
- 1Harmony 鸿蒙页面级变量的状态管理_鸿蒙 自定义组件中变量的状态
- 2基于蜻蜓优化算法的最优解 MATLAB 仿真
- 3关于鸿蒙的笔记整理
- 4数据结构->二叉树的基本操作_按先序次序输入二叉树中结点的值,建立一棵以二叉链表作存储结构的二叉树,然后
- 5Federated Learning 联邦学习概述及最新工作_feddefender: client-side attack-tolerant federated
- 6htc hd2刷android,真正的刷机之王! HTC HD2成功刷入安卓7.0
- 7Global SiC MOSFET Modules Market Size Is Projected to Grow from USD 1693 million in 2023
- 8短短60行代码搞定鸿蒙“二维码扫描”功能!
- 9CSS换行代码是什么?_css英文单词换行代码
- 10语义边缘精化方法_PointRend: Image Segmentation as Rendering_语义分割边缘优化
2022.07.25 C++下使用opencv部署yolov7模型(五)_yolov7 shezhi nmsthreshold
赞
踩
0.写在最前
此篇文字针对yolov7-1.0版本。
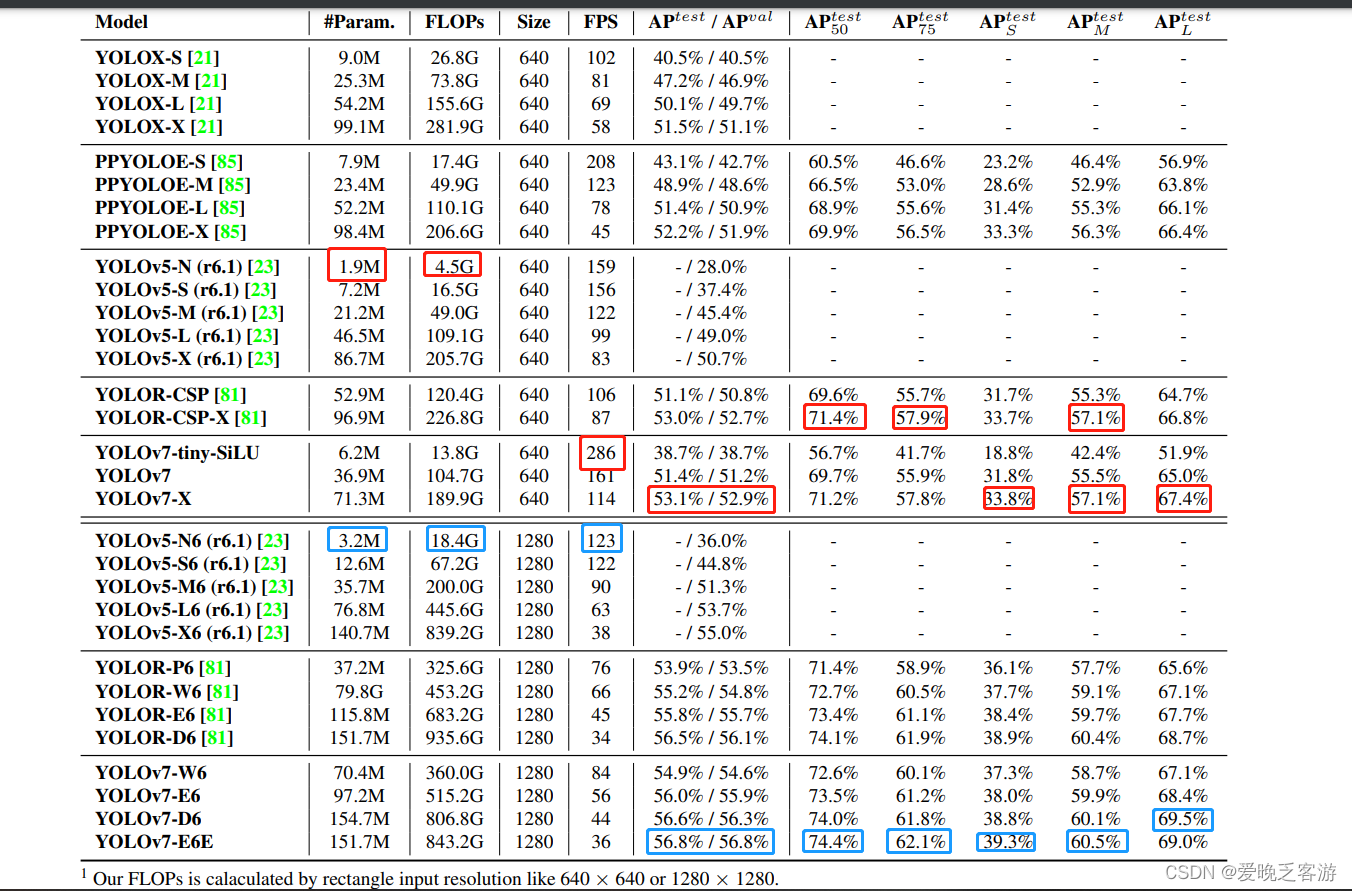
最近粗略的看了一遍yolov7的论文,关于yolov7和其他yolo系列的对比,咱就不多说了,大佬们的文章很多很详细。关于opencv部署方面,其实yolov7和yolov5的初期版本(5.0以前的版本)很像,分为三个输出口,yolov5-6.0之后的版本合并了三个输出口变成一个output输出【需要注意的是,虽然yolov可以在export的时候加上--grid参数将detect层加入之后变成和yolov5最新版本的输出一致(可以不用改yolov5代码直接跑yolov7的那种一致,当然,anchors数据还是得改的),但是我试过了,opencv包括onnxruntime推理加grid参数的onnx模型都有问题,暂时我也在探索一种适用于所有yolov7版本的修改方案,但是改了几种都是适用某几个模型,其他模型挂掉的情况】。使用Netron打开两个模型对比下很明显,数据格式也和yolo的一致。所以基本上可以和yolov5的代码通用。只不过具体使用的时候还是有一点区别的。另外,yolov7目前可以直接通过其自身带的export.py导出onnx模型,并不需要像yolov5早期的代码修改。
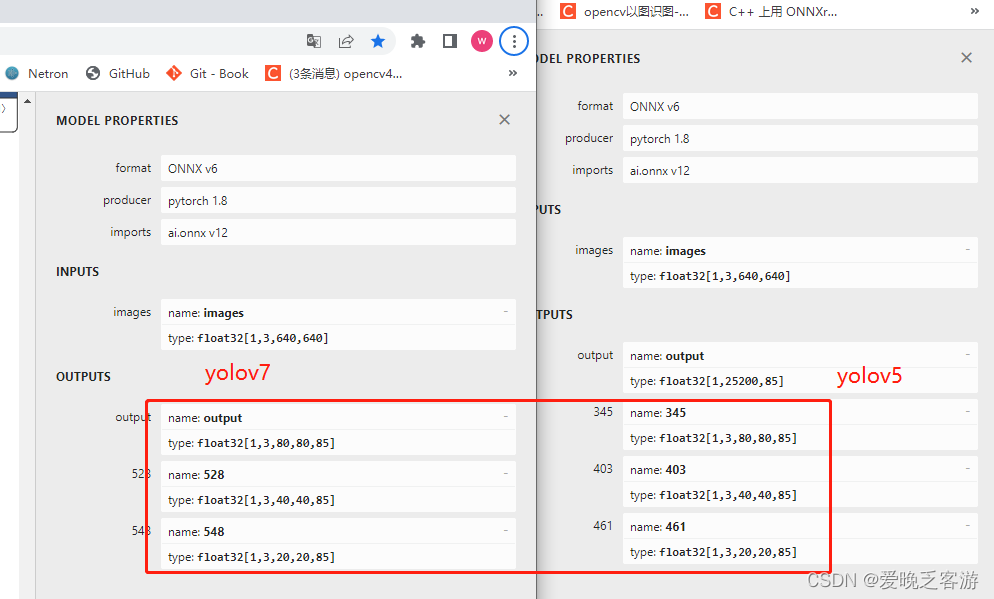
一.yolov5代码修改适用yolov7
1.归一化框的读取类似yolov5的早期版本
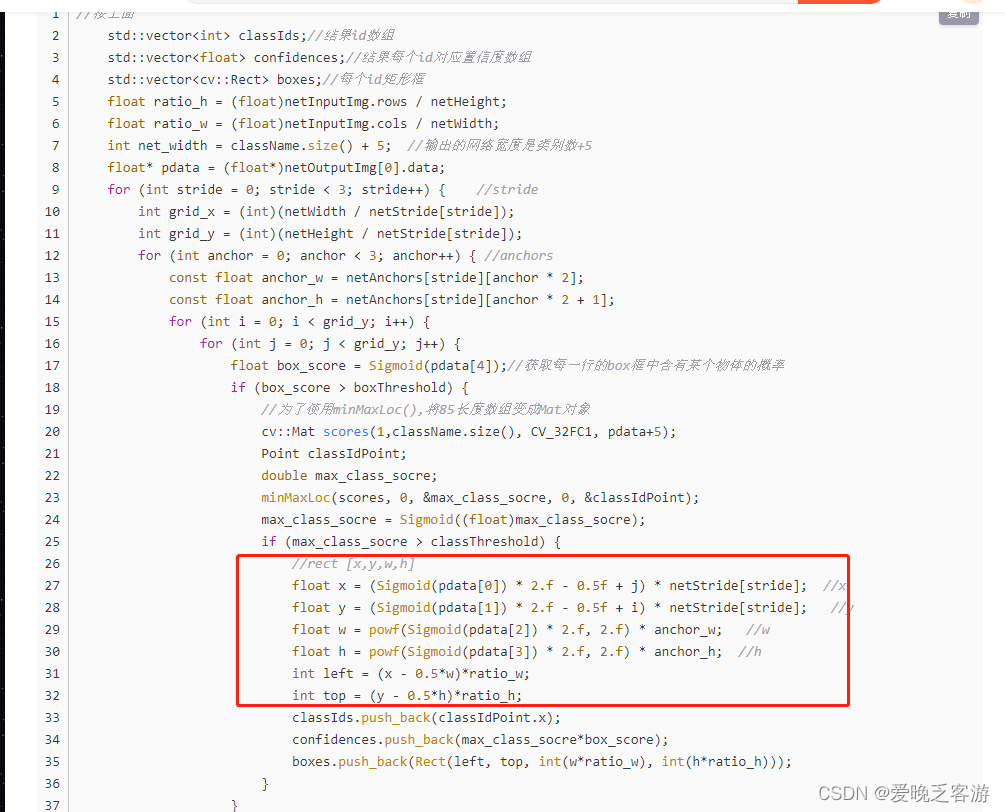
