
- 1mllib逻辑回归 spark_Spark Mllib中逻辑回归
- 2用python编写飞机3D模型
- 310种混沌映射优化灰狼算法,可一键切换,可用于优化所有群智能算法,以灰狼算法为例进行介绍...
- 4ssh服务配置
- 5【数字IC/FPGA】Verilog中的force和release_verilog force release
- 6五、SpringCloud之Gateway网关整合Eureka_spring cloud gateway eureka
- 7Stacking算法:集成学习的终极武器
- 8git diff 命令6种使用场景
- 9手机电脑投屏软件_5款免费手机投屏软件汇总(手机、电脑、电视)全投屏
- 10YOLOv5-Backbone模块实现_yolov5 1backbone
核密度估计(KDE)原理及实现
赞
踩
参数估计指样本数据来自一个具有明确概率密度函数的总体,而在非参数估计中,样本数据的概率分布未知,这时,为了对样本数据进行建模,需要估计样本数据的概率密度函数,核密度估计即是其中一种方式。
引言
统计学中,核密度估计,即Kernel Density Estimation,用以基于有限的样本推断总体数据的分布,因此,核密度估计的结果即为样本的概率密度函数估计,根据该估计的概率密度函数,我们就可以得到数据分布的一些性质,如数据的聚集区域。
从直方图开始
直方图由 Karl Pearson 提出,用以表示样本数据的分布,帮助分析样本数据的众数、中位数等性质,横轴表示变量的取值区间,纵轴表示在该区间内数据出现的频次与区间的长度的比例。
美国人口普查局(The U.S. Census Bureau)调查了 12.4 亿人的上班通勤时间,数据如下:
| 起点 | 组距 | 频次 | 频次/组距 | 频次/组距/总数 |
|---|---|---|---|---|
| 0 | 5 | 4180 | 836 | 0.0067 |
| 5 | 5 | 13687 | 2737 | 0.0221 |
| 10 | 5 | 18618 | 3723 | 0.03 |
| 15 | 5 | 19634 | 3926 | 0.0316 |
| 20 | 5 | 17981 | 3596 | 0.029 |
| 25 | 5 | 7190 | 1438 | 0.0116 |
| 30 | 5 | 16369 | 3273 | 0.0264 |
| 35 | 5 | 3212 | 642 | 0.0052 |
| 40 | 5 | 4122 | 824 | 0.0066 |
| 45 | 15 | 9200 | 613 | 0.0049 |
| 60 | 30 | 6461 | 215 | 0.0017 |
| 90 | 60 | 3435 | 57 | 0.0005 |
使用直方图进行数据可视化如下:
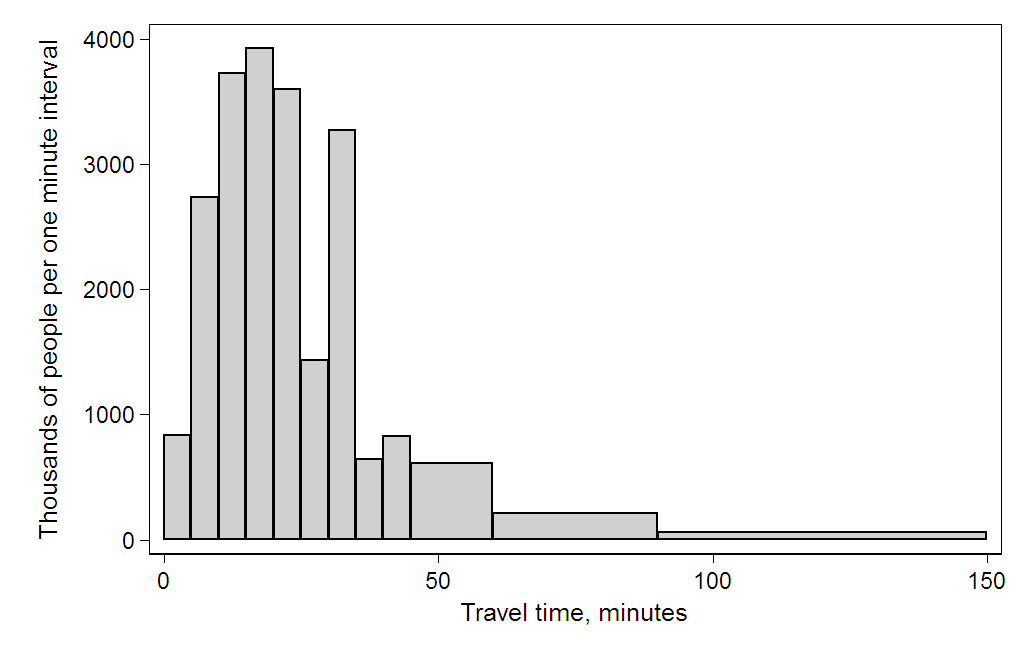
