
- 1超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门
- 2【Doris】Doris 最佳实践-Compaction调优(3)_doris中如何查看哪个表的版本有堆积?
- 3⑩② 【MySQL索引】详解MySQL`索引`:结构、分类、性能分析、设计及使用规则。_mysql 索引名带`
- 4CentOS 7.6 防火墙打开、关闭,端口开启、关闭_centos7.6开放端口命令
- 5李宏毅-2023春机器学习 ML2023 SPRING-学习笔记:2/24 正确认识chatGPT_李宏毅2023gpt
- 6yaw(pan)/pitch(tilt)/roll计算_yaw pitch roll计算
- 7Vivado PLL锁相环 IP核的使用
- 8雪花id如何保证连续且不重复
- 9解决ssh:connect to host github.com port 22: Connection timed out与kex_exchange_identification_cloning into 'gonganzichan'... ssh: connect to hos
- 10循环队列的初始化,入队,出队,求队长,取队头元素_循环队列初始化
大语言模型开源数据集_mnbvc 论文
赞
踩
本文目标:汇聚目前大语言模型预训练、微调、RM/RL、评测等全流程所需的常见数据集,方便大家使用,本文持续更新。文章篇幅较长,建议收藏后使用。
一、按语料类型分类
1、维基百科类
No.1 Identifying Machine-Paraphrased Plagiarism
● 发布方:德国伍珀塔尔大学 · 布尔诺孟德尔大学
● 发布时间:2021
● 简介: 该数据集用于训练和评估用于检测机器释义文本的模型。训练集包含从 8,024 篇维基百科(英文)文章(4,012 篇原文,4,012 篇使用 SpinBot API 释义)中提取的 200,767 段(98,282 篇原文,102,485 篇释义)。测试集分为 3 个子集:一个来自 arXiv 研究论文的预印本,一个来自毕业论文,另一个来自 Wikipedia 文章。此外,还使用了不同的 Marchine-paraphrasing 方法。
● 下载地址: https://opendatalab.org.cn/Identifying_Machine-Paraphrased_etc
No.2 Benchmark for Neural Paraphrase Detection
● 发布方:德国伍珀塔尔大学
● 发布时间:2021
● 简介: 这是神经释义检测的基准,用于区分原始内容和机器生成的内容。训练:从 4,012 篇(英文)维基百科文章中提取 1,474,230 个对齐的段落(98,282 个原始段落,1,375,948 个用 3 个模型和 5 个超参数配置进行释义的段落,每个 98,282 个)。
● 下载地址: https://opendatalab.org.cn/Benchmark_for_Neural_Paraphrase_etc
No.3 NatCat
● 发布时间:2021
● 简介: 来自三个在线资源的通用文本分类数据集 (NatCat):Wikipedia、Reddit 和 Stack Exchange。这些数据集由源自社区自然发生的手动管理的文档-类别对组成。
● 下载地址: https://opendatalab.org.cn/NatCat
No.4 Quoref
● 发布方:艾伦人工智能研究所 · 华盛顿大学
● 发布时间:2019
● 简介: Quoref 是一个 QA 数据集,用于测试阅读理解系统的共指推理能力。在这个跨度选择基准包含来自维基百科的 4.7K 段落中的 24K 问题,系统必须先解决硬共指,然后才能在段落中选择适当的跨度来回答问题。
● 下载地址: https://opendatalab.com/Quoref
No.5 QuAC (Question Answering in Context)
● 发布方:艾伦人工智能研究所 · 华盛顿大学 · 斯坦福大学 · 马萨诸塞大学阿默斯特分校
● 发布时间:2018
● 简介: 上下文问答是一个大规模的数据集,由大约 14K 众包问答对话和总共 98K 问答对组成。数据实例包括两个群众工作者之间的交互式对话:(1)提出一系列自由形式问题以尽可能多地了解隐藏的维基百科文本的学生,以及(2)通过提供简短摘录来回答问题的老师(跨越)来自文本。
● 下载地址: https://opendatalab.org.cn/QuAC
No.6 TriviaQA
● 发布方:华盛顿大学 · 艾伦人工智能研究所
● 发布时间:2017
● 简介: TriviaQA 是一个现实的基于文本的问答数据集,其中包括来自维基百科和网络的 662K 文档中的 950K 问答对。该数据集比斯坦福问答数据集(SQuAD)等标准 QA 基准数据集更具挑战性,因为问题的答案可能无法通过跨度预测直接获得,而且上下文很长。TriviaQA 数据集由人工验证和机器生成的 QA 子集组成。
● 下载地址: https://opendatalab.org.cn/TriviaQA
No.7 WikiQA (Wikipedia open-domain Question Answering)
● 发布方:微软研究院
● 发布时间:2015