上面说过,yolov7和yolov5的不同,实际上应该是一致的才对(实际上,如果yolov7导出的时候加上--grid参数,结果就和yolov5目前的版本一毛一样,但是加上之后opencv推理onnx的时候会报错,目前yolov7暂时未修复该bug,所以下面的yolov7代码导出的时候不要加--grid参数)。我没仔细debug,所以我们需要根据下面的红色框中的内容对网络的归一化anchors框进行变换变成正常的像素位置。也就是像yolov5之前古老的版本没优化之前一样(这就是我上面说的和yolov5-5.0以前的版本类似的原因)。可以看第三篇的代码中的读取归一化框的方式获取原始图像位置。2021.09.02更新说明 c++下使用opencv部署yolov5模型 (三)_爱晚乏客游的博客-CSDN博客_c++ yolov5
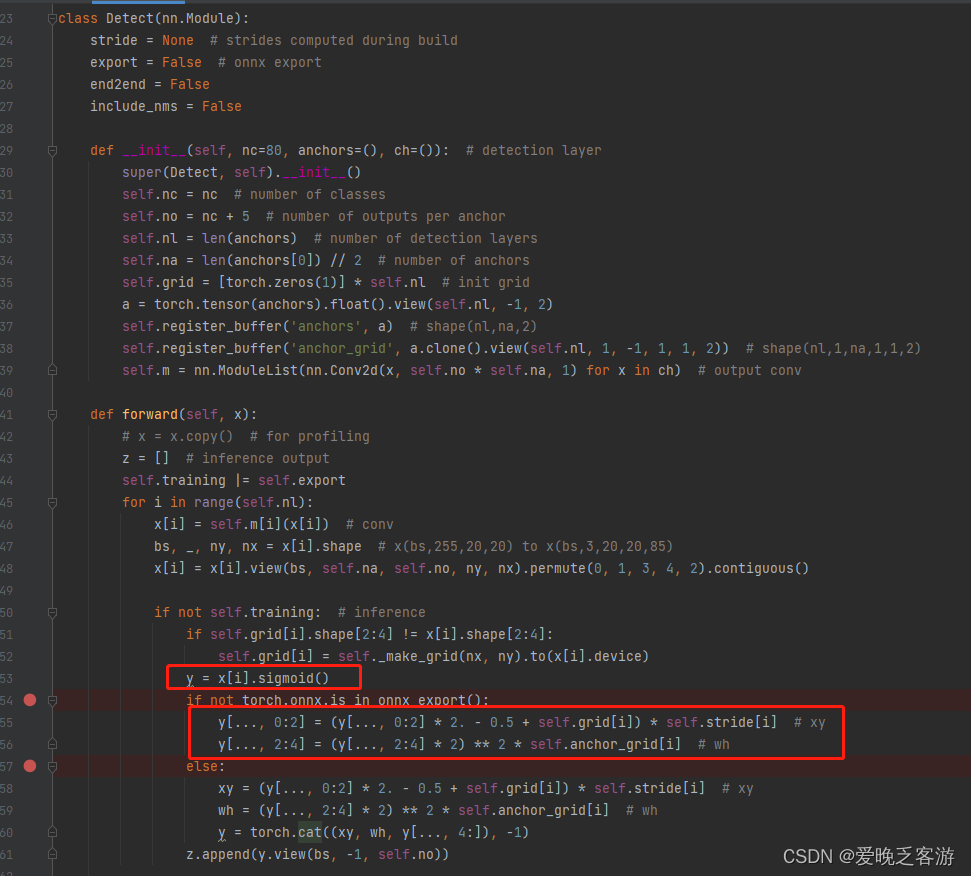
2.anchors数据不同

对比下两者的anchors数据,可以看到两个的anchors不一致了,修改这部分内容即可。
所以综上所诉,对于yolov5-6.0的代码,修改一些地方即可马上应用到yolov7上面,可以说很方便了。
具体修改有两处,一处是anchors,另外一处是推理程序,修改之后的链接我放最下面了,其实就是在第四篇的基础上面修改下:GitHub - UNeedCryDear/yolov5-opencv-dnn-cpp: 使用opencv模块部署yolov5-6.0版本
- //yolo.h中改下anchors
- const float netAnchors[3][6] = { {12, 16, 19, 36, 40, 28},{36, 75, 76, 55, 72, 146},{142, 110, 192, 243, 459, 401} }; //yolov7-P5 anchors
-
- //yolo.cpp中推理代码修改
- bool Yolo::Detect(Mat& SrcImg, Net& net, vector<Output>& output) {
- Mat blob;
- int col = SrcImg.cols;
- int row = SrcImg.rows;
- int maxLen = MAX(col, row);
- Mat netInputImg = SrcImg.clone();
- if (maxLen > 1.2 * col || maxLen > 1.2 * row) {
- Mat resizeImg = Mat::zeros(maxLen, maxLen, CV_8UC3);
- SrcImg.copyTo(resizeImg(Rect(0, 0, col, row)));
- netInputImg = resizeImg;
- }
- vector<Ptr<Layer> > layer;
- vector<string> layer_names;
- layer_names= net.getLayerNames();
