
- 1【时间】 js 根据已知的时间,判断是否是 前天,昨天,今天,明天,后天_js判断今天明天后天
- 2华为畅享6s可以升级鸿蒙,【华为畅享6S评测】华为畅享6S评测:颜值高又好用的千元机就是它了-中关村在线...
- 3运行速度终于变快了!优化VMD参数,五种适应度函数任意切换,最小包络熵、样本熵、信息熵、排列熵、排列熵/互信息熵...
- 4Macbook(苹果电脑) VSCode 创建简单c++程序 配置C++开发环境_mac做c++开发
- 5基于rk3568平台 rk809 codec的介绍
- 6sysbench的用法_sysbench可以设置table name吗
- 7两篇论文被ECML PKDD DC09接收_ecml-pkdd(ccf b类)论文被哪里收集
- 8flutter获取地理定位:geolocator依赖详细用法_flutter geolocator
- 9【自然语言处理】ChatGPT 相关核心算法_chatgpt核心算法
- 10OS系统下 使用MAMP站点配置详解_mamp 导出配置
NLP之基本介绍_nlp技术
赞
踩
人工智能-研究方向
- TTS语音合成(避免人喊)
- ASR语音识别(手机助手:声音-》文字)录音笔
- 字符识别(CV领域)银行卡扫描、身份证扫描
- 机器翻译(目前水平较好)双语字幕和语音识别相结合
- 声纹识别(一些验证场景)
- 指纹识别
- 语义理解(只能客服)
- 图像识别
机器学习是实现一种人工智能的一种方式。
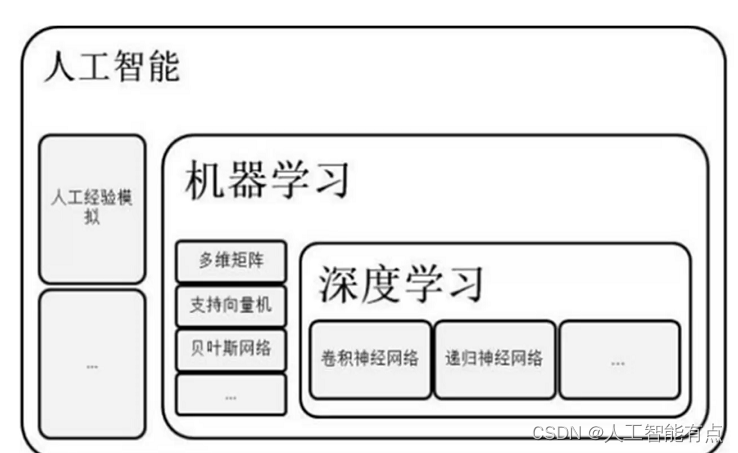
人工智能的三驾马车-算法、算力、数据。数据非常重要。
自然语言处理
是数学、语言学、计算机科学三者结合
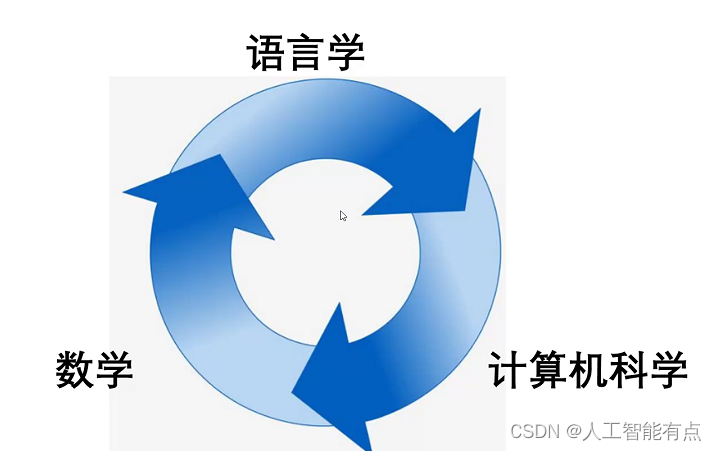
自然语言处理的目标
- 人机交互
- 问答搜索
- 机器翻译
- 指令操作(在家让车自己去加油,目前不行)
- 闲聊
- 辅助生活工作
- 其价值随着机器能力边界的提升而不断增加
- 数据分析/挖掘
- 舆情分析(电商对客户态度的收集、国家的民意调查)
- 文本分类
- 知识抽取
- 命名实体识别
- 辅助决策和选择
- 其价值随着数据量增大和类别增多而不断提升
算法相关工作
业务型
动手能力强
- 主要负责业务场景的算法落地,动手能力强
- 需要熟悉业务场景常见问题,极端情况的处理
- 小坑不断,需求总改,数据常缺,效果老降
研究型
论文 公开数据集
- 主要负责发表论文及算法比赛等,理论知识扎实
- 研究内容可以脱离实际业务,在公开数据集上工作
- 想好的思路已发表,比赛的分数被人超
算法工程师需要的技能
- 编程能力(实现自己想法)
- 算法知识储备
- 沟通和协作能力
- 学习能力
- 一定程度的英文能力
- 使用搜索引擎的能力
关于算法的学习
- 多动手
- 多思考
- 温故而知新
- 保持学习
- 保持好心态,以及多锻炼身体
NLP面临的困难







- NLP对于机器来说很困难,本质上是因为对于人来说它也很困难。事情本身复杂度高。
- 换句话说,这个任务本身的复杂度就非常高,远远高于下围棋等看似复杂,但实际有着明确规则的任务。
- 语言本身具有创造力,在不同领域和时代不断发生着变化。
新生词:
九漏鱼:九年义务教育漏网之鱼
NLP的发展历程
- 20世纪50年代开始,于计算机的诞生几乎同时
- 始于机器翻译
- 两种路线
- 基于规则的理性主义
主张建立符号处理系统,人工编写初始的语言知识表示体系,构造响应的推理程序。 - 基于统计的经验主义
主张通过建模学习复杂、广泛的语言结构,利用统计、模式识别、机器学习等方法训练模型。
- 基于规则的理性主义
- 20世纪80-90 两种方式对立走向融合
- 21世纪以来,机器学习快速崛起。在图像、语言、文本领域都有大量的数据集被建立起来,这种资源大幅度推动了基于统计的机器学习相关算法的发展。随着AlphaGo的出现,人工智能领域获得前所未有的关注度。NLP也飞快的追赶着其他领域发展(得益于数据和算力)。
图灵测试
计算机冒充人,与人对话,如果超多30%的人误认为自己对话而非计算机,则可以认为这台机器拥有人类智能。图灵测试是图灵个人看法,在1950年提出,并非当前业界的最求。
绕过图灵测试的方法:
焦躁的年轻人(机器一直说自己事情,表现出焦虑的感觉,容易让听者误认)
心理医生式问答(机器反问你一些问题,表现出一定的主动性,容易让人误认)
计算机在很多方面比人强(比如计算),如果在图灵测试中我问人工智能一个有计算量的运算(如:6526*541),那么它可以立刻给我答案,但这不是一个正常人可以马上计算出的。
NLP发展现状
深度学习大幅改变了NLP研究,使离散的符号转化为连续的数值,因此大量的数学工具得以应用,极大的推进了NLP技术的发展。
NLP技术已经深入生活的各个角落,输入法、语音助手、搜索引擎、智能客服等大量依赖NLP技术的应用已经被推广和使用。
综合来看,目前计算机对语义的理解能力尚不如小学生,但在特定任务上可以达到人类以上的水平。
深度学习发展历程
第一代神经网络(1958~1969)
用计算机来模拟人的神经元反应的过程,该模型将神经元简化为了三个过程:输入信号线性加权,求和,非线性激活(阈值法)
1969年,美国数学家及人工智能先驱Minsky在其著作中证明了感知器本质上是一种线性模型,只能处理线性分类问题。
第二代神经网络(1986~1998)
Hinton在1986年发明了适用于多层感知器(MLP)的BP算法,并采用Sigmoid进行非线性映射,有效解决了非线性分类和学习的问题。
1991年,BP算法被指出存在梯度消失问题,即在误差梯度后向传递的过程中,后层梯度以乘性方式叠加到前层,由于Sigmoid函数的饱和特性,后层梯度本来就小,误差梯度传到前层时几乎为0,因此无法对前层进行有效的学习
1997年,LSTM模型被发明,尽管该模型在序列建模上的特性非常突出,但由于正处于NN的下坡期,也没有引起足够的重视。
统计学习方法的春天(1986~2006)
决策树,支持向量机,随机森林等算法先后被提出,并且在实际场景取得不错的效果
第三代神经网络-DL(2006-至今)
该阶段又分为两个时期:快速发展期(20062012)与爆发期(2012至今)
2012年,Hinton课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过构建的CNN网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能。