● 简介: WikiQA 语料库是一组公开可用的问题和句子对,收集和注释用于研究开放域问答。为了反映一般用户的真实信息需求,使用必应查询日志作为问题来源。每个问题都链接到一个可能有答案的维基百科页面。由于 Wikipedia 页面的摘要部分提供了有关该主题的基本且通常最重要的信息,因此本部分中的句子被用作候选答案。该语料库包括 3,047 个问题和 29,258 个句子,其中 1,473 个句子被标记为相应问题的答案句。
● 下载地址: https://opendatalab.org.cn/WikiQA
2、书籍类
No.1 The Pile
● 发布方:EleutherAI
● 发布时间:2020
● 简介: The Pile 是一个 825 GiB 多样化的开源语言建模数据集,由 22 个较小的高质量数据集组合在一起组成。
● 下载地址: https://openxlab.org.cn/datasets?keywords=pile&lang=zh-CN&pageNo=1&pageSize=12
No.2 BookCorpus
● 发布方:多伦多大学 · 麻省理工学院
● 发布时间:2015
● 简介: BookCorpus是由未出版的作者撰写的大量免费小说书籍,其中包含16种不同子流派 (例如,浪漫,历史,冒险等) 的11,038本书 (约74m句子和1g单词)。
● 下载地址: https://opendatalab.org.cn/BookCorpus
No.3 EXEQ-300k
● 发布方:北京大学 · 宾夕法尼亚州立大学 · 中山大学
● 发布时间:2020
● 简介: EXEQ-300k 数据集包含 290,479 个详细问题以及来自数学堆栈交换的相应数学标题。该数据集可用于从详细的数学问题中生成简洁的数学标题。
● 下载地址: https://opendatalab.org.cn/EXEQ-300k
3、期刊类
No.1 Pubmed
● 发布方:马里兰大学
● 发布时间:2008
● 简介: Pubmed 数据集包含来自 PubMed 数据库的 19717 篇与糖尿病相关的科学出版物,分为三类之一。引文网络由 44338 个链接组成。数据集中的每个出版物都由字典中的 TF/IDF 加权词向量描述,该字典由 500 个唯一词组成。
● 下载地址: https://opendatalab.org.cn/Pubmed
No.2 PubMed Paper Reading Dataset
● 发布方:伊利诺伊大学厄巴纳香槟分校 · 滴滴实验室 · 伦斯勒理工学院 · 北卡罗来纳大学教堂山分校 · 华盛顿大学
● 发布时间:2019
● 简介: 该数据集从 PubMed 收集了 14,857 个实体、133 个关系以及对应于标记化文本的实体。它包含 875,698 个训练对、109,462 个开发对和 109,462 个测试对。
● 下载地址: https://opendatalab.org.cn/PubMed_Paper_Reading_Dataset
No.3 PubMed RCT (PubMed 200k RCT)
● 发布方:Adobe Research · 麻省理工学院
● 发布时间:2017
● 简介: PubMed 200k RCT 是基于 PubMed 的用于顺序句子分类的新数据集。该数据集由大约 200,000 个随机对照试验摘要组成,总计 230 万个句子。每个摘要的每个句子都使用以下类别之一标记其在摘要中的角色:背景、目标、方法、结果或结论。发布此数据集的目的是双重的。首先,用于顺序短文本分类(即对出现在序列中的短文本进行分类)的大多数数据集都很小:作者希望发布一个新的大型数据集将有助于为这项任务开发更准确的算法。其次,从应用的角度来看,研究人员需要更好的工具来有效地浏览文献。自动对摘要中的每个句子进行分类将有助于研究人员更有效地阅读摘要,尤其是在摘要可能很长的领域,例如医学领域。
● 下载地址: https://opendatalab.org.cn/PubMed_RCT
No.4 MedHop
● 发布方:伦敦大学学院 · Bloomsbury AI
● 发布时间:2018
● 简介: 与 WikiHop 格式相同,MedHop 数据集基于 PubMed 的研究论文摘要,查询是关于药物对之间的相互作用。必须通过结合来自药物和蛋白质的一系列反应的信息来推断出正确的答案。
● 下载地址: https://opendatalab.org.cn/MedHop
No.5 ArxivPapers
● 发布方:Facebook · 伦敦大学学院 · DeepMind
● 发布时间:2020
● 简介: ArxivPapers 数据集是 2007 年至 2020 年间在 http://arXiv.org 上发表的超过 104K 篇与机器学习相关的未标记论文集合。该数据集包括大约 94K 篇论文(可以使用 LaTeX 源代码),这些论文采用结构化形式,其中论文分为标题、摘要、部分、段落和参考文献。此外,该数据集包含从 LaTeX 论文中提取的超过 277K 表。由于论文许可,数据集作为元数据和开源管道发布,可用于获取和转换论文。
● 下载地址: https://opendatalab.org.cn/ArxivPapers
No.6 unarXive
● 发布方:Karlsruhe Institute of Technology
● 发布时间:2020
