
- 1Set a Light 3D Studio:探索光影艺术的全新维度mac/win中文版
- 27. 飞书机器人发送交互式信息_飞书交互式机器人卡片
- 3华为USG6000v
- 4无代理方式的网络准入技术:保护泛终端企业网络安全的未来
- 5RVC使用指南(四)-集群状况_rvcio
- 6安全远控如何设置?揭秘ToDesk、TeamViewer 、向日葵安全远程防御大招_todesk电脑远程控制怎么开启隐私屏
- 7Oracle Form开发之folder(文件夹)功能开发(二)_frm 40106
- 8AiSQL特性在特定业务场景下的应用_ai sql
- 9图文匹配 + 图像分类 = 统一多模态对比学习框架
- 10开启微软 Outlook 邮箱 POP, IMAP, SMTP 服务和获取服务密码(授权码)_imap/pop密码
大数据Hadoop完全分布式及心得体会_hadoop集群完全分布式的搭建手册实验心得
赞
踩
前言
认识hadoop,根据所学知识完成作业,并总结本学期心得体会。
一、认识hadoop
Hadoop是一个分布式系统基础技术框架,利用hadoop,开发用户可以在不了解分布式底层细节的情况下,开发分布式程序,从而达到充分利用集群的威力高速运算和存储的目的;而在本学期中,我们的专业老师带我们学习了Hadoop框架中最核心的设计:MapReduce和HDFS。
MapReduce从字面上就能看出,是由两个动词Map和Reduce组成,“Map” 就是将一个任务分解成为多个任务,“Reduce” 就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。即把一个巨大的任务分割成许许多多的小任务单元,最后再将每个小任务单元的结果汇总,并求得最终结果。
而map的输出和reduce的输入之间的还有一个数据处理过程,即为shuffle过程。该过程涉及分区、排序、分组等操作。
数据流转过程

HDFS的中文翻译是Hadoop分布式文件系统(Hadoop Distributed File System)。它本质还是程序,主要还是以树状目录结构来管理文件(和linux类似,/表示根路径),且可以运行在多个节点上(即分布式);它可以存储海量离线数据(如TB、PB、ZB级别的数据),并且保证数据高可用,支持高并发访问。但并不适合将大量的小文件存到HDFS。其主要原因是:HDFS的NameNode进程在内存中存储文件的元数据,故文件越多,消耗的内存就越大。大量的小文件,耗尽NameNode节点的内存,而实际存的文件总量却很小,HDFS存海量数据的优势没有发挥出来。
