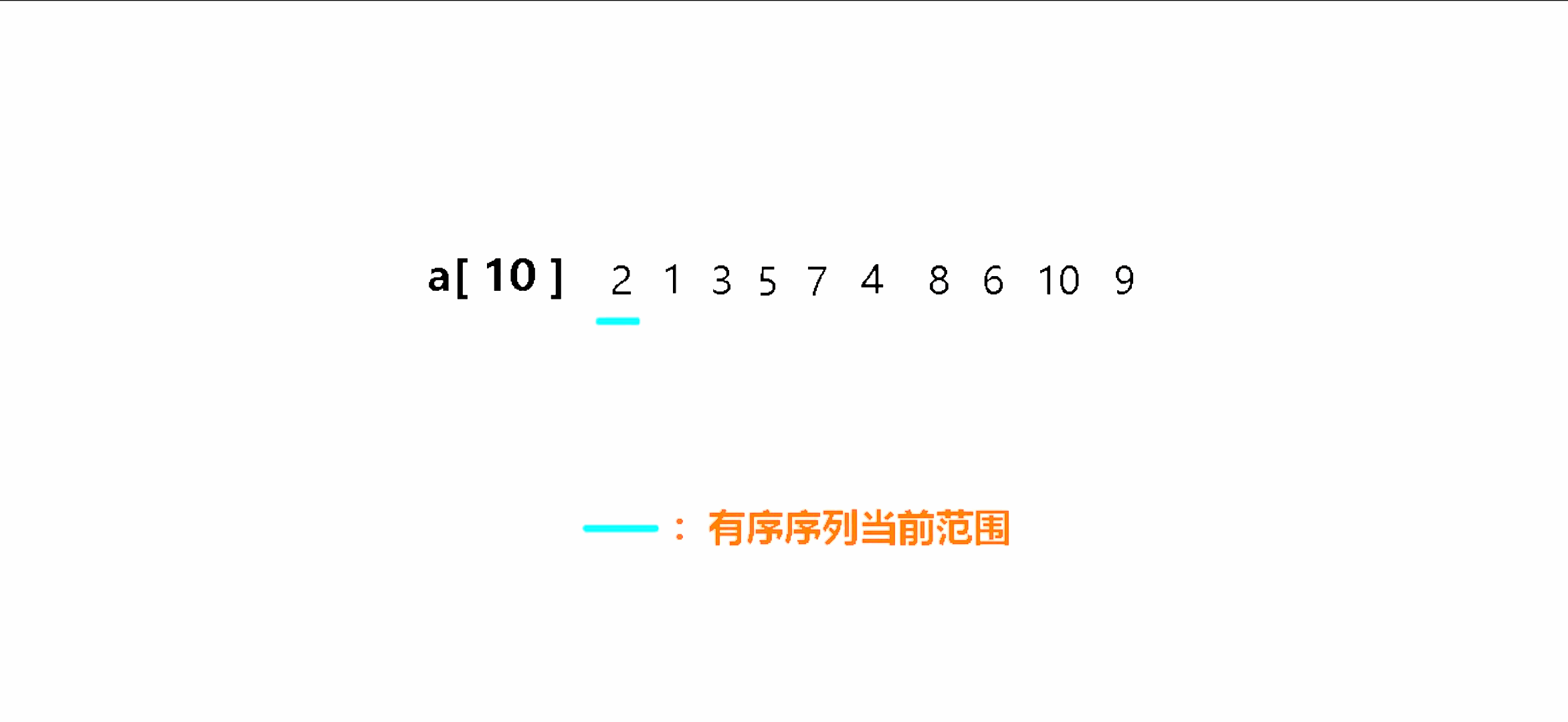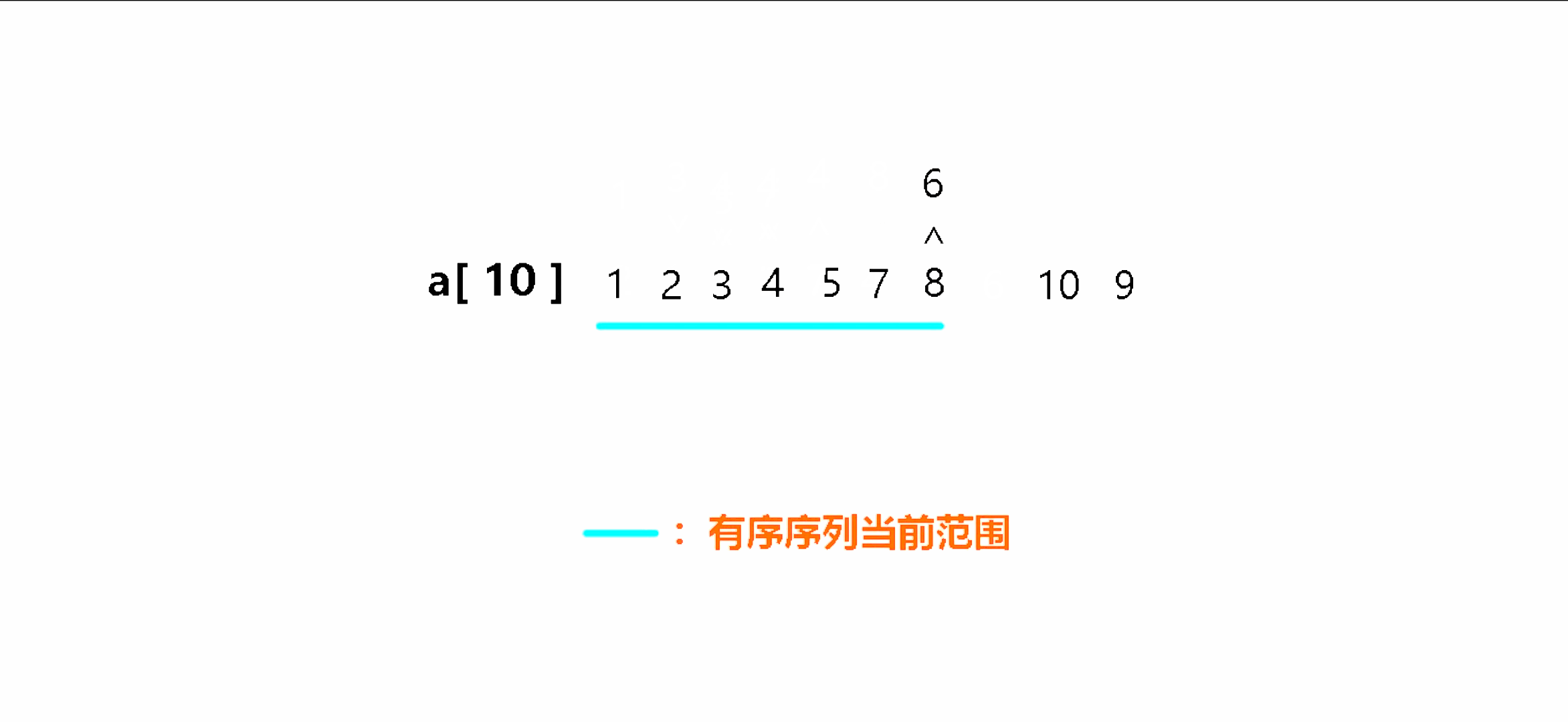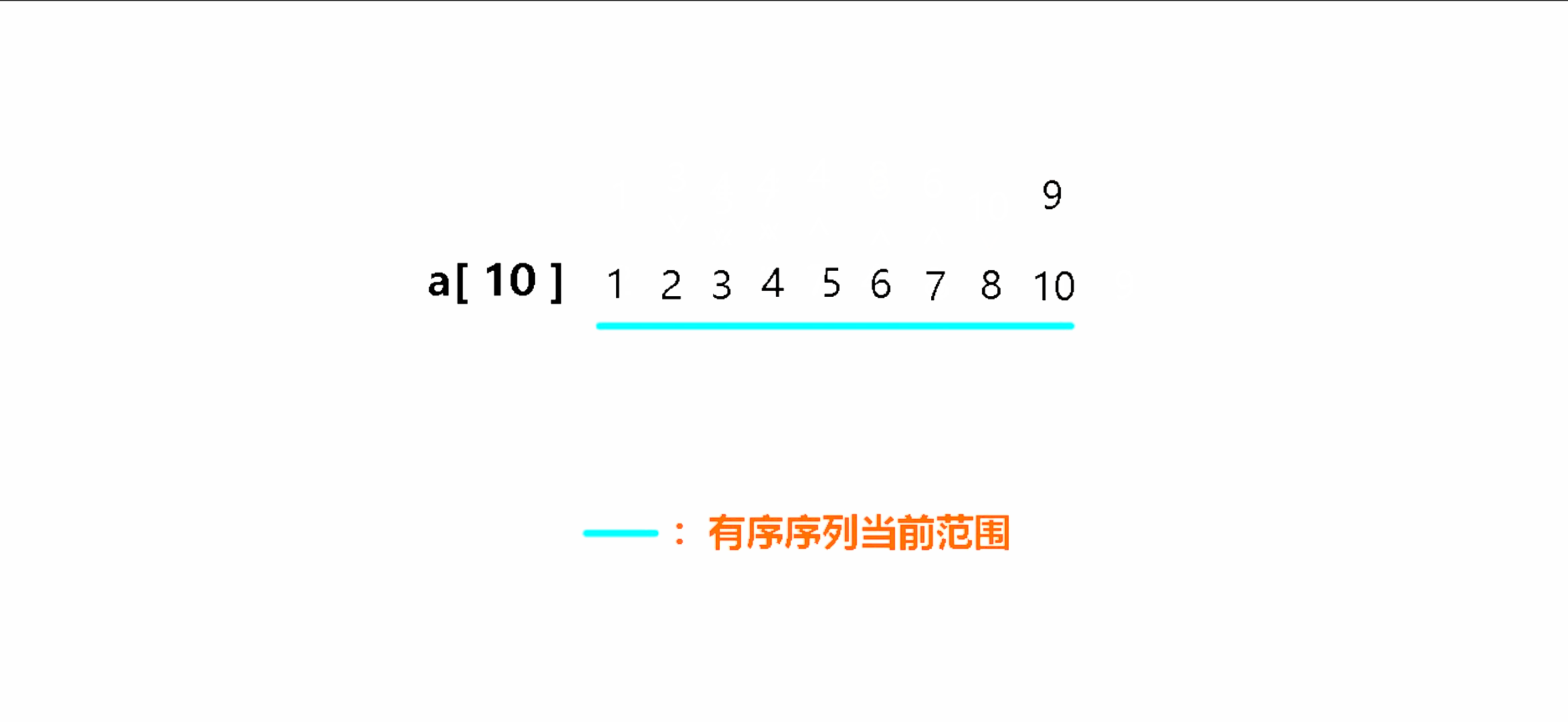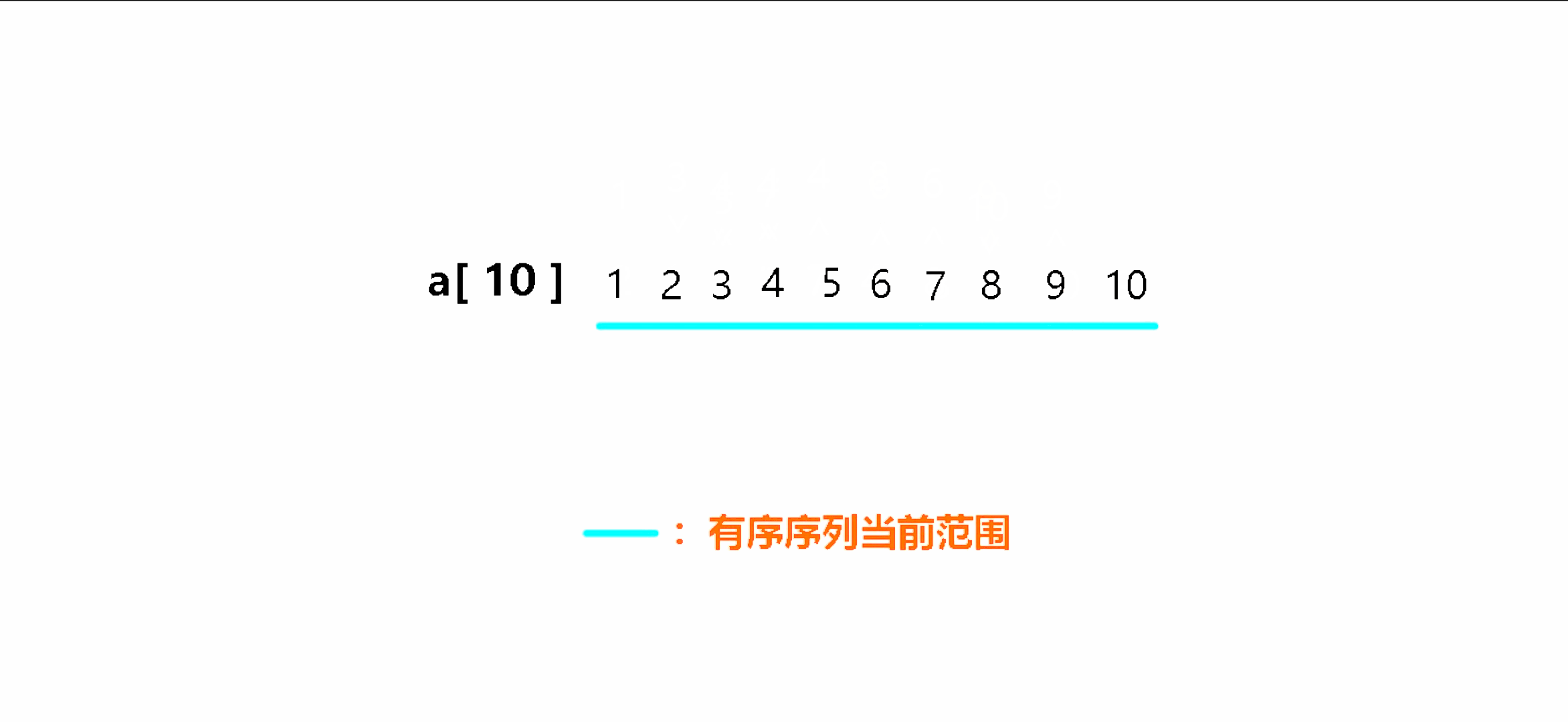
插入排序动图演示
代码实现
分析
1.时间复杂度:O(
)。
2.空间复杂度:O(1)。
3.稳定性:稳定。
4.综合总结:元素集合越接近有序,直接插入排序算法的时间效率越高。

希尔排序
原理
希尔排序是直接插入排序的优化,在直接插入排序的综合总结中我们说如果使用直接插入排序对接近有序的元素进行排序,那么效率将非常高,所以希尔排序在直接插入排序的基础上增加了预排序这个过程!
希尔排序分为两步(以升序为例):
1. 预排序
将相隔gap步的元素分为一组进行直接插入排序,让元素接近有序。在代码中有n个元素,如果数量庞大那么每次走3步太小了,为了效率最大化我们让gap=n,然后gap = gap/2,这样每次分组越来越小,元素就越来越接近有序。

希尔排序预排序分组 2. 直接插入排序
当预排序结束后,所得到的元素序列是解决有序的,这时使用直接插入排序进行最后的排序就能得到我们想要的排序序列。
希尔排序整体演示:
希尔排序动图演示
代码实现
分析
1.时间复杂度:O(
)。
2.空间复杂度:O(1)。
3.稳定性:不稳定。
4.综合总结:希尔排序是对直接插入排序的优化。当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。
直接选择排序
原理
直接选择排序,我们这里实现的原理是每次在区间中选出最大和最小的元素放在序列的两端,以升序为例,每一次找出当前序列的最大和最小元素,最大的元素与当前区间最尾端的元素交换,最小的元素与当前区间首端的元素交换,然后缩小区间,每一次找出最大最小放置并缩小区间这样就完成了直接选择排序。

直接选择排序动图演示
代码实现
分析
1.时间复杂度:O(
2.空间复杂度:O(1)。
3.稳定性:不稳定。
4.综合总结:直接选择排序思考非常好理解,但是效率不是很好,实际中很少使用。
堆排序
如果大家对 “堆” 这个数据结构有疑问可以先看看堆的介绍:数据结构初级<堆>CSDN博客
原理
首先原则是:排升序建大堆,排降序建小堆!