● 简介: 包含出版物全文、带注释的文本引用和元数据链接的学术数据集。unarXive 数据集包含 100 万篇纯文本论文 6300 万引文上下文 3900 万参考字符串 1600 万个连接的引文网络 数据来自 1991 年至 2020/07 年期间 arXiv 上的所有 LaTeX 源,因此质量高于生成的数据从 PDF 文件。此外,由于所有施引论文均以全文形式提供,因此可以提取任意大小的引文上下文。数据集的典型用途是引文推荐中的方法 引文上下文分析 参考字符串解析 生成数据集的代码是公开的。
● 下载地址: https://opendatalab.org.cn/unarXive
No.7 arXiv Summarization Dataset
● 发布方:Georgetown University · Adobe Research
● 发布时间:2018
● 简介: 这是一个用于评估研究论文摘要方法的数据集。
● 下载地址: https://opendatalab.org.cn/arXiv_Summarization_Dataset
No.8 SCICAP
● 发布方:宾夕法尼亚州立大学
● 发布时间:2021
● 简介: SciCap一种基于计算机科学arXiv论文的大型图形字幕数据集,2010年发表,2020年。SCICAP包含超过416k个图形,这些图形集中在从290,000多篇论文中提取的一个显性图形类型-图形图。
● 下载地址: https://opendatalab.org.cn/SCICAP
No.9 MathMLben (Formula semantics benchmark)
● 发布方:康斯坦茨大学 · 美国国家标准技术研究所
● 发布时间:2017
● 简介: MathMLben 是用于数学格式转换(LaTeX ↔ MathML ↔ CAS)的评估工具的基准。它包含从 NTCIR 11/12 arXiv 和 Wikipedia 任务/数据集、NIST 数学函数数字图书馆 (DLMF) 和使用 AnnoMathTeX 公式和标识符名称推荐系统 (https://annomathtex.wmflabs.组织)。
● 下载地址: https://opendatalab.org.cn/MathMLben
4、Reddit内容聚合社区类
No.1 OpenWebText
● 发布方:华盛顿大学 · Facebook AI Research
● 发布时间:2019
● 简介: OpenWebText 是 WebText 语料库的开源再造。该文本是从 Reddit 上共享的 URL 中提取的 Web 内容,至少获得了 3 次赞成(38GB)。
● 下载地址: https://opendatalab.org.cn/OpenWebText
5、Common Crawl网络爬虫开放数据库
No.1 C4 (Colossal Clean Crawled Corpus)
● 发布方:Google Research
● 发布时间:2020
● 简介: C4 是 Common Crawl 的网络爬虫语料库的一个巨大的、干净的版本。它基于 Common Crawl 数据集:https://commoncrawl.org。它用于训练 T5 文本到文本的 Transformer 模型。可以从 allennlp 以预处理的形式下载数据集。
● 下载地址: https://opendatalab.org.cn/C4
No.2 Common Crawl
● 发布方:法国国家信息与自动化研究所 · 索邦大学
● 发布时间:2019
● 简介: Common Crawl 语料库包含在 12 年的网络爬取过程中收集的 PB 级数据。语料库包含原始网页数据、元数据提取和文本提取。Common Crawl 数据存储在 Amazon Web Services 的公共数据集和全球多个学术云平台上。
● 下载地址: https://opendatalab.org.cn/Common_Crawl
6、其他类
6.1 代码数据集
No.1 CodeSearchNet
● 发布方:微软研究院 · GitHub
● 发布时间:2020
● 简介: CodeSearchNet 语料库是一个大型函数数据集,其中包含来自 GitHub 上的开源项目的用 Go、Java、JavaScript、PHP、Python 和 Ruby 编写的相关文档。CodeSearchNet 语料库包括:* 总共 600 万个方法 * 其中 200 万个方法具有相关文档(文档字符串、JavaDoc 等) * 指示找到数据的原始位置(例如存储库或行号)的元数据。
● 下载地址: https://opendatalab.org.cn/CodeSearchNet
No.2 StaQC
● 发布方:俄亥俄州立大学 · 华盛顿大学 · 富士通研究所
● 发布时间:2018
● 简介: StaQC(Stack Overflow 问题代码对)是迄今为止最大的数据集,大约有 148K Python 和 120K SQL 域问题代码对,它们是使用 Bi-View Hierarchical Neural Network 从 Stack Overflow 中自动挖掘出来的。
● 下载地址: https://opendatalab.org.cn/StaQC
No.3 CodeExp
● 发布方:北京航空航天大学 · 微软研究院 · 多伦多大学
● 发布时间:2022
● 简介: 我们提供了一个python代码-docstring语料库CodeExp,其中包含 (1) 2.3的大分区 百万原始代码-docstring对,(2) 一个介质 158,000对的分区从 使用学习的过滤器的原始语料库,以及 (3) 具有严格的人类13,000对的分区 注释。我们的数据收集过程利用了从人类那里学到的注释模型 自动过滤高质量的注释 来自原始GitHub数据集的代码-docstring对。
