
- 1VSCode 中使用 AI智能编程工具的几个小妙招_vscode ai编程
- 2AI工程师Devin:软件开发领域的革命先锋
- 3Github Copilot 程序员效率提升工具_github pilot
- 4Android Studio报错:无法访问Android SDK附加组件列表解决方案_无法访问android sdk加载项列表
- 5Git客户端Sourcetree工具安装使用详解&命令_sourcetree配置git
- 6Mycat高级进阶---Mycat注解_mycat 使用 insert 的表作为注解 sql
- 7ChatGLM-6B部署和微调实例_chatglm-6b微调环境搭建
- 82分钟教你配置好LoRA模型训练器—Kohya_kohya 安装教程
- 9CentOS7 --- 安装MySQL_centos7安装mysql
- 10自动驾驶笔记-轨迹跟踪-综述_如何对汽车车轮转向控制实现轨迹跟踪
MySQL-成本与统计数据学习_mysql执行一个查询可以有不同的执行方案,它会选择其中成本最低,或者说代价最低的
赞
踩
MySQL执行一个查询可以有不同的执行方案,它会选择其中成本最低,或者说代价最低的那种方案去真正的执行查询
基于成本的优化步骤
- 根据搜索条件,找出所有可能使用的索引
- 计算全表扫描的代价
- 计算使用不同索引执行查询的代价
- 对比各种执行方案的代价,找出成本最低的那一个
CREATE TABLE single_table ( id INT NOT NULL AUTO_INCREMENT, key1 VARCHAR(100), key2 INT, key3 VARCHAR(100), key_part1 VARCHAR(100), key_part2 VARCHAR(100), key_part3 VARCHAR(100), common_field VARCHAR(100), PRIMARY KEY (id), KEY idx_key1 (key1), UNIQUE KEY idx_key2 (key2), KEY idx_key3 (key3), KEY idx_key_part(key_part1, key_part2, key_part3) ) Engine=InnoDB CHARSET=utf8; ## 执行sql语句 SELECT * FROM single_table WHERE key1 IN ('a', 'b', 'c') AND key2 > 10 AND key2 < 1000 AND key3 > key2 AND key_part1 LIKE '%hello%' AND common_field = '123'; ## possible keys只有idx_key1和idx_key2。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
计算成本
SHOW TABLE STATUS LIKE 'single_table' ## 查看表的统计信息
Rows: 记录条数 #估算值
Data_length:Data_length = 聚簇索引的页面数量 x 16k(页面大小) #聚簇索引空间大小
- 1
- 2
- 3
-
I/O成本
聚簇索引的页面数量 = 1589248 ÷ 16 ÷ 1024 = 97
97 x 1.0 + 1.1 = 98.1
97指的是聚簇索引占用的页面数,1.0指的是加载一个页面的成本常数,后边的1.1是一个微调值 -
CPU成本:
9693 x 0.2 + 1.0 = 1939.6
9693指的是统计数据中表的记录数,对于InnoDB存储引擎来说是一个估计值,0.2指的是访问一条记录所需的成本常数,后边的1.0是一个微调值。
I/O +CPU=总成本
计算索引执行的成本
MySQL查询优化器先分析使用唯一二级索引的成本,再分析使用普通索引的成本,所以我们也先分析idx_key2的成本,然后再看使用idx_key1的成本。
idx_key2
idx_key2对应的搜索条件是:key2 > 10 AND key2 < 1000,也就是说对应的范围区间就是:(10, 1000),使用idx_key2搜索的示意图就是这样子
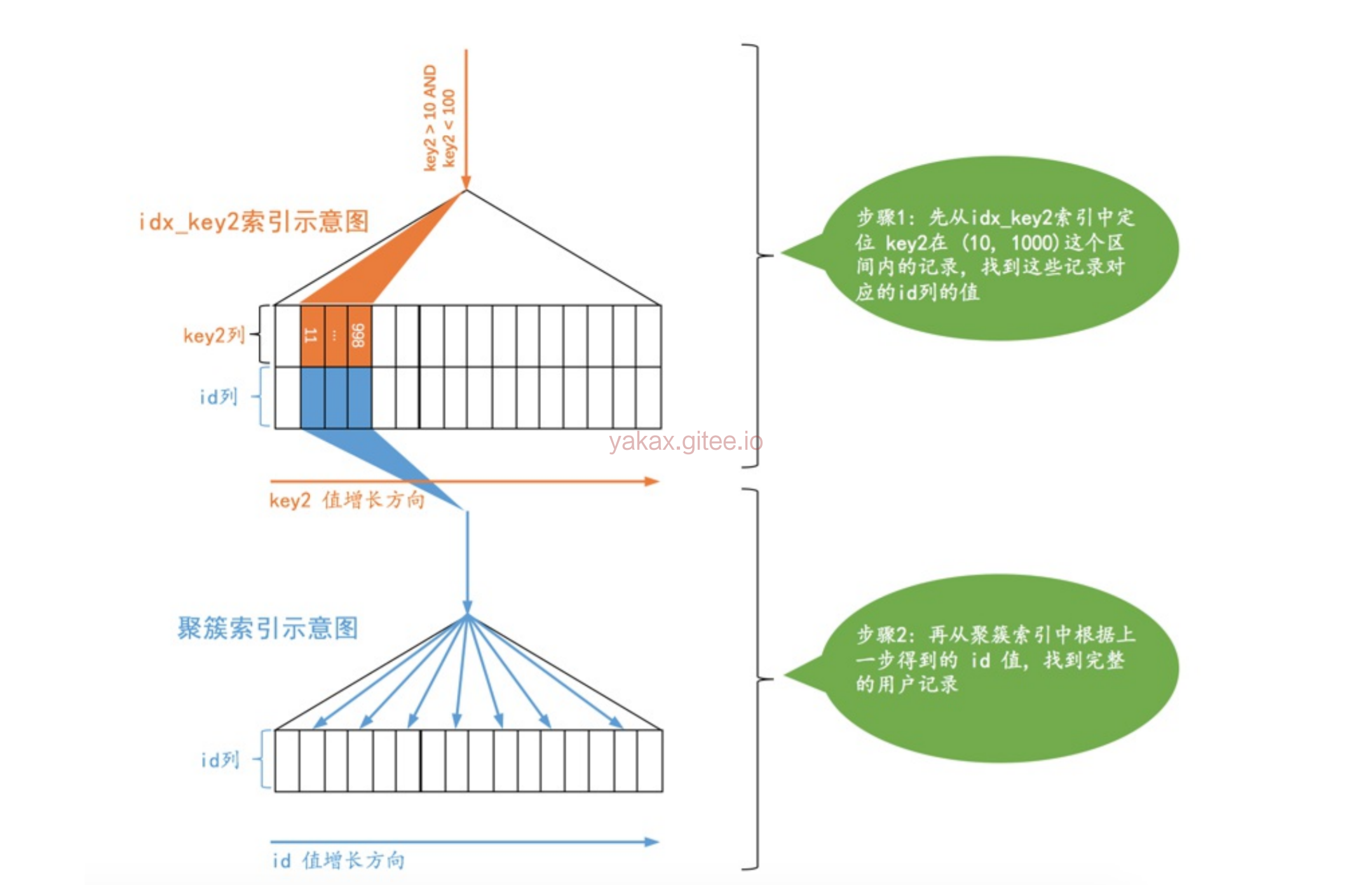
-
范围区间数量
不论某个范围区间的二级索引到底占用了多少页面,查询优化器粗暴的认为读取索引的一个范围区间的I/O成本和读取一个页面是相同的。所以这个二级索引付出的I/O成本就是:1 x 1.0 = 1.0 -
需要回表的记录数
- 先根据key2 > 10这个条件访问一下idx_key2对应的B+树索引,找到满足key2 > 10这个条件的第一条记录,我们把这条记录称之为区间最左记录。我们前头说过在B+数树中定位一条记录的过程是贼快的。
- 然后再根据key2 < 1000这个条件继续从idx_key2对应的B+树索引中找出第一条满足这个条件的记录,我们把这条记录称之为区间最右记录。
- 步骤3:如果区间最左记录和区间最右记录相隔不太远(在MySQL 5.7.21这个版本里,只要相隔不大于10个页面即可),那就可以精确统计出满足key2 > 10 AND key2 < 1000条件的二级索引记录条数。否则只沿着区间最左记录向右读10个页面,计算平均每个页面中包含多少记录,然后用这个平均值乘以区间最左记录和区间最右记录之间的页面数量就可以了
b+tree 每一个目录项都对应一个数据页,定位到目录项时就知道两个页中相差多少数据页了。相当于计算它们父节点的目录项记录之间隔着几条记录
I/O成本:
1.0 + 95 x 1.0 = 96.0 (范围区间的数量 + 预估的二级索引记录条数)
CPU成本:
95 x 0.2 + 0.01 + 95 x 0.2 = 38.01 (读取二级索引记录的成本 + 读取并检测回表后聚簇索引记录的成本)
idx_key1
idx_key1对应的搜索条件是:key1 IN (‘a’, ‘b’, ‘c’),也就是说相当于3个单点区间。
这三个单点区间总共需要回表的记录数就是:35 + 44 + 39 = 118
I/O成本:
3.0 + 118 x 1.0 = 121.0 (范围区间的数量 + 预估的二级索引记录条数)
CPU成本:
118 x 0.2 + 0.01 + 118 x 0.2 = 47.21 (读取二级索引记录的成本 + 读取并检测回表后聚簇索引记录的成本)
是否会使用索引合并
本例中有关key1和key2的搜索条件是使用AND连接起来的,而对于idx_key1和idx_key2都是范围查询,也就是说查找到的二级索引记录并不是按照主键值进行排序的,并不满足使用Intersection索引合并的条件,所以并不会使用索引合并
- 全表扫描的成本:2037.7
- 使用idx_key2的成本:134.01 选择
- 使用idx_key1的成本:168.21
基于索引统计数据的成本计算
查看索引统计数据SHOW INDEX FROM single_table
Table 索引所属表的名称。