- blobFromImage(netInputImg, blob, 1 / 255.0, cv::Size(netWidth, netHeight), cv::Scalar(0, 0, 0), true, false);
- //如果在其他设置没有问题的情况下但是结果偏差很大,可以尝试下用下面两句语句
- //blobFromImage(netInputImg, blob, 1 / 255.0, cv::Size(netWidth, netHeight), cv::Scalar(104, 117, 123), true, false);
- //blobFromImage(netInputImg, blob, 1 / 255.0, cv::Size(netWidth, netHeight), cv::Scalar(114, 114,114), true, false);
- net.setInput(blob);
- std::vector<cv::Mat> netOutputImg;
- net.forward(netOutputImg, net.getUnconnectedOutLayersNames());
- std::vector<int> classIds;//结果id数组
- std::vector<float> confidences;//结果每个id对应置信度数组
- std::vector<cv::Rect> boxes;//每个id矩形框
- float ratio_h = (float)netInputImg.rows / netHeight;
- float ratio_w = (float)netInputImg.cols / netWidth;
- int net_width = className.size() + 5; //输出的网络宽度是类别数+5
- for (int stride = 0; stride < strideSize; stride++) { //stride
- float* pdata = (float*)netOutputImg[stride].data;
- int grid_x = (int)(netWidth / netStride[stride]);
- int grid_y = (int)(netHeight / netStride[stride]);
- for (int anchor = 0; anchor < 3; anchor++) { //anchors
- const float anchor_w = netAnchors[stride][anchor * 2];
- const float anchor_h = netAnchors[stride][anchor * 2 + 1];
- for (int i = 0; i < grid_y; i++) {
- for (int j = 0; j < grid_x; j++) {
- float box_score = sigmoid_x(pdata[4]); ;//获取每一行的box框中含有某个物体的概率
