
- 1代理模式(Proxy Pattern) -(最通俗易懂的案例)_代理模式的典型例子
- 2Tokenizer使用(以BertTokenizer为例)_berttokenizer分词器
- 3移动端 图片上传 ajax,移动端图片裁剪上传插件 Mavatar.js(原创)
- 4二分查找(代码随想录刷题)_代码随想录 二分查找
- 5Dubbo3应用开发—Dubbo3注册中心(zookeeper、nacos、consul)的使用_dubbo 3.0后还需要注册中心吗
- 6python 获取github某仓库的 release的最新版本信息_gitlab python 获取项目的最新版本号
- 7kali php服务器,在云服务器上搭建公网kali linux2.0
- 8Java栈的压入、弹出序列(详解)_java压栈和弹栈原理
- 9海思QT开发系列(四):Hi3559 Qt+OpenGL移植_hisi3559 opengl
- 10用1片3-8译码器74LS138和必要的门电路设计一个多输出的组合电路. 要求写出设计过程, 画出连线图. 输出的逻辑函数为: Y1(A,B)=∑m(0,3), Y2(A,B)=∑m(1,2,3)_用74ls138设计多输出组合逻辑电路
【全面认知YOLO系列】第一部分:YOLO系列模型发展史_yolox模型是哪年诞生的
赞
踩
【全面认知YOLO系列】YOLO系列模型发展史
名字由来
2015年,Joseph Redmon、Santosh Divvala、Ross Girshick等人提出了一种单阶段(one-stage)的目标检测网络。该网络模型以每秒 45 帧的速度实时处理图像。该网络的较小版本每秒处理速度高达 155 帧。由于其速度之快和其使用的特殊方法,作者将其取名为:You Only Look Once,也即YOLO。
这也是YOLO系列的开山之作,论文原名叫《You Only Look Once: Unified, Real-Time Object Detection》,其早在2015年6月8日便提交了该论文的V1版本,因此YOLO的提出并不是很多其他文章中说的2016年,而应该是2015年。2016年是论文V5版本发布的时间,该版本论文也是最终版,即我们现在所看到的版本。
YOLO系列模型特点
YOLO系列模型主要特点就是快、快、快,除了快还是快。这也为YOLO模型限定了应用场景,在很多对实时性要求高的场景下,显然YOLO系列模型是一个十分不错的选择。
但是鱼与熊掌不可兼得,模型的速度与性能,也是两个难以同时兼顾的目标。YOLO模型很快,但是相对于很多two-stage模型来说,其性能就会差一些,自然在对模型性能要求极高的场景中,YOLO模型就不一定适合了;同样在很多实时性要求高的场景中,two-stage模型也不一定适合。
YOLO模型的发展
1、YOLO模型时间线
截至2023年5月,已经诞生了许多版本的YOLO,包括YOLO V1、YOLO9000 V2、YOLO V3、YOLO V4、Scaled YOLO V4、PP-YOLO、YOLO V5、YOLO V6、YOLOX、YOLOR、PP-YOLO V2、DAMO YOLO、PP-YOLOE、YOLO V7、YOLO V6、YOLO V8、YOLO-NAS。模型进化时间线如下图所示:
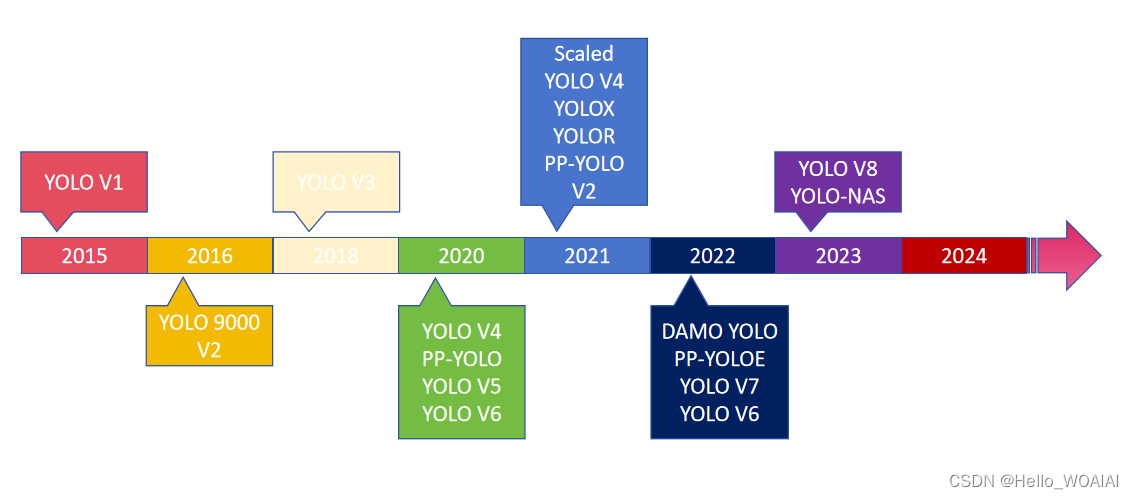
当然YOLO远不止我上文所列举的模型,还有许许多多的各种各样的变体,但是如果读者能够将我上文中列举的模型完全摸熟,在生产中也几乎完全够用了。下文中,我将对YOLO中一些常见的模型进行简要的介绍,在本系列后续文章中,还会利用TensorFlow和Pytorch对模型进行一一实现,欢迎感兴趣的朋友持续关注。
2、YOLO V1模型简介
YOLO V1(You Only Look Once version 1)是YOLO系列模型的第一个版本,由Joseph Redmon等人于2015年提出。相比于传统的目标检测方法,YOLO V1采用了全新的设计思路和网络结构,实现了端到端的目标检测,具有较高的检测速度和简单的设计。
