
- 1STM32移植工程教程 包括解决Keil 一些常见的错误等等_s32ds 移植 keil startup error
- 2全网最清楚的---逻辑回归(Logistic Regression)
- 3云开发表白墙微信小程序源码_微信小程序云开发许愿墙
- 4github 配置使用 personal access token 认证_github person token
- 5GitHub和Gitee的使用_gitee ai邀请码
- 6RPM打包用户指南_rmp包amd
- 713个软件测试工具,你都会哪些?
- 8【操作系统】操作系统原理复习_一座小桥横跨南北两岸
- 9Spark RDD实现分组排行榜_spark rddgroupby时如何排序
- 10PS2游戏操纵杆_ps2摇杆模块的使用
【基于深度学习的人脸识别】(Dlib+ResNet残差神经网络)——QT(C++)+Linux_残差神经网络智能识别
赞
踩
1.基于深度学习的人脸识别模型
1.人脸识别模型
dlib_face_recognition_resnet_model_v1.dat 是基于深度学习的人脸识别模型,是dlib库中的一个重要组件。该模型的原理涉及到深度卷积神经网络(DCNN)和具体的人脸识别算法。
dlib 人脸识别采用了 Resnet 残差神经网络,识别精度高于普通神经网络,同样我们可以到官网去下载训练好的模型 dlib_face_recognition_ resnet_ model_v1. dat,通过net(接口返回 128 维人脸特征,然后再通过目标图像也同样得到128 维人脸特征,将两组特征进行对比即可判断出要识别的对象。
以下是一些详细的解释:
1. 深度卷积神经网络 (DCNN): dlib_face_recognition_resnet_model_v1.dat使用了深度学习中的卷积神经网络。深度卷积神经网络是一种强大的模型,能够自动学习图像中的特征。在人脸识别任务中,这些特征可能包括脸部的形状、眼睛、鼻子、嘴巴等。
2. ResNet 架构:
模型采用了残差网络(ResNet)的架构。ResNet是一种具有跳跃连接(skip connection)的深度神经网络结构,能够更有效地训练深层网络。这对于人脸识别等任务是有益的,因为它允许网络学习残差,即输入与期望输出之间的差异。
3. 人脸识别算法:
该模型在训练过程中学习了一种将输入图像映射到高维特征空间中的算法。这个高维向量就是人脸的描述符,包含了识别人脸的信息。通过比较两个人脸的描述符,可以判断它们之间的相似性。
4. 训练数据:
该模型是在大规模的人脸数据集上进行训练的,以学习能够泛化到不同人脸的特征。这样,模型在实际应用中能够较好地适应各种人脸。
2.模型下载
下载链接(文件名dlib_face_recognition_resnet_model_v1.dat)
下载到Ubuntu中
2.人脸录入模块
1.创建人脸录入模块
- 创建新界面ui
在原本人脸特征值识别模块项目上新建一个界面
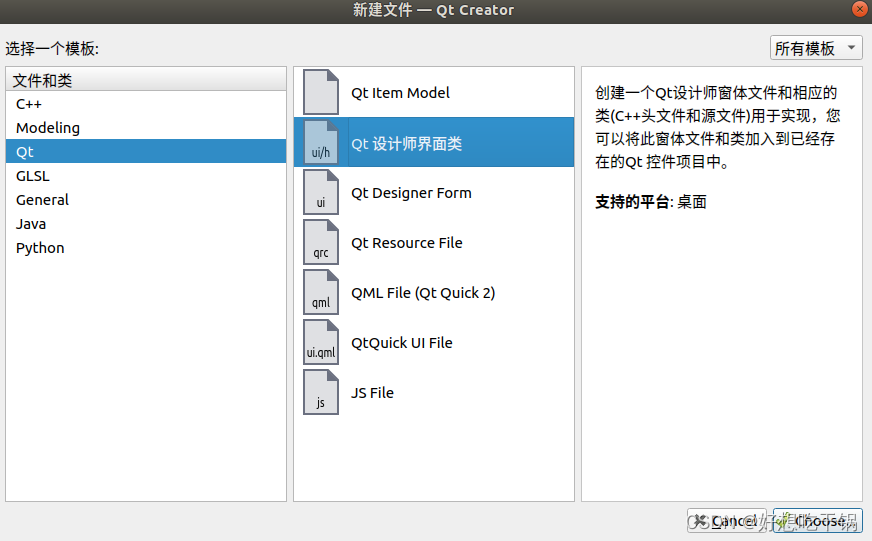
这里我命名为Face_in
在主界面创建一个按钮实现跳转,并在face_in界面上创建一个返回按钮,接下来实现两界面的跳转
face_in.ui
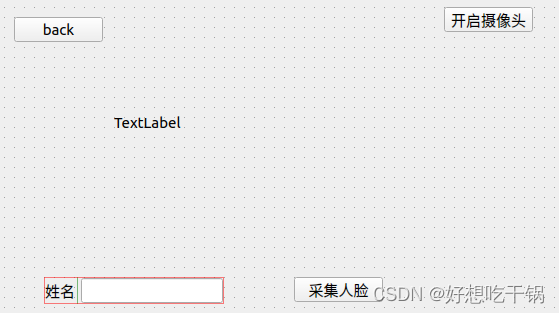
mianwindow.ui

- 界面跳转逻辑实现
这里我们使用信号与槽机制实现界面跳转(以下只是简单示例)
//先在mainwindow.h中声明face_in界面和槽函数
Face_in *face_in;
void backfromfacein();
//构造函数中实例化
face_in = new Face_in(); //人脸录入界面
face_in->setGeometry(this->geometry());
face_in->hide();
//人脸录入按钮点击事件
void MainWindow::on_face_in_clicked()
{
cap.release(); //关闭摄像头
timer->stop();
this->hide();
face_in->show();
}
//槽函数
void MainWindow::backfromfacein()
{
cap.open(0);
timer->start(10);
this->show();
face_in->hide();
}
//face_in.h中
signals:
void backtohome();
private slots:
void on_back_clicked(); //返回主界面
void on_start_face_clicked(); //开始录入人脸
void on_open_camera_clicked(); //开启摄像头
void updateframe(); //画面流
private:
VideoCapture cap;
Mat frame;
QTimer* timer;
//face_in.cpp中
void Face_in::on_back_clicked()
{
timer->stop();
cap.release();
emit backtohome();
}
//开始采集人脸
void Face_in::on_start_face_clicked()
{
//后续人脸录入逻辑
}
//开启摄像头
void Face_in::on_open_camera_clicked()
{
cap.open(0);
if (!cap.isOpened()) {
qDebug() << "Open camera failed!";
return;
}
// 创建定时器,每隔一定时间更新图像(timer在构造函数中实例化)
connect(timer, &QTimer::timeout, this, &Face_in::updateframe);
timer->start(30); // 设置定时器间隔,单位毫秒
}
void Face_in::updateframe()
{
if (cap.isOpened()) {
cap >> frame;
// 反转图像
flip(frame, frame, 1);
// 转换到label上显示