- if (box_score >= boxThreshold) {
- cv::Mat scores(1, className.size(), CV_32FC1, pdata + 5);
- Point classIdPoint;
- double max_class_socre;
- minMaxLoc(scores, 0, &max_class_socre, 0, &classIdPoint);
- max_class_socre = sigmoid_x(max_class_socre);
- if (max_class_socre >= classThreshold) {
- float x = (sigmoid_x(pdata[0]) * 2.f - 0.5f + j) * netStride[stride]; //x
- float y = (sigmoid_x(pdata[1]) * 2.f - 0.5f + i) * netStride[stride]; //y
- float w = powf(sigmoid_x(pdata[2]) * 2.f, 2.f) * anchor_w; //w
- float h = powf(sigmoid_x(pdata[3]) * 2.f, 2.f) * anchor_h; //h
- int left = (int)(x - 0.5 * w) * ratio_w + 0.5;
- int top = (int)(y - 0.5 * h) * ratio_h + 0.5;
- classIds.push_back(classIdPoint.x);
- confidences.push_back(max_class_socre * box_score);
- boxes.push_back(Rect(left, top, int(w * ratio_w), int(h * ratio_h)));
- }
- }
- pdata += net_width;//下一行
- }
- }
- }
- }
-
- //执行非最大抑制以消除具有较低置信度的冗余重叠框(NMS)
- vector<int> nms_result;
- NMSBoxes(boxes, confidences, nmsScoreThreshold, nmsThreshold, nms_result);
- for (int i = 0; i < nms_result.size(); i++) {
- int idx = nms_result[i];
- Output result;
- result.id = classIds[idx];
- result.confidence = confidences[idx];
- result.box = boxes[idx];
- output.push_back(result);
- }
- if (output.size())
- return true;
- else
- return false;
- }
二、yolov7一些模型转换的问题
评论区有些小伙伴反馈yolov7-d6模型在opencv4.5.1下面会报错,报错信息类似之前读取早期的yolov5的报错一致。
OpenCV(4.5.0) Error: Unspecified error (> Node [Slice]:(341) parse error: OpenCV(4.5.0) D:\opencv\ocv4.5.0\sources\modules\dnn\src\onnx\onnx_importer.cpp:697: error: (-2:Unspecified error) in function 'void __cdecl cv::dnn::dnn4_v20200908::ONNXImporter::handleNode(const class opencv_onnx::NodeProto &)' Slice layer only supports steps = 1 (expected: 'countNonZero(step_blob != 1) == 0'), where 'countNonZero(step_blob != 1)' is 1 must be equal to '0' is 0 in cv::dnn::dnn4_v20200908::ONNXImporter::handleNode, file D:\opencv\ocv4.5.0\sources\modules\dnn\src\onnx\onnx_importer.cpp, line 1797
经过对比yolov7和yolov7-d6的yaml文件,发现是由于yolov7-d6中使用了ReOrg模块引起的报错,也就是步长为2的切片,像我这个系列中第一篇的问题一样。
这个模块有点类似早期的yolov5的Facos模块,需要将ReOrg模块修改成下面的代码。 在models/common.py里面搜索下ReOrg,改成一下代码之后重新导出onnx模型即可正确读取。
- class ReOrg(nn.Module):
- def __init__(self):
- super(ReOrg, self).__init__()
-
- def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
- #origin code
- # return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
- self.concat=Contract(gain=2)
- return self.concat(x)
最后贴个yolov7和yolov5的对比图,可以看到yolov7提升还是蛮明显的,结果的置信度高了一些,后面的自行车也检测出来了,就是领带这里误检了。

贴合github链接,里面包括了yolov7和yolov5,通过宏定义来控制:

