
- 1myCobot pro 机械臂(6)逆向运动学_机械臂逆运动学
- 2Flink CDC 整库 / 多表同步至 Kafka 方案(附源码)_cdckafka
- 3Your branch and 'origin/master' have diverged, and have # and # different commits each, respectively
- 4python实现Android实时投屏操控_scrcpy投屏python
- 5职场生存法则和处世之道_职场处事之道
- 6《从零开始学python+自然语言处理100题》——给自己的记录_自然语言处理100练
- 7【深度学习图像识别课程】keras实现CNN系列:(7)迁移学习的原理和应用_机器学习、迁移学习和cnn
- 8windows版redis_redis windows
- 9分布式学习-总结
- 10图像分割实战-系列教程2:Unet系列算法(Unet、Unet++、Unet+++、网络架构、损失计算方法)
CLIP 浅析
赞
踩
CLIP 浅析
概述
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。
如何训练CLIP
CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
其中CLIP的流程图如下
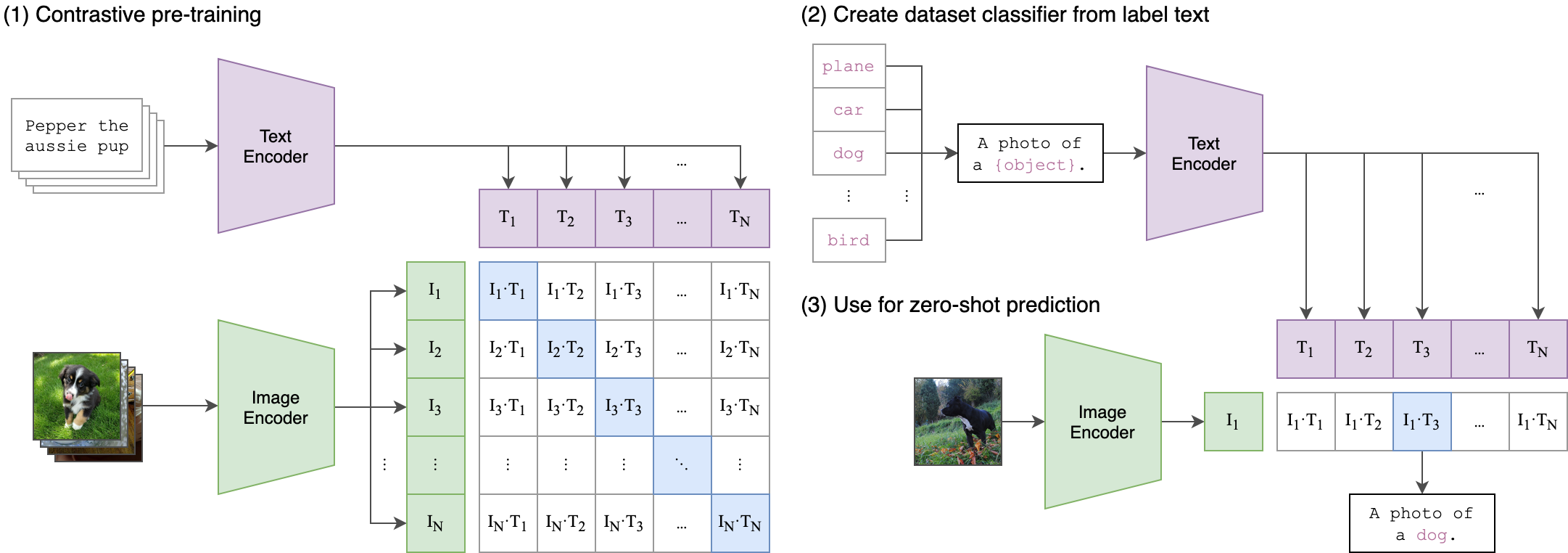
首先CLIP通过一个文本编码器和图像编码器获得相关特征
其中对于通过文本编码器获得的特征记为 T i T_i Ti 表示第 i i i个文本特征,其中共含有 N N N个特征, N N N为训练数据集中的文本信息中的类别个数,对于通过图像编码器获得的特征记为 I i I_i Ii 表示第 i i i个图像特征,并将 I i I_i Ii与每一个文本特征 T i T_i Ti进行余弦相似度计算。并使用softmax计算概率得到最相似的图文匹配对。其中伪代码如下
# image_encoder - ResNet or Vision Transformer # text_encoder - CBOW or Text Transformer # I[n, h, w, c] - minibatch of aligned images # T[n, l] - minibatch of aligned texts # W_i[d_i, d_e] - learned proj of image to embed # W_t[d_t, d_e] - learned proj of text to embed # t - learned temperature parameter # 分别提取图像特征和文本特征 I_f = image_encoder(I) #[n, d_i] T_f = text_encoder(T) #[n, d_t] # 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化 I_e = l2_normalize(np.dot(I_f, W_i), axis=1) T_e = l2_normalize(np.dot(T_f, W_t), axis=1) # 计算缩放的余弦相似度:[n, n] logits = np.dot(I_e, T_e.T) * np.exp(t) # 对称的对比学习损失:等价于N个类别的cross_entropy_loss labels = np.arange(n) # 对角线元素的labels loss_i = cross_entropy_loss(logits, labels, axis=0) loss_t = cross_entropy_loss(logits, labels, axis=1) loss = (loss_i + loss_t)/2

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对,论文称之为WebImageText。
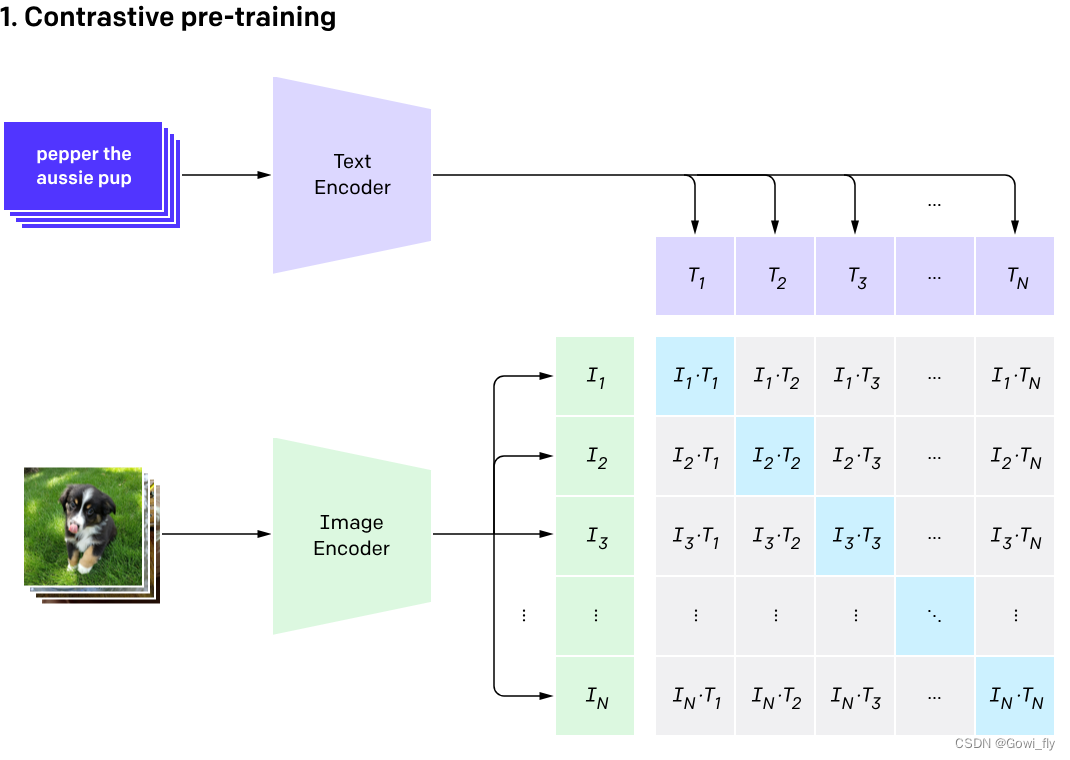
如何使用Clip进行图像分类
因为ImageNet中的label全是图像类别的表情,为了更好的适应Transformer,作者使用了A photo of {label}的句子作为输入。
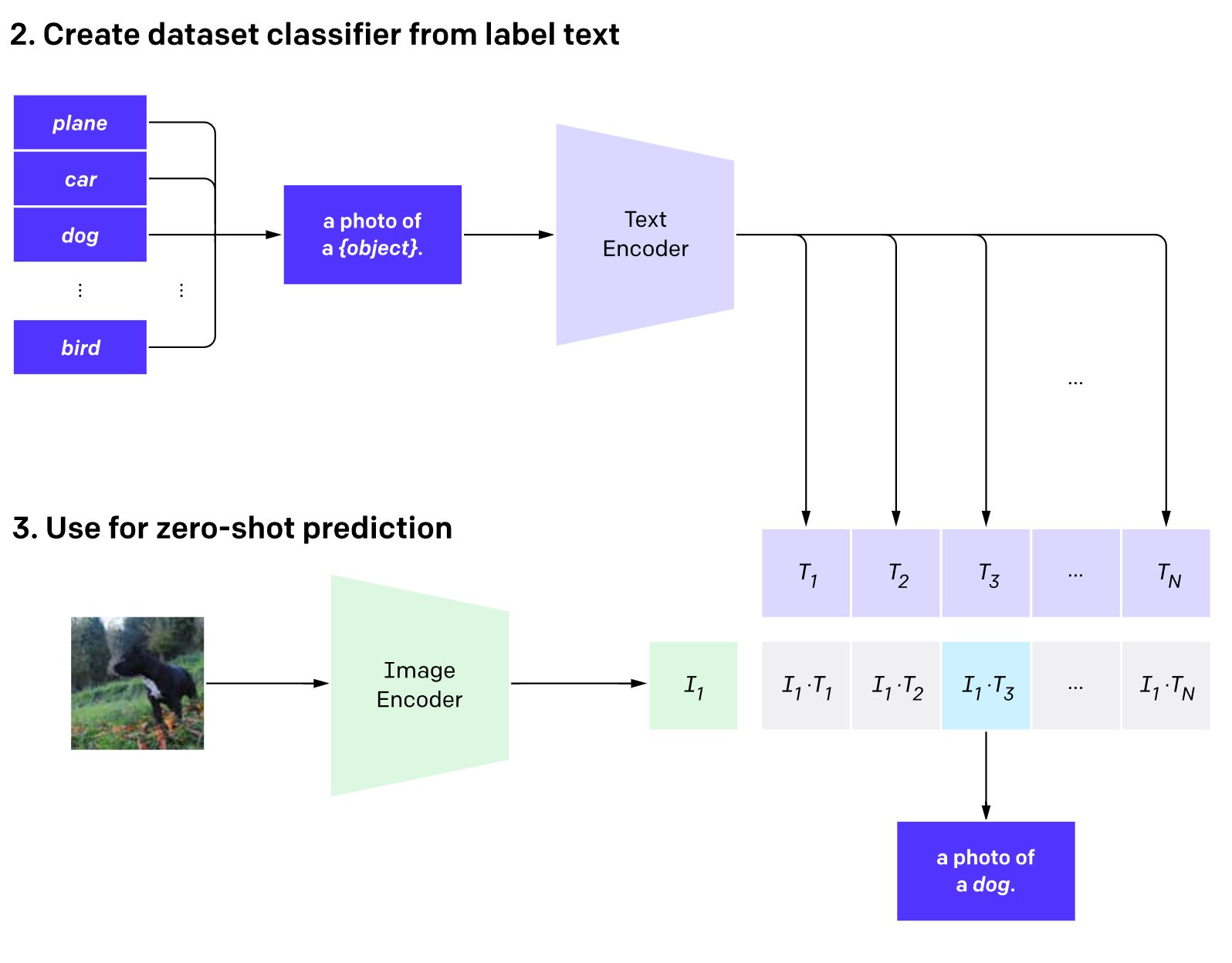
伪代码如下
# 首先生成每个类别的文本描述
labels = ["dog", "cat", "bird", "person", "mushroom", "cup"]
text_descriptions = [f"A photo of a {label}" for label in labels]