以升序为例,堆排序是先将数组中的元素按照堆的形式从最后一棵树开始进行向下调整建大堆,此时最大的都会在堆顶。将堆最末尾的节点与堆顶交换,最大的元素被放到了最末尾,然后对堆顶进行向下调整,选出次大的。
综合来说就是两步:
1. 根据序列建大堆。
2. 根节点依次与尾节点交换然后向下调整,每一趟调整之后序列范围减小。
第二步类似于弹夹中子弹上膛,弹出最大的放置在最末尾,这样就依次将大的放在最末尾了。

堆排序动图演示
代码实现
分析
1.时间复杂度:O(
)。
2.空间复杂度:O(1)。
3.稳定性:不稳定。
4.综合总结:堆排序使用堆来选数,效率就高了很多。
冒泡排序
原理
冒泡排序的原理,以升序为例,对比元素的下一个元素,如果比自己小则交换。每一趟排序都会将最大的放到最后,第二次排序时就不需要再与最后一个元素比较了,如果在一趟冒泡排序中没有进行任何交换表示序列有序,不需要排序了!
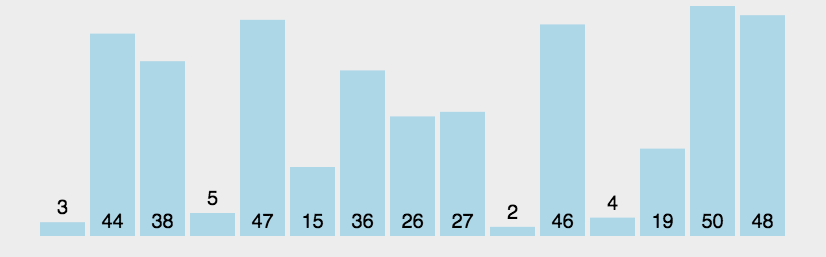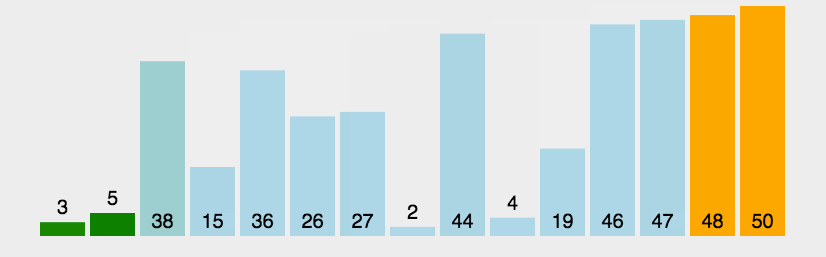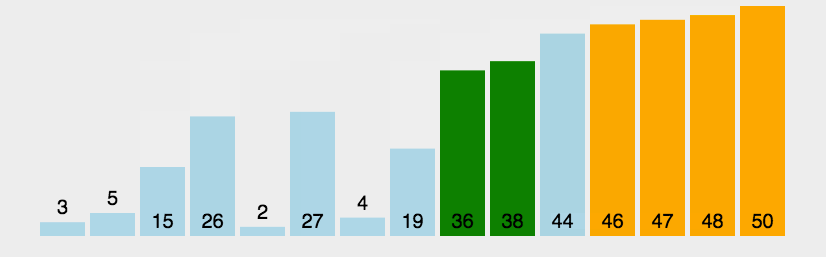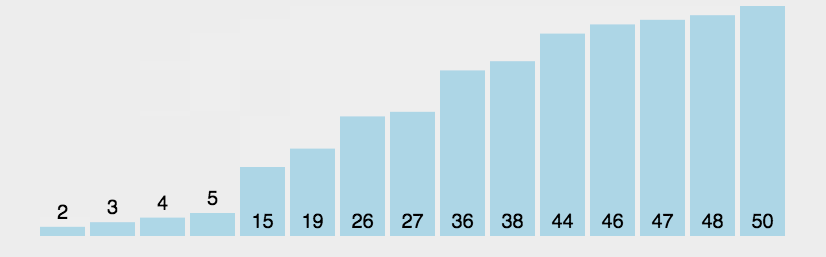
冒泡排序动图演示
代码实现
分析
1.时间复杂度:O(
2.空间复杂度:O(1)。
3.稳定性:稳定。
4.综合总结:冒泡排序是一种非常容易理解的排序,但效率不是很好。
快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中 的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右 子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
快速排序实现的三种方法
1. 霍尔法(Hoare)
