
- 1融合搜索:开发指导
- 2android httpurlconnection https,HttpUrlConnection中url写http不行,使用https可以
- 3网络通信详细过程(通过浏览器访问百度)_udp走域名需要先获取域名的ip吗
- 4Unity3D 常用得内置函数(Cg与GLSL)详解
- 5Linux是对用户的密码的复杂度要求设置【转】
- 6linux检查密码的复杂性强度,如何在 Linux 中检查密码的复杂性/强度和评分? | Linux 中国...
- 7【算法分析与设计】跳跃游戏_给一个正整数列 nums,一个跳数 jump,及幸存数量
- 8Node-Red系列教程——NodeRed通过OPC UA读取数据并写入mysql_node-red-contrib-opcua
- 9ConstraintLayout 完全解析 快来优化你的布局吧
- 10linux系统10个最常用命令,Linux操作系统10条最常用的基础操作命令
提高训练效果的方法--Bag of Tricks for Image Classification with Convolutional Neural Networks 论文笔记_bag of tricks for training deeper graph neural net
赞
踩
Bag of Tricks for Image Classification with Convolutional Neural Networks论文解读
Abstract
Much of the recent progress made in image classification research can be credited to training procedure refinements, such as changes in data augmentations and optimization methods. In the literature, however, most refinements are either briefly mentioned as implementation details or only visible in source code.In this paper, we will examine a collection of such refinements and empirically evaluate their impact on the final model accuracy through ablation study. We will show that, by combining these refinements together, we are able to improve various CNN models significantly. For example, we raise ResNet-50’s top-1 validation accuracy from 75.3% to 79.29% on ImageNet. We will also demonstrate that improvement on image classification accuracyleads to better transfer learning performance in other application domains such as object detection and semantic segmentation.
通过将这些改进结合在一起,我们能够显著改进CNN的各种模型。例如,我们在ImageNet上将ResNet-50的前1名验证准确率从75.3%提高到79.29%。我们还将证明,图像分类精度的提高会在其他应用领域(如对象检测和语义分割)带来更好的迁移学习性能。
Introduction
Our empirical evaluation shows that several tricks lead to significant accuracy improvement and combining them together can further boost the model accuracy. We compare ResNet-50, after applying all tricks, to other related networks in Table 1. Note that these tricks raises ResNet50’s top-1 validation accuracy from 75.3% to 79.29% on ImageNet. It also outperforms other newer and improved network architectures, such as SE-ResNeXt-50.
经验评估表明,几种技巧可以显著提高精度,将它们结合在一起可以进一步提高模型的精度。在应用所有技巧后,我们将ResNet-50与表1中的其他相关网络进行了比较。请注意,这些技巧将ResNet50在ImageNet上的前1名验证准确率从75.3%提高到79.29%。它还优于其他更新和改进的网络架构,如SE-ResNeXt-50。

Training Procedures
以算法一作为基线进行训练:

预处理方法:
- Randomly sample an image and decode it into 32-bit floating point raw pixel values in [0,255].
- Randomly crop a rectangular region whose aspect ratio is randomly sampled in [3/4,4/3] and area randomly sampled in [8%,100%], then resize the cropped region into a 224-by-224 square image.
- Flip horizontally with 0.5 probability.
- Scale hue, saturation, and brightness with coefficients uniformly drawn from [0.6,1.4].
- Add PCA noise with a coefficient sampled from a normal distribution N(0,0.1).
- Normalize RGB channels by subtracting 123.68,116.779, 103.939 and dividing by 58.393, 57.12,
57.375, respectively.
During validation, we resize each image’s shorter edge to 256 pixels while keeping its aspect ratio. Next, we crop out the 224-by-224 region in the center and normalize RGB channels similar to training. We do not perform any random augmentations during validation.
1.随机采样图像,并将其解码为[0,255]中的32位浮点原始像素值。
2.随机裁剪长宽比为[3/4,4/3]和面积比为[8%,100%]的矩形区域,然后将裁剪后的区域调整为224×224的正方形图像。
3.以0.5的概率水平翻转。
4.用从[0.6,1.4]中均匀抽取的系数来缩放色调、饱和度和亮度。
5.用从正态分布N(0,0.1)采样的系数添加主成分分析噪声。
6.通过分别减去123.68、116.779、103.939和除以58.393、57.12、57.375来归一化RGB通道
在验证过程中,我们将每个图像的短边调整到256像素,同时保持其纵横比。接下来,我们在中心裁剪出224乘224的区域,并像训练一样对RGB通道进行归一化。在验证过程中,我们不执行任何随机扩增。
The weights of both convolutional and fully-connected layers are initialized with the Xavier algorithm [6]. In particular, we set the parameter to random values uniformly drawn from [−a, a], where a =p6/(din+ dout). Here dinand doutare the input and output channel sizes, respectively. All biases are initialized to 0. For batch normalization layers, γ vectors are initialized to 1 and β vectors to 0.