该直方图使用单位间隔的人数(频次/组距)表示为每个矩形的高度,因此每个矩形的面积表示该区间内的人数,矩形的总面积即为 12.4 亿。
而当直方图使用(频次/组距/总数)表示为每个矩形的高度时,数据可视化如下:
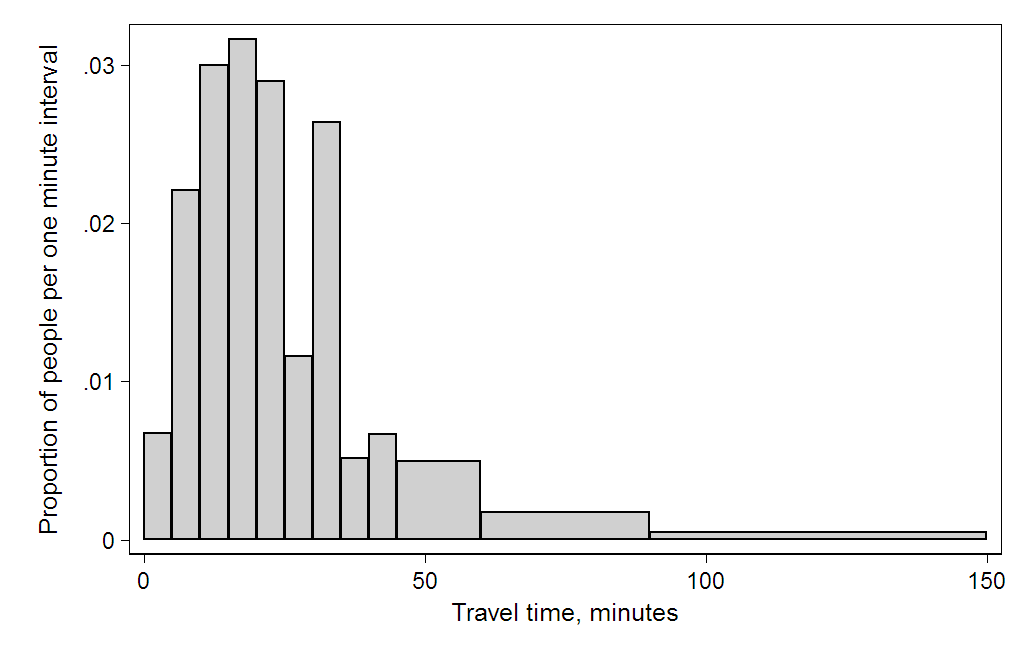
此时,矩形的面积表示该区间所占的频率,矩形的总面积为 1,该直方图也即频率直方图。
频率直方图有以下特点:
- 矩形面积为该区间的频率;
- 矩形的高度为该区间的平均频率密度。
概率密度函数
极限思维:我们使用微分思想,将频率直方图的组距一步步减小,随着组距的减小,矩形宽度越来越小,因此,在极限情况下频率直方图就会变成一条曲线,而这条曲线即为概率密度曲线。
对于概率密度曲线,我们知道:随机变量的取值落在某区域内的概率值为概率密度函数在这个区域的积分(见概率密度函数),即: P ( a < x ≤ b ) = ∫ a b f ( x ) d x P(a< x \leq b) = \int\limits_a^b f(x)dx P(a<x≤b)=a∫bf(x)dx。
设累积分布函数为 F ( x ) F(x) F(x),根据上述定义,则 F ( x ) = ∫ − ∞ x f ( x ) d x F(x) = \int\limits_{-\infty}^x f(x)dx F(x)=−∞∫xf(x)dx。
根据微分思想,则有:
f
(
x
0
)
=
F
(
x
0
)
˙
=
lim
h
→
0
F
(
x
0
+
h
)
−
F
(
x
0
−
h
)
2
h
核密度估计
根据上述分析,我们应该已经明白核密度估计的目的事实上就是估测所给样本数据的概率密度函数。
公式推导
考虑一维数据,有如下 n n n 个样本数据: x 1 , x 2 , x 3 , . . . , x n x_1,x_2,x_3,...,x_n x1,x2,x3,...,xn。
假设该样本数据的累积分布函数为 F ( x ) F(x) F(x),概率密度函数为 f ( x ) f(x) f(x),则有:
F ( x i − 1 < x < x i ) = ∫ x i − 1 x i f ( x ) d x F(x_{i-1} < x < x_i) = \int\limits_{x_{i-1}}^{x_i} f(x)dx F(xi−1<x<xi)=xi−1∫xif(x)dx
f ( x i ) = lim h → 0 F ( x i + h ) − F ( x i − h ) 2 h f(x_i) = \lim^{}_{h \to 0}\frac{F(x_i+h)-F(x_i-h)}{2h} f(xi)=h→0lim2hF(xi+h)−F(xi−h)
引入累积分布函数的经验分布函数:
F n ( t ) = 1 n ∑ i = 1 n 1 x i ≤ t F_n(t) = \frac{1}{n}\sum^{n}_{i=1}1_{x_i \leq t} Fn(t)=n1i=1∑n1xi≤t