QImage img(frame.data, frame.cols, frame.rows, frame.step, QImage::Format_RGB888);
this->ui->label->setPixmap(QPixmap::fromImage(img.rgbSwapped()));
this->ui->label->setFixedSize(frame.cols, frame.rows);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
如果不了解QT信号与槽机制,可参考
以上实现了两界面的切换,并且可在人脸录入模块显示摄像头视频
2.人脸录入模块逻辑实现
我们利用摄像头对人像进行拍照并提取128D人脸特征值保存到人脸数据文件中,以便进行人脸识别
4.14:优化了人脸录入代码:录入时进行灰度化,均衡化处理,并且在采集时显示采集的照片,询问用户是否保存。并且将人脸录入和人脸识别拆开了(上文的界面跳转没有用了,仅供参考)
- 利用dlib获取人脸特征
#ifndef WIDGET_H
#define WIDGET_H
#include <QWidget>
#include <dlib/dnn.h>
#include <dlib/image_io.h>
#include <dlib/image_processing.h>
#include <dlib/opencv.h>
#include <dlib/image_processing/frontal_face_detector.h>
#include <dlib/image_processing/render_face_detections.h>
#include <opencv2/opencv.hpp>
#include <opencv2/core.hpp>
#include <QDebug>
#include <QTimer>
#include <QMessageBox>
using namespace cv;
using namespace dlib;
using namespace std;
// ----------------------------------------------------------------------------------------
template <template <int,template<typename>class,int,typename> class block, int N, template<typename>class BN, typename SUBNET>
using residual = add_prev1<block<N,BN,1,tag1<SUBNET>>>;
template <template <int,template<typename>class,int,typename> class block, int N, template<typename>class BN, typename SUBNET>
using residual_down = add_prev2<avg_pool<2,2,2,2,skip1<tag2<block<N,BN,2,tag1<SUBNET>>>>>>;
template <int N, template <typename> class BN, int stride, typename SUBNET>
using block = BN<con<N,3,3,1,1,relu<BN<con<N,3,3,stride,stride,SUBNET>>>>>;
template <int N, typename SUBNET> using ares = relu<residual<block,N,affine,SUBNET>>;
template <int N, typename SUBNET> using ares_down = relu<residual_down<block,N,affine,SUBNET>>;
template <typename SUBNET> using alevel0 = ares_down<256,SUBNET>;
template <typename SUBNET> using alevel1 = ares<256,ares<256,ares_down<256,SUBNET>>>;
template <typename SUBNET> using alevel2 = ares<128,ares<128,ares_down<128,SUBNET>>>;
template <typename SUBNET> using alevel3 = ares<64,ares<64,ares<64,ares_down<64,SUBNET>>>>;
template <typename SUBNET> using alevel4 = ares<32,ares<32,ares<32,SUBNET>>>;
using anet_type = loss_metric<fc_no_bias<128,avg_pool_everything<
alevel0<
alevel1<
alevel2<
alevel3<
alevel4<
max_pool<3,3,2,2,relu<affine<con<32,7,7,2,2,
input_rgb_image_sized<150>
>>>>>>>>>>>>;
// ----------------------------------------------------------------------------------------
std::vector<matrix<rgb_pixel>> jitter_image(
const matrix<rgb_pixel>& img
);
// ----------------------------------------------------------------------------------------
QT_BEGIN_NAMESPACE
namespace Ui { class Widget; }
QT_END_NAMESPACE
class Widget : public QWidget
{
Q_OBJECT
public:
Widget(QWidget *parent = nullptr);
~Widget();
private slots:
void on_start_face_clicked();
void on_open_camera_clicked();
void updateframe(); //画面流
void on_close_camera_clicked();
void updateImageDisplay(const cv::Mat& image);//显示采集的图像
private:
Mat frame;
VideoCapture cap;
QTimer* timer;
frontal_face_detector detector; //dlib的人脸检测器
shape_predictor sp; //预测器
anet_type net; // 创建dlib的人脸识别器
std::vector<dlib::rectangle> faces; //检测到的人脸
QImage currentImage;//存储当前采集的图像
Ui::Widget *ui;
};
#endif // WIDGET_H
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
#include "widget.h"
#include "ui_widget.h"
Widget::Widget(QWidget *parent)
: QWidget(parent)
, ui(new Ui::Widget)
{
ui->setupUi(this);
timer = new QTimer(this);
//dlib的人脸关键点检测器
detector = get_frontal_face_detector();
deserialize("/home/tj/model/shape_predictor_68_face_landmarks.dat") >> sp;
//dlib的人脸识别器
deserialize("/home/tj/model/dlib_face_recognition_resnet_model_v1.dat") >> net;
}
Widget::~Widget()
{
delete ui;
}
//采集人脸按钮
void Widget::on_start_face_clicked()
{
timer->stop(); //先暂停视频采集
if(cap.isOpened()){ //确保摄像头打开才进行采集
//人脸录入逻辑实现
QString name = ui->name_input->text(); //获取人名字
if (name.isEmpty()) {
QMessageBox::warning(this, "提示", "请输入人名!");
return;
}
Mat processedFrame = frame.clone();
cvtColor(processedFrame,processedFrame,CV_BGR2GRAY);//将彩色图转换从灰度图
equalizeHist(processedFrame,processedFrame);//进行均衡化处理
// 将OpenCV灰度图转换为dlib图像
dlib::cv_image<unsigned char> dlib_img(processedFrame);
// 获取人脸关键点
full_object_detection shape = sp(dlib_img, faces[0]);
// 截取人脸部分并调整大小对齐
matrix<rgb_pixel> face_chip;
extract_image_chip(dlib_img, get_face_chip_details(shape, 150, 0.25), face_chip);
// 提取人脸特征值
matrix<float, 0, 1> face_descriptor = net(face_chip);
// 转换为OpenCV格式
cv::Mat faceMat(face_chip.nr(), face_chip.nc(), CV_8UC1); // 灰度图,单通道
for (int r = 0; r < face_chip.nr(); ++r) {
for (int c = 0; c < face_chip.nc(); ++c) {
// 因为是灰度图,只取一个通道的值
faceMat.at<uchar>(r, c) = static_cast<uchar>(face_chip(r, c).blue);
}
}
// 调整图像大小
cv::resize(faceMat, faceMat, cv::Size(processedFrame.cols, processedFrame.rows));
// 更新图像显示
updateImageDisplay(faceMat);
QMessageBox msgBox;
msgBox.setText("是否保存此人脸图形");
msgBox.setStandardButtons(QMessageBox::Yes | QMessageBox::No);
// 获取当前窗口的底部中心位置
int x = this->x() + this->width() / 2 - msgBox.width() / 2; // 居中对齐
int y = this->y() + this->height() - msgBox.height(); // 底部对齐
// 将QMessageBox移动到窗口的底部中心
msgBox.move(x, y);
int reply = msgBox.exec();
if (reply == QMessageBox::Yes) {
// 用户选择了“是”
//保存人脸图片到文件夹
string save_path = "/home/tj/faces/";
string photo_name = save_path + name.toStdString()+ + ".jpg";
imwrite(photo_name, faceMat);
// 保存人脸特征值到文件
string file_name = save_path + name.toStdString() + ".dat";
ofstream outfile(file_name, ios::binary);
serialize(face_descriptor, outfile);
outfile.close();
QMessageBox::information(this, "提示", name + "保存成功!");
timer->start(30); //继续视频
} else {
// 用户选择了“否”
timer->start(30); //继续视频
return;
}
}
//没有打开摄像头
else{
QMessageBox::information(this,"提示","请打开摄像头");
}
}
//打开摄像头按钮
void Widget::on_open_camera_clicked()
{
cap.open(0);
if (!cap.isOpened()) {
qDebug() << "Open camera failed!";
return;
}
// 创建定时器,每隔一定时间更新图像
connect(timer, &QTimer::timeout, this, &Widget::updateframe);
timer->start(30); // 设置定时器间隔,单位毫秒
}
void Widget::updateframe()
{
cap >> frame;
// 反转图像
flip(frame, frame, 1);
// 将OpenCV图像转换为dlib图像
dlib::cv_image<dlib::bgr_pixel> dlibImage(frame);
// 使用人脸检测器检测人脸
faces = detector(dlibImage);
// 对检测到的第人脸进行处理,有人脸才处理
if (!faces.empty()) {
for(size_t i = 0; i < faces.size(); ++i) {
// 在图像上绘制人脸框
cv::rectangle(frame, cv::Point(faces[i].left(), faces[i].top()),
cv::Point(faces[i].right(), faces[i].bottom()),
cv::Scalar(0, 255, 0), 2);
}
}
// 转换到label上显示
QImage img(frame.data, frame.cols, frame.rows, frame.step, QImage::Format_RGB888);
this->ui->label->setPixmap(QPixmap::fromImage(img.rgbSwapped()));
this->ui->label->setFixedSize(frame.cols, frame.rows);
}
//关闭摄像头
void Widget::on_close_camera_clicked()
{
cap.release();
timer->stop();
}
//显示采集的图像
void Widget::updateImageDisplay(const Mat &image)
{
// 转换图像格式
QImage img(image.data, image.cols, image.rows, image.step, QImage::Format_Grayscale8);
currentImage = img.copy(); // 使用copy确保图像数据的独立性
this->ui->label->setPixmap(QPixmap::fromImage(currentImage));
this->ui->label->setFixedSize(image.cols, image.rows);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
serialize 和 deserialize 函数是 Dlib 库中用于序列化(将对象转换为字节流)和反序列化(将字节流还原为对象)的函数。这两个函数通常用于将对象保存到文件或从文件中加载对象。
serialize: 该函数用于将一个对象序列化为一个字节流,可以将这个字节流保存到文件、传输给其他系统等。在 Dlib 中,经过 serialize 处理的对象可以被保存为二进制文件。
deserialize: 该函数用于将一个字节流反序列化为原始对象。通过 deserialize,你可以还原之前使用 serialize序列化的对象。
这两个函数一起使用,使得你可以方便地保存和加载模型、数据、状态等信息。在本项目中, deserialize 函数用于加载训练好的人脸检测器、面部关键点检测器以及人脸识别器的模型
这里就成功将人脸特征保存至了指定目录下(代码做了详细注释)
3.人脸识别模块
人脸识别的主要流程:采集摄像头当前人脸数据生成128D人脸特征,再与人脸数据文件中的全部人脸特征进行对比,设置一个阈值,当两张人脸阈值小于指定阈值时,即判定属于同一个人
1.创建人脸识别模块
- dnn_face_recognition_ex.cpp代码参考dlib官网:参考
- 使用Dlib库定义的深度学习模型,基于残差网络(ResNet)结构的人脸识别模型。
// ----------------------------------------------------------------------------------------
template <template <int,template<typename>class,int,typename> class block, int N, template<typename>class BN, typename SUBNET>
using residual = add_prev1<block<N,BN,1,tag1<SUBNET>>>;
template <template <int,template<typename>class,int,typename> class block, int N, template<typename>class BN, typename SUBNET>
using residual_down = add_prev2<avg_pool<2,2,2,2,skip1<tag2<block<N,BN,2,tag1<SUBNET>>>>>>;
template <int N, template <typename> class BN, int stride, typename SUBNET>
using block = BN<con<N,3,3,1,1,relu<BN<con<N,3,3,stride,stride,SUBNET>>>>>;
template <int N, typename SUBNET> using ares = relu<residual<block,N,affine,SUBNET>>;
template <int N, typename SUBNET> using ares_down = relu<residual_down<block,N,affine,SUBNET>>;
template <typename SUBNET> using alevel0 = ares_down<256,SUBNET>;
template <typename SUBNET> using alevel1 = ares<256,ares<256,ares_down<256,SUBNET>>>;
template <typename SUBNET> using alevel2 = ares<128,ares<128,ares_down<128,SUBNET>>>;
template <typename SUBNET> using alevel3 = ares<64,ares<64,ares<64,ares_down<64,SUBNET>>>>;
template <typename SUBNET> using alevel4 = ares<32,ares<32,ares<32,SUBNET>>>;
using anet_type = loss_metric<fc_no_bias<128,avg_pool_everything<
alevel0<
alevel1<
alevel2<
alevel3<
alevel4<
max_pool<3,3,2,2,relu<affine<con<32,7,7,2,2,
input_rgb_image_sized<150>
>>>>>>>>>>>>;
// ----------------------------------------------------------------------------------------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
代码(上文也是用到了该网络)中定义了一系列模板(template)和类型别名(using),这些构建块用于构造一个深层神经网络
1.block 模板: 一个基本的残差块,包含卷积层、批归一化层和激活函数。这是构建整个网络的基本单元。2.residual 和 residual_down 类型别名: 分别表示残差块和降采样残差块。residual_down 在 avg_pool层之后执行降采样,其目的是减小特征图的尺寸。
3.ares, ares_down 类型别名: 表示使用残差块或降采样残差块的激活层。4.alevel0 到 alevel4 类型别名: 表示不同层次的网络结构,每个层次都包含多个残差块或降采样残差块。
5.anet_type 类型别名: 表示整个神经网络模型,其中包含五个层次的残差块和一些池化层,最终使用 loss_metric进行人脸识别的损失计算。
总体而言,这段代码(应该位于处理人脸识别类的头文件中)定义了一个深度学习模型,用于人脸识别,其中使用了残差网络结构来提高模型的训练和推断性能。这是基于Dlib库的一种高级抽象。
我们利用上篇文章中的人脸68位特征值检测类来进行人脸识别,大概流程为:从当前摄像头人脸中提取出特征值,遍历人脸库(上一步保存的),利用欧氏距离的阈值作为是否是同一个人的判别
2.人脸识别逻辑实现
- 创建人脸识别函数recognizeFace,该函数功能就是在程序提取出当前人脸的128D特征时对人脸库中的人脸进行遍历,找到最符合要求的人脸输出名字
//人脸识别函数
string Faceprocess::recognizeFace(const matrix<rgb_pixel> &face_chip)
{
// 从人脸形状中提取特征
matrix<float, 0, 1> face_descriptor = net(face_chip);
// 遍历已保存的人脸特征矩阵,计算特征之间的欧氏距离
double min_distance = std::numeric_limits<double>::infinity();
std::string recognized_name = "null"; // 默认值为 "null"
for (size_t i = 0; i < stored_descriptors.size(); ++i)
{
double distance = length(face_descriptor - stored_descriptors[i]);
// 如果距离小于阈值,认为是同一个人
if (distance < 0.6 && distance < min_distance)
{
recognized_name = files[i].left(files[i].size() - 4).toStdString();
min_distance = distance;
}
}
// 如果没有找到匹配的人脸,返回"null"
return recognized_name;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
可以在构造函数中进行一次性的遍历人脸库文件夹,然后将所有人脸特征存储到矩阵(stored_descriptors)中。这样,后续的识别过程就只需要比对当前人脸与这个矩阵即可,避免在每一帧都重新读取文件。
1.遍历人脸特征文件夹中的所有文件,读取每个文件的人脸特征,然后将这些特征存储到 stored_descriptors 矩阵中。files 用于迭代这些文件,获取文件路径,读取特征,最后将特征添加到 stored_descriptors 中。
2.在每一帧中,检测到人脸,并通过人脸形状提取特征,得到 face_descriptor。
3.遍历 stored_descriptors 中已保存的人脸特征,计算当前人脸特征与已保存特征之间的欧氏距离。
