- 1python学习——逻辑回归_python 逻辑回归
- 2Unity如何判断对象是否已被Destroy_unity 判断物体是否正在destroy
- 3不要再无头苍蝇般寻找AI工具了--100个AI工具网站请查收_toolify.all
- 4使用深度学习进行时间序列预测_深度学习 时间序列预处理
- 52024最新AI大模型产品汇总_最新的ai模型
- 6drawio画图工具_drawio下载 csdn
- 7linux智能聊天机器人,基于bluemix智能聊天机器人开发过程(一)
- 8无人机摄影测量---倾斜摄影测量原理与关键技术
- 9鸿蒙~ArkUI 基础 Grid网格布局_arkui grid 设置每行数量
- 10利用YOLO标注并训练自己的数据集_标注自己的yolo数据集
量化敏感层分析Quantization-Aware-Training(QAT)_quantization aware training
赞
踩
Quantization-Aware-Training(QAT)
量化感知训练 (QAT) 是一种用于深度学习的技术,用于训练可以量化的模型,以便部署在计算能力有限的硬件上。QAT 在训练过程中模拟量化,让模型在不损失精度的情况下适应更低的位宽。与量化预训练模型的训练后量化 (PTQ) 不同,QAT 涉及在训练过程本身中量化模型。
QAT过程可以分解为以下步骤:
定义模型:定义一个浮点模型,就像常规模型一样。
定义量化模型:定义一个与原始模型结构相同但增加了量化操作(如torch.quantization.QuantStub())和反量化操作(如torch.quantization.DeQuantStub())的量化模型。
准备数据:准备训练数据并将其量化为适当的位宽。
训练模型:在训练过程中,使用量化模型进行正向和反向传递,并在每个 epoch 或 batch 结束时使用反量化操作计算精度损失。
重新量化:在训练过程中,使用反量化操作重新量化模型参数,并使用新的量化参数继续训练。
Fine-tuning:训练结束后,使用fine-tuning技术进一步提高模型的准确率。
在PyTorch中,可以使用 torch.quantization.quantize_dynamic() 方法来执行 QAT。这是一个基本的 QAT 示例:
import torch import torch.nn as nn import torch.optim as optim import torchvision.datasets as datasets import torchvision.transforms as transforms from torch.quantization import QuantStub, DeQuantStub, \ quantize_dynamic, prepare_qat, convert # Define the model class MyModel(nn.Module): def __init__(self): super(MyModel, self).__init__() self.quant = QuantStub() self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1) self.relu = nn.ReLU(inplace=True) self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.fc = nn.Linear(128, 10) self.dequant = DeQuantStub() def forward(self, x): x = self.quant(x) x = self.conv1(x) x = self.relu(x) x = self.conv2(x) x = self.relu(x) x = self.avgpool(x) x = x.view(x.size(0), -1) x = self.fc(x) x = self.dequant(x) return x # Prepare the data transform = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) train_data = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) train_loader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True, num_workers=4) # Define the model and optimizer model = MyModel() optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # Prepare the model model.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm') model = prepare_qat(model) # Train the model model.train() for epoch in range(10): for i, (data, target) in enumerate(train_loader): optimizer.zero_grad() output = model(data) loss = nn.CrossEntropyLoss()(output, target) loss.backward() optimizer.step() if i % 100 == 0: print('Epoch: [%d/%d], Step: [%d/%d], Loss: %.4f' % (epoch+1, 10, i+1, len(train_loader), loss.item())) # Re-quantize the model model = quantize_dynamic(model, { '': torch.quantization.default_dynamic_qconfig }, dtype=torch.qint8) # Fine-tuning model.eval() for data, target in train_loader: model(data) model = convert(model, inplace=True)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
在这个例子中,我们在CIFAR10 数据集上训练一个简单的卷积神经网络,并执行 QAT 以获得更好的量化模型。我们首先定义一个MyModel类来定义模型,然后准备训练数据。我们使用 torch.quantization.get_default_qat_qconfig() 方法获取默认的 QAT 配置,使用 prepare_qat() 方法准备
量化参数。训练后,我们使用 convert() 方法将模型转换为量化模型。
总的来说,QAT是一种非常有用的技术,可以帮助我们训练更好的量化模型。与PTQ不同,QAT 可以在训练过程中自适应地调整模型的参数和量化参数,以提高模型的准确性和性能。在PyTorch中,可以使用 torch.quantization.quantize_dynamic() 方法来执行 QAT。
如果PTQ中模型训练和量化是分开的,而QAT则是在模型训练时加入了伪量化节点,用于模拟模型量化时引起的误差。
QAT处理流程如下:
-
首先在数据集上以FP32精度进行模型训练,得到训练好的baseline模型;
-
在baseline模型中插入伪量化节点,
-
进行PTQ得到PTQ后的模型;
-
进行量化感知训练;
-
导出ONNX 模型。
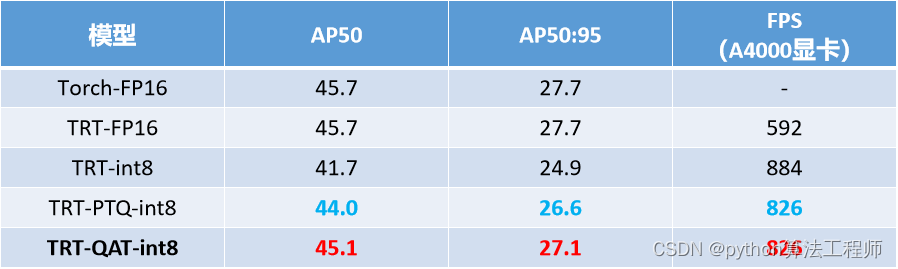
QAT后的提升