该函数大意为:使用 n n n 次观测中 x i ≤ t x_i \leq t xi≤t 出现的次数与 n n n 的比值来近似描述 P ( x ≤ t ) P(x \leq t) P(x≤t)。
将该函数代入 f ( x i ) f(x_i) f(xi),有:
f ( x i ) = lim h → 0 1 2 n h ∑ i = 1 n 1 x i − h ≤ x j ≤ x i + h f(x_i) = \lim^{}_{h \to 0}\frac{1}{2nh}\sum^{n}_{i=1}1_{x_i-h \leq x_j \leq x_i+h} f(xi)=h→0lim2nh1i=1∑n1xi−h≤xj≤xi+h
根据该公式,在实际计算中,必须给定 h h h 值, h h h 值不能太大也不能太小,太大不满足 h → 0 h \to 0 h→0 的条件,太小使用的样本数据点太少,误差会很大,因此,关于 h h h 值的选择有很多研究,该值也被称为核密度估计中的带宽。
确定带宽后,我们可以写出 f ( x ) f(x) f(x) 的表达式:
f ( x ) = 1 2 n h ∑ i = 1 n 1 x − h ≤ x i ≤ x + h f(x) = \frac{1}{2nh}\sum^{n}_{i=1}1_{x-h \leq x_i \leq x+h} f(x)=2nh1i=1∑n1x−h≤xi≤x+h
核函数
f ( x ) f(x) f(x) 表达式可变形为:
f
(
x
)
=
1
2
n
h
∑
i
=
1
n
1
x
−
h
≤
x
i
≤
x
+
h
=
1
2
n
h
∑
i
=
1
n
K
(
∣
x
−
x
i
∣
h
)
其中,令 t = ∥ x − x i ∥ h t = \frac{\|x-x_i\|}{h} t=h∥x−xi∥,则当 0 ≤ t ≤ 1 0 \leq t \leq 1 0≤t≤1 时, K ( t ) = 1 K(t) = 1 K(t)=1.
且:
∫
f
(
x
)
d
x
=
∫
1
2
n
h
∑
i
=
1
n
K
(
∣
x
−
x
i
∣
h
)
d
x
=
∫
1
2
n
∑
i
=
1
n
K
(
t
)
d
t
=
∫
1
2
K
(
t
)
d
t
注意,此处的 ∑ i = 1 n \sum^{n}_{i=1} ∑i=1n 指的是 n n n 次实验,而不是累计,因此计算值为 n n n。
令 K 0 ( t ) = 1 2 K ( t ) K_0(t) = \frac{1}{2} K(t) K0(t)=21K(t),根据概率密度函数的定义,我们有:
∫ K 0 ( t ) d t = 1 \int K_0(t)dt = 1 ∫K0(t)dt=1
其中当 0 ≤ t ≤ 1 0 \leq t \leq 1 0≤t≤1 时, K 0 ( t ) = 1 2 K_0(t) = \frac{1}{2} K0(t)=21.