以升序为例,霍尔法的思想是,先确定一个待调整元素下标key(一般是序列头元素),然后有两个变量head和end分别存储序列的头和序列尾的下标,然后开始调整序列,end开始向head移动寻找小于key下标的元素,如果找到了则head开始向序列尾移动寻找大于key下标的元素,当head下标下找到了比key大的,则交换head和end所指向下标的元素,重复以上的步骤直到head和end相遇则将我们选择的key放置在两指针相遇的下标位置下,这样key就放在了序列中属于他的正确位置(排序后key的位置上)完成了一趟排序,然后以key为分界线,分成了两个区间,[0,key下标-1],[key下标+1,n],这两个区间我们需要继续使用这种方法去确定每一个元素的正确位置,于是我们使用递归继续对两个区间进行排序,直到区间为1个元素时停止递归,直到所有区间全部排序完毕,霍尔法快排结束。
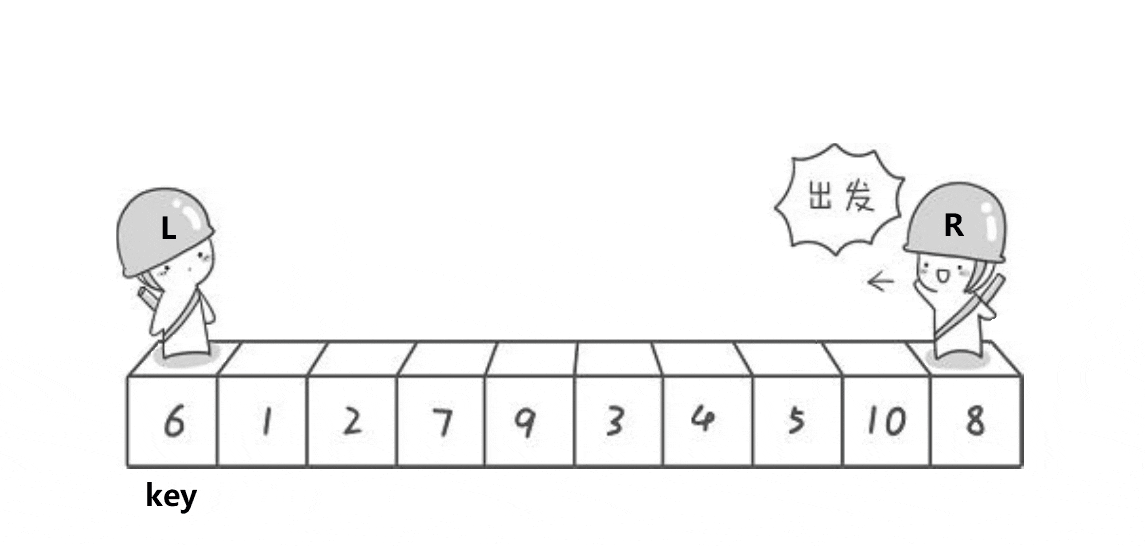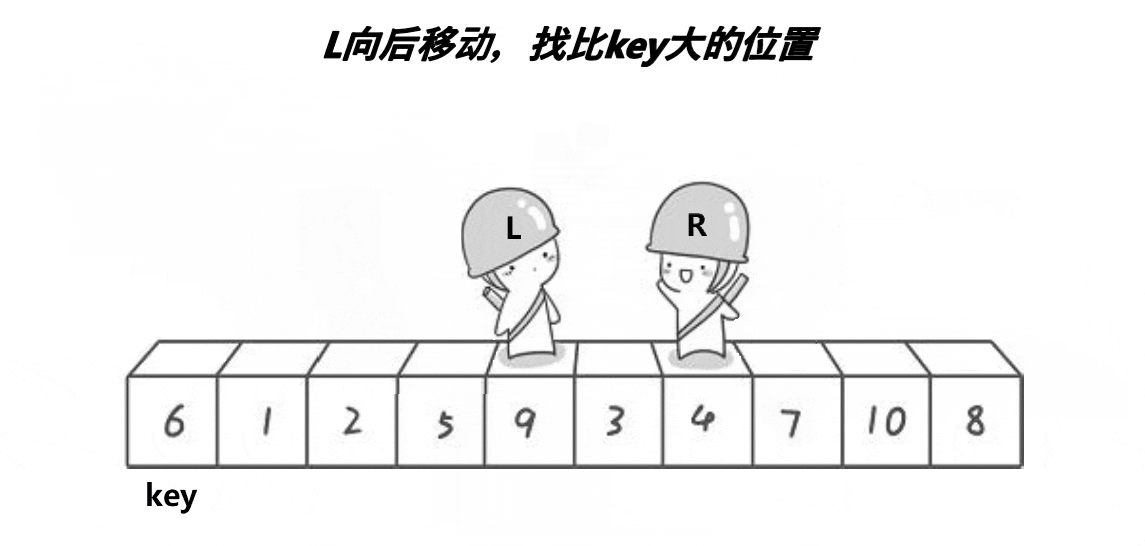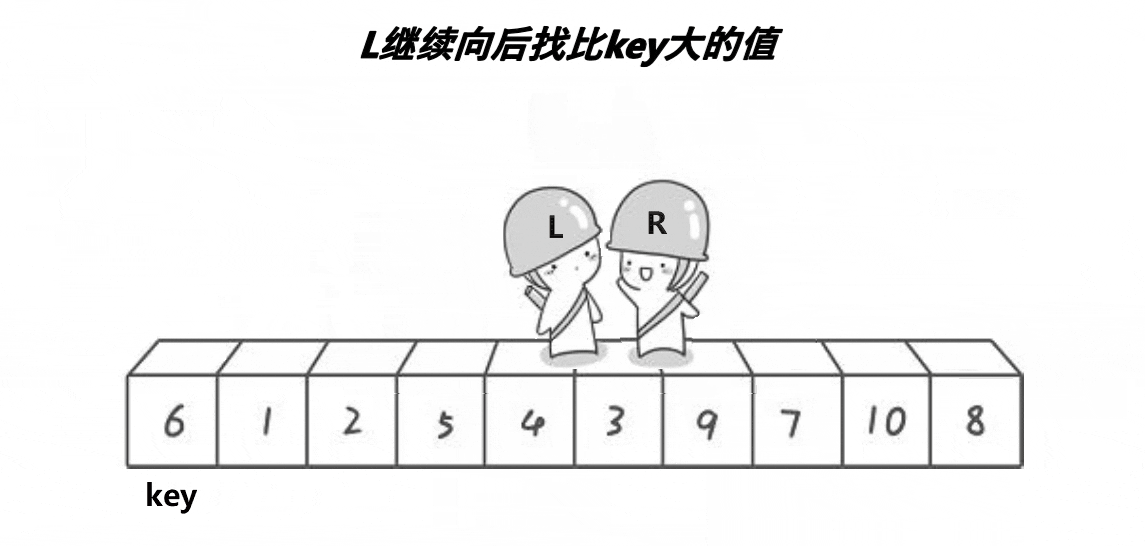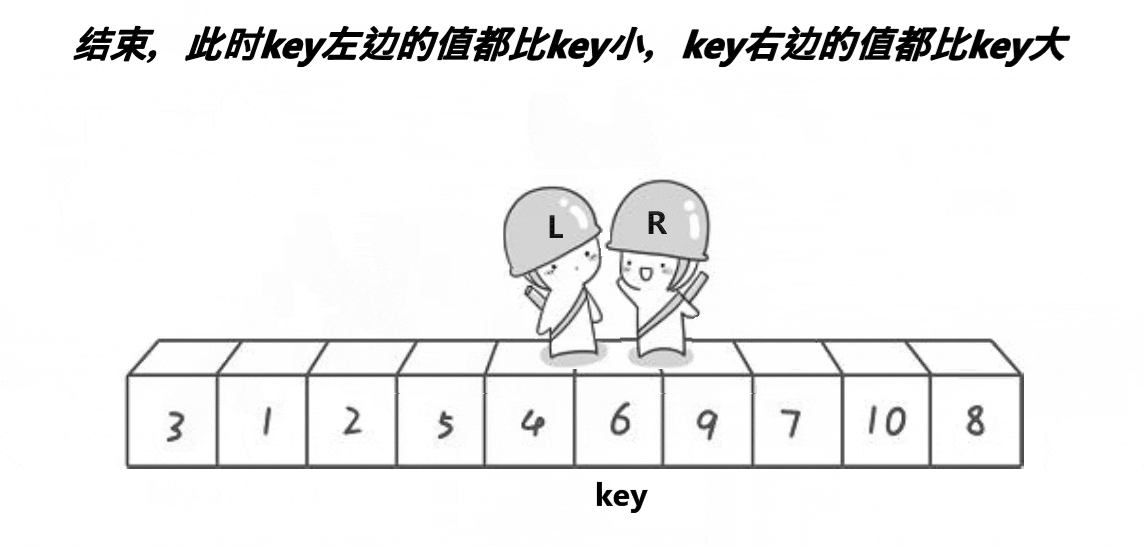
霍尔法快速排序动图演示
2. 挖坑法
挖坑法与霍尔法相似,以升序为例,先确定一个待调整元素key(一般是序列头元素),这样key元素的下标位置就空出来了(也就是坑位),然后定义两个变量存储序列的头尾下标和一个坑位指针hole记录当前坑位下标,接下来我们需要去找填坑的元素,end开始向head移动寻找比key小的元素,找到了就填到空出的坑位上,这样尾指针就空出了一个坑位,此时将尾指针下标赋值给hole记录当前坑位,接下来head开始向end移动找比key大的元素,找到了则填在当前的坑位中并就当前新的坑位下标赋值给hole,重复以上步骤直到head和end相遇则将key元素放在当前的坑位中,这样key就被放在了排序位上,也完成了一趟挖坑法排序。霍尔法和挖坑法每一趟单趟排序都会给key找到正确的排序位置并将所有小于key的放在可以左边,大于key的放在右边。挖坑法一趟排序也会分出两个区间,使用递归对剩下的区间进行排序,直到区间为一个元素时停止,这样就完成了挖坑法快速排序。
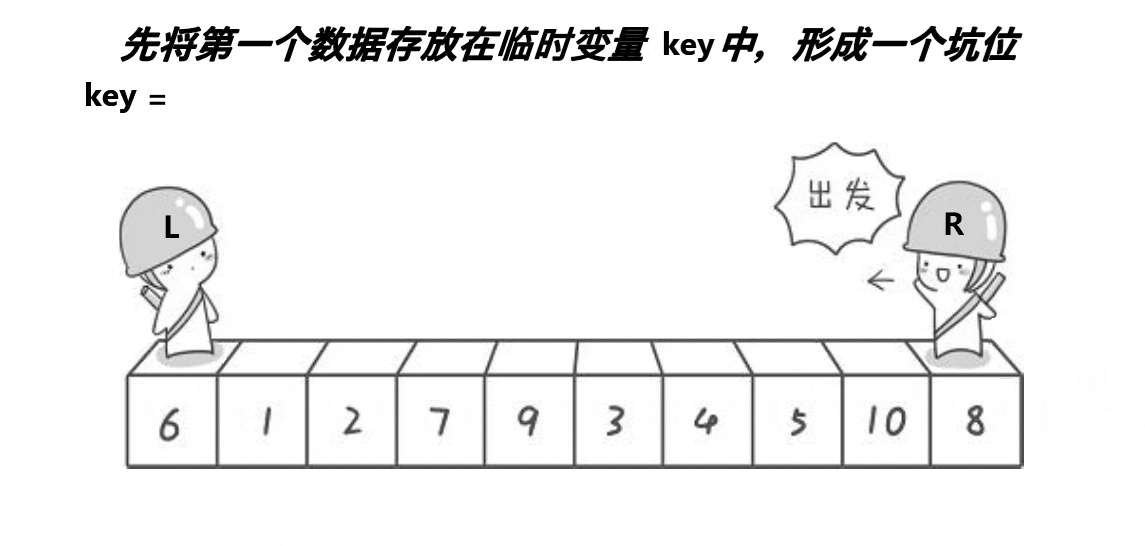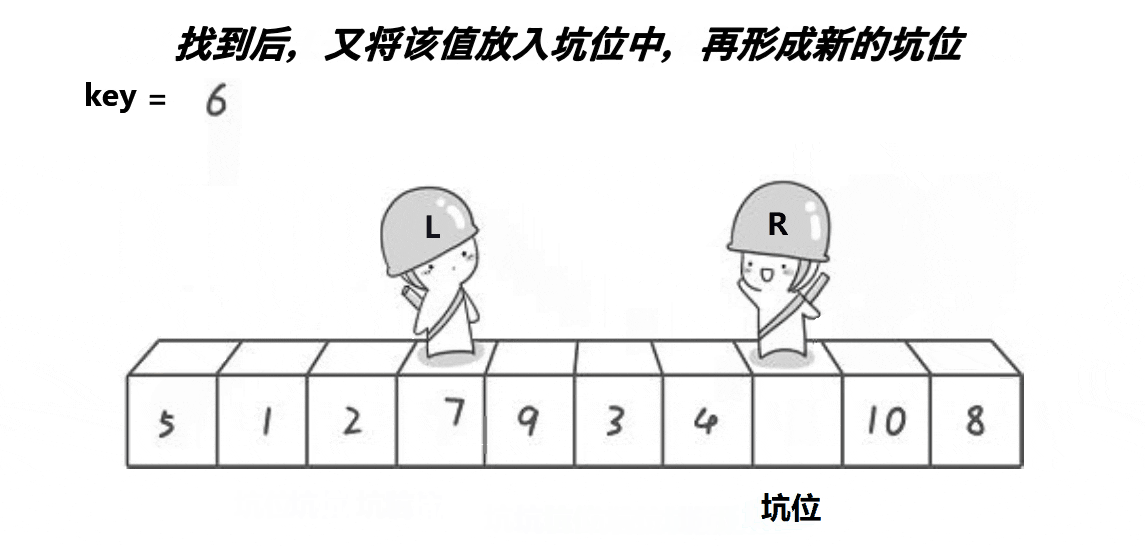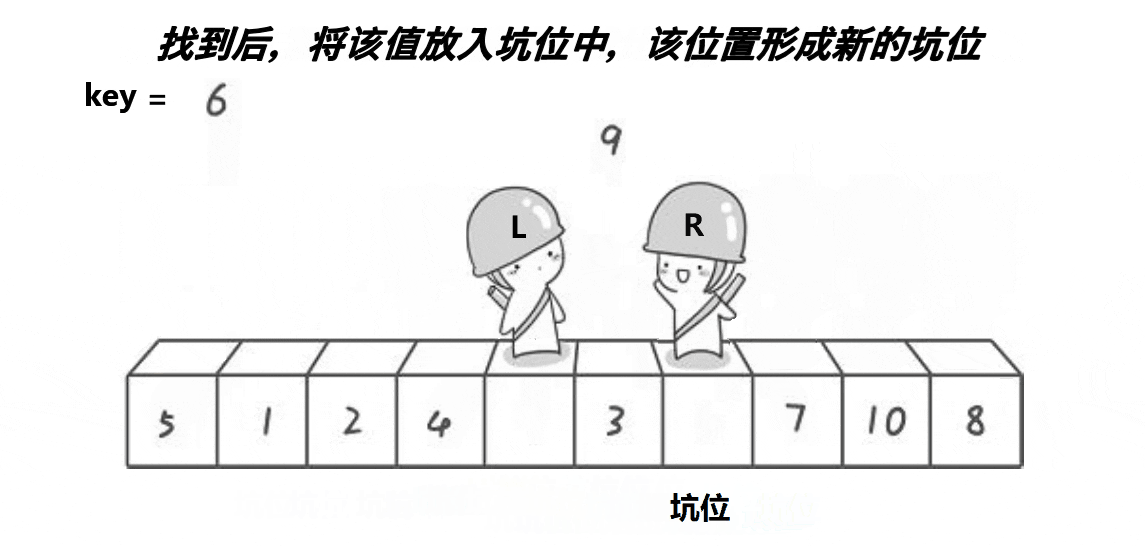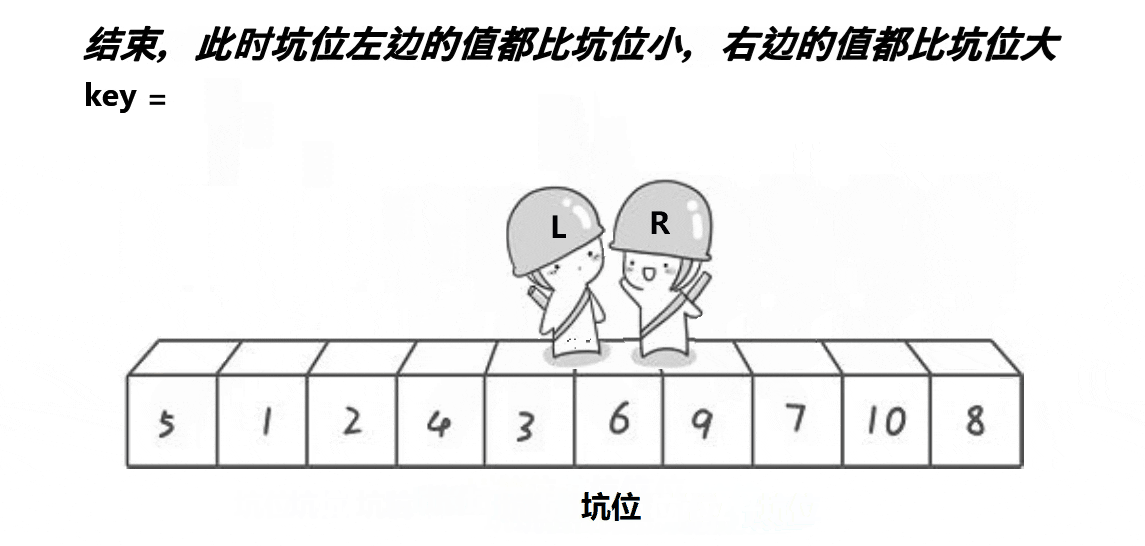
快速排序挖坑法动图演示
3. 前后指针法
以升序为例,前后指针法依然需要确定一个待调整元素下标key(一般是序列头元素),然后定义两个指针prev和cur来遍历序列,prev从序列头开始,而cur在prev的前一个位置上,接下来将cur下标下的元素与key下标元素比较,如果比cur大则cur向序列后移动,如果比key下标元素小则prev加1,如果prev与cur下标不同则将cur下标元素与prev下标元素交换,重复以上步骤直到cur走完了序列,将key下标元素与prev下标元素交换,这样就key下标元素就被放到了正确的位置上且key下标元素左边小于key下标元素,右边大于key下标元素,这样就完成了单趟排序且以key下标为分界线分出了两个区间,接下来使用递归对两个区间进行排序直到区间为一个元素时停止,就能完成快速排序前后指针法的排序。
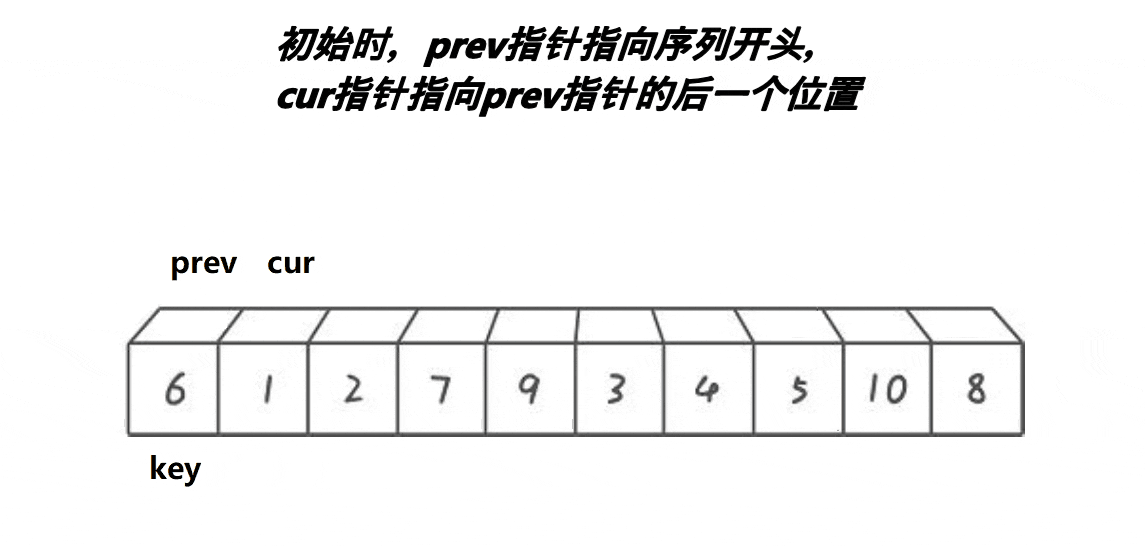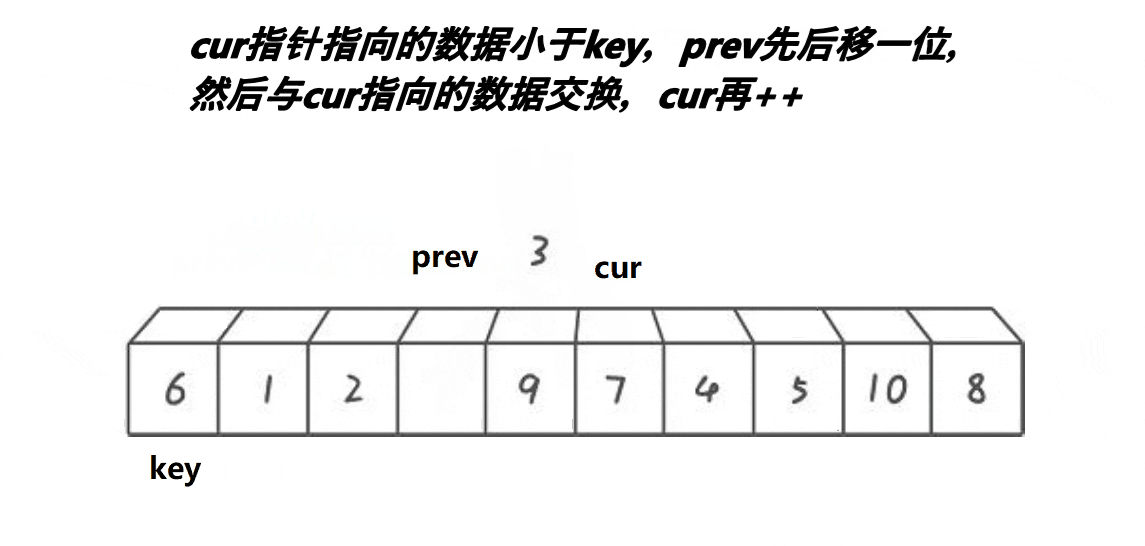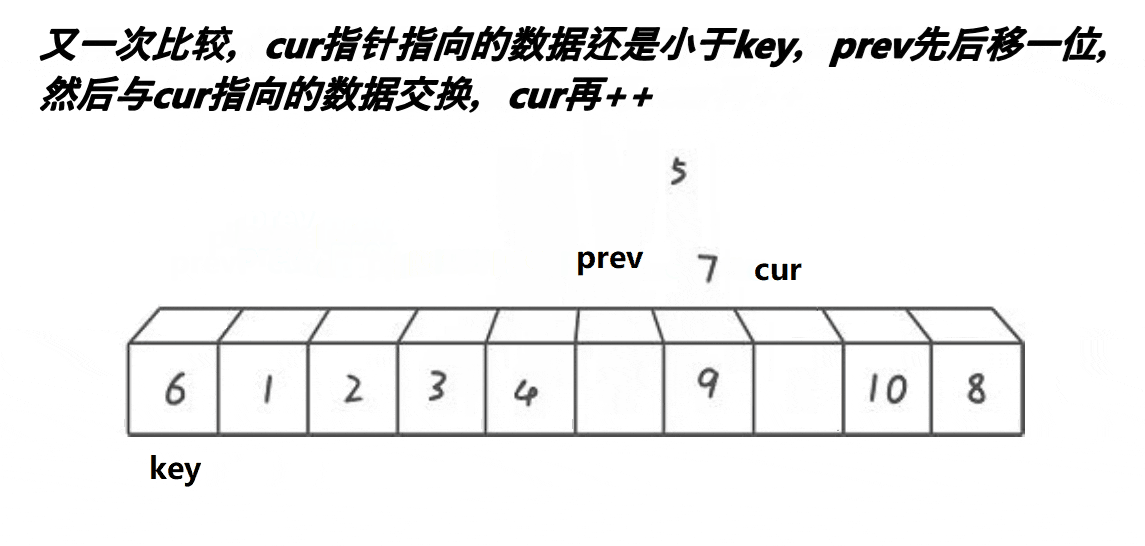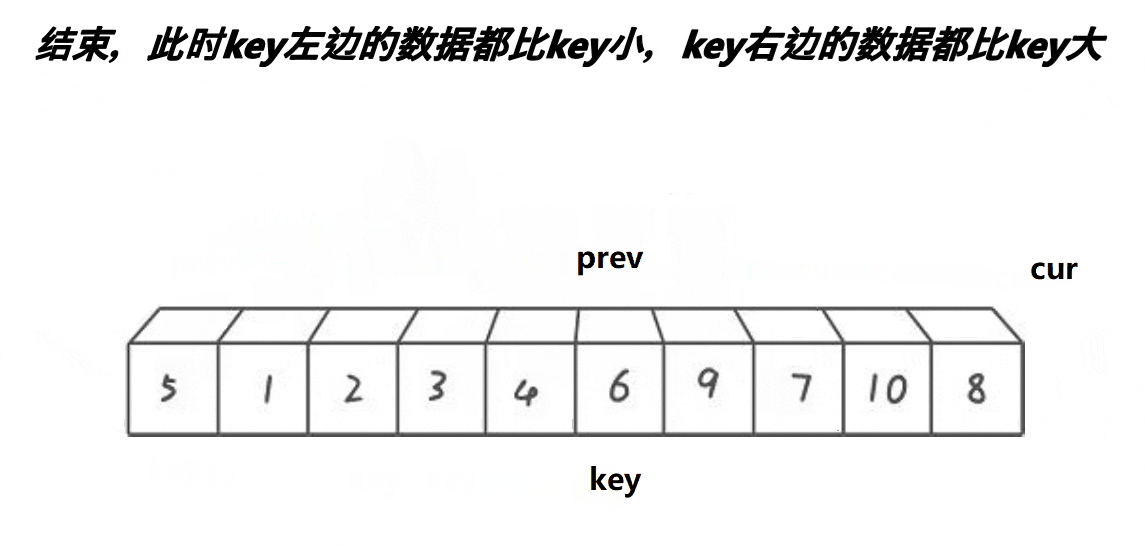
快速排序前后指针法动图演示
可以发现,前面介绍的三种方法的核心思路相似而且都是使用递归进行逐个排序,但是递归会出现一个问题就是栈溢出,于是我们将霍尔法的递归换位迭代,于是就有了迭代版快速排序,这里迭代版的快速排序需要借助栈来实现。
快速排序迭代版