HDFS的框架


HDFS存文件的时候,会将文件按照一定的大小(默认是128M)进行分割,独立存储,这些独立的文件即为数据块(Block)。
二、一课一得作业讲解
题: 模拟生成新能源车辆数据编写一个程序,每天凌晨3点模拟生成当天的新能源车辆数据(字段信息必须包含:车架号、行驶总里程、车速、车辆状态、充电状态、剩余电量SOC、SOC低报警、数据生成时间等)。
1、最终部署时,要将这些数据写到第一题的HDFS中。
2、车辆数据要按天存储,数据格式是JSON格式,另外如果数据文件大于100M,则另起一个文件存。每天的数据总量不少于300M。比如假设程序是2023-01-1 03点运行,那么就将当前模拟生成的数据写入到HDFS的/can_data/2023-01-01文件夹的can-2023-01-01.json文件中,写满100M,则继续写到can-2023-01-01.json.2文件中,依次类推;
3、每天模拟生成的车辆数据中,必须至少包含20辆车的数据,即要含有20个车架号(一个车架号表示一辆车,用字符串表示);
4、每天生成的数据中要有少量(20条左右)重复数据(所有字段都相同的两条数据则认为是重复数据),且同一辆车的两条数据的数据生成时间间隔两秒;
5、每天生成的数据中要混有少量前几天的数据(即数据生成时间不是当天,而是前几天的)。
实现步骤
- 搭建集群
- 模拟生成新能源车辆数据编写一个程序
- 最终部署,将这些数据写到HDFS中。
1. 搭建集群
集群规划
| 主机IP | 主机名 | HDFS | YARN |
|---|---|---|---|
| 192.168.91.4 | master | NameNode DataNode | ResourceManager NodeManager |
| 192.168.91.5 | save1 | SecondaryNameNode DataNode | NodeManager |
| 192.168.91.6 | save2 | DataNode | NodeManager |
(1) 准备三台虚拟机,之前在伪分布式中部署过一台虚拟机了,因此直接复制三份虚拟机即可
1.1 先创建三个文件夹,并分别在每一个文件夹中复制一个虚拟机
1.2 启动VMware,重命名三个节点的名称分别为master save1 save2
1.3 分别修改master、save1、save2中的ip并重启网卡
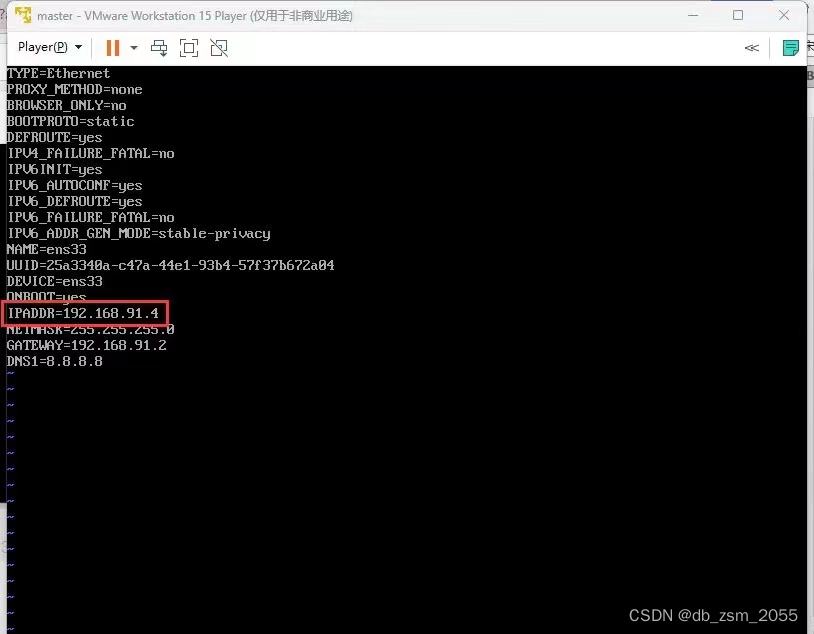
修改IP命令
vi /etc/sysconfig/network-scripts/ifcfg-ens33;
Esc 保存退出
:wq
- 1
- 2
- 3
- 4
- 5
重启网卡命令:service network restart;
(2) 修改master、save1、save2的主机名
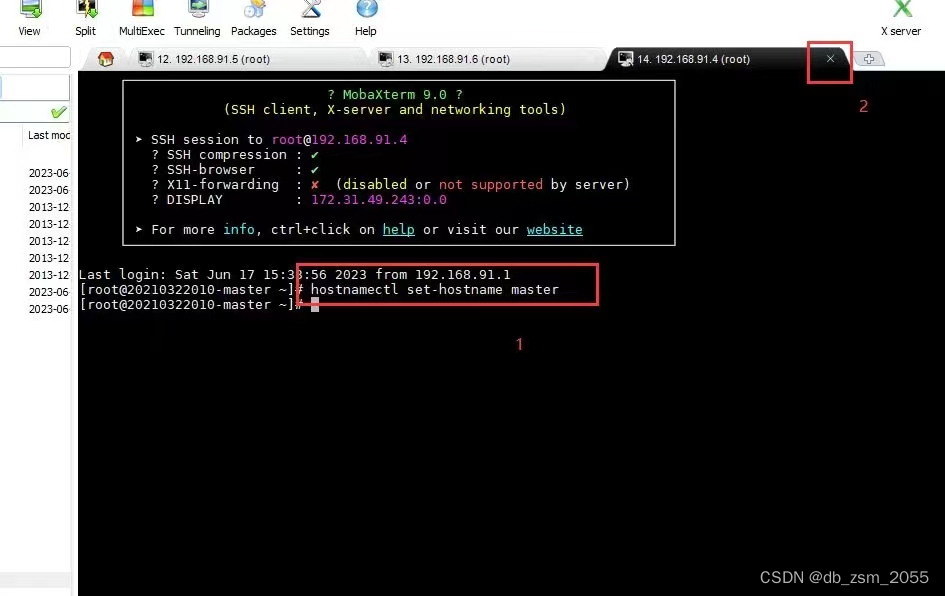
重命名命令:
hostnamectl set-hostname master //master
hostnamectl set-hostname save1 //save1
hostnamectl set-hostname save2 //save2
- 1
- 2
- 3
- 4
(3) 添加IP的映射
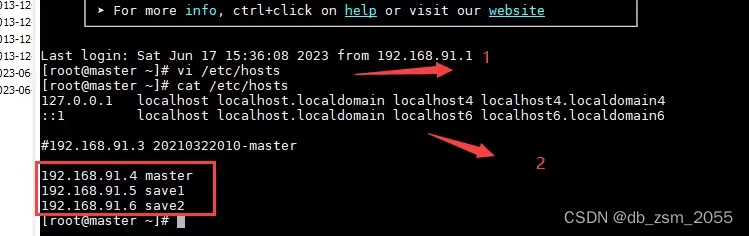
添加IP的映射命令
vi /etc/hosts
Esc 保存退出
:wq
- 1
- 2
- 3
- 4
- 5
(4) 免密登录
因为master、save1、save2三个节点都是从之前的已经安装好Hadoop伪分布式的虚拟机复制得来,而当时已经设置了免密登录,故不需再设置了。也就是master可以免密登录到master、save1、save2。
(5) 关闭防火墙
同理,之前已经设置不允许防火墙开机自启,默认开机是关闭的,故也不需要操作。
(6) 删除伪分布式data的数据
切换到该路径下
cd /usr/local/hadoop-2.7.1/
删除命令
rm -rf ./data/
- 1
- 2
- 3
- 4
- 5
(7) 修改master 的配置文件
7.1
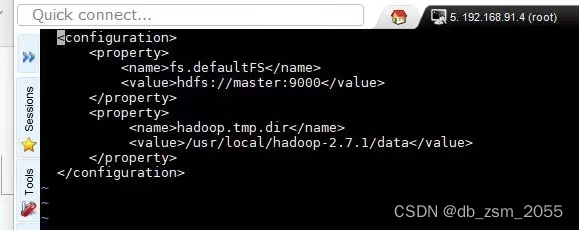
命令示例
vi core-site.xml;
Esc 保存退出
:wq
- 1
- 2
- 3
- 4
- 5
7.2
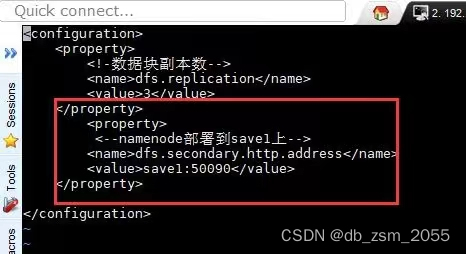
命令示例
vi hdfs-site.xml;
Esc 保存退出
:wq
- 1
- 2
- 3
- 4
- 5
- 6
7.3
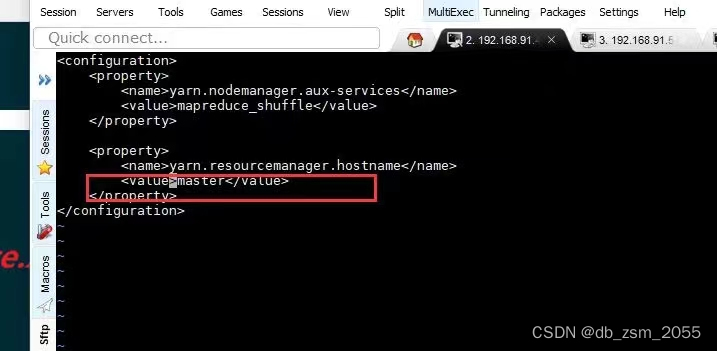
命令示例
vi yarn-site.xml;
Esc 保存退出
:wq
- 1
- 2
- 3
- 4
- 5
- 6
7.4

命令示例
vi saves;
Esc 保存退出
:wq
- 1
- 2
- 3
- 4
- 5
- 6
(8)将刚才master的配置信息同步到saev1、saev2上
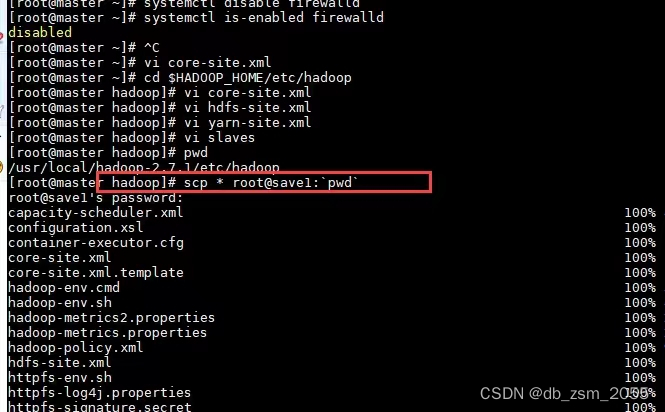
同步到saev1
scp /etc/hosts root@save1:/etc;
同步到saev2
scp /etc/hosts root@save2:/etc;
- 1
- 2
- 3
- 4
- 5
(9)时间同步
- 下载ntpdate插件
yum install -y ntpdata
2.时间同步命令
ntpdate ntp4.aliyun.com;
(10)将NameNode格式化
hdfs namenode -format
- 1
ps:禁止重复格式化
(11)启动集群
分别在master、save1,save2节点上都输入一遍start-all.sh
代码示例:
start-all.sh
- 1
- 2
至此,三个节点的集群就可以算搭建成功!
2. 模拟生成新能源车辆数据编写一个程序
2.1 生成车辆数据
(1)先随机生成20辆车的车架号,并把它存入一个空的列表中;
(2)设置每一个值的状态;
(3)设置数据生成的时间;
(4)把数据存入列表中;
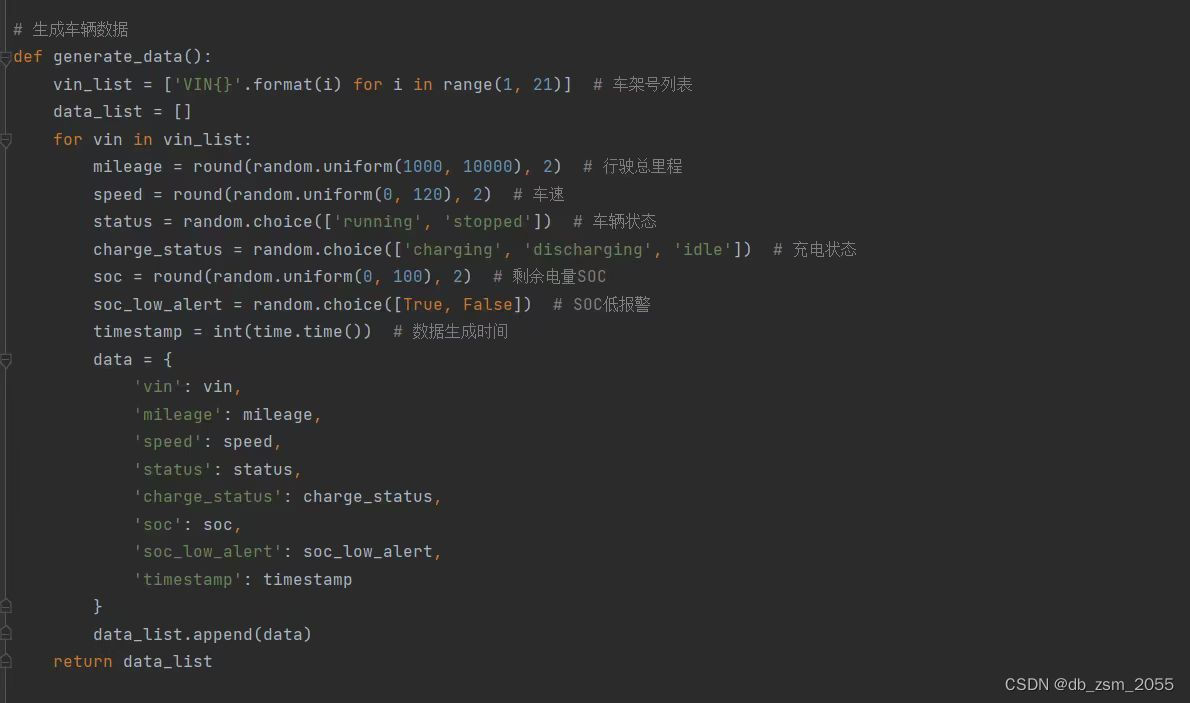
代码示例:
def generate_data(): vin_list = ['VIN{}'.format(i) for i in range(1,21)] # 车架号列表 data_list = [] for vin in vin_list: mileage = round(random.uniform(1000,10000),2) # 行驶总里程 speed = round(random.uniform(0,120),2) # 车速 status = random.choice(['running’,'stopped']) # 车辆状态 charge_status = random.choice(['charging','discharging','idle']) # 充电状态 soc = round(random.uniform(0,100),2) # 剩余电量SOC soc_Low_alert = random.choice([True,False]) # SOC低报警 timestamp = int(time.time()) # 数据生成时间 data = { 'vin': vin, 'mileage': mileage ' speed': speed, ' status': status , ' charge_status': charge_status ' soc': soc, 'soc_low_alert': soc_low_alert 'timestamp': timestamp } data_list.append(data) return data_list

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
2.2.添加重复数据
(1)添加重复数据,使用随机添加,在20辆车中随机添加一些重复的数据;
(2)看题目要求:每天生成的数据中要混有少量前几天的数据(即数据生成时间不是当天,而是前几天的),所以我们要添加前几天的数据;
(3)按时间排序:data.sort(key=lambda x:x[‘timestamp’])
(4)添加时间间隔为2秒的重复数据
(5)将数据写入HDFS
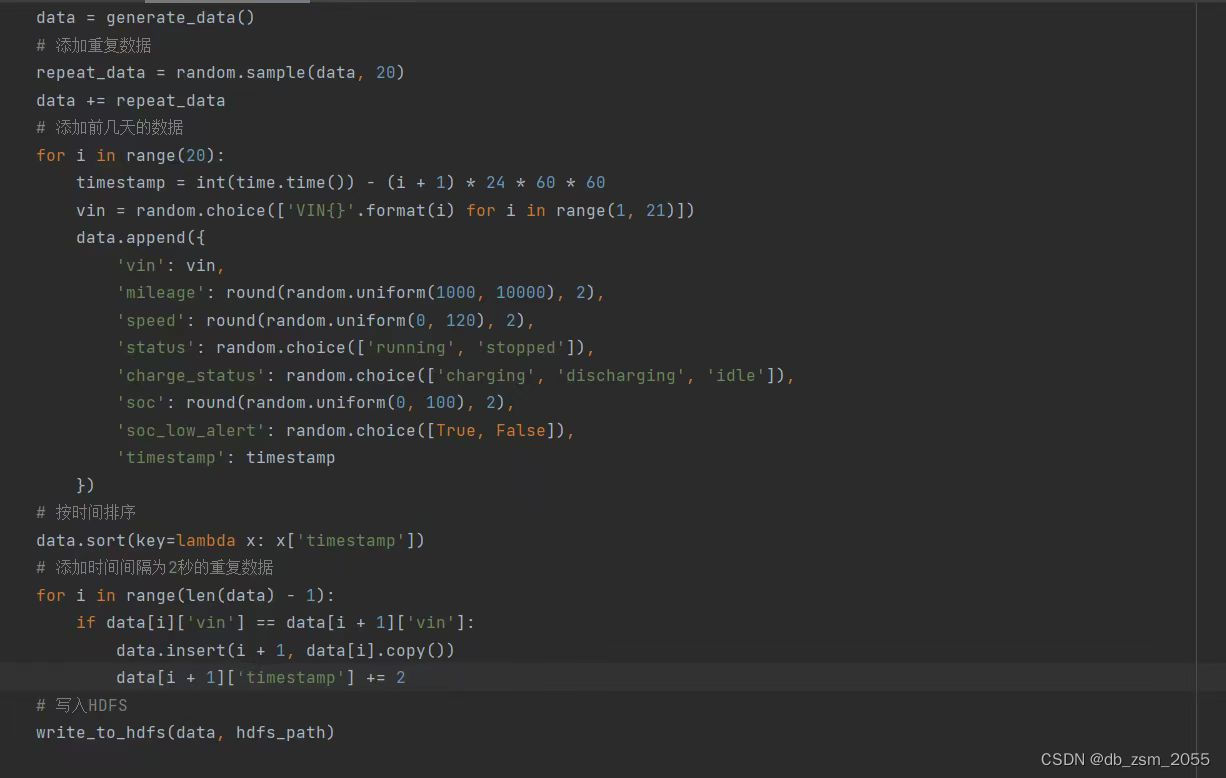
代码示例:
data = generate_data() #添加重复数据 repeat_data = random.sample(data, 20) data += repeat_data #添加前几天的数据 for i in range(20): timestamp = int(time.time()) - (i + 1) * 24 * 60 * 60 vin = random.choice(['VIN{}'.format(i) for i in range(1,21)]) data.append({ ' vin': vin, 