YOLO V1模型论文可在如下网址查看:《You Only Look Once: Unified, Real-Time Object Detection》
2.1、YOLO V1模型的简要介绍
-
网络结构:YOLO V1模型采用卷积神经网络(CNN)作为基础网络结构,在输入图像上进行卷积操作,提取图像特征。
-
单次预测:与传统目标检测方法不同,YOLO V1模型将目标检测任务视为一个回归问题,通过单个神经网络模型直接在整个图像上进行预测。这意味着模型一次性产生图像中所有目标的位置和类别预测。
-
网格划分:YOLO V1将输入图像划分为固定大小的网格,并为每个网格单元预测边界框和类别置信度。
-
特征融合:YOLO V1模型采用多层卷积操作,在不同层次的特征图上进行目标检测,从而实现对不同尺度目标的检测。
-
损失函数:YOLO V1模型使用多任务损失函数,包括边界框坐标损失、目标类别损失和置信度损失,综合考虑了目标定位和分类的准确性。
-
训练与调优:YOLO V1模型采用随机梯度下降(SGD)等优化算法进行训练,通过在大规模数据集上进行反向传播和参数更新,优化模型参数。
-
速度与准确性权衡:YOLO V1模型通过牺牲一定的检测准确性,换取更快的检测速度,适用于实时目标检测等应用场景。
3、YOLO V2模型简介
YOLOv2(You Only Look Once version 2)是YOLO系列模型的第二个版本,于2016年由Joseph Redmon等人提出。YOLOv2相比于YOLOv1在多个方面进行了优化和改进,提高了目标检测的准确性和性能。
YOLOv2模型论文地址:《YOLO9000: Better, Faster, Stronger》
3.1、YOLOv2模型的简要介绍以及相对于YOLOv1的优化改进
-
网络结构优化:YOLOv2采用了更深、更宽的网络结构,引入了残差连接(Residual connections)和批归一化(Batch Normalization)等技术,提高了网络的学习能力和稳定性。
-
多尺度预测:YOLOv2在网络中引入了多尺度预测机制,通过在不同层次的特征图上进行目标检测,提高了对不同尺度目标的检测能力。
-
Anchor boxes:YOLOv2引入了Anchor boxes的概念,用于预测不同尺度和长宽比的目标边界框,提高了模型对目标形状和尺寸的适应性。
-
Darknet-19:YOLOv2使用了一种名为Darknet-19的网络结构,相比于YOLOv1的网络结构更加轻量化,减少了模型参数数量和计算量,提高了模型的训练和推理效率。
-
Batch normalization:YOLOv2在网络中增加了批归一化层,有助于加速收敛速度和提高模型的泛化能力。
-
调整损失函数:YOLOv2对损失函数进行了优化调整,加入了适应权重的损失函数,使得模型更加关注难以训练的样本,提高了检测准确性。
-
训练策略改进:YOLOv2采用了更多的数据增强技术和更长的训练时间,提高了模型的泛化能力和稳定性。
综上所述,相较于YOLOv1,YOLOv2在网络结构、预测机制、损失函数、训练策略等方面进行了优化和改进,提高了目标检测的准确性和性能。
4、YOLO V3模型简介
YOLOv3(You Only Look Once version 3)是YOLO系列模型的第三个版本,由Joseph Redmon等人于2018年提出。YOLOv3相比于YOLOv2在多个方面进行了优化和改进,进一步提高了目标检测的准确性和性能。
YOLOv3论文地址:《YOLOv3: An Incremental Improvement》
4.1、YOLOv3模型的简要介绍以及相对于YOLOv2的优化改进
-
网络结构改进:YOLOv3采用了更深、更宽的网络结构,包括53个卷积层,使得模型能够更好地学习和提取图像特征。
-
多尺度预测:YOLOv3引入了三种不同尺度的预测,分别在不同层次的特征图上进行目标检测,提高了对不同尺度目标的检测能力。
-
Feature Pyramid Network(FPN):YOLOv3中引入了FPN结构,可以在不同层次的特征图上获取丰富的语义信息,有助于提高目标检测的准确性。
-
更多的Anchor boxes:YOLOv3使用了更多、更合适的Anchor boxes,提高了模型对不同尺度和长宽比目标的检测能力。