4.如果距离小于阈值(0.6),则认为当前人脸与已保存的某个人脸匹配,返回匹配的人脸名称。否则,返回空字符串。
- 总体识别代码
#include "faceprocess.h"
Faceprocess::Faceprocess(QObject *parent) : QObject(parent)
{
// 创建dlib的人脸检测器
detector = get_frontal_face_detector();
deserialize("/home/tj/shape_predictor_68_face_landmarks.dat") >> sp;
// 创建dlib的人脸识别器
deserialize("/home/tj/dlib_face_recognition_resnet_model_v1.dat") >> net;
// 遍历人脸库文件夹,将所有人脸特征存储到矩阵中
std::string folderPath = "/home/tj/faces/";
QDir directory(QString::fromStdString(folderPath));
files = directory.entryList(QStringList("*.dat"), QDir::Files);
// 用于存储累积的人脸描述符的矩阵
for (const auto &file : files)
{
std::string filePath = folderPath + file.toStdString();
std::ifstream infile(filePath, std::ios::binary);
if (!infile.is_open()) {
qDebug() << "人脸库文件打开失败 " << filePath.c_str();
} else {
// 文件成功打开,继续读取数据
dlib::matrix<float, 0, 1> stored_descriptor;
dlib::deserialize(stored_descriptor, infile);
infile.close();
// 将存储的描述符添加到矩阵中
stored_descriptors.push_back(stored_descriptor);
}
}
}
Faceprocess::~Faceprocess()
{
// 清理 stored_descriptors
stored_descriptors.clear();
}
void Faceprocess::processFrame(const cv::Mat &frame)
{
cv::Mat processedFrame = frame.clone();
// qDebug()<< "处理帧";
// 将OpenCV图像转换为dlib图像
dlib::cv_image<dlib::bgr_pixel> dlibImage(processedFrame);
// 使用人脸检测器检测人脸
std::vector<dlib::rectangle> faces = detector(dlibImage);
// 对检测到的第一个人脸进行处理,有人脸才处理
if (!faces.empty()) {
// 获取面部关键点
dlib::full_object_detection shape = sp(dlibImage, faces[0]);
// 在图像上绘制人脸框
cv::rectangle(processedFrame, cv::Point(faces[0].left(), faces[0].top()), cv::Point(faces[0].right(), faces[0].bottom()), cv::Scalar(0, 255, 0), 2);
// 在图像上绘制面部关键点
for (unsigned int i = 0; i < shape.num_parts(); ++i)
{
cv::circle(processedFrame, cv::Point(shape.part(i).x(), shape.part(i).y()), 2, cv::Scalar(255, 0, 0), -1);
}
// 截取人脸部分并调整大小
matrix<rgb_pixel> face_chip;
extract_image_chip(dlibImage, get_face_chip_details(shape, 150, 0.25), face_chip);
// 传入截取的人脸进行人脸识别
recognizedName = recognizeFace(face_chip);
// 输出识别结果
if (!recognizedName.empty()) {
qDebug() << "识别到的人脸:" << recognizedName.c_str();
// 在人脸矩形框上显示识别结果
cv::putText(processedFrame, recognizedName, cv::Point(faces[0].left(), faces[0].top() - 5),
cv::FONT_HERSHEY_COMPLEX, 0.5, cv::Scalar(255, 0, 0), 1);
} else {
qDebug() << "未识别到人脸";
// 在人脸矩形框上显示"unknown"
cv::putText(processedFrame, "unknown", cv::Point(faces[0].left(), faces[0].top() - 5),
cv::FONT_HERSHEY_COMPLEX, 0.5, cv::Scalar(255, 0, 0), 1);
}
}
// 转换到QImage
QImage img(processedFrame.data, processedFrame.cols, processedFrame.rows, processedFrame.step, QImage::Format_RGB888);
emit frameProcessed(img); //处理完一帧,触发信号传送出去
}
//人脸识别函数
string Faceprocess::recognizeFace(const matrix<rgb_pixel> &face_chip)
{
// 从人脸形状中提取特征
