
- 1C语言哈希表_c 哈希表 标准库
- 2mac下appium1.11.0桌面版的安装以及安卓、iOS的自动化测试(python)一_mac 的appium桌面版本
- 3Bash写脚本,几个常用的语法总结_bash脚本语法
- 4编译原理学习指导_编译原理学习指南
- 5OpenHarmony开发-连接开发板调试应用_openharmony如何适配开发板
- 6论文阅读:(2020版)A Survey on Deep Learning for Named Entity Recognition 命名实体识别中的深度学习方法_使用brill规则推理方法来处理语音输入
- 7LLM之RAG实战(十九)| 利用LangChain、OpenAI、ChromaDB和Streamlit构建RAG
- 8算法学习——LeetCode力扣动态规划篇1(509. 斐波那契数、70. 爬楼梯、746. 使用最小花费爬楼梯、62. 不同路径、63. 不同路径 II)_leetcode 动态规划 爬楼梯 斐波那契数
- 9【数据结构与算法学习心得】_数据与算法的学习体会
- 10【python】flask结合SQLAlchemy,在视图函数中实现对数据库的增删改查
Java学习笔记(接口、数组、集合和泛型)_java为接口数组
赞
踩
接口
接口的概念
-
接口是功能的集合,是一个比抽象类更加抽象的类,接口也是一种数据类型。
-
接口里面只描述做什么事情,并没有具体的实现。
-
具体的实现由子类完成,将功能的定义与实现分离。
-
世间万物均有接口。
接口的定义
-
定义类用 class 而定义接口则用 interface。
-
接口里面只能有常量,必须初始化的时候赋值。
-
接口里面只能有抽象方法(1.8版本之前)。
public interface 接口名{
// 属性都是常量
public static final 数据类型 常量名=常量值;
// 抽象方法
public 数据类型 方法名(参数列表);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
类实现接口
-
类与接口的关系为实现关系,实现的动作类似继承,用的关键字不同,实现使用 implements。
-
一个类实现一个接口后拥有该接口的所有功能,需要重写该接口里面所有的抽象方法。
public class 类名 implements 接口名{
// 需要重写接口中的所有抽象方法
}
- 1
- 2
- 3
类同时继承与实现
- Java类只支持单继承
- Java类可以多实现接口,多个接口名之间使用逗号进行分隔
public class Student extends Person implements IProgram,ISing {
}
- 1
- 2

接口的多继承
类与类之间可以通过继承产生关系,接口和类之间可以通过实现产生关系,接口与接口之间通过extends关键字实现继承。
public interface 子接口名 extends 父接口名1,父接口名2{
}
- 1
- 2
接口的使用
-
接口实现了功能的扩展。
-
推荐:多组合实现接口,尽量不使用继承。
抽象类和接口的区别
- 都是不能实例化(不能通过new来创建对象)
- 抽象类只有普通方法和抽象方法,接口中只有抽象方法,没有普通方法
- 抽象类中的属性有常量和变量,接口中的属性只有常量
类的执行顺序
-
如果没有继承关系时
new Person()- 1
- 第1步:先初始静态的属性
- 第2步:执行静态的代码块
- 第3步:初始化成员属性
- 第4步:执行构造方法
-
如果有继承关系时:
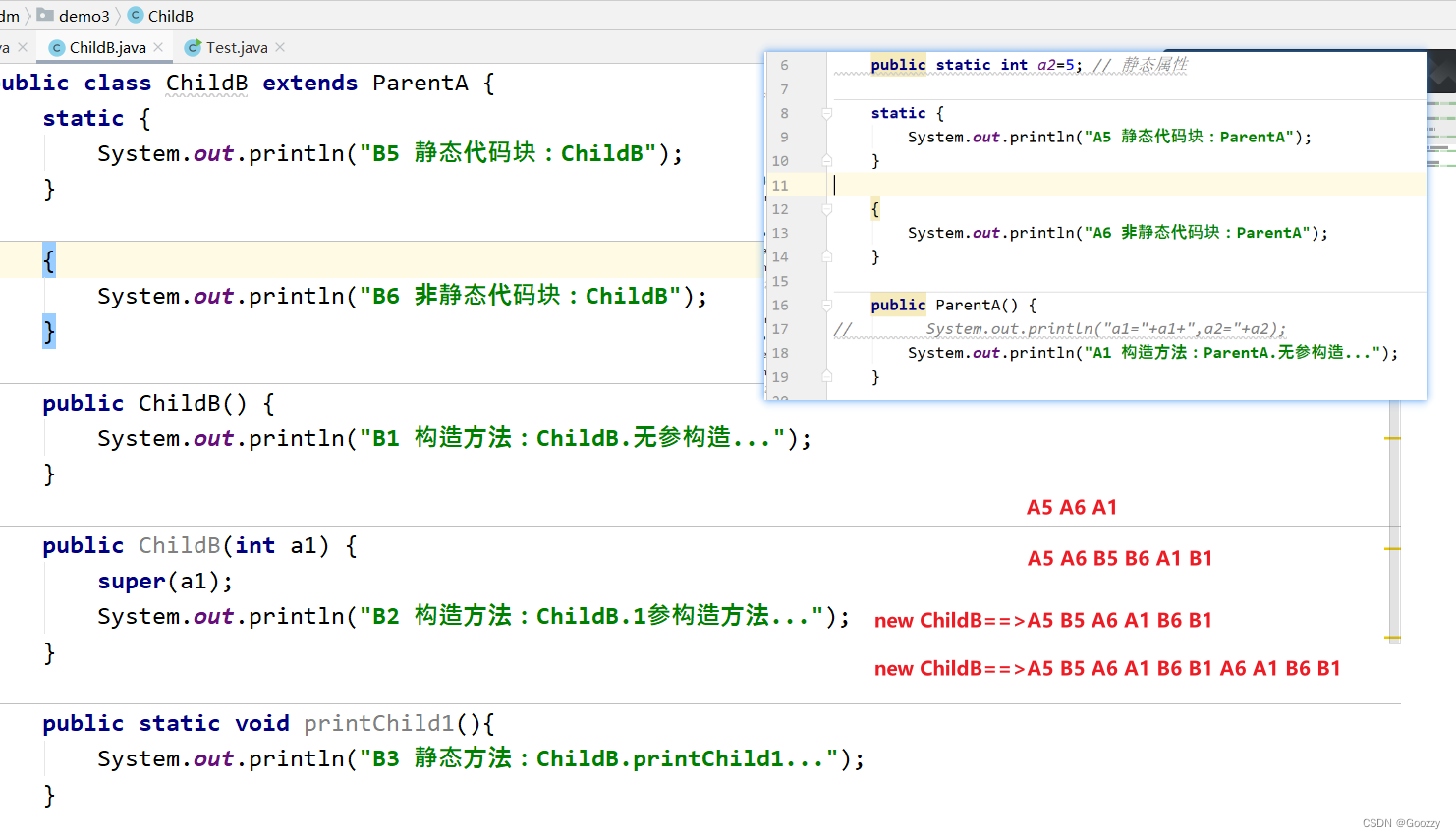
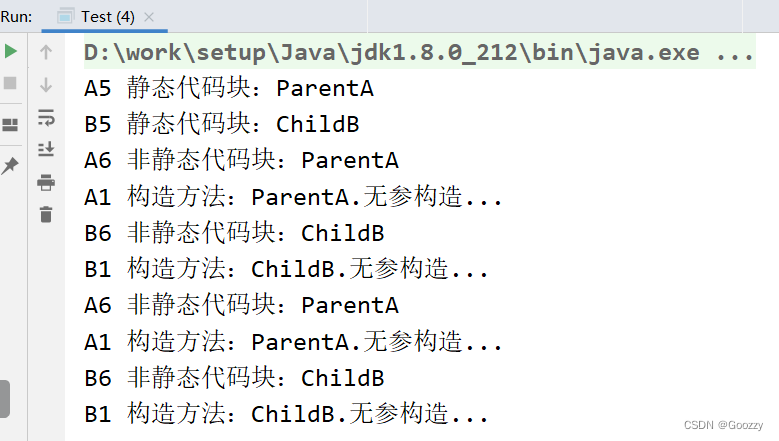
- 第1步:先初始父类的静态的属性和方法,包括静态代码块
- 第2步:再初始子类的静态的属性和方法,包括静态代码块
- 第3步:先要初始化父类的非静态代码块、属性和普通方法
- 第4步:再执行父类的构造方法
- 第5步:先要初始化子类的非静态代码块、属性和普通方法
- 第6步:再执行子类的构造方法
注意:静态的只会加载一次,后面无论你实例化多少次对象,都不会再执行了。
# static修饰的属性和方法需要通过类名.属性或类名.方法名()来使用- 1
-
静态方法为什么不能调用普通方法
请查看类的执行顺序
-
普通方法可以调用静态方法
请查看类的执行顺序
基本数据类型对应的包装类
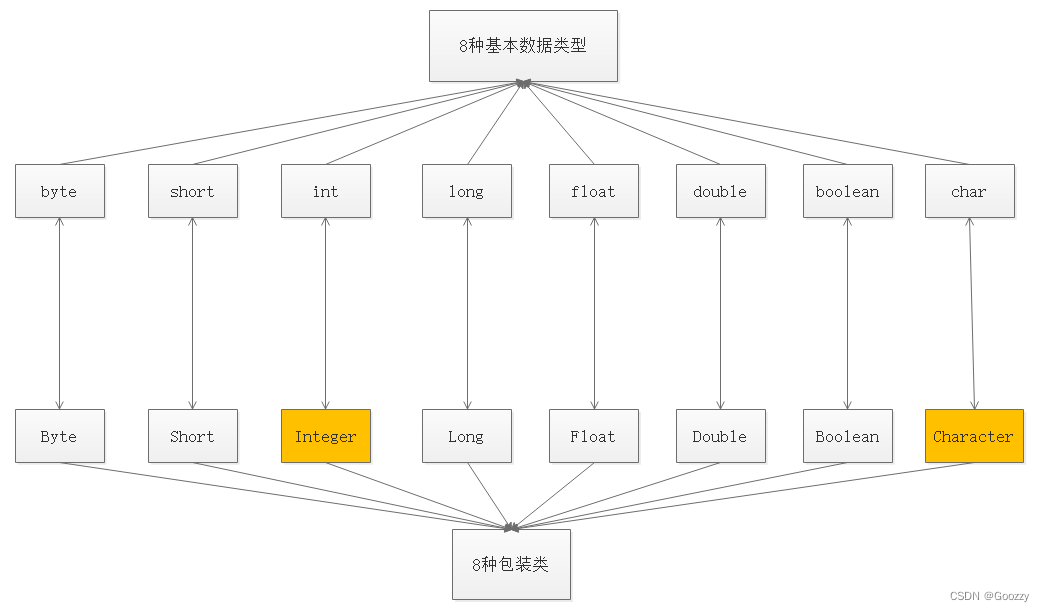
- 自动装箱和拆箱

为什么要使用包装类
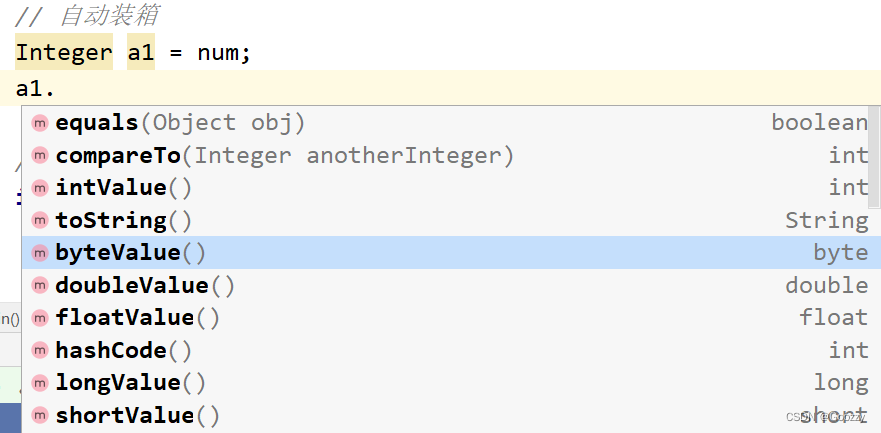
- 基本数据类型进行数据转换要通过第三方完成
- 包装类其实就是类,类可以定义属性和方法,那么可以通过类的方法实现一些业务功能。
数组和集合
数组
数组的概述
-
数组是一个容器,用来存储多个数据(数据类型相同)。
-
声明一个变量就是在内存空间画出一块合适的空间。
-
声明一个数组就是在内存中间划出一串连续的空间。
注意:创建数组长度时按需创建,不要太大浪费内存空间。
普通数组
数组的初始化
-
静态初始化
数组初始化时就能确认数组中的元素的值时使用静态初始化
// 1.1 静态初始化 // 1.1.1 语法1:数据类型[] 变量名={值1,值2,值3,...}; // 值的类型要与前面定义的数组的元素类型保持一致 // 数组中的每一个值我们称为数组中的元素 int[] nums1 = {1,2,3,4,5,7};//这里的数组的长度6 // 1.1.2 语法2:数据类型[] 变量名= new 数据类型[]{值1,值2,值3,...}; int[] nums2 = new int[]{1,2,3,4,5};// 这里的数组的长度是5- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
动态初始化
数组初始化时不能确认数组中的元素的值时使用动态初始化
// 1.2 动态初始化 // 语法:数据类型[] 变量名 = new 数据类型[数组的长度]; // 创建int类型的数组,用于保存5个数据,里面的值是该数据类型的默认值 int[] nums3 = new int[5]; // 数组通过下标进行元素的设置或获取,下标是从0开始,0代表第1个元素,依此类推 // 设置nums3的元素的值,num3的下标范围为0-4,那么超出下标范围会抛出异常ArrayIndexOutOfBoundsException nums3[0]=3;// 设置第1个元素的值 nums3[1]=5;// 设置第2个元素的值 nums3[2]=7; nums3[3]=9; nums3[4]=1; //nums3[5]=5;// 这里的下标5超出了下标范围,所以会抛出异常ArrayIndexOutOfBoundsException- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
数组中元素的访问和遍历
-
单个元素的访问
// 2、获取数据中的元素,通过下标进行获取 // 2.1 单个元素的获取 System.out.println("nums3的第1个元素:"+nums3[0]); System.out.println("nums3的第3个元素:"+nums3[2]); System.out.println("nums3的数组长度:"+nums3.length);- 1
- 2
- 3
- 4
- 5
-
数组中元素的遍历
-
普通for循环遍历:如果要使用数组下标就用这种
// 2.2.1普通的for循环:可以获取到数组的下标 /* 语法: for(表达式1;表达式2;表达式3){ // 循环体 } */ for (int i=0;i<nums3.length;i++){ System.out.println("第"+(i+1)+"个元素为:"+nums3[i]); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
增强型for循环遍历:如果不需要使用到数组下标就用这种。
// 2.2.2 增强型for:如果不需要数组或集合的下标时使用 /* 语法: for(数组类型 变量名: 数组或集合的变量名){ // 循环体 } */ for(int num:nums3){ System.out.println(num); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
数组操作中可能出现的异常
-
ArrayIndexOutOfBoundsException:下标越界异常指的是如果下标超出范围会抛出该异常
int[] nums = {1,2,3}; // 该数组的下标范围是:0,1,2 System.out.println(nums[2]);//合法的下标:2 System.out.println(nums[3]);//非法的下标:3,会抛出ArrayIndexOutOfBoundsException异常- 1
- 2
- 3
- 4
- 5
-
NullPointException:空指针异常
public static void print(int[] nums){ for(int n:nums){ // 这1行的nums对象会报:NullPointException:空指针异常 System.out.println(n); } } public static void main(String[] args){ print(null); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
对象数组
-
使用对象类型作为数组的数据类型
-
初始化语法:
基本数据类型[] 变量名 = new 基本数据类型[长度] 引用类型[] 变量名 = new 引用类型[数组长度];- 1
- 2
- 3
-
初始化示例