● 下载地址: https://opendatalab.org.cn/CodeExp
No.4 ETH Py150 Open
● 发布方:印度科学理工学院 · Google AI Research
● 发布时间:2020
● 简介: 来自 GitHub 的 740 万个 Python 文件的大规模去重语料库。
● 下载地址: https://opendatalab.org.cn/ETH_Py150_Open
6.2 论坛数据集
No.1 Federated Stack Overflow
● 发布方:Google Research
● 发布时间:2022
● 简介: 数据由所有问题和答案的正文组成。Body被解析成句子,任何少于 100 个句子的用户都会从数据中删除。最少的预处理如下进行:小写文本, 对 HTML 符号进行转义, 删除非ASCII符号, 单独的标点符号作为单独的标记(撇号和连字符除外), 去除多余的空白, 用特殊标记替换 URLS。此外,还提供以下元数据:创建日期 问题标题 问题标签 问题分数 类型(“问题”或“答案”)。
● 下载地址: https://opendatalab.org.cn/Federated_Stack_Overflow
No.2 QUASAR (QUestion Answering by Search And Reading)
● 发布方:卡内基梅隆大学
● 发布时间:2017
● 简介: 搜索和阅读问答(QUASAR)是一个由QUASAR-S和QUASAR-T组成的大规模数据集。这些数据集中的每一个都旨在专注于评估旨在理解自然语言查询、大量文本语料库并从语料库中提取问题答案的系统。具体来说,QUASAR-S 包含 37,012 个填空题,这些问题是使用实体标签从流行的网站 Stack Overflow 收集的。QUASAR-T 数据集包含从各种互联网资源收集的 43,012 个开放域问题。该数据集中每个问题的候选文档是从基于 Apache Lucene 的搜索引擎中检索的,该搜索引擎构建在 ClueWeb09 数据集之上。
● 下载地址: https://opendatalab.org.cn/QUASAR
No.3 GIF Reply Dataset
● 发布方:卡内基梅隆大学
● 发布时间:2017
● 简介: 发布的 GIF 回复数据集包含 1,562,701 次 Twitter 上的真实文本 - GIF 对话。在这些对话中,使用了 115,586 个独特的 GIF。元数据,包括 OCR 提取的文本、带注释的标签和对象名称,也可用于该数据集中的一些 GIF。
● 下载地址: https://opendatalab.org.cn/GIF_Reply_Dataset
6.3 视频字幕数据集
No.1 TVC (TV show Captions)
● 发布方:北卡罗来纳大学教堂山分校
● 发布时间:2020
● 简介: 电视节目 Caption 是一个大规模的多模态字幕数据集,包含 261,490 个字幕描述和 108,965 个短视频片段。TVC 是独一无二的,因为它的字幕也可以描述对话/字幕,而其他数据集中的字幕仅描述视觉内容。
● 下载地址: https://opendatalab.org.cn/TVC
二、按训练阶段分类
1、预训练数据集
NO.1 MNBVC
- 地址:https://github.com/esbatmop/MNBVC
- 数据集说明:超大规模中文语料集,不但包括主流文化,也包括各个小众文化甚至火星文的数据。MNBVC数据集包括新闻、作文、小说、书籍、杂志、论文、台词、帖子、wiki、古诗、歌词、商品介绍、笑话、糗事、聊天记录等一切形式的纯文本中文数据。数据均来源于互联网收集,且在持续更新中。
NO.2 WuDaoCorporaText
- 地址:https://data.baai.ac.cn/details/WuDaoCorporaText
- 数据集说明:WuDaoCorpora是北京智源人工智能研究院(智源研究院)构建的大规模、高质量数据集,用于支撑大模型训练研究。目前由文本、对话、图文对、视频文本对四部分组成,分别致力于构建微型语言世界、提炼对话核心规律、打破图文模态壁垒、建立视频文字关联,为大模型训练提供坚实的数据支撑。
NO.3 CLUECorpus2020
- 地址:https://github.com/CLUEbenchmark/CLUECorpus2020
- 数据集说明:通过对Common Crawl的中文部分进行语料清洗,最终得到100GB的高质量中文预训练语料,可直接用于预训练、语言模型或语言生成任务以及专用于简体中文NLP任务的小词表。
NO.4 WanJuan-1.0
- 地址:https://opendatalab.org.cn/WanJuan1.0
- 数据集说明:书生·万卷1.0为书生·万卷多模态语料库的首个开源版本,包含文本数据集、图文数据集、视频数据集三部分,数据总量超过2TB。 目前,书生·万卷1.0已被应用于书生·多模态、书生·浦语的训练。通过对高质量语料的“消化”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出的优异性能。
2、SFT数据集
NO.1 RefGPT:基于RefGPT生成大量真实和定制的对话数据集
- 地址:GitHub - DA-southampton/RedGPT
