
- 1小和问题_力扣小和问题
- 2Mybatis insert 生成 ID_mybatis insert id
- 3Mybatis实体类的映射文件中select,insert语句使用
- 4Android获取设备唯一标识
- 5在vue3中,新的组合式API中没有this,那我们如果需要用到this怎么办?_this.$api在vue3
- 6华为鸿蒙HarmonyOS-面向全场景的分布式操作系统_鸿蒙全场景代理
- 7【ASP.NET】5.百度富文本编辑器UEditor之存入数据库_ueditor内容保存到数据库
- 8ChatGPT新一代人工智能_gpt人工智能代码编写
- 9系统变量无法编辑问题_系统变量无法新建编辑删除
- 10拦不住了!HarmonyOS鸿蒙这次动静有点大,B端、C端全面发力!_1月18日鸿蒙发布会
深度学习——数据预处理
赞
踩
一、数据预处理
为了能用深度学习来解决现实世界的问题,我们经常从预处理原始数据开始, 而不是从那些准备好的张量格式数据开始。 在Python中常用的数据分析工具中,我们通常使用pandas软件包。 像庞大的Python生态系统中的许多其他扩展包一样,pandas可以与张量兼容。下面简要介绍了使用pandas预处理原始数据,并将原始数据转换为张量格式的步骤。
1、创建文件存入数据集后读取数据集
举一个例子,我们首先创建一个人工数据集,并存储在CSV(逗号分隔值)文件 …/data/house_tiny.csv中。 以其他格式存储的数据也可以通过类似的方式进行处理。 下面我们将数据集按行写入CSV文件中。
import os
//创建文件并写入数据
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
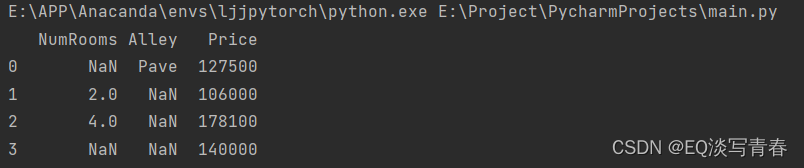
要从创建的CSV文件中加载原始数据集,我们导入pandas包并调用read_csv函数。该数据集有四行三列。其中每行描述了房间数量(“NumRooms”)、巷子类型(“Alley”)和房屋价格(“Price”)。
# 如果没有安装pandas,只需取消对以下行的注释来安装pandas
# !pip install pandas
import pandas as pd
//读取文件数据
data = pd.read_csv(data_file)
print(data)
- 1
- 2
- 3
- 4
- 5
- 6
输出:
2、处理缺失值
注意,“NaN”项代表缺失值。 为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。 在这里,我们将考虑插值法。
通过位置索引iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。 对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean(inputs.mean(numeric_only=True)))
print(inputs)
- 1
- 2
- 3
输出:

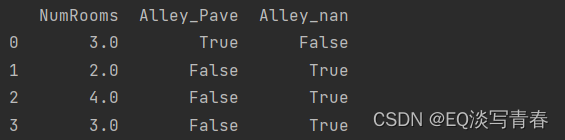
对于inputs中的类别值或离散值,我们将“NaN”视为一个类别。 由于“巷子类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”, pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。 巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
- 1
- 2
输出:
3. 转换为张量格式
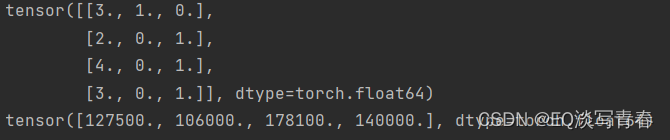
现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式。
import torch
X = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
print(X)
print(y)
- 1
- 2
- 3
- 4
- 5
- 6
输出:
二、小结
- pandas软件包是Python中常用的数据分析工具中,pandas可以与张量兼容。
- 用pandas处理缺失的数据时,我们可根据情况选择用插值法和删除法。
- 数据预处理是为了改善数据挖掘分析工作,减少时间,降低成本和提高质量。很有必要,就像做菜不洗菜,这样的人做出来的菜质量也不会好在哪里,没人愿意吃。
三、完整代码展示
import torch import os # 如果没有安装pandas,只需取消对以下行的注释来安装pandas # !pip install pandas import pandas as pd os.makedirs(os.path.join('..', 'data'), exist_ok=True) data_file = os.path.join('..', 'data', 'house_tiny.csv') with open(data_file, 'w') as f: f.write('NumRooms,Alley,Price\n') # 列名 f.write('NA,Pave,127500\n') # 每行表示一个数据样本 f.write('2,NA,106000\n') f.write('4,NA,178100\n') f.write('NA,NA,140000\n') data = pd.read_csv(data_file) print(data) inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] inputs = inputs.fillna(inputs.mean(numeric_only=True)) print(inputs) inputs = pd.get_dummies(inputs, dummy_na=True) print(inputs) X = torch.tensor(inputs.to_numpy(dtype=float)) y = torch.tensor(outputs.to_numpy(dtype=float)) print(X) print(y)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31