使用Xavier对卷积层和全连接层进行权重初始化,并且从【-a,a】,a=sqrt(6/(din+ dout)),din和dout分别表示输入和输出通道大小,b设置为0,对于批量标准化层,γ向量初始化为1,β向量初始化为0。
Nesterov Accelerated Gradient (NAG) descent [20] is used for training. Each model is trained for 120 epochs on 8 Nvidia V100 GPUs with a total batch size of 256. The learning rate is initialized to 0.1 and divided by 10 at the 30th, 60th, and 90th epochs.
使用NAG进行梯度下降,训练120个时期,总批量为256,学习了被初始化为0.1,在30,60,90个时期的时候除以10。
与参考文献的差距
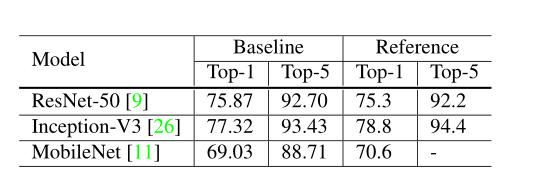
Efficient Training
Hardware, especially GPUs, has been rapidly evolving in recent years. As a result, the optimal choices for many performance related trade-offs have changed. For example, it is now more efficient to use lower numerical precision and larger batch sizes during training. In this section, we review various techniques that enable low precision and large batch training without sacrificing model accuracy. Some techniques can even improve both accuracy and training speed.
硬件,尤其是GPU,近年来发展迅速。因此,许多与性能相关的权衡的最佳选择已经改变。例如,现在在训练过程中使用较低的数值精度和较大的批量更有效。在本节中,我们将回顾各种技术,这些技术能够在不牺牲模型精度的情况下实现低精度和大批量训练。有些技术甚至可以提高准确性和训练速度。
In other words, for the same number of epochs, training with a large batch size results in a model with degraded validation accuracy compared to the ones trained with smaller batch sizes
相同的epoch下,与用较小批量训练的模型相比,用较大批量训练导致模型的验证精度降低。
Linear scaling learning rate. In mini-batch SGD, gradient descending is a random process because the examples are randomly selected in each batch. Increasing the batch size does not change the expectation of the stochastic gradient but reduces its variance. In other words, a large batch size reduces the noise in the gradient, so we may increase the learning rate to make a larger progress along the opposite of the gradient direction. Goyal et al. [7] reports that linearly increasing the learning rate with the batch size works empirically for ResNet-50 training. In particular, if we follow He et al. [9] to choose 0.1 as the initial learning rate for batch size 256, then when changing to a larger batch size b, we will increase the initial learning rate to 0.1 × b/256.
随着batch size的线性增加来增加学习速率,对网络有经验作用,选择0.1作为批量大小256的初始学习率,那么当改变到更大的批量大小b时,我们将把初始学习率提高到0.1 × b/256。
Learning rate warmup. At the beginning of the training, all parameters are typically random values and therefore far away from the final solution. Using a too large learning rate may result in numerical instability. In the warmup heuristic, we use a small learning rate at the beginning and then switch back to the initial learning rate when the training process is stable [9]. Goyal et al. [7] proposes a gradual warmup strategy that increases the learning rate from 0 to the initial learning rate linearly. In other words, assume we will use the first m batches (e.g. 5 data epochs) to warm up, and the initial learning rate is η, then at batch i, 1 ≤ i ≤ m, we will set the learning rate to be iη/m.
由于一开始使用过大的学习速率可能会导致数值不稳定,因此采用预热策略,将学习率随着训练周期线性增加到初始学习率,也就是:假设我们将使用前m个批次(例如5个数据时期)来预热,并且初始学习速率是η,那么在批次i,1 ≤ i ≤ m,我们将学习速i率设置为iη/m。
Zero γ. A ResNet network consists of multiple residual blocks, each block consists of several convolutional layers. Given input x, assume block(x) is the output for the last layer in the block, this residual block then outputs x + block(x). Note that the last layer of a block could be a batch normalization (BN) layer. The BN layer first standardizes its input, denoted by ˆ x, and then performs a scale transformation γˆ x + β. Both γ and β are learnable parameters whose elements are initialized to 1s and 0s, respectively. In the zero γ initialization heuristic, we initialize γ = 0 for all BN layers that sit at the end of a residual block. Therefore, all residual blocks just return their inputs, mimics network that has less number of layers and is easier to rain at the initial stage.
普通的BN初始化,γ=1,β=0,残差块末端BN的γ=0,β=0。
No bias decay. The weight decay is often applied to all learnable parameters including both weights and bias. It’s equivalent to applying an L2 regularization to all parameters to drive their values towards 0. As pointed out by Jia et al. [14], however, it’s recommended to only apply the regularization to weights to avoid overfitting. The no bias decay heuristic follows this recommendation, it only applies the weight decay to the weights in convolution and fullyconnected layers. Other parameters, including the biases and γ and β in BN layers, are left unregularized.Note that LARS [4] offers layer-wise adaptive learning rate and is reported to be effective for extremely large batch sizes (beyond 16K). While in this paper we limit ourselves to methods that are sufficient for single machine training, in which case a batch size no more than 2K often leads to good system efficiency.
对bias偏置值不进行偏置值衰减,仅仅对权重值w进行衰减。
Low-precision training
Despite the performance benefit, a reduced precision has a narrower range that makes results more likely to be out-ofrange and then disturb the training progress. Micikevicius et al. [19] proposes to store all parameters and activations in FP16 and use FP16 to compute gradients. At the same time, all parameters have an copy in FP32 for parameter updating. In addition, multiplying a scalar to the loss to better align the range of the gradient into FP16 is also a practical solution.
将所有参数的精度设置为FP16,同时,这些参数会复制一份FP32的精度用于参数更新,这种情况下,有可能会导致结果受到影响,因此可以使用一个标量值乘以loss的方法来与FP16的梯度范围对齐,解决结果影响的问题
Experiment Results
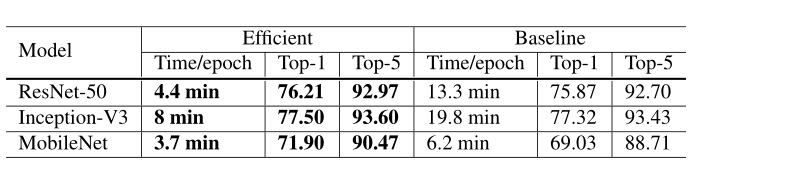

The evaluation results for ResNet-50 are shown in Table 3. Compared to the baseline with batch size 256 and FP32, using a larger 1024 batch size and FP16 reduces the training time for ResNet-50 from 13.3-min per epoch to 4.4-min per epoch. In addition, by stacking all heuristics for large-batch training, the model trained with 1024 batch size and FP16 even slightly increased 0.5% top-1 accuracy compared to the baseline model.
The ablation study of all heuristics is shown in Table 4. Increasing batch size from 256 to 1024 by linear scaling learning rate alone leads to a 0.9% decrease of the top-1 accuracy while stacking the rest three heuristics bridges the gap. Switching from FP32 to FP16 at the end of training does not affect the accuracy.
从表3中不难看出,当降低精度时,即使采用了1024的BS,数据量也比256的BS要小,从表4可以看出,采用了所有的方法后,BS1024,数据精度为FP16在TOP1的精确度上对比256的提高了0.5个百分点。
Model Tweaks
通过修改模型中的stride或者添加padding层达到影响准确度的目的。


ResNet-B: 考虑到图1中下采样层中,path A 的第一层步长为2,会忽略四分之三的内容,因此将步长设置为1。
ResNet-C:考虑到图2中的input stem采用的是7x7的卷积核,将7x7的卷积核改成三个3x3的卷积核,其中前两个卷积核是步数为2层数32,最后一个层数为64。
ResNet-D:图1中下采样层中,path B卷积层前加入一个步长为2的平均池化层。卷积层设置为步长为1.