// 创建长度为5的学生数组 Student[] stus = new Student[5];- 1
- 2
注意:刚创建出来的对象数组中的元素值为null
-
示例
public static void main(String[] args) { // 普通数组: // 基本数据类型在初始化时数组中的元素有默认值,int的默认值是0 int[] nums = new int[5]; // 对象数组 // 对象数组中的元素的默认值为null // 1、初始化对象数组 Student[] students = new Student[5]; // 2、为每个元素赋值 students[0] = new Student("张三",18); students[1] = new Student("李四",28); students[2] = new Student("王五",38); students[3] = new Student("赵六",48); students[4] = new Student("孙七",58); // 3、获取数组中的元素 // 3.1 访问数组中的单个元素 Student stu1 = students[1]; System.out.println("第2个元素的学生姓名:"+stu1.getName()); System.out.println("第2个元素的学生姓名:"+students[1].getName()); // 3.2 循环遍历 for(int i=0;i<students.length;i++){ Student stu = students[i]; System.out.println(stu); } System.out.println("----------------"); for (Student stu:students){ System.out.println(stu); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
集合

ArrayList类和LinkedList类
ArrayList类
ArrayList实现了List接口,是顺序容器,允许放入null元素,底层通过数组实现,每个ArrayList都有一个容量,容器内存储的元素个数不能超过这个容量,当超过时容器会自动扩容。
// 数组中保存6个int类型的元素,将偶数在控制台打印出来 List<Integer> list = new ArrayList<>(); // 2、添加元素 list.add(1); list.add(2); list.add(3); list.add(4); list.add(5); // 3、循环遍历 for(int i=0;i<list.size();i++){ if(list.get(i)%2==0){ System.out.println(list.get(i)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
LinkedList类
LinkedList实现了List接口和Deque接口, 也就说可以看作顺序容器,也可以看作一个队列, 又可以看作是栈, 这样看来LinkedList很全能, 当需要使用栈或者队列的时候, 可以考虑使用LinkedList.
