
- 1vue中代理proxy的原理_vue proxy代理原理
- 2Git 修改已提交的commit注释_tortoisegit 修改已经提交的注释
- 3Android -- Autosizing TextView 自动调整文字大小_autosizemaxtextsize
- 4微信小程序上传图片_微信小程序上传图片怎么实现
- 5汽车加油行驶问题全网最详细(动态规划+画图)_动态规划算法汽车加油问题
- 6rabbitmqWeb管理界面无法打开的问题_mq阻塞,管理端页面打不开了
- 7不到 50 行 Python 代码,做个刮刮卡_python制作刮刮乐
- 8Windows系统下的可用SNMP软件-[资源]_snmpwalk windows
- 9Spring Cloud 学习笔记(2 3)_@feignclient 限流请求次数
- 10讲真,做Python一定不要只会一个方向!
关键词抽取方法
赞
踩
1、关键词提取
为了方便用户快速了解文章的中心主题,会抽取文章的一些中心词来表达文章的中心思想。关键词抽取就是通过一定的方法抽取出能表达文章的中心主题的一系列方法。
2、关键词抽取方法分类
2.1、有监督无监督抽取方法
无监督关键词提取方法主要有三类:基于统计特征的关键词提取(TF,TF-IDF);基于词图模型的关键词提取(PageRank,TextRank);基于主题模型的关键词提取(LDA)
- 基于统计特征的关键词提取算法的思想是利用文档中词语的统计信息抽取文档的关键词;
- 基于词图模型的关键词提取首先要构建文档的语言网络图,然后对语言进行网络图分析,在这个图上寻找具有重要作用的词或者短语,这些短语就是文档的关键词;
- 基于主题关键词提取算法主要利用的是主题模型中关于主题分布的性质进行关键词提取;
有监督关键词提取方法
将关键词抽取过程视为二分类问题,先提取出候选词,然后对于每个候选词划定标签,要么是关键词,要么不是关键词,然后训练关键词抽取分类器。当新来一篇文档时,提取出所有的候选词,然后利用训练好的关键词提取分类器,对各个候选词进行分类,最终将标签为关键词的候选词作为关键词。
2.2、无监督方法和有监督方法优的缺点
无监督方法不需要人工标注训练集合的过程,因此更加快捷,但由于无法有效综合利用多种信息 对候选关键词排序,所以效果无法与有监督方法媲美;而有监督方法可以通过训练学习调节多种信息对于判断关键词的影响程度,因此效果更优,有监督的文本关键词提取算法需要高昂的人工成本,因此现有的文本关键词提取主要采用适用性较强的无监督关键词提取。
2.3、关键词提取常用工具包
- jieba
- Textrank4zh (TextRank算法工具)
- SnowNLP (中文分析)简体中文文本处理
- TextBlob (英文分析)
3、常见的关键词抽取方法
3.1、TFIDF
3.1.1、TF-IDF算法介绍
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。 TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
词频(TF)表示词条(关键字)在文本中出现的频率。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。表示如下:
TF=该词语在这篇内容中出现的次数/这篇内容所有的词语数量
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1
IDF=log((语料库中的文档总数包含该词语的文档数+1)/(语料库中的文档总数包含该词语的文档数+1))
TF-IDF=TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
3.1.2、TFIDF关键词提取jieba实现
- import jieba.analyse
-
- '''
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- '''
-
- text = '关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、\
- 信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、\
- 文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作\
- '
-
- keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=True, allowPOS=())
- print(keywords) #[('文档', 0.7683580497346154), ('文本', 0.4587102868907692), ('关键词', 0.45658796811333335), ('挖掘', 0.37005466278512816), ('文本检索', 0.30653250007435895)]
-

3.1.3、tfidf的缺点
优点:
解释性强,能快速实现
缺点:
1)TF-IDF 采用文本逆频率 IDF 对 TF 值加权取权值大的作为关键词,但 IDF 的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以 TF-IDF 算法的精度并不是很高,尤其是当文本集已经分类的情况下。
2)在本质上 IDF 是一种试图抑制噪音的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用。这对于大部分文本信息,并不是完全正确的。IDF 的简单结构并不能使提取的关键词, 十分有效地反映单词的重要程度和特征词的分布情 况,使其无法很好地完成对权值调整的功能。尤其是在同类语料库中,这一方法有很大弊端,往往一些同类文本的关键词被盖。
3)没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
4)按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
5)传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
6)对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
3.2、TextRank关键词提取
3.2.1、TextRank原理简介
TextRank算法是一种基于图的用于关键词抽取和文档摘要的排序算法,由谷歌的网页重要性排序算法PageRank算法改进而来,它利用一篇文档内部的词语间的共现信息(语义)便可以抽取关键词,它能够从一个给定的文本中抽取出该文本的关键词、关键词组,并使用抽取式的自动文摘方法抽取出该文本的关键句。
TextRank算法的基本思想是将文档看作一个词的网络,该网络中的链接表示词与词之间的语义关系。TextRank算法将词视为“万维网上的节点”,根据词之间的共现关系计算每个词的重要性,并将PageRank中的有向边变为无向边。

3.2.2、TextRank具体构建过程

3.2.3、TextRank实例
- import jieba.analyse
- '''
- jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 textrank 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- '''
-
- if __name__ == "__main__":
- text = "来源:中国科学报本报讯(记者肖洁)又有一位中国科学家喜获小行星命名殊荣!4月19日下午,中国科学院国家天文台在京举行“周又元星”颁授仪式," \
- "我国天文学家、中国科学院院士周又元的弟子与后辈在欢声笑语中济济一堂。国家天文台党委书记、" \
- "副台长赵刚在致辞一开始更是送上白居易的诗句:“令公桃李满天下,何须堂前更种花。”" \
- "据介绍,这颗小行星由国家天文台施密特CCD小行星项目组于1997年9月26日发现于兴隆观测站," \
- "获得国际永久编号第120730号。2018年9月25日,经国家天文台申报," \
- "国际天文学联合会小天体联合会小天体命名委员会批准,国际天文学联合会《小行星通报》通知国际社会," \
- "正式将该小行星命名为“周又元星”。"
-
- # 基于jieba的textrank算法实现
- keywords = jieba.analyse.textrank(text,topK=6,withWeight=True)
-
- print(keywords) #[('小行星', 1.0), ('命名', 0.6266890825831086), ('国际', 0.5926007143549065), ('中国', 0.5078347136494592), ('国家', 0.45833708297743847), ('天文学家', 0.3978444911417721)]
-
-
优点:
1) 无监督方式,无需构造数据集训练。
2) 算法原理简单且部署简单。
3) 继承了PageRank的思想,效果相对较好,相对于TF-IDF方法,可以更充分的利用文本元素之间的关系。
缺点:
1) 结果受分词、文本清洗影响较大,即对于某些停用词的保留与否,直接影响最终结果。
2) 虽然与TF-IDF比,不止利用了词频,但是仍然受高频词的影响,因此,需要结合词性和词频进行筛选,以达到更好效果,但词性标注显然又是一个问题。
3.3、LDA(Latent Dirichlet Allocation)文档主题生成模型
主题模型是一种统计模型用于发现文档集合中出现的抽象“主题”。主题建模是一种常用的文本挖掘工具,用于在文本体中发现隐藏的语义结构。
LDA也称三层贝叶斯概率模型,包含词、主题和文档三层结构;利用文档中单词的共现关系来对单词按主题聚类,得到“文档-主题”和“主题-单词”2个概率分布。
PLSA和LDA的过程是一样的,只是引入了dirichlet主题分布和词分布的先验
3.2.1、LDA理论

根据文档反推其主题分布
反过来,既然文档已经产生,那么如何根据已经产生好的文档反推其主题呢?这个利用看到的文档推断其隐藏的主题(分布)的过程(其实也就是产生文档的逆过程),便是主题建模的目的:自动地发现文档集中的主题(分布)。
换言之,人类根据文档生成模型写成了各类文章,然后丢给了计算机,相当于计算机看到的是一篇篇已经写好的文章。现在计算机需要根据一篇篇文章中看到的一系列词归纳出当篇文章的主题,进而得出各个主题各自不同的出现概率:主题分布。即文档d和单词w是可被观察到的,但主题z却是隐藏的。
如下图所示(图中被涂色的d、w表示可观测变量,未被涂色的z表示未知的隐变量,N表示一篇文档中总共N个单词,M表示M篇文档):
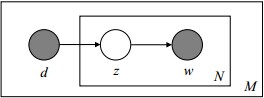
上图中,文档d和词w是我们得到的样本(样本随机,参数虽未知但固定,所以pLSA属于频率派思想。区别于LDA:样本固定,参数未知但不固定,是个随机变量,服从一定的分布,所以LDA属于贝叶斯派思想),可观测得到,所以对于任意一篇文档,其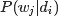
从而可以根据大量已知的文档-词项信息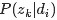
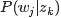
故得到文档中每个词的生成概率为:
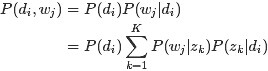

3.3.2、基于LDA主题模型的关键词提取算法实现
- from gensim import corpora, models
- import jieba.posseg as jp
- import jieba
-
- def get_text(texts):
- flags = ('n', 'nr', 'ns', 'nt', 'eng', 'v', 'd') # 词性
- stopwords = ('的', '就', '是', '用', '还', '在', '上', '作为') # 停用词
- words_list=[]
-
- for text in texts:
- words = [w.word for w in jp.cut(text) if w.flag in flags and w.word not in stopwords]
-
- words_list.append(words)
- return words_list
-
- def lda_model(words_list):
- dictionary=corpora.Dictionary(words_list)
- #dictionary.token2id获取<单词,id>对;dictionary.doc2bow获取<文档,向量>对
- print(dictionary.token2id)
- corpus=[dictionary.doc2bow(words) for words in words_list]
- print(corpus)
-
- #lda主题模型
- lda_model = models.ldamodel.LdaModel(corpus=corpus, num_topics=2, id2word=dictionary, passes=10)
- return lda_model
-
-
- if __name__ == "__main__":
- texts = ['作为千元机中为数不多拥有真全面屏的手机,OPPO K3一经推出,就簇拥不少粉丝', \
- '很多人在冲着这块屏幕购买了OPPO K3之后,发现原来K3的过人之处不止是在屏幕上', \
- 'OPPO K3的消费者对这部手机总体还是十分满意的', \
- '吉利博越PRO在7月3日全新吉客智能生态系统GKUI19发布会上正式亮相', \
- '今年上海车展,长安CS75 PLUS首次亮相', \
- '普通版车型采用的是双边共双出式排气布局;运动版本车型采用双边共四出的排气布局']
- # 获取分词后的文本列表
- words_list = get_text(texts)
- print('分词后的文本:')
- print(words_list)
-
- # 获取训练后的LDA模型
- lda_model = lda_model(words_list)
-
- # 可以用 print_topic 和 print_topics 方法来查看主题
- # 打印所有主题,每个主题显示5个词
- topic_words = lda_model.print_topics(num_topics=2, num_words=5)
- print('打印所有主题,每个主题显示5个词:')
- print(topic_words)
-
- # 输出该主题的的词及其词的权重
- words_list = lda_model.show_topic(0, 5)
- print('输出该主题的的词及其词的权重:')
- print(words_list)
3.3.3、LDA优缺点
优点
1、LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。无需标注数据
2、它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。易于理解
3、document-level word co-occurrences 很稀疏,短文本上效果不好
缺点
1、但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。
2、每一个主题又代表了很多单词所构成的一个概率分布。由于 Dirichlet分布随机向量各分量间的弱相关性(之所以还有点“相关”,是因为各分量之和必须为1),使得我们假想的潜在主题之间也几乎是不相关的,这与很多实际问题并不相符,从而造成了LDA的又一个遗留问题。
3.4、基于词向量和聚类的关键词提取方法
先将文本中的词词向量表示->通过kmeans方法聚类->计算各个词与各个中心的距离->选取每个聚类的关键词;目前词向量表示方法有fasttext,word2vec,bert等。
3.5、有监督问题的特征选择提取词
一般在模型中,词都可以表示为特征,通过模型训练可以发现一些一些关键的特征;在文本中,这些特征可以对应于词。比如树模型的信息增益,gini系数等
参考文献
https://www.cnblogs.com/enhaofrank/p/13972754.html (关键词提取 LDA,TFIDF)
https://blog.csdn.net/asialee_bird/article/details/96454544 (关键词提取的方法汇总,tfidf,textrank,lda,word2vec,信息增益,卡方检验,树模型)
https://blog.csdn.net/asialee_bird/article/details/81486700 (tfidf算法介绍及实现)
https://blog.csdn.net/asialee_bird/article/details/96894533 (textrank算法介绍)
https://blog.csdn.net/wotui1842/article/details/80351386(textrank和pagerank的区别、以及textrank的具体构建过程;textrank4zh源码详解)
https://zhuanlan.zhihu.com/p/126733456 (textrank和pagerank的区别;给出了构建图的实例)
https://www.cnblogs.com/jackchen-net/p/8207009.html (jieba的各种使用)
https://blog.csdn.net/v_JULY_v/article/details/41209515 (LDA主题模型详解)
https://blog.csdn.net/chuange6363/article/details/100752622(LDA优缺点)