text_tokens = clip.tokenize(text_descriptions).cuda()
# 提取文本特征
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
然后通过计算余弦相似度,并使用softmax计算概率得到最相似的图文匹配对。
优缺点分析
优点
因为CLIP使用图文对的形式进行训练,所以可以从互联网上获得大量的数据进行训练,从而无需大量的人工标注。因为大数据集的原因使得CLIP与CV中常用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类。
同时OpenAI证明了CLIP在许多数据集上与ResNet50具有相似甚至更好的准确率。
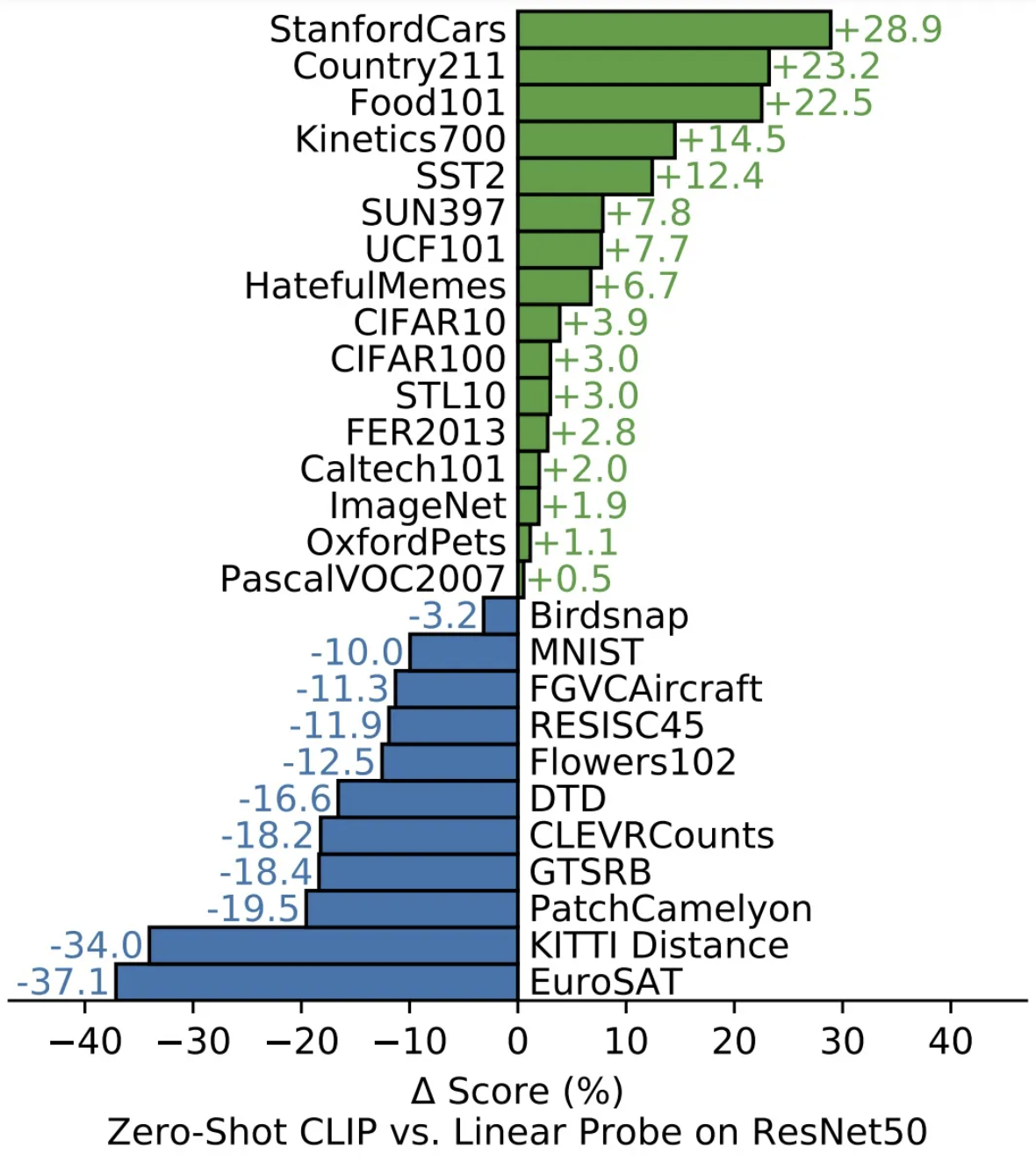
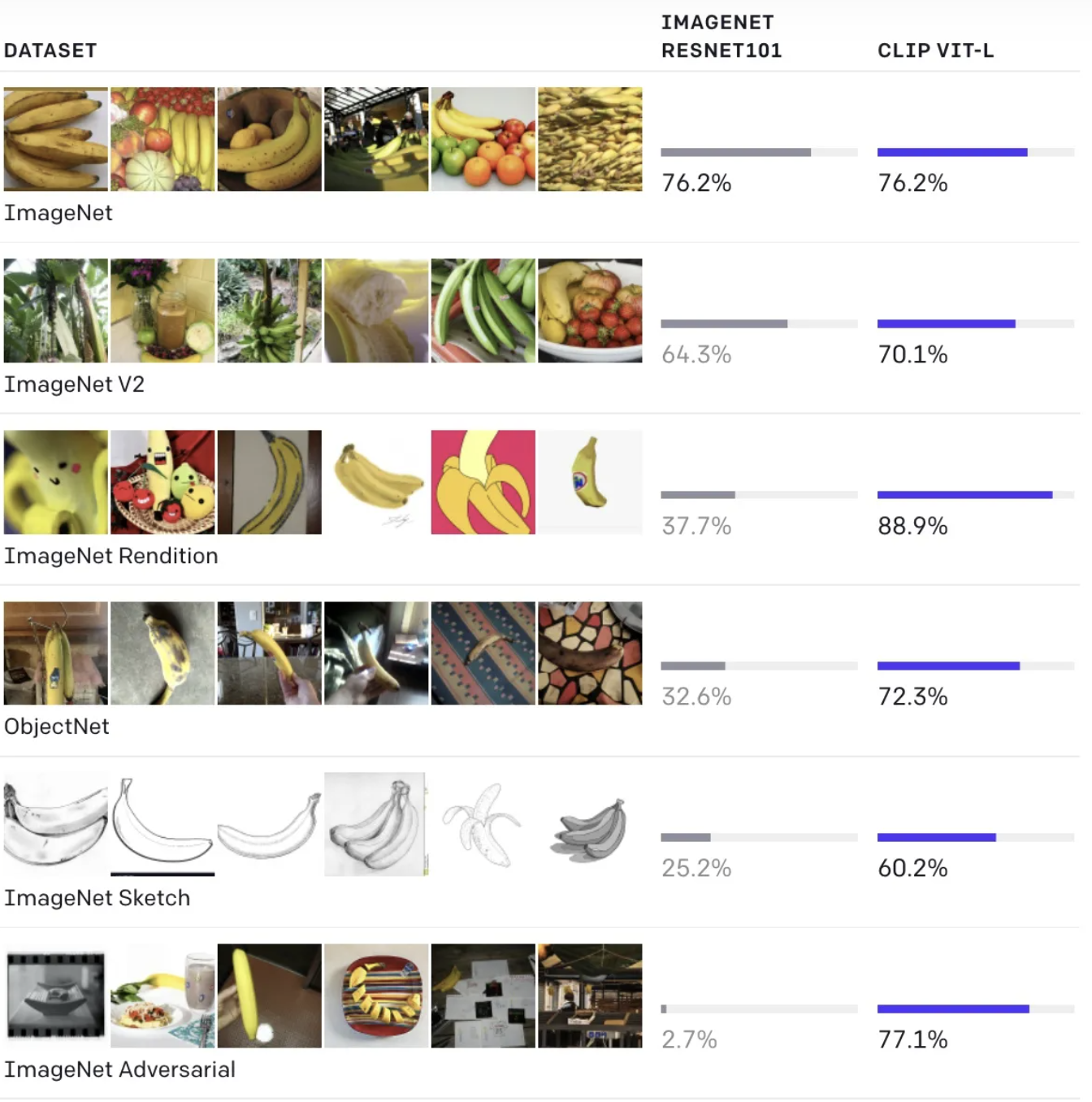
缺点
因为CLIP采用了大量的数据集以及复杂的视觉结构使得它需要消耗恐怖的计算资源。同时对于训练集外的数据,无法做到很好的预测。