LinkedList底层是基于链表的数据结构:

package com.tipdm.demo1; import java.util.LinkedList; import java.util.List; public class TestLinkedList { public static void main(String[] args) { // 1、创建集合对象 List<Integer> list = new LinkedList<>(); // 2、添加 list.add(2); list.add(3); list.add(1); list.add(5); list.add(9); // 3、获取元素 System.out.println("第2个元素:"+list.get(1)); System.out.println("集合中元素的个数:"+list.size()); // 4、调用LinkedList特有的方法 // 语法: 变量名 instanceof 数据类型 // 用于判断当前的变量是否为指定的数据类型 if(list instanceof LinkedList){ LinkedList<Integer> linkedList = (LinkedList) list; // 获取集合中的第1个元素 Integer first = linkedList.getFirst(); Integer last = linkedList.getLast(); System.out.println("第1个元素:"+first); System.out.println("最后1个元素:"+last); // 删除第1个元素 linkedList.removeFirst(); // 删除最后1个元素 linkedList.removeLast(); } System.out.println("-------------------"); // 3、遍历 for(int i=0;i<list.size();i++){ System.out.println(list.get(i)); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
ArrayList和LinkedList的区别
-
ArrayList是实现了基于动态数组的数据结构,因地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的),ArrayList要移动数据,所以插入和删除操作效率比较低。 -
LinkedList基于链表的数据结构,地址是任意的,对于新增和删除数据有较好的性能,查询较慢,因为LinkedList查询需要移动指针遍历。 -
LinkedList插入、删除指定位置的性能是优于ArrayList的,因为ArrayList需要额外的移动损耗,以及拷贝元素。 -
ArrayList在查找和尾部插入删除的性能时优于LinkedList的。
泛形
在类或接口定义时设置泛形占位符:<E>,然后在实际使用时再指定具体的数据类型作为泛形的类型。


注意:这个字母E不是必须这个值,可以是其它的字母A、B等等,这个字母仅仅只是一个占位符,没有具体的含义。
// 泛形的具体类型是在使用时设置
List<Student> list = new ArrayList();
- 1
- 2
-
约束集合中的数据类型,添加时不能添加约束之外的其它类型
list.add(new Student("张三",18)); //list.add(1);// 报错,因为泛形约束了集合中的数据类型只能是Student- 1
- 2
-
在获取集合中的某个下标元素时不需要进行强制类型转换就可以直接使用
for(int i=0;i<list.size();i++){ // Object obj = list.get(i); // 不加泛形时需要将父类强制转换为子类对象 // Student stu = (Student) obj; // 不需要强制类型转换就可以直接使用 Student student = list.get(i); System.out.println("姓名:"+student.getName()); // ok //System.out.println("姓名:"+list.get(i).getName());//ok }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
集合工具类
Collections是集合的工具类。
排序
注意:只能对List接口的排序。
1.自然排序
public static void main(String[] args) { // 对集合中的元素进行排序后输出 List<Integer> list = new ArrayList<>(); list.add(3); list.add(2); list.add(5); list.add(1); list.add(9); System.out.println("排序前------"); for(int i=0;i<list.size();i++){ System.out.println(list.get(i)); } // 排序:只能升序 Collections.sort(list); System.out.println("排序后-------"); //list.forEach(System.out::println);// 升序 // 降序 for(int i=list.size()-1;i>=0;i--){ System.out.println(list.get(i)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
2.自定义排序