Non_unique 索引列的值是否是唯一的,聚簇索引和唯一二级索引的该列值为0,普通二级索引该列值为1。
Key_name 索引的名称。
Seq_in_index 索引列在索引中的位置,从1开始计数,联合索引顺序
Column_name 索引列的名称。
Collation 索引列中的值是按照何种排序方式存放的,值为A时代表升序存放,为NULL时代表降序存放。
Cardinality 索引列中不重复值的数量。后边我们会重点看这个属性的。
Sub_part 对于存储字符串或者字节串的列来说,有时候我们只想对这些串的前n个字符或字节建立索引,这个属性表示的就是那个n值。如果对完整的列建立索引的话,该属性的值就是NULL。
Packed 索引列如何被压缩,NULL值表示未被压缩。这个属性我们暂时不了解,可以先忽略掉。
Null 该索引列是否允许存储NULL值。
Index_type 使用索引的类型,我们最常见的就是BTREE,其实也就是B+树索引。
Comment 索引列注释信息。
Index_comment 索引注释信息。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
有时候使用索引执行查询时会有许多单点区间
SELECT * FROM single_table WHERE key1 IN ('aa1', 'aa2', 'aa3', ... , 'zzz')
- 1
很显然,这个查询可能使用到的索引就是idx_key1,由于这个索引并不是唯一二级索引,所以并不能确定一个单点区间对应的二级索引记录的条数有多少,需要我们去计算。计算方式跟上边一样,就是先获取索引对应的B+树的区间最左记录和区间最右记录,然后再计算这两条记录之间有多少记录(记录条数少的时候可以做到精确计算,多的时候只能估算)
参数SHOW VARIABLES LIKE '%dive%'; eq_range_index_dive_limit 代表in最大的参数,如果大于200就会根据索引的估值进行估算进行成本分析了。
两表连接查询成本分析
连接查询总成本 = 单次访问驱动表的成本 + 驱动表扇出数 x 单次访问被驱动表的成本
外连接
- 分别为驱动表和被驱动表选择成本最低的访问方法。
内连接
- 不同的表作为驱动表最终的查询成本可能是不同的,也就是需要考虑最优的表连接顺序。
- 然后分别为驱动表和被驱动表选择成本最低的访问方法。
执行计划查看成本
EXPLAIN FORMAT=JSON SELECT * FROM s1 INNER JOIN s2 ON s1.key1 = s2.key2 WHERE s1.common_field = 'a' EXPLAIN: { "query_block": { "select_id": 1, # 整个查询语句只有1个SELECT关键字,该关键字对应的id号为1 "cost_info": { "query_cost": "3197.16" # 整个查询的执行成本预计为3197.16 }, "nested_loop": [ # 几个表之间采用嵌套循环连接算法执行 # 以下是参与嵌套循环连接算法的各个表的信息 { "table": { "table_name": "s1", # s1表是驱动表 "access_type": "ALL", # 访问方法为ALL,意味着使用全表扫描访问 "possible_keys": [ # 可能使用的索引 "idx_key1" ], "rows_examined_per_scan": 9688, # 查询一次s1表大致需要扫描9688条记录 "rows_produced_per_join": 968, # 驱动表s1的扇出是968 "filtered": "10.00", # condition filtering代表的百分比 "cost_info": { "read_cost": "1840.84", # 稍后解释 "eval_cost": "193.76", # 稍后解释 "prefix_cost": "2034.60", # 单次查询s1表总共的成本 "data_read_per_join": "1M" # 读取的数据量 }, "used_columns": [ # 执行查询中涉及到的列 "id", "key1", "key2", "key3", "key_part1", "key_part2", "key_part3", "common_field" ], # 对s1表访问时针对单表查询的条件 "attached_condition": "((`xiaohaizi`.`s1`.`common_field` = 'a') and (`xiaohaizi`.`s1`.`key1` is not null))" } }, { "table": { "table_name": "s2", # s2表是被驱动表 "access_type": "ref", # 访问方法为ref,意味着使用索引等值匹配的方式访问 "possible_keys": [ # 可能使用的索引 "idx_key2" ], "key": "idx_key2", # 实际使用的索引 "used_key_parts": [ # 使用到的索引列 "key2" ], "key_length": "5", # key_len "ref": [ # 与key2列进行等值匹配的对象 "xiaohaizi.s1.key1" ], "rows_examined_per_scan": 1, # 查询一次s2表大致需要扫描1条记录 "rows_produced_per_join": 968, # 被驱动表s2的扇出是968(由于后边没有多余的表进行连接,所以这个值也没啥用) "filtered": "100.00", # condition filtering代表的百分比 # s2表使用索引进行查询的搜索条件 "index_condition": "(`xiaohaizi`.`s1`.`key1` = `xiaohaizi`.`s2`.`key2`)", "cost_info": { "read_cost": "968.80", # 稍后解释 "eval_cost": "193.76", # 稍后解释 "prefix_cost": "3197.16", # 单次查询s1、多次查询s2表总共的成本 "data_read_per_join": "1M" # 读取的数据量 }, "used_columns": [ # 执行查询中涉及到的列 "id", "key1", "key2", "key3", "key_part1", "key_part2", "key_part3", "common_field" ] } } ] } } ## 两个表分别成本 "cost_info": { "read_cost": "1840.84", "eval_cost": "193.76", "prefix_cost": "2034.60", "data_read_per_join": "1M" } "cost_info": { "read_cost": "968.80", "eval_cost": "193.76", "prefix_cost": "3197.16", "data_read_per_join": "1M" } 由于s2表是被驱动表,所以可能被读取多次,这里的read_cost和eval_cost是访问多次s2表后累加起来的值 单次查询s1表和多次查询s2表后的成本的和968.80 + 193.76 + 2034.60 = 3197.16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
统计数据怎么收集的
innodb_stats_persistent参数是代表统计信息是否存储到磁盘。在MySQL 5.6.6之后默认打开的
或者我们直接在创建表或修改表时设置STATS_PERSISTENT属性的值为0,那么该表的统计数据就是非永久性的了
基于磁盘的永久性统计数据
SHOW TABLES FROM mysql LIKE 'innodb%';
SELECT * FROM mysql.innodb_table_stats; 查询
innodb_table_stats表存储了关于表的统计数据,每一条记录对应着一个表的统计数据
innodb_index_stats表存储了关于索引的统计数据,每一条记录对应着一个索引的一个统计项的统计数据
- 1
- 2
- 3
- 4
innodb_table_stats:
database_name 数据库名、table_name 表名、last_update 本条记录最后更新时间、n_rows 表中记录的条数
clustered_index_size 表的聚簇索引占用的页面数量、sum_of_other_index_sizes 表的其他索引占用的页面数量

n_rows估算值:可以理解为按照一定算法(并不是纯粹随机的)选取几个叶子节点页面,计算每个页面中主键值记录数量,然后计算平均一个页面中主键值的记录数量乘以全部叶子节点的数量就算是该表的n_rows值。
innodb_index_stats:
database_name 数据库名、table_name 表名、index_name 索引名、last_update 本条记录最后更新时间
stat_name 统计项的名称、stat_value 对应的统计项的值、sample_size 为生成统计数据而采样的页面数量、
stat_description 对应的统计项的描述
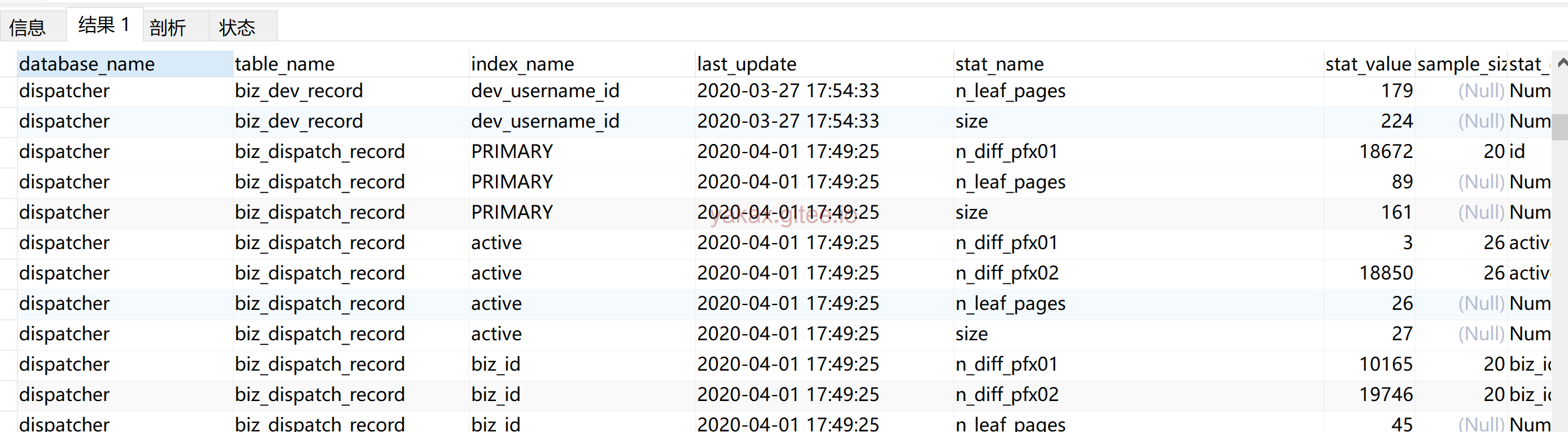
针对index_name列相同的记录,stat_name表示针对该索引的统计项名称,stat_value展示的是该索引在该统计项上的值,stat_description指的是来描述该统计项的含义的
- n_leaf_pages:表示该索引的叶子节点占用多少页面。
- size:表示该索引共占用多少页面。
- n_diff_pfxNN:表示对应的索引列不重复的值有多少。
- n_diff_pfx01表示的是统计key_part1这单单一个列不重复的值有多少。
- n_diff_pfx02表示的是统计key_part1、key_part2这两个列组合起来不重复的值有多少。以此类推
更新统计数据
参数innodb_stats_auto_recalc 默认是开启的。
如果发生变动的记录数量超过了表大小的10%,并且自动重新计算统计数据的功能是打开的,那么服务器会重新进行一次
统计数据的计算,并且更新innodb_table_stats和innodb_index_stats表。不过自动重新计算统计数据的过程是异步发生
基于内存
这个没啥说的。