迭代版快速排序借助栈来实现,栈有先进后出性质,我们细想递归的霍尔法快速排序,第一趟排序分出两个区间,然后继续对左区间进行排序,一直到区间中只有一个元素时停止开始调整右区间,那么每一次调整都会分出两个区间且先调整左区间再调整又区间,所以我们每次需要将右区间先入栈左区间后入栈,将一个区间的两个元素看作一个元素。
快速排序递归版流程:
1. 将序列头尾下标入栈(尾先入头后入)。
2. 栈元素出栈,头下标先出栈尾下标后出栈赋给left和right,且l和r变量再存储一次当前下标记录当前区间的大小。
3. 对出栈的区间进行霍尔法快速排序。
4. 单趟排序结束后产生两个区间,右区间先入栈,在入栈前判断右区间right+1是否小于当前区间的右区间r;左区间后入栈,在入栈前判断左区间left-1是否大于当前区间的左区间l。这样就成功将区间入栈。
5. 重复2-3步操作,直到栈空时表示所有元素已经排序成功。
对以上快排进行分析:
1.时间复杂度:O(
2.空间复杂度:O(
)。
3.稳定性:不稳定。
4.综合总结:以上排序的效率比较欠缺,需要进一步优化
快速排序最终优化版
优化一:小区间优化
在霍尔法的快速排序中,使用递归完成了所有排序,但是如果我们有一亿数据,那么以二叉树的思想,叶子节点将有5000万个,这些区间如果是小区间例如只有10个以下的数据进行排序,就要开5000万个函数栈帧,这是一个巨大的数据量代价太大了而且及容易栈溢出,这里我们使用直接插入排序解决,当区间为10个数据以下时调用直接插入排序函数进行排序,虽然直接插入排序的时间复杂度为O(
优化二:三数取中
对于一些相对排序要求来说逆序的序列,那么霍尔法的效率会极大的降低甚至时间复杂度将为O(
三数取中的原理是在数组中取端点上的两值以及通过序列的头尾下标求出序列中间元素下标的位置,然后在这三个数中取一个不是最大也不是最小的数作为key。
对于某些OJ题目,可能针对三数取中优化来进行设计测试用例,这里我们可以针对其进行优化,不再只取中间序列,而是随机取下标进行三数取中,这样就能防止测试用例搞事情!