之后基于深度学习的模型在各种算法任务上开始屠榜,也带来了人工智能整个产业的崛起
NLP常用工具
编程语言
引擎开发:C++和Java居多
算法实验:Python, R
C++,Java的特点:
执行效率高,开发累(代码量大),不好上手,有助于深入理解编程,有成熟的框架和各种检查工具
Python的特点:
执行效率低,开发轻松,开源库多,简单易学,做线上业务需要开发者有较好的编程习惯
框架:
- Tensorflow 大名鼎鼎,工程配套完善
- Pytorch 学术界宠儿,调试方便,个人推荐
- Keras 高级封装,简单好用,现已和Tensorflow合体
- Gensim 训练词向量,bm25等算法支持
- Sklearn 大量机器学习算法,如逻辑回归,决策树,支持向量机,随机森林,KMeans等等,同时具有数据集划分和各种评价指标的实现
- Numpy 各种向量矩阵操作
数据处理常用库
- Jieba 分词,词性标注等
- Pandas 数据处理,可以读取excel,csv等格式文件,按列去重、排序,去除无效值等等,但是经常搞事情
- Matplotlib 用于画图,可视化是了解数据集的有效手段,也是做汇报等工作中常用的
- Nltk 英文的预处理工具中的佼佼者,词性还原,去停用词等功能完善,对中文也有一定支持
- Re 正则表达式,也许这会是你最常用的库
- Json 读取json格式数据,非常常见
- Pickle 文件读写自己建立的任意变量或数据结构,比如说自己建的索引等
检索框架
- Lucene 基于java的全文检索引擎,使用倒排索引的机制
- ElasticSearch 基于Lucene开发,提供分布式服务和api接口
数据库
- MySQL
- Postgre
- MongoDB
- Redis
- Hbase
- Neo4j
机器学习简介

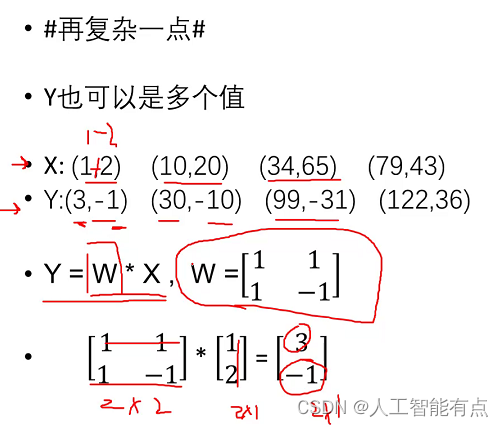

训练的模型是一种输入与输出之间的映射。找输入输出的一种对应关系。这属于有监督学习。有监督学习的核心目标:建立一个魔心给(函数),来描述输入(X)与输出(Y)之间的映射关系。有监督学习的价值:对于新的输入,通过模型给出预测的输出。
有监督学习的要点:
- 需要有一定数量的训练样本(一个样本)
- 输入和输出之间有关联关系(预测幻云男孩女孩)
- 输入和输出可以数值化表示
- 任务需要有预测价值
有监督学习在人工智能种的应用
-
文本分类任务
-
输入:文本
-
输出:类别
-
关系:文本内容决定了文本的类别
-
机器翻译任务
-
输入:A狱中文本
-
输出:B狱中文本
-
A与中国表达的意思,在B狱中共有对应的意思
-
图像识别任务
-
输入:图像
-
输出:类别
-
图中的像素排列,决定了图像的的内容
-
语音识别任务
-
输入:音频
-
输出:文本
-
声音信号在特定语言中对应特定的文本
无监督学习
给与机器的数据没有标注信息,通过算法对数据进行一定的自动分析处理,得到一些结论
常见任务:聚类、降维、找特征值等等。
聚类
降维
高维降到低维,利于观察。
一般流程
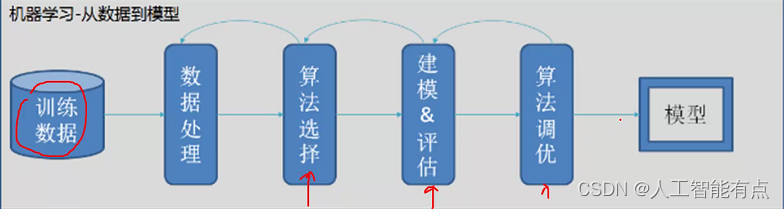
常用概念
- 训练集:用于模型训练的训练数据集合
- 验证集:对于每种任务一般都有多种算法可以选择,一般会使用验证集验证用于对比不同算法的效果差异
- 测试集:最终用于评判算法模型效果的数据集合。评判。一般不暴露给算法开发人员
训练集和验证集可以看见。
- K折交叉验证
初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果
过度的频繁的使用一个数据集去修改一个模型很可能会发生集内。导致在其它测试集上不准。
-
过拟合:模型失去繁华能力。如果模型在训练集和验证集上都有很好的表现,但在测试集上表现很差,一般认为是发生了过拟合
-
欠拟合:模型没能建立起合理的输入输出之间的映射。当输入训练集中的样本时,预测结果与标注结果依然相差很大
-
回归问题
预测值为数值型(连续值)。如预测房价。 -
分类问题
预测值为类别(离散值)或在类别上的概率的分布。 -
特征
模型输入需要数值化,对于较为抽象的输入,如声音,文字,情绪等信息,需要将其转化为数值,才能输入模型。转化后的输入,被称作特征。 -
特征工程
筛选哪些信息值得(以特征的形式)输入模型,以及应当以何种形式输入的工作过程。对于机器学习而言非常重要。模型的输入,决定了模型能力的上限。
算法假设:
一般而言,算法模型是对问题的一种简化。或者说,对于数据事先进行了某种假设,然后在这个基础上,寻找合适的参数,使模型可以拟合数据。
即使问题明显不符合假设,并不意味着这个算法就不能用。事实上,很多情况下,这样依然能有不错的结果。但是,“假设”表明了算法的局限性。
评价指标:
评价算法效果的好坏,不同任务有不同指标
为了评价算法效果的好坏,需要找到一种评价模型效果的计算指标。不同的任务会使用不同的评价指标。常用的评价指标有:
1)准确率
2)召回率
3)F1值
4)TopK
5)BLEU…
深度学习简介
想要快速获得正确的模型,有哪些可以优化的地方?
- 随机初始化
设想初始化后loss很小,是不是很快收敛
NLP中的预训练模型实际上就是对随机初始化的技术优化 - 优化损失函数
(损失函数的选取) - 调整参数的策略
(优化器,学习率) - 调整模型结构
不同模型能够拟合不同的数据集
优化过程:模型随机初始化,预测,计算误差,反复调整
人工神经网络(Artificial Neural Networks,简称ANNs),也简称为神经网络(NN)。它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。
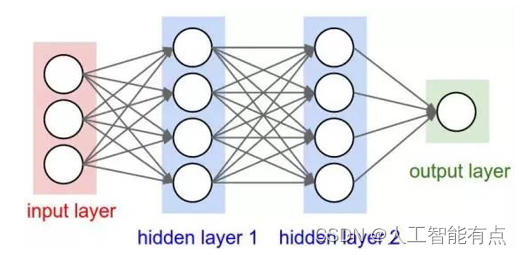
隐含层/中间层:
神经网络模型输入层和输出层之间的部分,隐含层可以有不同的结构:RNN、CNN、DNN、LSTM、Transformer等等
不同的模型结构本质上就是不同的公式
随机初始化
- 隐含层中会含有很多的权重矩阵,这些矩阵需要有初始值,才能进行运算
- 初始值的选取会影响最终的结果
- 一般情况下,模型会采取随机初始化,但参数会在一定范围内
- 在使用预训练模型一类的策略时,随机初始值被训练好的参数代替
- 好的开始是成功的一半!
损失函数:计算预测值与真实值之间的误差
- 损失函数(loss function或cost function)用来计算模型的预测值与真实值之间的误差。
- 模型训练的目标一般是依靠训练数据来调整模型参数,使得损失函数到达最小值。
- 损失函数有很多,选择合理的损失函数是模型训练的必要条件。
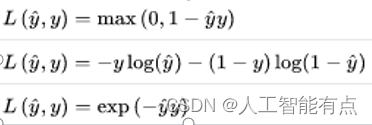
导数与梯度
导数表示函数曲线上的切线斜率。 除了切线的斜率,导数还表示函数在该点的变化率。
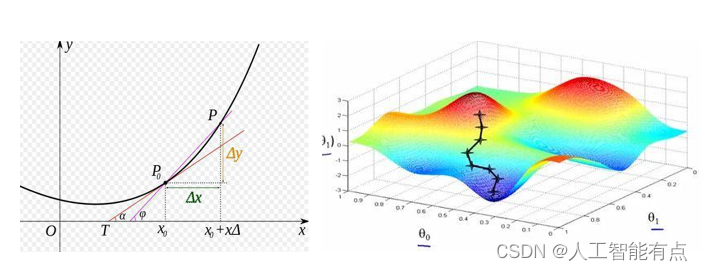
梯度下降
- 梯度告诉我们函数向哪个方向增长最快,那么他的反方向,就是下降最快的方向
- 梯度下降的目的是找到函数的极小值
- 为什么要找到函数的极小值?
因为我们最终的目标是损失函数值最小
优化器
- 知道走的方向,还需要知道走多远
- 假如一步走太大,就可能错过最小值,如果一步走太小,又可能困在某个局部低点无法离开
- 学习率(learning rate),动量(Momentum)都是优化器相关的概念
一步走太大,可能错过全局最优点;一步走太小,课呢困在局部最优点。所以需要一定的策略进行调整。
Mini Batch & epoch
- 一次训练数据集的一小部分,而不是整个训练集,或单条数据
- 它可以使内存较小、不能同时训练整个数据集的电脑也可以训练模型。
- 它是一个可调节的参数,会对最终结果造成影响
- 不能太大,因为太大了会速度很慢。 也不能太小,太小了以后可能算法永远不会收敛。
- 我们将遍历一次所有样本的行为叫做一个 epoch
一次训练使用一部分
一次全部使用,机器不足。不容易收敛。
迭代过程:
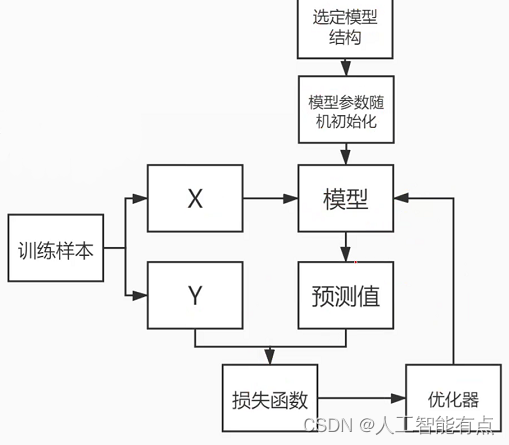
迭代训练要点:
- 模型结构选择
- 初始化方式选择
- 损失函数选择
- 优化器选择
- 样本质量数量
模型训练好后把参数保存,可用于对新样本的预测
总结:
机器学习的本质,是从已知的数据中寻找规律,用来预测未知的样本
深度学习是机器学习的一种方法
深度学习的基本思想,是先建立模型,并将模型权重随机初始化,之后将训练样本输入模型,可以得到模型预测值。使用模型预测值和真实标签可以计算loss。通过loss可以计算梯度,调整权重参数。简而言之,“先蒙后调”

