
- 1程序员请收好:10个非常实用的 VS Code 插件
- 2如何使用api接入星火大模型(超详细,亲测有效!)_星火大模型v4接口
- 3NLTK库——词形还原(Lemmatization)_nltk词形还原(lemmatization)
- 4Python实战项目——用户消费行为数据分析(三)_数据挖掘消费者行为分析
- 5【深度学习】归一化(十一)_权重归一化
- 6LangChain安装和入门案例_langchain 安装
- 7MySQL面试题系列-8
- 8人工智能-----自然语言处理(NLP)基础理解_智能化需求调查与分析采用自然语言处理深度学习等技术从什么等自然语言描述文
- 9第四届全国人工智能大赛答疑分享会等你围观_杨文瀚 鹏城实验室
- 10西北乱跑娃 --- bottle web框架(七)_bottle 如何显示图片
决策树—ID3、C4.5、CART_决策树流程图
赞
踩
目录
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程,可以认为是if-then规则的集合, 也可以认为是定义在特征空间与类空间上的条件概率分布。主要优点是 模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。
一、决策树模型与学习
1、决策树模型
定义: 分类决策树模型是一种描述对实例进行分类的树形结构。决策树由节点(node)和有向边(directed edge)组成。节点有两种类型:内部节点和叶节点。内部节点表示一个特征或属性,叶节点表示一个类。
用决策树分类,从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值。如此递归的对实例进行测试并分类,直至达到叶节点。最后将实例分到叶结点的类中。
如图是一个决策树示意图,图中圆和方框分别表示内部结点和叶结点:
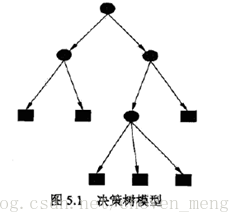
2、决策树学习
决策树学习本质上是从训练数据集中归纳出一组分类规则。与训练数据集不相矛盾的决策树(即能对训练数据进行正确分类的决策树)可能有多个,也可能一个也没有。我们需要一个与训练数据矛盾较小的决策树,同时具有很好的泛化能力。
决策树学习的损失函数通常是 正则化的极大似然函数 。
决策树学习的目标是 以损失函数为目标函数的最小化 。
决策树学习的算法通常是一个 递归的选择最优特征,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类过程。开始,构建根结点,将所有训练数据都放在根结点。选择一个最优特征,按照这个特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。如果这些子集已经能够被基本正确分类,那么构建叶结点,并将这些子集分到所对应的叶结点中去;如果还有子集不能被基本正确分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的结点。如此递归的进行下去,直至所有训练数据子集被基本正确分类,或者没有合适的特征为止。最后每个子集都被分到叶结点上,即有了明确的类。这就生成一颗决策树。
以上方法生成的决策树可能对训练数据有很好的分类能力,但对未知的测试数据可能过拟合。需要对已生成的树自下而上进行剪枝,将树变得更简单,从而使它具有更好的泛化能力。具体的就是去掉过于细分的叶结点,使其退回到父结点,甚至更高的结点,然后将其改为新的叶结点。
若特征较多,在决策树学习开始的时候,对 特征进行选择,只留下对训练数据有足够分类能力的特征。
决策树的生成只考虑局部最优
决策树的剪枝只考虑全局最优
二、特征选择
特征选择在于选取对训练数据具有分类能力的特征,可以提高决策树学习的效率。通常特征选择的准则是信息增益或信息增益率。
特征选择的划分依据:这一特征将训练数据集分割成子集,使得各个子集在当前条件下有最好的分类,那么就应该选择这个特征。(将数据集划分为纯度更高,不确定性更小的子集的过程。)
如果属性是连续型,可以确定一个值作为分裂点splitPoint,按照大于splitPoint和小于等于splitPoint生成两个分支。
决策树量化纯度:
决策树的构建是基于样本概率和纯度进行构建操作的,判断数据集“纯”的指标有三个:Gini指数、熵、错误率。三个公式的值越小,说明越“纯”,实践证明这三个公式效果相似,一般采用熵。
决策树算法的停止条件:
决策树的构建过程是一个递归过程,所以必须给定停止条件,否则过程将不会停止,一般的停止条件有两种:
-
- 当每个子节点只有一种类型的时候停止。
-
- 当前节点中记录数小于某个阈值,同时迭代次数达到给定值时,停止构建,此时使用max(p(i))作为节点的对应类型。
方式一可能会使树的节点过多,产生过拟合等问题。一般采用第二种方法。
- 当前节点中记录数小于某个阈值,同时迭代次数达到给定值时,停止构建,此时使用max(p(i))作为节点的对应类型。
1、信息增益
(1)信息熵:

