
- 1Unity3D 碰撞盒忽略碰撞_rigid body怎么互相不碰撞
- 2git vscode下拉代码到本地推送到远程,本地分支远程分支关联、合并_vscodegit拉取代码到本地
- 3使用Coze(扣子)为公众号/企业微信接入:月之暗面 · Kimi聊天机器人(操作教程)_coze 微信
- 4怎样查看kafka写数据送到topic是否成功_kafka 查询消息是否发送成功
- 5AI绘画stability工具大全_stabilityai/stable-diffusion-2-inpainting
- 6自动驾驶-最优控制方法LQR的C语言工程实现【附Github源码链接】_github 有自动驾驶规划控制代码
- 7android技巧:dumpsys简化信息查看Activity结构_dumpsys activity activities
- 8Android蓝牙BLE开发_android ble
- 9OpenWrt:使用WinSCP传输文件_openwrt接winscp
- 10Gitblit服务搭建+Git安装+TortoiseGit安装(完整版)
ELK日志采集系统搭建
赞
踩
需求背景
现在的系统大多比较复杂,一个服务的背后可能就是一个集群的机器在运行,各种访问日志、应用日志、错误日志量随着访问量和时间会越来越多,运维人员就无法很好的去管理日志,开发人员排查问题,需要到服务器上查日志,极为不方便。逐台登陆机器去查看日志特别费力,且效率慢。
为什么要用 ELK?
在日志分析场景一般使用最多的就是通过 grep、awk 命令获取想要的日志信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大、难以归档、搜索慢、多维度查询困难等。
如果像搜索引擎一样通过关键字搜索出相关的日志,岂不快哉。于是就有了集中式日志系统。ELK 就是其中一款使用最多的开源产品。
常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
ELK 架构
ELK(Elasticsearch + Logstash + Kibana)是一套开源的日志管理方案,三者组合在一起搭建实时的日志分析平台。
- Elasticsearch:简称 ES,是个开源分布式搜索引擎,是ELK的核心,基于Apache Lucene的开源数据搜索引擎,可以实时快速的搜索和分析,性能强悍。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。
- Logstash:一个具有实时传输能力的数据收集引擎,用来数据收集、分析、过滤日志的工具,支持多类型日志
- Kibana:为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
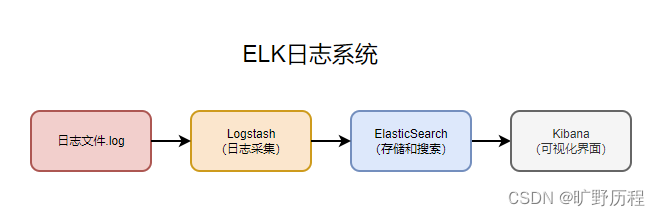
这是最简单的一种 ELK 架构方式。此架构由 Logstash 分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的 Elasticsearch 进行存储。Elasticsearch 将数据以分片的形式压缩存储并提供多种API供用户查询,操作。用户亦可以更直观的通过配置 Kibana Web 方便的对日志查询,并根据数据生成报表。
优点:搭建简单,易于上手。
缺点:Logstash 耗资源较大,占用 CPU 和内存高。另外没有消息队列缓存,存在数据丢失隐患。
为解决传统 ELK 架构上的不足,对此进行了以下扩展:
Filebeat:一个轻量级日志采集器,早期的 ELK 架构中使用 Logstash 收集、解析日志,但是 Logstash 对内存、cpu、io 等资源消耗比较高,相比 Logstash,Filebeat 所占系统的 CPU 和内存几乎可以忽略不计。适合于在各个服务器上搜集日志后传输给 Logstash,官方也推荐此工具。
Kafka:一种高吞吐量的分布式发布订阅消息系统,如果日志量巨大,还需要引入Kafka用以均衡网络传输,降低网络闭塞,保证数据不丢失,还可以系统之间解耦,具有更好的灵活性和扩展性。
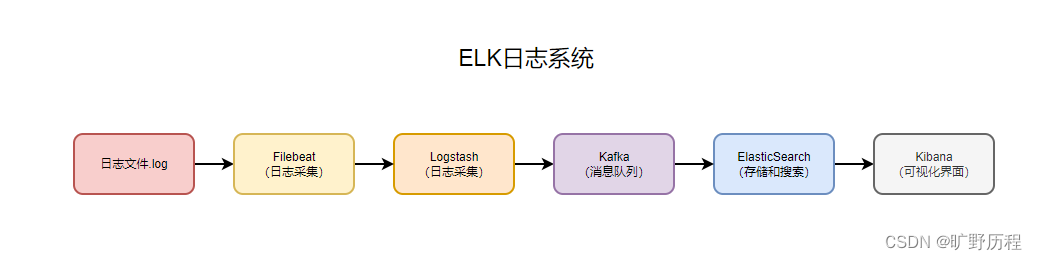
filebeat 收集需要提取的日志文件,将日志文件转存到 kafka 中,logstash 处理 kafka 日志,格式化处理,并将日志输出到 elasticsearch 中,前台页面通过 kibana 展示日志。
使用 kafka 做缓存层,而不是直接将 filebeat 收集到的日志信息写入 logstash,让整体结构更健壮,减少网络环境,导致数据丢失。filebeat 负责将收集到的数据写入 kafka,logstash 取出数据并处理。
即解决的资源消耗过大问题,也解决了消息可能丢失的隐患。
环境介绍
- jdk:17
- kafka:3.3.2
- elasticsearch:7.17.10
- filebeat:7.17.10
- kibana:7.17.10
- logstash:7.17.10
JDK17
配置 JDK 环境,elasticsearch:7.17.10 需要 Java 11 以上的版本。
Kafka
1、下载并解压
新版的 kafka 已经内置了一个 zookeeper 环境,所以我们可以直接使用。
2、配置 zookeeper
zookeeper.properties
- # 数据文件目录
- dataDir=/data/zookeeper/data
- # 客户端连接端口
- clientPort=2181
- # 客户端最大连接数限制
- maxClientCnxns=0
- admin.enableServer=false
启动
./bin/zookeeper-server-start.sh ./config/zookeeper.properties &2、配置 kafka
server.properties
- # 监听
- listeners=PLAINTEXT://192.168.200.11:9092
- # 日志存放路径
- log.dirs=/data/logs/kafka
- # zookeeper地址和端口
- zookeeper.connect=192.168.200.11:2181
启动
./bin/kafka-server-start.sh ./config/server.properties &3、测试
生产者发送消息测试
./bin/kafka-console-producer.sh --topic test --bootstrap-server 192.168.200.11:9092![]()
消费者消费消息测试
./bin/kafka-console-consumer.sh --topic test --from-beginning --bootstrap-server 192.168.200.11:9092 
Filebeat
如上面所说,简单搭建的 ELK 是有缺陷的,如果 Logstash 需要添加插件,那就全部服务器的 Logstash 都要添加插件,扩展性差。所以就有了 FileBeat,占用资源少,只负责采集日志,不做其他的事情。
1、下载并解压
2、配置 filebeat.yml 文件
- inputs:Filebeat 的输入为目标日志
- ouput:Filebeat 的输出为 kakfa,指定 topic
- # ============================== Filebeat inputs ===============================
-
- filebeat.inputs:
- - type: log
- id: filebeat-user-log
- enabled: true
- paths:
- - /data/logs/*.log
- # 定义日志标签,注意:不同的服务使用不同的标签
- tags: ["user-log"]
-
- # 注释掉
- # ---------------------------- Elasticsearch Output ----------------------------
- #output.elasticsearch:
- # Array of hosts to connect to.
- # hosts: ["localhost:9200"]
-
- # Protocol - either `http` (default) or `https`.
- #protocol: "https"
-
- # Authentication credentials - either API key or username/password.
- #api_key: "id:api_key"
- #username: "elastic"
- #password: "changeme"
-
- # 新增
- # ------------------------------ kafka Output -------------------------------
- output.kafka:
- enable: true
- hosts: ["192.168.200.11:9092"]
- topic: "elk_logs_topic"
3、启动
启动Filebeat,需要指定配置文件,即刚才配置好的 filebeat.yml
./filebeat -c filebeat.yml &注意
filebeat.yml 文件权限为 644,否则会报错:Exiting: error loading config file: config file ("filebeat.yml") can only be writable by the owner but the permissions are "-rw--w--w-" (to fix the permissions use: 'chmod go-w /opt/filebeat/7.17.10/filebeat.yml')
权限分别由三个数字表示:
- r = 4
- w = 2
- x = 1
使用数字表示权限时,每组权限分别对应数字之和:
- rw = 4 + 2 = 6
- rwx = 4 + 2 + 1 = 7
- r-x = 4 + 1 = 5
Elasticsearch
1、下载并解压
2、创建用户
root用户不能启动 elasticsearch 需要创建独立的用户
useradd elastic3.修改文件归属用户
chown -R elastic:elastic 7.17.10/切换用户
su elastic4、配置 config/elasticsearch.yml 文件
- http.port: 9200
- http.host: 0.0.0.0
- http.cors.enabled: true
- http.cors.allow-origin: "*"
- http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
- # 如果需要设置密码需要开启下面两行
- # xpack.security.enabled: true
- # xpack.security.transport.ssl.enabled: true
5、启动
./bin/elasticsearch &6、测试
- [elastic@localhost 7.17.10]$ curl 192.168.200.11:9200
- {
- "name" : "localhost.localdomain",
- "cluster_name" : "elasticsearch",
- "cluster_uuid" : "6_zpcReFSTuR9hgkj9eOKg",
- "version" : {
- "number" : "7.17.10",
- "build_flavor" : "default",
- "build_type" : "tar",
- "build_hash" : "fecd68e3150eda0c307ab9a9d7557f5d5fd71349",
- "build_date" : "2023-04-23T05:33:18.138275597Z",
- "build_snapshot" : false,
- "lucene_version" : "8.11.1",
- "minimum_wire_compatibility_version" : "6.8.0",
- "minimum_index_compatibility_version" : "6.0.0-beta1"
- },
- "tagline" : "You Know, for Search"
- }
LogStash
使用 FileBeat 采集日志时就可以把 Logstash 抽出来,做一些滤处理之类的工作。
1、下载并解压
2、配置 config/logstash.yml 文件
node.name: local3、创建 logstash-kafka.conf 配置文件
- input :Logstash 去接 Filebeat 发送到 Kafka 的数据,配置 Kafka 相关的信息,指定 topic,并指明类型为 json
- output : 需要向 ES 中存储,指定ES的地址,并创建索引:名称-年份.月份
- input {
- kafka {
- bootstrap_servers => ["192.168.200.11:9092"]
- group_id => "elk_logs_group"
- topics => ["elk_logs_topic"]
- consumer_threads => 5
- codec => json {
- charset => "UTF-8"
- }
- }
- }
-
- output {
- # 按照日志标签对日志进行分类处理,日志标签在 filebeat 中定义
- if "user-log" in [tags] {
- elasticsearch {
- hosts => ["http://192.168.200.11:9200"]
- index => "user-log-%{+YYYY.MM.dd}"
- # user => "elastic"
- # password => "elastic"
- }
- }
- if "order-log" in [tags] {
- elasticsearch {
- hosts => ["http://192.168.200.11:9200"]
- index => "order-log-%{+YYYY.MM.dd}"
- # user => "elastic"
- # password => "elastic"
- }
- }
- }
注意,需要保证格式的正确,且不能大写,要不然 LogStash会抛出异常。
3、启动
./bin/logstash -f ./config/logstash-kafka.conf &Kibana
1、下载并解压
2、创建用户
root用户不能启动 kibana 需要创建独立的用户
useradd kibana3、修改文件拥有用户
chown -R kibana:kibana 7.17.10/切换用户
su kibana4、配置 kibana.yml 文件
- server.port: 5601
- server.host: "192.168.200.11"
- elasticsearch.hosts: ["http://192.168.200.11:9200"]
- # 中文页面
- i18n.locale: "zh-CN"
5、启动
./bin/kibana6、测试
打开浏览器输入 localhost:5601 ,如果能打开说明启动成功。
到此,程序安装工作就已经结束了。