-
跨层连接:YOLOv3引入了跨层连接机制,使得低层特征图可以获取高层特征图的语义信息,有助于提高对小目标的检测能力。
-
预训练策略改进:YOLOv3采用了更多的数据增强技术和更长的预训练时间,提高了模型的泛化能力和稳定性。
-
后处理优化:YOLOv3对非极大值抑制(NMS)算法进行了优化,提高了目标检测的精度和效率。
-
改进的损失函数:YOLOv3对损失函数进行了优化调整,加入了对不同尺度目标的权重调整,提高了检测准确性。
综上所述,相较于YOLOv2,YOLOv3在网络结构、预测机制、特征融合、损失函数等方面进行了优化和改进,进一步提高了目标检测的准确性和性能。
5、YOLO V4模型简介
YOLOv4(You Only Look Once version 4)是YOLO系列模型的第四个版本,是由Alexey Bochkovskiy等人于2020年发布的。YOLOv4相较于YOLOv3在多个方面进行了改进和优化,以进一步提高目标检测的准确性和性能。
YOLOv4模型论文地址:《YOLOv4: Optimal Speed and Accuracy of Object Detection》
5.1、YOLOv4模型的简要介绍以及相对于YOLOv3的优化改进
-
网络结构改进:YOLOv4采用了更深、更宽的网络结构,引入了CSPDarknet53作为骨干网络,使得模型能够更好地学习和提取图像特征。
-
Backbone网络优化:YOLOv4中采用了Cross Stage Partial Network(CSPNet)和Spatial Pyramid Pooling(SPP)等技术来优化骨干网络的结构,提高了特征提取的效率和质量。
-
加强的数据增强策略:YOLOv4采用了更加强大的数据增强策略,包括CutMix和Mosaic等技术,提高了模型对复杂场景和遮挡目标的识别能力。
-
Mish激活函数:YOLOv4采用了Mish激活函数替代了传统的ReLU激活函数,提高了模型的非线性拟合能力,加速模型收敛。
-
Bag of Freebies和Bag of Specials:YOLOv4引入了Bag of Freebies和Bag of Specials两个概念,分别用于优化训练过程和模型结构,提高了模型的性能和稳定性。
-
更强的模型鲁棒性:YOLOv4在模型训练和调优过程中引入了更多的正则化技术,如DropBlock和DropPath等,提高了模型的泛化能力和鲁棒性。
-
优化的训练策略:YOLOv4采用了更长的训练时间和更大的批量大小,优化了模型的训练策略,提高了模型在目标检测任务上的性能。
综上所述,相较于YOLOv3,YOLOv4在网络结构、数据增强、激活函数、正则化技术等方面进行了优化和改进,进一步提高了目标检测的准确性和性能。
6、YOLO V5模型简介
YOLOv5是YOLO系列模型的第五个版本,是由Ultralytics团队于2020年发布的。相对于YOLOv4,YOLOv5在模型架构和训练策略上进行了优化和改进,以提高目标检测的准确性和效率。
YOLOv5模型论文地址:《YOLOv5: A Unified Framework for Object Detection》
6.1、YOLOv5模型的简要介绍以及相对于YOLOv4的优化改进
-
轻量化模型结构:YOLOv5采用了轻量级的模型结构,包括S、M、L、X四个版本,分别对应不同的模型大小和计算资源需求,使得模型更加灵活和易于部署。
-
模型结构改进:YOLOv5引入了Cross Stage Partial Network(CSP)和Scaled-YOLOv4等技术,优化了模型的网络结构和特征提取能力,提高了目标检测的准确性。
-
数据增强和训练策略:YOLOv5采用了更加强大的数据增强策略,包括CutMix、MixUp等技术,同时优化了训练策略,提高了模型的泛化能力和稳定性。
-
自动混合精度训练:YOLOv5采用了自动混合精度训练技术,通过混合精度计算和参数更新,提高了模型的训练速度和效率。
-
模型部署和推理优化:YOLOv5引入了一键部署和ONNX模型导出等技术,使得模型的部署和推理更加简单和高效。
-
集成学习:YOLOv5采用了集成学习技术,将多个训练好的模型进行集成,提高了模型的鲁棒性和泛化能力。
综上所述,相较于YOLOv4,YOLOv5在模型结构、数据增强、训练策略、模型部署和推理优化等方面进行了优化和改进,进一步提高了目标检测的准确性和效率。
7、YOLOx模型简介
YOLOX发布于2021年,YOLOX是一种轻量级目标检测模型,于2021年由华为诺亚方舟实验室发布。YOLOX旨在提供高性能的目标检测,同时具有更小的模型体积和更快的推理速度。
YOLOx并未发布相关论文,其详细资料,可以参考如下网址:https://github.com/Megvii-BaseDetection/YOLOX
(备注:在YOLOv5之后,美团也发布了YOLO相关的模型,名为MT-YOLOv6,论文地址为:YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
7.1、YOLOX模型的一些主要特点和优化改进
-
骨干网络改进:YOLOX采用了YOLOPaddle作为骨干网络,这是一种全新的轻量级网络结构,具有更好的特征提取能力和更小的模型体积。
-
跨阶段特征融合:引入了跨阶段特征融合(Cross-Stage Partial Connection,CSPC)机制,有助于提高网络的特征融合效率和目标检测的性能。
-
数据增强和训练策略:采用了一系列先进的数据增强技术,如MixUp、CutMix等,同时优化了训练策略,提高了模型的泛化能力和稳定性。
-
动态混合精度训练:引入了动态混合精度训练技术,通过自适应调整精度,提高了模型的训练速度和效率。
-
多尺度预测:在不同尺度的特征图上进行目标检测,有助于提高模型对不同尺度目标的检测能力。
-
高效的模型部署:在模型设计时考虑了部署效率,采用了轻量级的网络结构和高效的推理算法,使得模型在移动端和嵌入式设备上也能够快速运行。
综上所述,YOLOX通过优化骨干网络、特征融合机制、数据增强和训练策略等方面,相较于YOLOv5实现了更高的性能和更小的模型体积。
8、YOLO V7模型简介
YOLOv7发布于2022年,作者与YOLOv4的团队相同,可以认为是YOLO的官方发布。它是在yoloV5的基础上进一步改进而来的。
YOLOv7沦为地址:《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》
8.1、YOLOv7模型相对于YOLOv5的优化改进
- 网络结构:yoloV7采用了更深的网络结构,包含更多的卷积层和残差块,可以提高模型的表达能力和检测精度。
- 数据增强:yoloV7引入了更多的数据增强方法,如随机裁剪、随机旋转等,可以增加训练数据的多样性,提高模型的鲁棒性。
- 激活函数:yoloV7采用了swish激活函数,可以提高模型的非线性表达能力,进一步提高检测精度。
相比于yoloV5,yoloV7在网络结构、数据增强和激活函数等方面都进行了优化,可以提高模型的表达能力和检测精度。
9、YOLO V8模型简介
YOLOv8模型是由Ultralytics团队开发,并未发布对应论文,YOLOv8 支持全方位的视觉 AI 任务,包括检测、分割、姿态估计、跟踪和分类。这种多功能性使用户能够在各种应用和领域中利用YOLOv8 的功能。
YOLOv8对应资料:https://docs.ultralytics.com/zh
9.1、YOLOv8模型改进点
YOLO v8有以下改进点:
- Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
- PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
- Decoupled-Head:是不是嗅到了不一样的味道?是的,YOLOv8走向了Decoupled-Head;
- Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
- 损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;
- 样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。