将int mid = (head + end) / 2;
替换为
srand((unsigned int)time(NULL));
int mid = head+rand()%(end-head);即可!
优化三:三段划分
在排序中,我们可能会碰到有相同值排序的情况,这样会导致重复操作的出现而导致性能下降。于是我们使用三段划分解决这个问题。三段划分就是将比key小的放在key的左边,比key大的放在右边,而与key相等的则放在中间。
三段划分的思想是:
1. 定义三个变量分别为left控制左边界(序列头)、right控制右边界(序列尾)、cur遍历序列。
2. 判断当前 cur处值是否大于 key,大于就将其与right处的值交换,然后right-1向left靠近。然后再判断cur是否小于 key,小于就与 left交换,此时left++向right靠近。如果cur等于 key,此时将cur处的值划入中段,不需要交换,此时直接cur++就行了。
3. 当以上判断完并执行相应操作后cur+1向序列尾移动,因为cur一开始是在序列头的下一个,left动,cur也要跟着动,不然它就被覆盖了。
4. 重复2-3步,直到 cur超出当前序列尾的下标right,显然此时有三条路,[head,left]、[left+1,right-1]、[right,end] 这就是三路划分。再对[head,left]和[right,end]进行递归排序即可。
快速排序最终优化版代码:
分析
快速排序最终优化版分析:
1.时间复杂度:O(
2.空间复杂度:O(
3.稳定性:不稳定。
4.综合总结:对于优化后的快速排序才是真正的快速排序,快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序。
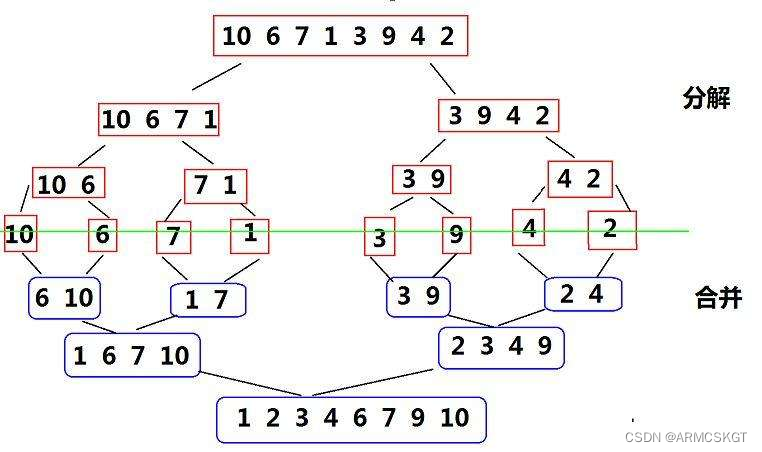
二路归并排序
二路归并:将两个有序表合并成一个有序表,称为二路归并。
二路归并排序思想类似于二叉树的后序遍历,先将区间对半分开直到区间为一个元素时停止递归,开始回归进行排序,排序时合并两个有序序列。
二路归并排序动图演示
二路归并排序递归版
代码思路:在开始排序之前,归并排序函数需要一个数组tmp作为临时排序数组,定义一个mid变量将序列头尾下标head和end相加除2得到中间下标,于是就分为了两个区间,[head,mid],[mid+1,end],对这个区间继续以以上方式递归分解,直到分为一个数元素区间时停止开始归并排序,此时有两个区间,分别由left1和right1以及left2和right2来接收,然后开始合并两个区间,两有序区间从left1和left2开始比较,如果left1下标下的元素小则先放在tmp数组上,然后tmp数组指针 i 指向下一个位置,然后继续比较,直到一个序列走完或者两个序列全部走完。此时我们并不知道两个序列是否都走完,使用两个while循环判断,如果有序列没有走完则将序列上的元素依次拷贝到tmp数组上,两个区间合并完成使用memcpy拷贝到原序列的指定区间上即可!
