
- 1CVPR 2022 | 南开程明明团队和天大提出LD:目标检测的定位蒸馏
- 2鸿蒙App开发,Button坑死你不偿命!_鸿蒙设置button不可点击
- 3Redis部署之哨兵
- 4大数据知识图谱之深度学习——基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统_bert+lstm+crf的识别模型
- 5可以不用KEPServer吗?上位机软件便捷、稳定、隐蔽地获取PLC数据的另外一种选择_类似kepserver的软件
- 6【MySQL】20. 使用C语言链接
- 7LLaMA Pro: Progressive LLaMA with Block Expansion
- 8网格搜索:GridSearchCV函数参数解释及示例_gridsearchcv官方文档
- 9PINN神经网络求解偏微分方程的11种方法【附论文和代码下载】
- 10开发5年!三面字节,成功拿到27k*17offer,原来也没那么难_字节二面比一面难很多吗
双数组字典树DoubleArrayTrie_double array trie
赞
踩
双数组Tire树是Tire树的存储结构上升级版。
在查询方面,双数组Tire树拥有Tire树的所有优点,而且刻服了Tire树浪费空间的不足。在插入和删除的时,往往需要对双数组结构进行全局调整,灵活性能较差。如果核心词典已经预先建立好并且有序的,并且不会添加或删除新词,那么这个缺点是可以忽略的。
标准Trie
向一棵树中插入“清华”、“清华大学”、“清新”、“中华”、“华人”,形成trie.
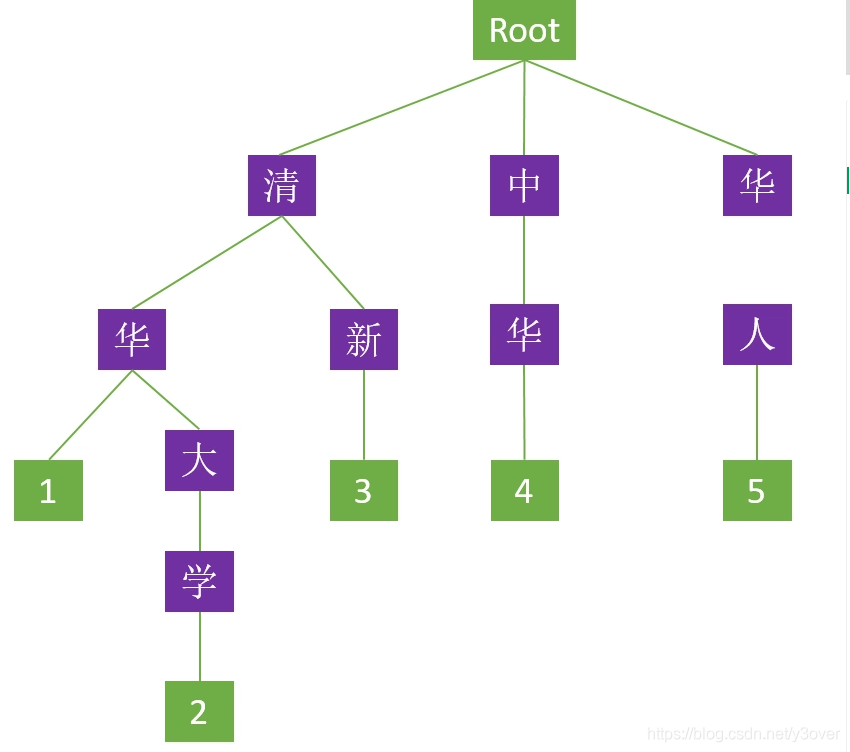
双数组结构
设例树的字符编码表为:[清-1,华-2,大-3,学-4,新-5,中-6,人-7](也可以用默认的统一字符编码)
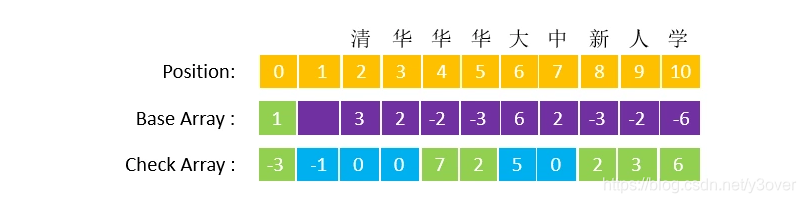
如图所示:
Position:数据下标,position = 0的时间为root
Base Array:转移基数数组,ROOT节点为1(可自定义),清的position位置确定为 base[0] + 1(清的编码) 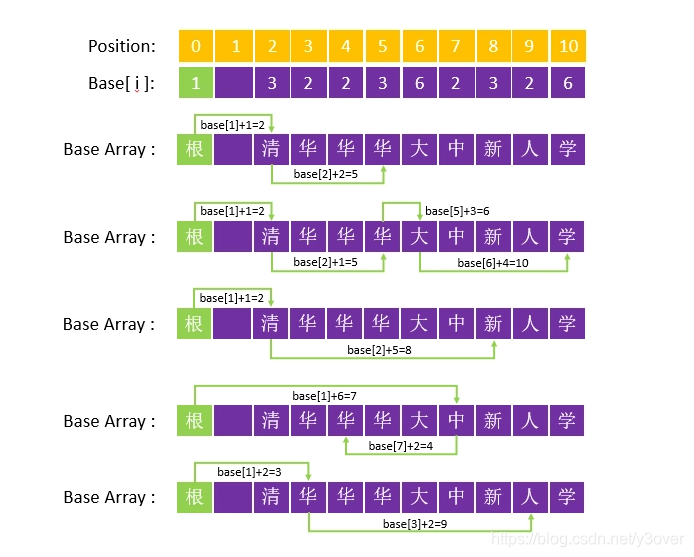
如何表示叶子节点?转移基数统一设置设为-1 * base[n], n为叶子节点的position
Check Array: 较验数组。check数组记录的提这个字的父亲节点的下标,例【清】其 check[2] = 0 指向ROOT
如果我们要在例树中确认外部的一个字符串“清中”是否是一个词,按照 Trie 树的查找规则,首先要查找“清”这个字,我们从根节点出发,获得|base[1]|+code(“清”)=3,然后转移到“清”节点,确认清在数组中存在,我们继续查找“中”,通过|base[3]|+code(“中”)=9获得位置9,字符串此时查询完毕,根据位置9的转移基数base[9]=-2确定该词在此终结,从而认为字符串“清中”是一个词。而这显然是错误的!所以加了check数组,发现check[9]=3指向“华”。
数组的构建
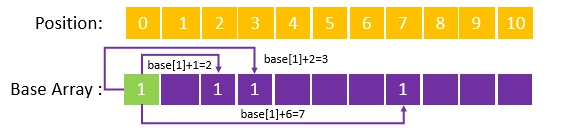
1.首先将五个词中的首字"清"、“中”、“华”写入数组之中,写入的位置由base[1]+code(字符)确定,每个位置的转移基数(base[i])等于上一个状态的转移基数(此例也即base[1]),这个过程未遇到冲突,最终结果见下图:
2.然后依次处理每个词的第二个字,首先需要整理相同前缀词(“清华”,“清新”)(“中华”),(“华人”),程序先从根节点出发,通过base[1]+code(“清”)=2找到“清”节点,然后以此计算“华”节点应写入的位置,通过计算base[2]+code(“华”)=3寻找到位置 3,却发现位置3已有值;将base[2] + 1 = 2.再通过计算base[2]+code(“华”)=4,base[2]+code(“新”) = 7,base[7] 又发现有值;base[2] + 1 =3,再通过计算base[2]+code(“华”)=5,base[2]+code(“新”) = 8,成功。 base[5]=base[8]=base[2]=3.(“中华”),(“华人”) 简单。注: 上述的 base[2] 表示 |base[s]| (因为可能是叶子结点,上面忘记写绝对值)