Experiment Results
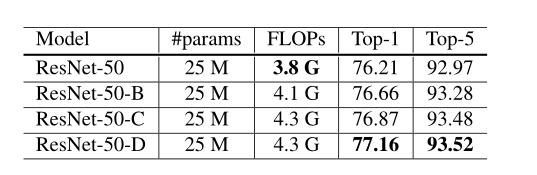
表中不难看出,采用ResNet-B的方法,使下采样获得了更多的信息,与原来的网络相比,正确率提高了百分之0.5,用3个3X3的卷积核代替7X7的卷积核,验证准确度又提高了百分之0.2,ResNet-D的做法又提高了百分之0.3,因此整个过程提高了百分之1的验证准确度。
但就浮点运算而言,ResNet-D与ResNet-50的差异在15%以内。在实践中,我们观察到ResNet-50-D相比ResNet-50在训练吞吐量上仅慢3%。
Training Refinements
Cosine Learning Rate Decay
在学习率的衰减上,采用: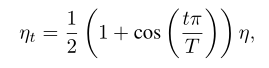
其中η是初始学习率。我们称这种调度为“余弦”衰减。效果如下图:

阶跃衰减和余弦衰减之间的比较如图3a所示。可以看出,余弦衰减在开始时使学习速率缓慢下降,然后在中间变成几乎线性下降,到最后又变慢。与阶跃衰减相比,余弦衰减从一开始就开始衰减学习,但一直很大,直到阶跃衰减将学习速率降低10倍,这可能会提高训练进度。
Label Smoothing
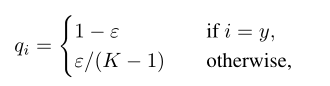
将label中的one-hot标签改成上图,其中ε是一个小常数。
将输出预测分数改成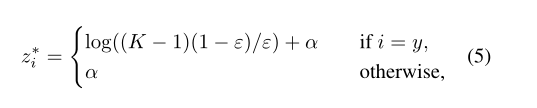
其中α可以是任意实数。这促进了全连接层的有限输出,并且可以更好地概括。
通过添加最小值使标签平滑,使用标签平滑,分布中心在理论值,并且具有较少的极值。可以降低最大预测值的差距。
Knowledge Distillation
采用的是知识蒸馏的方法,通过设置两个模型,即教师模型和学生模型,教师模型是预先训练好的精度比较高的模型,学生网络通过模仿,在保持模型复杂度不变的情况下提高自身精度,其中loss使用:
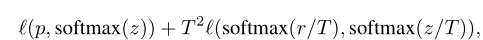
p是真实的概率分布,z和r分别是学生模型和教师模型的最后一个全连通层的输出,其中T是温度超参数,以使softmax输出更平滑,从而从教师的预测中提取标签分布的知识。
教师模型不是来自学生的同一个家庭,因此在预测中有不同的分布,并给模型带来负面影响
Mixup Training
In Section 2.1 we described how images are augmented before training. Here we consider another augmentation method called mixup [29]. In mixup, each time we randomly sample two examples (xi, yi) and (xj, yj). Then we form a new example by a weighted linear interpolation of these two examples:
ˆ x = λxi+ (1 − λ)xj
ˆ y = λyi+ (1 − λ)yj
where λ ∈ [0,1] is a random number drawn from the Beta(α, α) distribution. In mixup training, we only use the new example (ˆ x, ˆ y).
通过抽取数据集中的任意两个模型,对其进行如上操作,获得新的数据,再采用新的数据进行训练(抽取的应该是同label的数据)
Experiment Results
Now we evaluate the four training refinements. We set ε = 0.1 for label smoothing by following Szegedy etal. [26]. For the model distillation we use T = 20, specifically a pretrained ResNet-152-D model with both cosine decay and label smoothing applied is used as the teacher. In the mixup training, we choose α = 0.2 in the Beta distribution and increase the number of epochs from 120 to 200 because the mixed examples ask for a longer training progress to converge better. When combining the mixup training with distillation, we train the teacher model with mixup as well.
使用T = 20,具体地说,使用预处理的ResNet-152-D模型作为教师,该模型应用了余弦衰减和标签平滑。在混合训练中,我们选择β分布中的α = 0.2,并将纪元数从120增加到200,因为混合示例要求更长的训练进度以更好地收敛。当混合训练和蒸馏结合时,我们也用混合训练教师模型。我们证明了改进不仅仅局限于ResNet架构或ImageNet数据集。首先,我们在ImageNet数据集上对ResNet-50-D、盗梦空间-V3和MobileNet进行了细化训练。表6显示了逐个应用这些训练改进的验证精度。通过叠加余弦衰减、标签平滑和混合,我们稳步改进了ResNet、InceptionV3和MobileNet模型。蒸馏在ResNet上运行良好,但是在盗梦空间V3和MobileNet上运行不佳。我们的解释是,教师模型不是来自学生的同一个家庭,因此在预测中有不同的分布,并给模型带来负面影响。