matrix<float, 0, 1> face_descriptor = net(face_chip);
// 遍历已保存的人脸特征矩阵,计算特征之间的欧氏距离
double min_distance = std::numeric_limits<double>::infinity();
std::string recognized_name = "null"; // 默认值为 "null"
for (size_t i = 0; i < stored_descriptors.size(); ++i)
{
double distance = length(face_descriptor - stored_descriptors[i]);
// 如果距离小于阈值,认为是同一个人
if (distance < 0.6 && distance < min_distance)
{
recognized_name = files[i].left(files[i].size() - 4).toStdString();
min_distance = distance;
}
}
// 如果没有找到匹配的人脸,返回"null"
return recognized_name;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
这里有个问题:cv::putText并不能显示中文,我们利用QT对中文的支持,定义一个函数进行转化(QImage上绘制中文再转换为Mat)即可:
#include <QPainter>
#include <QFont>
//解决puttext无法显示中文
void Faceprocess::PutTextChinese(Mat &inMat, QString drawText, Point wordCenter, int inWordSize, Scalar inColor)
{
QImage image;
switch (inMat.type())
{
case CV_8UC1:
image = QImage(inMat.data, inMat.cols, inMat.rows, inMat.cols, QImage::Format_Mono);
break;
case CV_8UC3:
image = QImage(inMat.data, inMat.cols, inMat.rows, inMat.cols * 3, QImage::Format_RGB888);
break;
case CV_8UC4:
image = QImage(inMat.data, inMat.cols, inMat.rows, inMat.cols * 4, QImage::Format_ARGB32);
break;
}
QColor drawColor(inColor[0], inColor[1], inColor[2]);
QPainter painter(&image);
QPen pen = QPen(drawColor, inWordSize);
QBrush brush = QBrush(drawColor);
painter.setPen(pen);
painter.setBrush(brush);
QFont font("KaiTi", inWordSize);
painter.setFont(font);
painter.drawText(QPointF(wordCenter.x, wordCenter.y), drawText);
}
//直接将cv::putText替换为PutTextChinese即可
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
效果图:
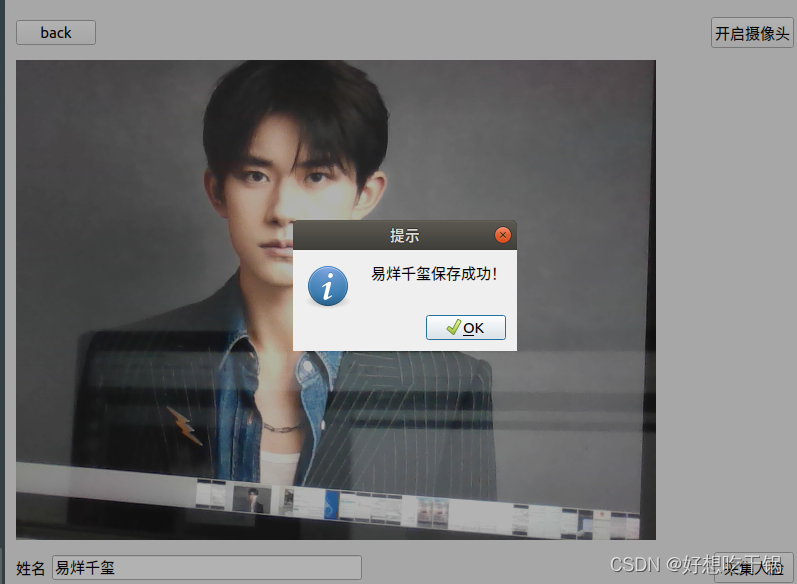

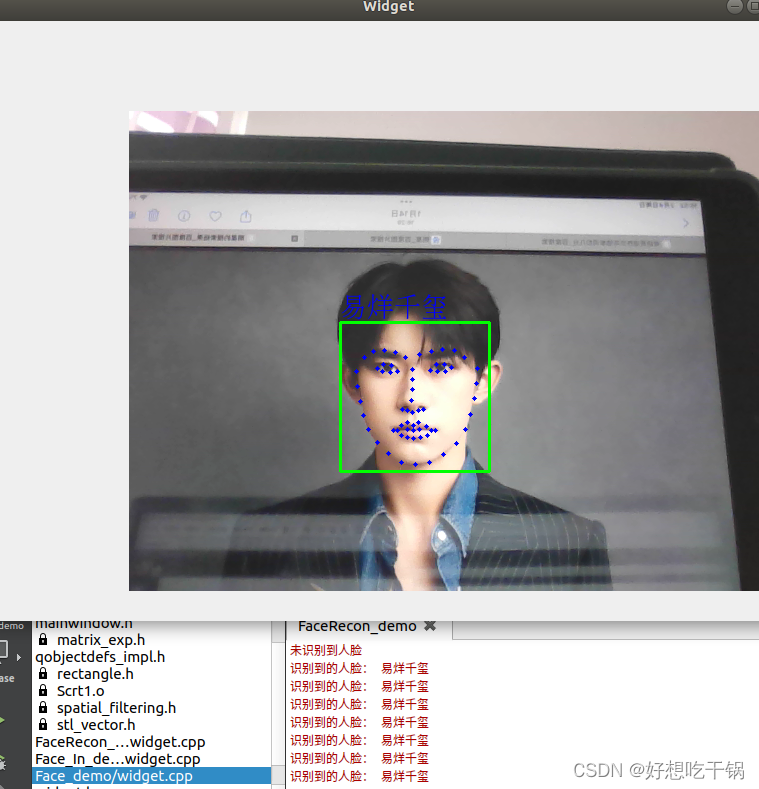
3.灰度化,均衡化
在人脸识别中,灰度化和均衡化起着重要的作用:
灰度化(Grayscale):
将彩色图像转换为灰度图像的过程。在灰度图像中,每个像素的数值表示图像中的亮度,而不再包含颜色信息。在人脸识别中,灰度化可以简化图像的复杂性,减少了颜色对识别的干扰,同时也降低了数据处理的复杂度。均衡化(Histogram Equalization):
通过调整图像的直方图来增强图像的对比度,使得图像中的像素分布更加均匀。在人脸识别中,均衡化可以提高图像的亮度和对比度,使得人脸特征更加突出,从而提高识别的准确性。综合来看,灰度化和均衡化可以帮助人脸识别系统更好地理解图像中的信息,减少不必要的噪声和干扰,从而提高识别的准确性和鲁棒性。
void Widget::updateFrame()
{
// 读取帧
cap >> frame;
flip(frame, frame, 1);
cv::Mat processedFrame = frame.clone(); //克隆一个图像用于人脸识别,保留原本的彩色图像
cvtColor(processedFrame,processedFrame,CV_BGR2GRAY);//将彩色图转换从灰度图
equalizeHist(processedFrame,processedFrame);//进行均衡化处理
// // 显示灰度图像
// cv::imshow("灰度图", processedFrame);
// cv::waitKey(0);
if (detector.num_detectors() == 0) {
qDebug() << "人脸检测器未正确初始化!";
// 处理错误情况
return;
}
// // 将OpenCV彩色图像转换为dlib图像
// dlib::cv_image<dlib::bgr_pixel> dlibImage(processedFrame);
// 将OpenCV灰度图转换为dlib图像
dlib::cv_image<unsigned char> dlibImage(processedFrame);
// 使用人脸检测器检测人脸
std::vector<dlib::rectangle> faces = detector(dlibImage);
// cout << faces.size()<< endl;
// 对检测到的第一个人脸进行处理,有人脸才处理