二路归并排序迭代版
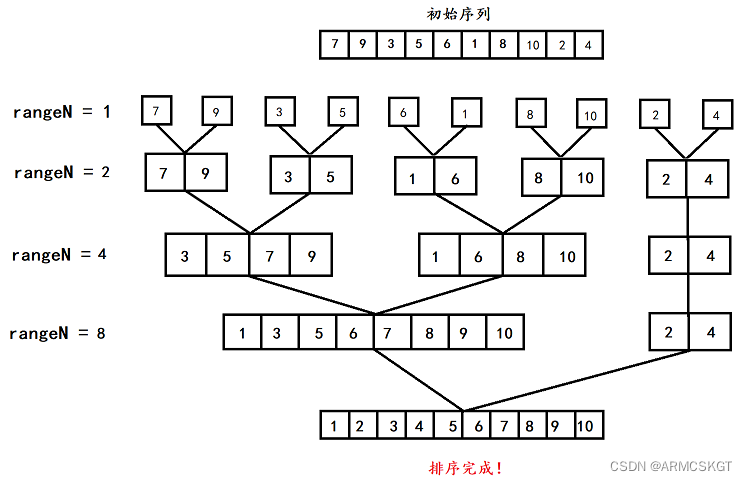
二路归并虽然有递归,但是迭代版却不需要借助其他数据结构,只需要定义一个rangeN,这个rangeN记录的是当前每个区间所含元素的个数,默认从1开始。将rangeN套入循环中控制每一次归并每个区间所含元素个数,每一次合并完序列后rangeN*2这样就能合理控制每一次调整的区间,直到rangeN等于元素个数时归并排序就完成了。
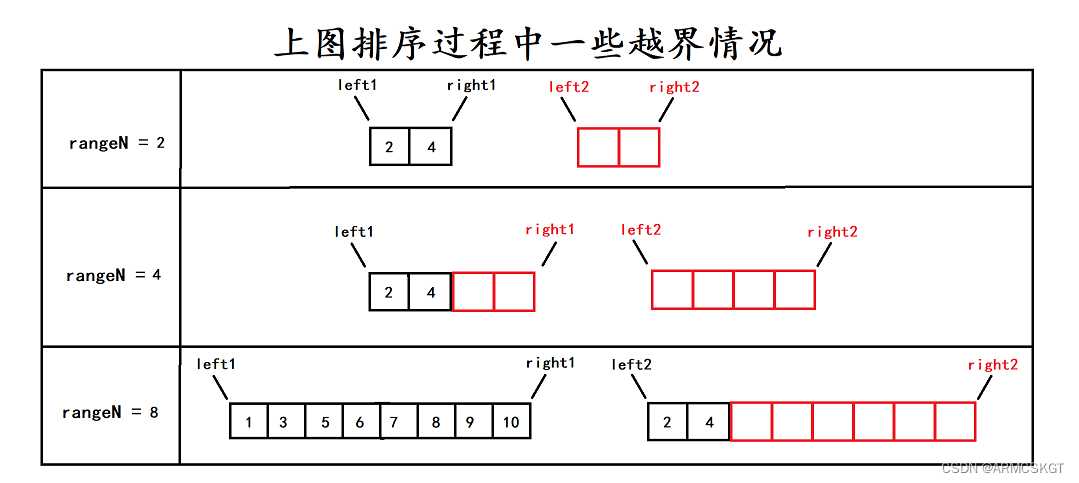
此时还有两个问题,第一个是迭代有很严重的边界越界问题,第二个是归并排序既可以单趟归并完两序列就将tmp数组拷贝到原序列,也可以全部归并完再拷贝回去。
1. 对于每合并两个区间就将tmp拷贝回原序列
我们对越界问题采用的方法是直接跳出,如果right1和left2越界那么本次就不需要归并了,如果是最右区间right2越界则进行修正。这样对于每合并两个序列就拷贝的归并排序是可以有效避免越界的。
2. 对于合并完所有区间在拷贝tmp到原序列
对于这种情况,我们采用的是修正和销毁区间,如果是right1越界则修正right1为当前区间的最大下标且销毁left2和right2区间,如果三叔left2越界则也是销毁left2和right2区间,如果是right2越界则修正right2为当前区间的最大下标。这样对于归并所有序列再拷贝的情况是可以有效避免越界的。
分析
1.时间复杂度:O(
2.空间复杂度:O(N)。
3.稳定性:稳定。
4.综合总结:归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
计数排序
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。其核心思想是映射到数组。
原理
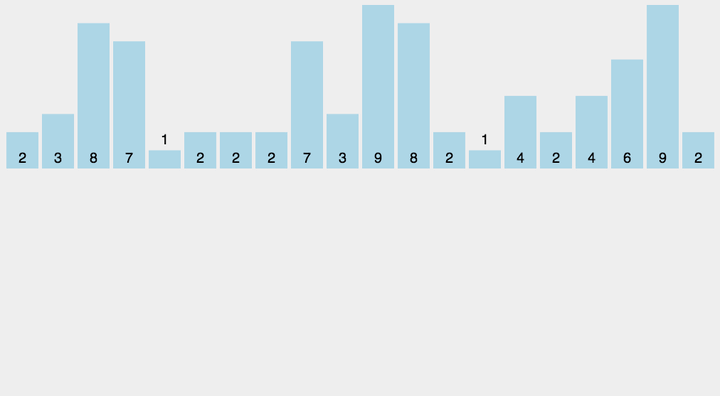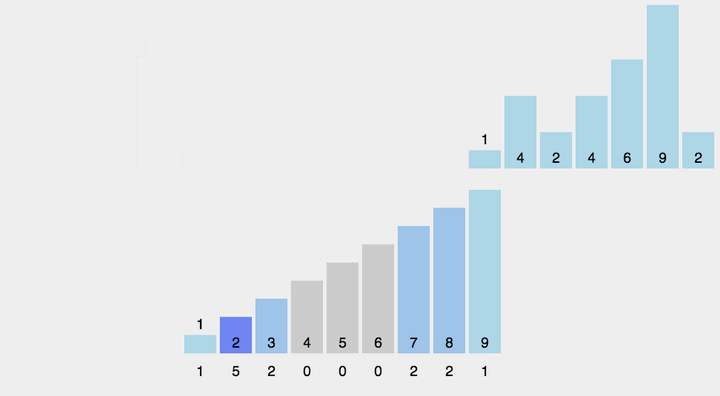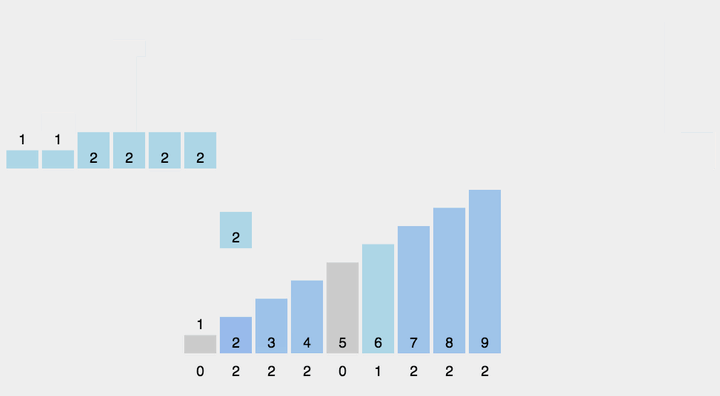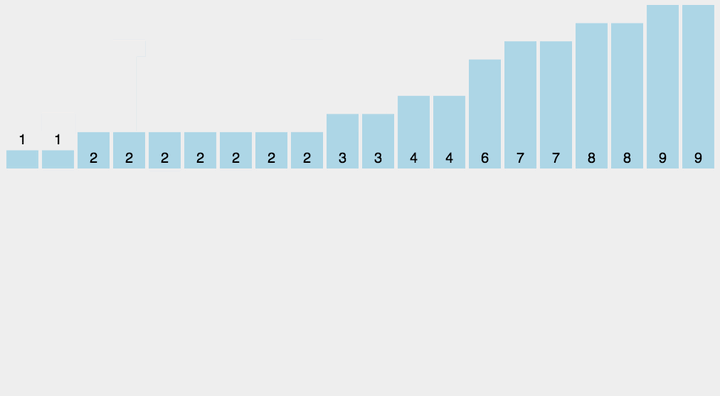
1. 元素计数:找出待排序的数组中最大和最小的元素,开辟所需大小的辅助空间数组,统计相同元素出现次数,将其映射到有序辅助数组上并对所有的计数累加。
2. 反向填充目标数组:根据统计的结果将序列回收到原来的序列中,因为数组是有序的,所有通过计算输出到序列上的元素也会程有序排列,每放置一个到原序列上对于下标就减一直到该下标放置完毕。
计数排序动图演示
代码实现
分析
1.时间复杂度:O(N+range(序列最大最小值之差的范围))。
2.空间复杂度:O(range)。
3.稳定性:不稳定。
4.综合总结:计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
总结
排序算法 时间复杂度 空间复杂度 稳定性 用于内/外部排序 直接插入排序 O(
O(1) 稳定 内部排序 希尔排序 O(
O(1) 不稳定 内部排序 选择排序 O( O(1) 不稳定 内部排序 堆排序 O( )
O(1) 不稳定 内部排序 冒泡排序 O(
O(1) 稳定 内部排序 快速排序优化版 O(
O(
不稳定 内部排序 归并排序 O(
O(N) 稳定 内/外部排序 计数排序 O(N+范围) O(范围) 不稳定 内部排序
最后
排序算法有很多种,本次我们介绍了八种排序,这八种排序我们既要了解简单的,也要学习高效复杂的,在八大排序算法中,堆排序,快速排序和,归并排序和希尔排序是效率比较高的,其中快速排序在C语言库中以qsort函数的方式调用,可见快速排序的效率非常高。
本次排序算法的基本知识就介绍到这里啦,希望能够尽可能帮助到大家。
如果文章中有瑕疵,还请各位大佬细心点评和留言,我将立即修补错误,谢谢!
博客中的所有代码合集:排序博客代码

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/240980?site

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