- 数据集说明:包括RefGPT-Fact和RefGPT-Code两部分,其中RefGPT-Fact给出了5万中文的关于事实性知识的多轮对话,RefGPT-Code给出了3.9万中文编程相关的多轮对话数据。
NO.2 COIG
- 地址:https://huggingface.co/datasets/BAAI/COIG
- 数据集说明:维护了一套无害、有用且多样化的中文指令语料库,包括一个人工验证翻译的通用指令语料库、一个人工标注的考试指令语料库、一个人类价值对齐指令语料库、一个多轮反事实修正聊天语料库和一个 leetcode 指令语料库。
NO.3 generated_chat_0.4M
- 地址:https://huggingface.co/datasets/BelleGroup/generated_chat_0.4M
- 数据集说明:包含约40万条由BELLE项目生成的个性化角色对话数据,包含角色介绍。但此数据集是由ChatGPT产生的,未经过严格校验,题目或解题过程可能包含错误。
NO.4 alpaca_chinese_dataset
- 地址:GitHub - hikariming/alpaca_chinese_dataset: 人工精调的中文对话数据集和一段chatglm的微调代码
- 数据集说明:根据斯坦福开源的alpaca数据集进行中文翻译,并再制造一些对话数据
NO.5 Alpaca-CoT
- 地址:https://github.com/PhoebusSi/Alpaca-CoT
- 数据集说明:统一了丰富的IFT数据(如CoT数据,目前仍不断扩充)、多种训练效率方法(如lora,p-tuning)以及多种LLMs,三个层面上的接口,打造方便研究人员上手的LLM-IFT研究平台。
NO.6 pCLUE
- 地址:GitHub - CLUEbenchmark/pCLUE: pCLUE: 1000000+多任务提示学习数据集
- 数据集说明:基于提示的大规模预训练数据集,用于多任务学习和零样本学习。包括120万训练数据,73个Prompt,9个任务。
NO.7 firefly-train-1.1M
- 地址:https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
- 数据集说明:23个常见的中文数据集,对于每个任务,由人工书写若干种指令模板,保证数据的高质量与丰富度,数据量为115万
NO.8 BELLE-data-1.5M
- 地址:BELLE/data/1.5M at main · LianjiaTech/BELLE · GitHub
- 数据集说明:通过self-instruct生成,使用了中文种子任务,以及openai的text-davinci-003接口,涉及175个种子任务
NO.9 Chinese Scientific Literature Dataset
- 地址:GitHub - ydli-ai/CSL: [COLING 2022] CSL: A Large-scale Chinese Scientific Literature Dataset 中文科学文献数据集
- 数据集说明:中文科学文献数据集(CSL),包含 396,209 篇中文核心期刊论文元信息 (标题、摘要、关键词、学科、门类)以及简单的prompt
NO.11 Chinese medical dialogue data
- 地址:GitHub - Toyhom/Chinese-medical-dialogue-data: Chinese medical dialogue data 中文医疗对话数据集
- 数据集说明:中文医疗对话数据集,包括:<Andriatria_男科> 94596个问答对 <IM_内科> 220606个问答对 <OAGD_妇产科> 183751个问答对 <Oncology_肿瘤科> 75553个问答对 <Pediatric_儿科> 101602个问答对 <Surgical_外科> 115991个问答对 总计 792099个问答对。
NO.12 Huatuo-26M
- 地址:GitHub - FreedomIntelligence/Huatuo-26M: The Largest-scale Chinese Medical QA Dataset: with 26,000,000 question answer pairs.
- 数据集说明:Huatuo-26M 是一个中文医疗问答数据集,此数据集包含了超过2600万个高质量的医疗问答对,涵盖了各种疾病、症状、治疗方式、药品信息等多个方面。Huatuo-26M 是研究人员、开发者和企业为了提高医疗领域的人工智能应用,如聊天机器人、智能诊断系统等需要的重要资源。
NO.13 Alpaca-GPT-4
- 地址:GitHub - Instruction-Tuning-with-GPT-4/GPT-4-LLM: Instruction Tuning with GPT-4
- 数据集说明:Alpaca-GPT-4 是一个使用 self-instruct 技术,基于 175 条中文种子任务和 GPT-4 接口生成的 50K 的指令微调数据集。
NO.14 InstructionWild
- 地址:GitHub - XueFuzhao/InstructionWild
- 数据集说明:InstructionWild 是一个从网络上收集自然指令并过滤之后使用自然指令结合 ChatGPT 接口生成指令微调数据集的项目。主要的指令来源:Twitter、CookUp.AI、Github 和 Discard。
NO.15 ShareChat