simple代码
- public class DoubleArrayTrie {
-
- String[] keys;// 字符集
- int[] base;// 转移数组
- int[] check;// 较验数组
-
- private static class Node {
-
- private int code;// 字符编码
-
- private int s;// 父字符位置
-
- @Override
- public boolean equals(Object o) {
- if (this == o)
- return true;
- if (o == null || getClass() != o.getClass())
- return false;
-
- Node node = (Node) o;
-
- if (code != node.code)
- return false;
- return s == node.s;
- }
-
- @Override
- public int hashCode() {
- int result = code;
- result = 31 * result + s;
- return result;
- }
- }
-
- public void build(List<String> list) {
-
- // 给所有字符定编码
- this.keys = list.stream().map(word -> word.split("")).flatMap(Arrays::stream).distinct().sorted()
- .collect(Collectors.toList()).toArray(new String[0]);
-
- base = new int[3 * keys.length];
- check = new int[3 * keys.length];
-
- String[] dir = list.toArray(new String[0]);
-
- // 设置root
- base[0] = 1;
- for (int i = 0; i < check.length ; i++) {
- check[i] = -1;
- }
-
- // 词的深度
- int depth = 1;
-
- while (!list.isEmpty()) {
-
- // 根据相同前缀分组
- Map<Integer, List<Node>> map = new HashMap<>();
- for (int i = 0; i < list.size();) {
- String word = list.get(i);
-
- String pre = word.substring(0, depth - 1);
- String k = word.substring(depth - 1, depth);
-
- Node n = new Node();
- n.code = findIndex(k);
- n.s = depth == 1 ? 0 : indexOf(pre);
- if (depth == word.length()) {
- list.remove(i);
- } else {
- i++;
- }
-
- List<Node> siblings = map.getOrDefault(n.s, new ArrayList<>());
-
- if(siblings.contains(n)){
- continue;
- }
- siblings.add(n);
- map.put(n.s, siblings);
- }
-
- map.forEach((s, siblings) -> {