public static void main(String[] args) { // 需求:对集合中的学生对象进行排序 // 1、创建集合对象 List<Student> list = new ArrayList<>(); // 2、添加元素 list.add(new Student("张三",28,"bbb")); list.add(new Student("李四",18,"ddd")); list.add(new Student("王五",20,"aaa")); list.add(new Student("赵六",38,"ccc")); list.add(new Student("孙七",15,"fff")); // 3、循环遍历集合 System.out.println("排序前-------"); for(int i=0;i<list.size();i++){ System.out.println(list.get(i)); } // 4、对集合中元素排序 // 通过对匿名内部类来实现接口 /* Collections.sort(list, new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { // 按年龄升序 // return Integer.compare(o1.getAge(),o2.getAge()); // 按年龄降序 // return -Integer.compare(o1.getAge(),o2.getAge()); return Integer.compare(o2.getAge(),o1.getAge()); } }); */ Collections.sort(list, new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { // 按姓名升序 // return o1.getClassName().compareTo(o2.getClassName()); // 按姓名降序 // return -o1.getClassName().compareTo(o2.getClassName()); return o2.getClassName().compareTo(o1.getClassName()); } }); // 5、循环遍历集合 System.out.println("排序后-------"); for(int i=0;i<list.size();i++){ System.out.println(list.get(i)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
HashSet类和TreeSet类
HashSet类
HashSet概述
-
HashSet是 Set 接口的典型实现,大多数时候使用 Set 集合时就是使用这个实现类。HashSet是按照 Hash 算法来存储集合中的元素。因此具有很好的存取和查找性能。 -
HashSet具有以下特点:- 不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化。
HashSet不是同步的,如果多个线程同时访问或修改一个 HashSet,则必须通过代码来保证其同步。- 集合元素值可以是 null。
-
当向
HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置。如果有两个元素通过 equals() 方法比较返回的结果为 true,但它们的hashCode不相等,HashSet将会把它们存储在不同的位置,依然可以添加成功。 -
Object类中的
HashCode()是根据内存地址来计算的Hash值,但是不能等价于内存地址就是Hash值。Object类中的toString()方法会默认返回全类名**(包名+类名)+@+hash** 值的16进制。
示例1:添加String类型的数据
package com.tipdm.demo1; import java.util.HashSet; import java.util.Iterator; import java.util.Set; public class TestHashSet1 { public static void main(String[] args) { // 1、创建集合对象 Set<String> sets= new HashSet<>(); // 2、添加元素 sets.add("aaa"); sets.add("ccc"); sets.add("ddd"); sets.add("aaa"); //重复数据不能添加到Set集中 sets.add("ccc"); //重复数据不能添加到Set集中 // 3、获取元素 // Set不是通过下标获取数据 // 3.1) 通过迭代器进行数据的遍历 Iterator<String> it = sets.iterator(); // it.hasNext():判断是否有下一个元素,返回值为boolean, while (it.hasNext()){ // 用于获取下一个元素 String next = it.next(); System.out.println(next); } System.out.println("----------------"); // 3.2) 通过增强for遍历 for(String str:sets){ System.out.println(str); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
示例2:自定义对象重复规则
Object类中的HashCode()是根据内存地址来计算的Hash值,但是不能等价于内存地址就是Hash值。Object类中的toString()方法会默认返回全类名**(包名+类名)+@+hash** 值的16进制。
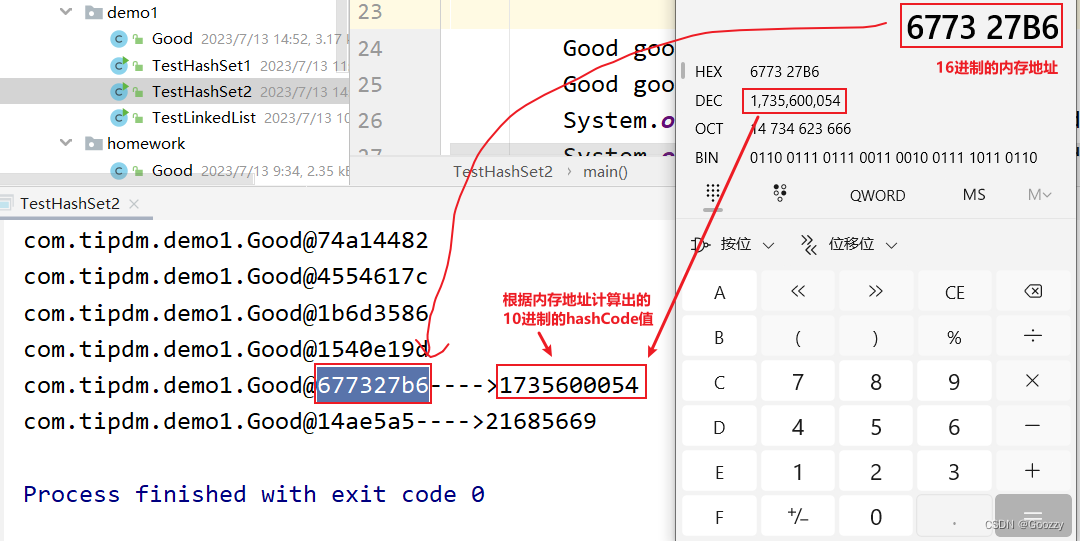
- 1)先通过hashCode()获得数据保存的位置,如果新添加的元素的hashCode的值没有找到相同的值,则该元素添加成功。
- 2)如果新添加的元素的hashCode值找到相同的,那么调用equals()方法,将其与该位置的所有元素进行比较,如果不同,则添加成功,否则添加失败。
- 通过计算HashCode的值来减少调用equals()方法进行比较的次数,从而提高存取和查找的性能。
- 1
- 2
- 3
- 4

# 1.Good实体类
- 1