'mileage': round(random.uniform(1000,10000),2), 'speed': round(random.uniform(0,120), 2), ' status': random.choice(['running','stopped']), 'charge_status': random.choice(['charging','discharging','idle']), ' soc': round(random.uniform(0, 100),2), 'soc_Low_alert': random.choice([True, False]), 'timestamp': timestamp }) #按时间排序 data.sort(key=lambda x: x['timestamp']) #添加时间间隔为2秒的重复数据 for i in range(len(data) - 1): if data[i]['vin'] == data[i + 1]['vin']: data.insert(i + 1,data[i].copy()) data[i + 1]['timestamp'] += 2 #写入HDFS write_to_hdfs(data, hdfs_path)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
3. 最终部署,将这些数据写到HDFS中。
1.打包生成jar包,并提交至Hadoop集群运行
2.设置定时任务,规定每天凌晨三点的第一分钟运行一次
三、学习收获
互联网的快速发展带来了数据快速增加,海量数据的存储已经不是一台机器所能处理的问题了。Hadoop的技术就应运而生。在本学期中专业老师的授课下,我对于这个概念有了一个比较系统的了解。
大数据Hadoop是一个非常重要的实际项目,对于所有想要了解大数据和Hadoop生态系统的人来说都是一个很好的机会。在课上课后的实操过程中,我不仅学到了Hadoop的基础知识,同时也学到了如何使用Hadoop来处理大数据。实操的过程需要我们掌握一些关于大数据的技能,如如何使用MapReduce算法,以及如何使用IDEA API来进行大数据分析。
总的来说,通过学习本学期这门课程,我对大数据和Hadoop系统有了较深入的了解,并且也加深了我的实操应用能力。我相信,随着大数据和人工智能的不断发展,这项技能将在未来发挥更大的作用。