- int offset = 0;
-
- for (int i = 0; i < siblings.size(); i++) {
- Node node = siblings.get(i);
- int c = node.code;
- int t = base[s] + offset + c;
-
- // 发现在节点已有值则偏移+1
- if (check[t] != -1) {
- offset++;
- i = -1;
- }
- }
-
- base[s] = base[s] + offset;
-
- for (Node node : siblings) {
- int c = node.code;
- int t = base[s] + c;
- // 给上父结点
- check[t] = s;
- // 给拿上一个节点偏移量
- base[t] = base[s];
- }
- });
- depth++;
- }
-
- // 发现字节点,置为负数
- for (String aDir : dir) {
- int s = indexOf(aDir);
- base[s] = -1 * base[s];
- }
- }
-
- // 找询字符编码
- private int findIndex(String key) {
- for (int i = 0; i < keys.length; i++) {
- if (keys[i].equals(key))
- return i + 1;
- }
- throw new RuntimeException("找不到[" + key + "]");
- }
-
- // 定位前缀结点position
- private int indexOf(String pre) {
- int s = 0;
- String[] ss = pre.split("");
- for (int i = 0; i < ss.length; i++) {
- String word = ss[i];
- int c = findIndex(word);
- int t = (base[s] < 0 ? -1 * base[s] : base[s]) + c;
- s = t;
- }
- return s;
- }
-
- public boolean get(String key) {
-
- int s = 0;
-
- String[] ss = key.split("");
- for (int i = 0; i < ss.length; i++) {
- String word = ss[i];
- int c = findIndex(word);
-
- int t = (base[s] < 0 ? -1 * base[s] : base[s]) + c;
-
- if (t >= base.length)
- return false;
-
- if (i == ss.length - 1 && check[t] == s) {
- return true;
- }
-
- s = t;
- }
-
- return false;
- }
-
- public static void main(String[] args) {
- DoubleArrayTrie adt = new DoubleArrayTrie();
- List<String> list = Stream.of(new String[]{"hers", "his", "she", "he"}).collect(Collectors.toList());
- // 构建DoubleArrayTrie
- adt.build(list);
- System.out.println(adt.get("hers"));
- System.out.println(adt.get("hr"));
- }
- }

双数组Tire树相对Tire树。减少了查询过程的中比较。相当于对每单词进行hashcode标记