package com.tipdm.demo1; public class Good { // 商品编号、商品名称、商品类型、单价、库存、计量单位、产地、品牌 private String gno; private String name; private String type; private Double price; private Integer stock; private String unit; private String address; private String brand; public Good() { } public Good(String gno, String name, String type, Double price, Integer stock, String unit, String address, String brand) { this.gno = gno; this.name = name; this.type = type; this.price = price; this.stock = stock; this.unit = unit; this.address = address; this.brand = brand; } // 省略getter/setter方法 // 用于计算数据保存的位置 @Override public int hashCode() { System.out.println("hashCode="+this.stock%6); return this.stock%6; } // 如果hashCode值相同时则调用equals()方法比较值 @Override public boolean equals(Object obj) { System.out.println("equals..."); // 初步步骤 // 1、传入的obj是不是当前对象 if(this==obj){ return true; } // 2、判断传入obj的类型是否为Good类 if(obj instanceof Good){ Good good = (Good) obj; // 2.2 如果是Good类型再比较name的值 return this.getName().equals(good.getName()); }else { // 2.1 如果不是该类型直接返回false return false; } } @Override public String toString() { return "Good{" + "gno='" + gno + '\'' + ", name='" + name + '\'' + ", type='" + type + '\'' + ", price=" + price + ", stock=" + stock + ", unit='" + unit + '\'' + ", address='" + address + '\'' + ", brand='" + brand + '\'' + '}'; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
# 2.测试类
- 1
package com.tipdm.demo1; import java.util.HashSet; import java.util.Set; public class TestHashSet2 { public static void main(String[] args) { // 1、创建集合对象 Set<Good> goodSets = new HashSet<>(); // 2、添加元素 goodSets.add(new Good("g0001","礼京果觅阳光玫瑰晴王葡萄","葡萄",38.9,15,"斤","云南","礼京果觅")); goodSets.add(new Good("g0002","黄桃水果礼盒","黄桃",36.5,18,"斤","山东","桃小安")); goodSets.add(new Good("g0003","黄桃水果礼盒","黄桃",46.5,12,"斤","山东","桃小安")); goodSets.add(new Good("g0003","abc","黄桃",46.5,21,"斤","山东","桃小安")); System.out.println("---------------"); // 3、输出 for(Good good:goodSets){ System.out.println(good); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

TreeSet类
TreeSet概述
-
TreeSet类同时实现了 Set 接口和SortedSet接口。SortedSet接口是 Set 接口的子接口,可以实现对集合进行自然排序,因此使用TreeSet类实现的 Set 接口默认情况下是自然排序的,这里的自然排序指的是升序排序。 -
TreeSet只能对实现了 Comparable 接口的类对象进行排序,因为 Comparable 接口中有一个compareTo(Object o)方法用于比较两个对象的大小。例如a.compareTo(b),如果 a 和 b 相等,则该方法返回 0;如果 a 大于 b,则该方法返回大于 0 的值;如果 a 小于 b,则该方法返回小于 0 的值。
示例:自然排序
package com.tipdm.demo1; import java.util.TreeSet; public class TestTreeSet1 { public static void main(String[] args) { // 1、创建TreeSet集合对象 TreeSet<String> sets = new TreeSet<>(); // 2、添加元素 // 默认是自然排序 sets.add("bbb"); sets.add("aaa"); sets.add("ddd"); sets.add("ccc"); sets.add("fff"); // TreeSet实现的是Set接口,没有办法通过下标获取元素 for (String str:sets){ System.out.println(str); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
示例2:自定义排序规则