if (!faces.empty()) {
// 获取面部关键点
dlib::full_object_detection shape = sp(dlibImage, faces[0]);
// 在图像上绘制人脸框(在frame上绘制,防止传入神经网络的照片上有标记)
cv::rectangle(frame, cv::Point(faces[0].left(), faces[0].top()), cv::Point(faces[0].right(), faces[0].bottom()), cv::Scalar(0, 255, 0), 2);
// 在图像上绘制面部关键点
for (unsigned int i = 0; i < shape.num_parts(); ++i)
{
cv::circle(frame, cv::Point(shape.part(i).x(), shape.part(i).y()), 2, cv::Scalar(255, 0, 0), -1);
}
// 根据68位关键点截取人脸部分并调整大小,人脸对齐
matrix<rgb_pixel> face_chip;//人脸部分截图
extract_image_chip(dlibImage, get_face_chip_details(shape, 150, 0.25), face_chip);
// // 转换为OpenCV格式
// cv::Mat faceMat(face_chip.nr(), face_chip.nc(), CV_8UC3);
// for (int r = 0; r < face_chip.nr(); ++r) {
// for (int c = 0; c < face_chip.nc(); ++c) {
// faceMat.at<cv::Vec3b>(r, c) = cv::Vec3b(face_chip(r, c).blue, face_chip(r, c).green, face_chip(r, c).red);
// }
// }
// // 显示图像
// cv::imshow("Face Chip", faceMat);
// cv::waitKey(0);
if (++frameCounter % RECOGNITION_INTERVAL == 0) {
recognizedName = recognizeFace(face_chip);
frameCounter = 0; // 重置计数器
}
// 输出识别结果
if (!recognizedName.empty()) {
// 在人脸矩形框上显示识别结果
PutTextChinese(frame, QString::fromStdString(recognizedName), cv::Point(faces[0].left(), faces[0].top() - 5),
20, cv::Scalar(255, 0, 0));
} else {
//qDebug() << "未识别到人脸";
// 在人脸矩形框上显示"unknown"
cv::putText(frame, "unknown", cv::Point(faces[0].left(), faces[0].top() - 5),
cv::FONT_HERSHEY_COMPLEX, 0.5, cv::Scalar(255, 0, 0), 1);
}
}
// 转换到QImage
QImage img(frame.data, frame.cols, frame.rows, frame.step, QImage::Format_RGB888);
this->ui->label->setPixmap(QPixmap::fromImage(img.rgbSwapped()));
this->ui->label->setFixedSize(img.height(), img.width());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
测试:
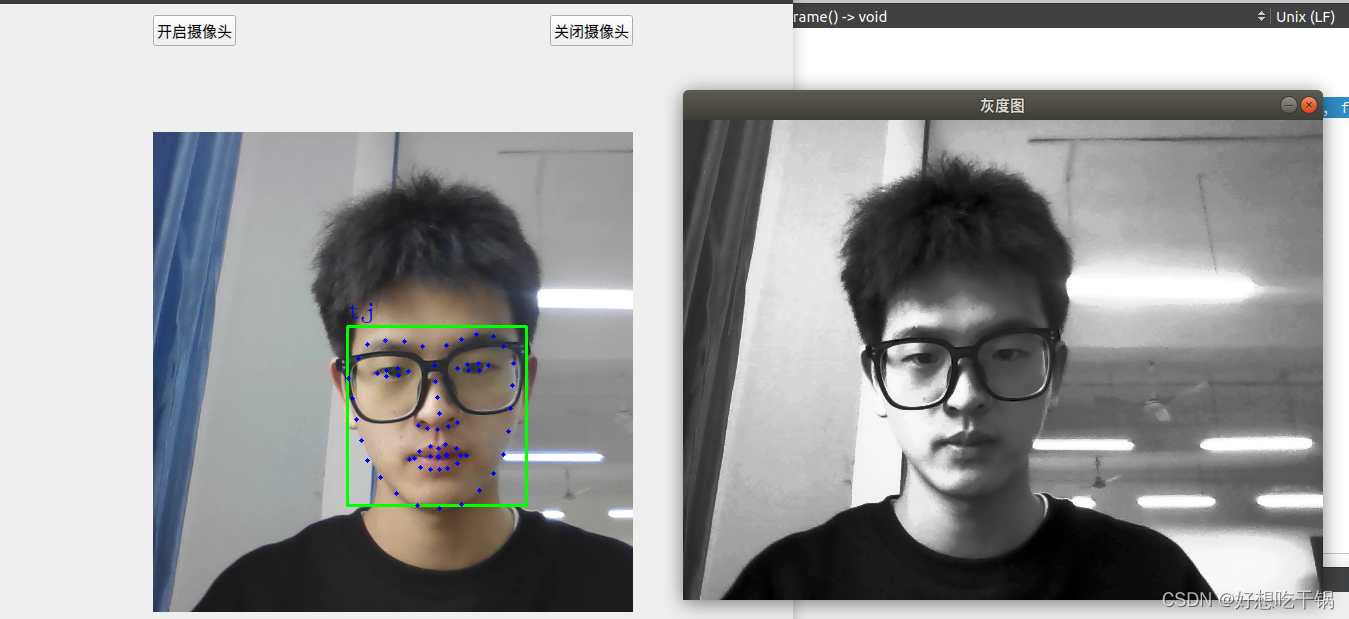
4.人脸对齐
通过后续学习,我发现之前我并未进行人脸对齐的工作,但是在检测时,我们对图像进行灰度化,均衡化以及人脸对齐过后会更加准确地提起人脸特征值,在查阅相关文献(这里可参考
[1]刘兆丰.Dlib在人脸识别技术中的运用[J].电子制作,2020(21):39-41+7.DOI:10.16589/j.cnki.cn11-3571/tn.2020.21.015.),我发现在上述程序中已经实现了人脸对齐的工作,如下:
我们可知 extract_image_chip(dlibImage, get_face_chip_details(shape, 150, 0.25), face_chip);主要完成的工作就是:根据人脸68位关键点截取人脸部分,并且实现人脸对齐工作,具体原理可参考文献,下面是验证程序:
// 根据68位关键点截取人脸部分并调整大小以及人脸对齐
matrix<rgb_pixel> face_chip;//人脸部分截图
extract_image_chip(dlibImage, get_face_chip_details(shape, 150, 0.25), face_chip);
// 转换为OpenCV格式
cv::Mat faceMat(face_chip.nr(), face_chip.nc(), CV_8UC3);
for (int r = 0; r < face_chip.nr(); ++r) {
for (int c = 0; c < face_chip.nc(); ++c) {
faceMat.at<cv::Vec3b>(r, c) = cv::Vec3b(face_chip(r, c).blue, face_chip(r, c).green, face_chip(r, c).red);
}
}
// 显示图像
cv::imshow("Face Chip", faceMat);
cv::waitKey(0);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
测试:
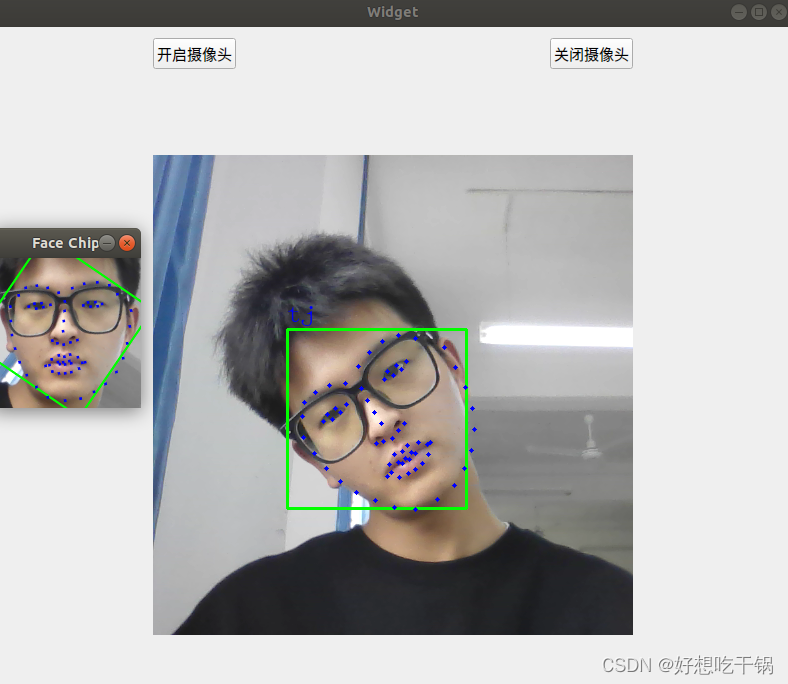
实际上就已经完成了人脸对齐。

