
热门标签
热门文章
- 1单片机USB应用_单片机usb通信
- 2【C#关键字】DataTable_datatable 查找属性
- 3裸辞后破釜沉舟三个月,拿到SSP!
- 4Spring Kafka——基于 Spring Kafka 实现动态管理 Kafka 连接和 topic 的监听
- 5智慧树大数据分析的python_智慧树知到大数据分析的python基础搜题公众号
- 6考试专用计算机6,6所双非计算机强校,评估都是c-类,性价比高,不到500分就可考取...
- 7MySQL误删数据 回滚_mysql误删除数据回滚
- 8Code:美团代码托管平台的演进与实践_git 提交规范 美团
- 9自学PMP,可以!但没必要?考了就可以做项目经理?看完这些你就明白_考了pmp但不会编程可以去带软件项目吗
- 10Self-Attention机制的计算详解_自注意力机制公式
当前位置: article > 正文
ELK 日志分析(二)
作者:繁依Fanyi0 | 2024-04-22 08:01:20
赞
踩
ELK 日志分析(二)
一、ELK Kibana 部署
1.1 安装Kibana软件包
- #上传软件包 kibana-5.5.1-x86_64.rpm 到/opt目录
- cd /opt
- rpm -ivh kibana-5.5.1-x86_64.rpm
1.2 设置 Kibana 的主配置文件
- vim /etc/kibana/kibana.yml
- --2--取消注释,Kiabana 服务的默认监听端口为5601
- server.port: 5601
- --7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
- server.host: "0.0.0.0"
- --21--取消注释,设置和 Elasticsearch 建立连接的地址和端口
- elasticsearch.url: "http://192.168.133.10:9200"
- --30--取消注释,设置在 elasticsearch 中添加.kibana索引
- kibana.index: ".kibana"
1.3 启动 Kibana 服务
- systemctl start kibana.service
- systemctl enable kibana.service
- netstat -natp | grep 5601
1.4 验证 Kibana
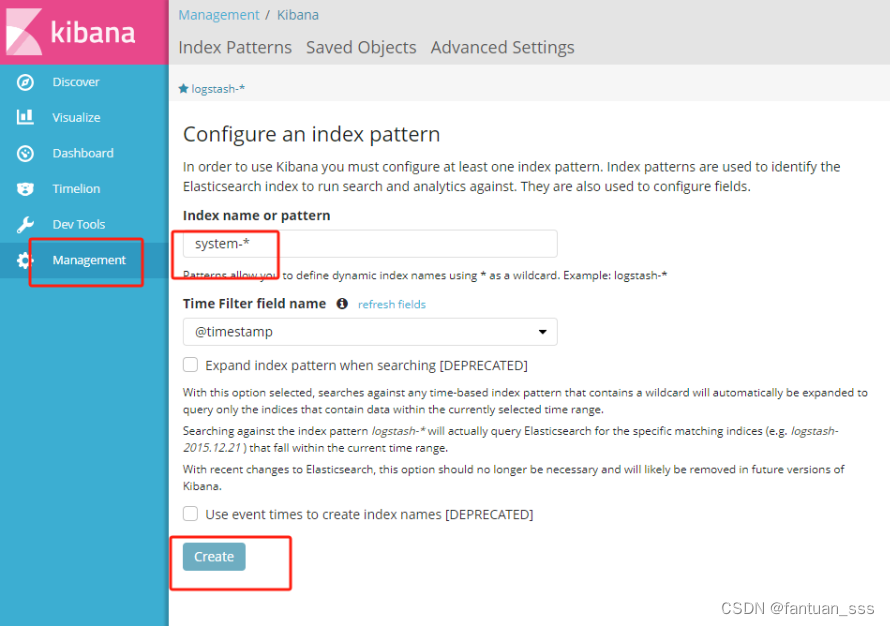
第一次登录需要添加一个 Elasticsearch 索引:
Index name or pattern 里输入:system-* #在索引名中输入之前配置的 Output 前缀“system”
单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
1.5 将 Apache 服务器日志添加到 Elasticsearch 并通过 Kibana 显示
- vim /etc/logstash/conf.d/apache_log.conf
- input {
- file{
- path => "/etc/httpd/logs/access_log"
- type => "access"
- start_position => "beginning"
- }
- file{
- path => "/etc/httpd/logs/error_log"
- type => "error"
- start_position => "beginning"
- }
- }
- output {
- if [type] == "access" {
- elasticsearch {
- hosts => ["192.168.10.13:9200"]
- index => "apache_access-%{+YYYY.MM.dd}"
- }
- }
- if [type] == "error" {
- elasticsearch {
- hosts => ["192.168.10.13:9200"]
- index => "apache_error-%{+YYYY.MM.dd}"
- }
- }
- }

- cd /etc/logstash/conf.d/
- /usr/share/logstash/bin/logstash -f apache_log.conf
二、Filebeat+ELK
2.1 简介
Filebeat是一款轻量级的日志收集工具,可以在非JAVA环境下运行。
因此,Filebeat常被用在非JAVAf的服务器上用于替代Logstash,收集日志信息。实际上,Filebeat几乎可以起到与Logstash相同的作用,可以将数据转发到Logstash、Redis或者是Elasticsearch中进行直接处理。
2.2 使用Filebeat的原因
logstash就需要消耗500M左右的内存,而filebeat只需要10M左右的内存资源。
常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat发送到logstash,lostash根据配置文件进行过滤,然后将过滤之后的文件传输到elasticsearch中,最后通过kibana展示。
2.3 好处
Filebeat结合logstash中,Filebeat负责收集日志,logstash负责过滤。
(1)通过logstash,具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻Elasticsearch持续写入数据的压力。
(2)从其它数据源(例如数据库,s3对象存储或消息传递队列)中提取
(3)将数据发送到多个目的地,例如S3,HDFS(hadoop分部署文件系统)或写入文件
(4)使用数据流逻辑组成更复杂的处理管道。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/467594
推荐阅读
相关标签