package com.tipdm.demo1; import java.util.*; public class TestTreeSet2 { public static void main(String[] args) { Set<Good> goodSets = new TreeSet<>(new Comparator<Good>() { @Override public int compare(Good o1, Good o2) { // 按单价升序 // return Double.compare(o1.getPrice(),o2.getPrice()); // 按单价降序 return -Double.compare(o1.getPrice(),o2.getPrice()); } }); // 2、添加元素 goodSets.add(new Good("g0001","礼京果觅阳光玫瑰晴王葡萄","葡萄",38.9,15,"斤","云南","礼京果觅")); goodSets.add(new Good("g0002","黄桃水果礼盒","黄桃",36.5,18,"斤","山东","桃小安")); goodSets.add(new Good("g0003","黄桃水果礼盒","黄桃",46.5,12,"斤","山东","桃小安")); goodSets.add(new Good("g0003","abc","黄桃",46.5,21,"斤","山东","桃小安")); System.out.println("---------------"); // 3、输出 for(Good good:goodSets){ System.out.println(good); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
HashSet和TreeSet的区别
-
HashSet类-
底层数据结构是哈希表(是一个元素为链表的数组)。
-
添加元素在底层的实现依赖两个方法:
hashCode()和equals() -
执行顺序:
先判断哈希值是否相同,
如果不同,直接添加,
如果相同,则再判断
equals()是否相等,返回true则表示元素重复了,返回false直接添加元素。 -
在多线程中不安全
-
-
TreeSet类-
底层数据结构是红黑树(是一个自平衡的二叉树)。
-
保证元素的排序方式
-
a:自然排序(这种排序方式可以理解成元素本身具备比较性)【不推荐】
让元素所属的类实现
java.lang.Comparable接口 -
b:比较器排序(这种排序可以理解成集合类具备比较性)【推荐】
让集合构造方法接收
java.util.Comparator的实现类对象,实现方式可以用匿名类来实现。
-
-
在多线程中也是不安全的
-
对元素默认进行自然排序
-
HashMap
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YrIk7dvc-1690006498746)(笔记.assets/image-20230714095722576.png)]
-
Map是一个接口,我们不能直接创建对象,可以通过多态的形式创建对象,Map中有两个参数,一个是K表示键,一个是V表示值,且一个键有且对应一个值,Map中不能包含重复的键,若是有重复的键添加,则会以最后一次的键为准,而其他的键会被覆盖。集合都在
java.util包下,所以需要导包。 -
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
-
Map 接口提供三种collection 视图,允许以键集、值集或键-值映射关系集的形式查看某个映射的内容。映射顺序 定义为迭代器在映射的 collection 视图上返回其元素的顺序。某些映射实现可明确保证其顺序,如
TreeMap类;另一些映射实现则不保证顺序,如HashMap类。 -
HashMap底是哈希表,查询速度非常快(jdk1.8之前是数组+单向链表,1.8之后是数组+单向链表/红黑树 ,链表长度超过8时,换成红黑树)。 -
HashMap是无序的集合,存储元素和取出元素的顺序有可能不一致。 -
HashMap存储自定义类型键值,Map集合保证key是唯一的:作为key的元素,必须重写hashCode方法和equals方法,以保证key唯一
package com.tipdm.demo1; import java.util.HashMap; import java.util.Map; import java.util.Set; public class TestHashMap { public static void main(String[] args) { // 1、创建集合对象 Map<String,Integer> map = new HashMap<>(); // 2、添加元素 // HashMap中的key是唯一的,如果put多次相同的key,那么会进行替换,以最后1次为准 map.put("张三",80); map.put("李四",90); map.put("张三",100); // 3、获取元素 // 根据key获取value Integer name1 = map.get("张三"); System.out.println("张三的成绩为:"+name1); System.out.println("张三的成绩为:"+map.get("张三")); System.out.println("---------------"); // 判断key是否存在 // 判断在集合中是否有张三这个学生 if(map.containsKey("张三")){ System.out.println("张三在集合中"); }else { System.out.println("张三不在集合中"); } // 4、遍历集合 // 4.1 通过获取所有的key来进行遍历 // 用于获取所有的key Set<String> keySets = map.keySet(); for (String key:keySets){ // 根据key获取value Integer value = map.get(key); System.out.println(key+"的成绩为:"+value); } System.out.println("------------------"); // 4.2 通过 Set<Map.Entry<String, Integer>> entrySet = map.entrySet(); for(Map.Entry<String, Integer> entry:entrySet){ // 获取key String key = entry.getKey(); // 获取value Integer value = entry.getValue(); System.out.println(key+"的成绩为:"+value); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53