- 地址:ParaTranz
- 数据集说明:一个倡议大家一起翻译高质量 ShareGPT 数据的项目。
- 项目介绍:清洗/构造/翻译中文的ChatGPT数据,推进国内AI的发展,人人可炼优质中文 Chat 模型。本数据集为ChatGPT约九万个对话数据,由ShareGPT API获得(英文68000,中文11000条,其他各国语言)。项目所有数据最终将以 CC0 协议并入 Multilingual Share GPT 语料库。
NO.16 Guanaco
- 地址:https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
- 数据集说明:一个使用 Self-Instruct 的主要包含中日英德的多语言指令微调数据集。
NO.17 chatgpt-corpus
- 地址:GitHub - PlexPt/chatgpt-corpus: ChatGPT 中文语料库 对话语料 小说语料 客服语料 用于训练大模型
- 数据集说明:开源了由 ChatGPT3.5 生成的300万自问自答数据,包括多个领域,可用于用于训练大模型。
NO.18 SmileConv
- 地址:GitHub - qiuhuachuan/smile: SMILE: Single-turn to Multi-turn Inclusive Language Expansion via ChatGPT for Mental Health Support paper:
- 数据集说明:数据集通过ChatGPT改写真实的心理互助 QA为多轮的心理健康支持多轮对话(single-turn to multi-turn inclusive language expansion via ChatGPT),该数据集含有56k个多轮对话,其对话主题、词汇和篇章语义更加丰富多样,更加符合在长程多轮对话的应用场景。
3、RM/RL数据集
NO.1 CValues
- 地址:GitHub - X-PLUG/CValues: 面向中文大模型价值观的评估与对齐研究
- 数据集说明:该项目开源了数据规模为145k的价值对齐数据集,该数据集对于每个prompt包括了拒绝&正向建议 (safe and reponsibility) > 拒绝为主(safe) > 风险回复(unsafe)三种类型,可用于增强SFT模型的安全性或用于训练reward模型。
NO.2 GPT-4-LLM
- 地址:GitHub - Instruction-Tuning-with-GPT-4/GPT-4-LLM: Instruction Tuning with GPT-4
- 数据集说明:该项目开源了由GPT4生成的多种数据集,包括通过GPT4生成的中英PPO数据,可以用于奖励模型的训练。
NO.3 hihu_rlhf_3k
- 地址:https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k
- 数据集说明:该项目开源了3k+条基于知乎问答的人类偏好数据集,每个实际的知乎问题下给出了赞同数据较高(chosen)和较低(rejected)的回答,可以用于奖励模型的训练。
NO.4 hh_rlhf_cn
- 地址:https://huggingface.co/datasets/dikw/hh_rlhf_cn
- 数据集说明:基于Anthropic论文Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback 开源的helpful 和harmless数据,使用翻译工具进行了翻译。
NO.5 chatbot_arena_conversations
- 地址:https://huggingface.co/datasets/lmsys/chatbot_arena_conversations
- 数据集说明:该偏好数据集包含20个LLM的输出,其中包括GPT-4和Claude-v1等更强的LLM,它还包含这些最先进模型的许多失败案例。包含来自超过13K个用户的无限制对话。
NO.6 UltraFeedback
- 地址:GitHub - OpenBMB/UltraFeedback: A large-scale, fine-grained, diverse preference dataset (and models).
- 数据集说明:该数据集是一个大规模、细粒度、多样化的偏好数据集,用于训练强大的奖励模型和批评者模型。该工作从各种资源(包括UltraChat、ShareGPT、Evol-Instruct、TruthfulQA、FalseQA和FLAN,数据集统计数据请参见此处)中收集了约64k条提示。然后使用这些提示来查询多个LLM,并为每个提示生成4个不同的回复,从而得到总共256k个样本。
4、评测数据集
4.1 中文评测数据
NO. 1 C-Eval:学科知识评测集
- 范围广泛:人文、社科、理工等52个学科。
- 数据形式:13948道单选题,涉及52个学科,4类不同难度(初中、高中、大学、专业)。
- 论文:https://arxiv.org/pdf/2305.08322.pdf
- 评测代码:https://github.com/hkust-nlp/ceval
- 排行榜:C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models
- 一句话评价:C-Eval整体围绕学科知识,覆盖范围广、难度跨度合适,选择题适合快速评测,但是缺乏对生成表达能力的考察。

NO.2 CMMLU:中文多任务语言理解评估
- 范围广泛:常识类、人文、社科、理工等共67个主题(详见下图)
- 难易平衡:小学、中学、大学均有涉及
- 数据形式:11,528道单选题,其中67个主题每个主题至少105道题
- 论文:https://arxiv.org/pdf/2306.09212.pdf
- 评测代码:https://github.com/haonan-li/CMMLU
- Huggingface: haonan-li/cmmlu · Datasets at Hugging Face
- 一句话评价:CMMLU整体围绕学科知识,覆盖范围广、难度跨度合适,选择题适合快速评测,但是缺乏对生成表达能力的考察。

NO.3 GaoKao:中国高考试题
- 评测范围:2010-2022年高考试卷,包括文科和理科。
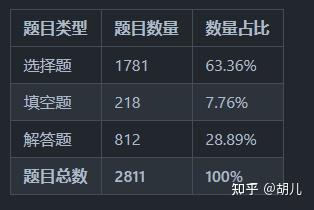
- 数据形式:2811道题目,包括选择、填空、解答,具体分布见下图。
- 论文:https://arxiv.org/pdf/2305.12474.pdf
- 评测代码: https://github.com/OpenLMLab/GAOKAO-Bench
- 一句话评价:GaoKao本身数据质量较高,但是范围较窄、难度跨度小。评测分为客观和主观评测,主观评测需要人工参与,成本较高。
NO.4 SuperCLUE
- 项目:GitHub - CLUEbenchmark/SuperCLUE: SuperCLUE: 中文通用大模型综合性基准 | A Benchmark for Foundation Models in Chinese
- 介绍:SuperCLUE是一个综合性大模型评测基准,本次评测主要聚焦于大模型的四个能力象限,包括语言理解与生成、专业技能与知识、Agent智能体和安全性,进而细化为12项基础能力。
NO.5 AGIEval
- 项目:GitHub - ruixiangcui/AGIEval
- 介绍:AGIEval 是一个用于评估基础模型在标准化考试(如高考、公务员考试、法学院入学考试、数学竞赛和律师资格考试)中表现的数据集。AGIEval 是一个以人为中心的基准测试,专门用于评估基础模型在与人类认知和解决问题相关的任务中的一般能力。该基准源自 20 项针对普通人类考生的官方、公开和高标准的入学和资格考试,例如普通大学入学考试(例如,中国高考(高考)和美国 SAT)、法学院入学考试、数学竞赛、律师资格考试和国家公务员考试。
4.2 英文评测数据
NO.1 MMLU(Measuring Massive Multitask Language Understanding)
- 范围广泛:57个任务,涵盖人文、社科、理工等;也包括了不同难度水平。
- 数据形式:15908道单选题
- 论文:Measuring Massive Multitask Language Understanding (arxiv.org)
- 排行榜:MMLU Benchmark (Multi-task Language Understanding) | Papers With Code
- 一句话点评:MMLU偏学科知识的考察,涉及模型的知识储备和理解能力。缺少对生成能力和安全价值观的考察。
NO.2 GSM8K 小学数学题
- 8.5千道高质量小学数学题,由人工编写答案。其中7.5K是训练集,1K是测试集。
- 论文:https://arxiv.org/pdf/2110.14168.pdf
- 排行榜:https://paperswithcode.com/sota/arithmetic-reasoning-on-gsm8k
- 一句话点评:GSM8K 由数学题组成,主要考察模型的理解和推理能力。
NO.3 winogrande
- 项目:GitHub - allenai/winogrande: WinoGrande: An Adversarial Winograd Schema Challenge at Scale
- 数据集:https://huggingface.co/datasets/winogrande
- 介绍:WinoGrande 是 44k 问题的新集合,受 Winograd Schema Challenge(Levesque、Davis 和 Morgenstern 2011)的启发,进行了调整以提高针对数据集特定偏差的规模和鲁棒性。表述为带有二元选项的填空任务,目标是为需要常识推理的给定句子选择正确的选项。
NO.4 MATH
- 项目:GitHub - hendrycks/math: The MATH Dataset (NeurIPS 2021)
- 介绍:MATH 是一个由数学竞赛问题组成的评测集,由 AMC 10、AMC 12 和 AIME 等组成,包含 7.5K 训练数据和 5K 测试数据。
NO.5 HumanEval
- 数据集:https://huggingface.co/datasets/openai_humaneval
- HumanEval 是由 OpenAI 发布的 164 个手写的编程问题,包括模型语言理解、推理、算法和简单数学等任务
NO.6 BBH
- 数据集:https://huggingface.co/datasets/lukaemon/bbh
- 布尔类型的表达式推理判断
NO.7 MBPP
- 数据集:https://huggingface.co/datasets/mbpp
- 该基准测试由大约 1,000 个众包 Python 编程问题组成,旨在由入门级程序员解决,涵盖编程基础知识、标准库功能等。每个问题都由任务描述、代码解决方案和 3 个自动化测试用例组成。
NO.8 AI2 ARC
- 数据集:https://huggingface.co/datasets/ai2_arc
- 一个由7787个真正的小学水平的多项选择科学问题组成的新数据集,旨在鼓励对高级问答的研究。数据集分为挑战集和简单集,其中前者仅包含由基于检索的算法和单词共现算法错误回答的问题。我们还包括一个包含超过 1400 万个与该任务相关的科学句子的语料库,以及该数据集的三个神经基线模型的实现。我们将ARC视为对社区的挑战。
NO.9 HellaSwag
- 论文地址:HellaSwag: Can a Machine Really Finish Your Sentence?
- 数据集地址:Rowan/hellaswag · Datasets at Hugging Face
- 介绍:用于测试模型的常识推理能力,比如问题是:”一个苹果掉下来,然后“,hellaSwag 提供了及个选项 "果农接住了它", ”牛顿被砸到了“等等,看模型能否从中选中最佳答案。
NO.10 TruthfulQA
- 论文地址:TruthfulQA: Measuring How Models Mimic Human Falsehoods
- 数据集地址:truthful_qa · Datasets at Hugging Face
- 介绍:TruthfulQA 测评模型胡说八道的能力,TruthfulQA 分为 generation 和 multiple_choice 两个数据集。Huggingface Leaderboard 采用其中的多选题数据集 (TruthfulQA_mc),评测指标采用 mc2(选项中有多个正确选项)。
4.3 多语言测试数据集
NO.1 M3Exam
- 项目:GitHub - DAMO-NLP-SG/M3Exam: Data and code for paper "M3Exam: A Multilingual, Multimodal, Multilevel Benchmark for Examining Large Language Models"
- 包含 12317 个问题,涵盖从高资源语种例如中文英文,到低资源语种例如斯瓦希里语及爪哇语等9个语言。一个特点是所有问题均来源是当地的真实人类试题,所以包含了特定的文化背景,要求模型不仅是能理解语言,还需要对背景知识有所掌握。中文部分也公开了图片类试题,可以测试中文多模态模型。
NO.2 LongBench
- 数据集:GitHub - THUDM/LongBench: LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
- LongBench是第一个用于对大型语言模型进行双语、多任务、全面评估长文本理解能力的基准测试。
三、按公司/组织分类
1、huggingface.co开源数据集
链接:https://huggingface.co/datasets
镜像:Hugging Face – The AI community building the future.

2、opendatalab开源数据集
链接:OpenDataLab 引领AI大模型时代的开放数据平台

3、aws亚马逊开源数据集
链接:Registry of Open Data on AWS

4、微软开源数据集
链接:Researcher tools: code, datasets, & models - Microsoft Research

5、谷歌开源数据集
链接:https://datasetsearch.research.google.com/

6、github开源数据集
链接:GitHub - awesomedata/awesome-public-datasets: A topic-centric list of HQ open datasets.

7、modelscope开源数据集
链接:魔搭社区

8、luge千言开源数据集

9、tianchi天池开源数据集
链接:天池数据集_阿里系唯一对外开放数据分享平台-阿里云天池

10、kaggle开源数据集
链接:https://www.kaggle.com/datasets

11、uci开源数据集
链接:UCI Machine Learning Repository

12、计算机视觉开源数据集
链接:VisualData - Search Engine for Computer Vision Datasets

13、dataju聚数力开源数据集
链接:聚数力大数据平台 | 聚集数据的力量 | 大数据应用要素托管与交易平台

14、hyper超神经开源数据集
链接:数据集 / 超神经

15、baai开源数据集
链接:Data Hub

16、百度飞桨开源数据集

17、payititi帕衣提提开源数据集
链接:公开数据集 人工智能公开数据集—帕依提提-人工智能数据集开放平台

18、启智开源数据集
链接:Explore - OpenI - 启智AI开源社区提供普惠算力!

19、和鲸开源数据集

References