此时 K 0 ( t ) K_0(t) K0(t) 就称为核函数,常用的核函数有:uniform,triangular, biweight, triweight, Epanechnikov, normal…。
f ( x ) f(x) f(x) 的表达式变为:
f ( x ) = 1 n h ∑ i = 1 n K 0 ( ∣ x − x i ∣ h ) f(x) = \frac{1}{nh}\sum^{n}_{i=1}K_0(\frac{|x-x_i|}{h}) f(x)=nh1i=1∑nK0(h∣x−xi∣)
对于二维数据, f ( x ) f(x) f(x) 为:
f ( x , y ) = 1 n h 2 ∑ i = 1 n K 0 ( d i s t ( ( x , y ) , ( x i , y i ) ) h ) f(x, y) = \frac{1}{nh^2}\sum^{n}_{i=1}K_0(\frac{dist((x, y), (x_i, y_i))}{h}) f(x,y)=nh21i=1∑nK0(hdist((x,y),(xi,yi)))
实验:POI 点核密度分析
技术选型
- 栅格数据可视化:canvas
- KFC POI 爬取:POIKit
核函数、带宽选择
使用 ArcGIS 软件说明文档提供的带宽选择方案,核函数为:
K 0 ( t ) = 3 π ( 1 − t 2 ) 2 K_0(t) = \frac{3}{\pi}(1-t^2)^2 K0(t)=π3(1−t2)2
概率密度估测函数为:
f
(
x
,
y
)
=
1
n
∗
h
2
∑
i
=
1
n
p
o
p
i
K
0
(
d
i
s
t
i
h
)
f(x, y) = \frac{1}{n*h^2}\sum_{i=1}^n pop_i K_0(\frac{dist_i}{h})
f(x,y)=n∗h21i=1∑npopiK0(hdisti)
其中, p o p i pop_i popi 为给定的权重字段,若不含有该字段,则取值为 1, n n n 为 POI 点个数。
带宽为:
h = 0.9 ∗ m i n ( A , 1 ln ( 2 ) ∗ D m ) ∗ n − 0.2 h = 0.9*min(A,\sqrt{\frac{1}{\ln(2)}}*D_m)*n^{-0.2} h=0.9∗min(A,ln(2)1 ∗Dm)∗n−0.2
参数解释:
-
平均中心:指 n n n 个 POI 点的平均中心,即经度和纬度分别取平均;
-
加权平均中心:指 n n n 个 POI 点的加权平均中心,即经度和纬度分别乘以权重再取平均;
-
标准距离计算公式:
S D = ∑ i = 1 n ( x i − X ˉ ) 2 n + ∑ i = 1 n ( y i − Y ˉ ) 2 n + ∑ i = 1 n ( z i − Z ˉ ) 2 n SD = \sqrt{\frac{\sum_{i=1}^n(x_i-\bar X)^2}{n}+\frac{\sum_{i=1}^n(y_i-\bar Y)^2}{n}+\frac{\sum_{i=1}^n(z_i-\bar Z)^2}{n}} SD=n∑i=1n(xi−Xˉ)2+n∑i=1n(yi−Yˉ)2+n∑i=1n(zi−Zˉ)2
其中:
- x i , y i , z i x_i,y_i,z_i xi,yi,zi 是 POI 的坐标
- X ˉ , Y ˉ , Z ˉ {\bar X,\bar Y, \bar Z} Xˉ,Yˉ,Zˉ 表示平均中心
- n n n 是 POI 总数
-
加权标准距离计算公式:
S D w = ∑ i = 1 n w i ( x i − X ˉ w ) 2 ∑ i = 1 n w i + ∑ i = 1 n w i ( y i − Y ˉ w ) 2 ∑ i = 1 n w i + ∑ i = 1 n w i ( z i − Z ˉ w ) 2 ∑ i = 1 n w i SD_w = \sqrt{\frac{\sum_{i=1}^n w_i(x_i-\bar X_w)^2}{\sum_{i=1}^{n}w_i}+\frac{\sum_{i=1}^nw_i(y_i-\bar Y_w)^2}{\sum_{i=1}^{n}w_i}+\frac{\sum_{i=1}^nw_i(z_i-\bar Z_w)^2}{\sum_{i=1}^{n}w_i}} SDw=∑i=1nwi∑i=1nwi(xi−Xˉw)2+∑i=1nwi∑i=1nwi(yi−Yˉw)2+∑i=1nwi∑i=1nwi(zi−Zˉw)2
其中:
- w i w_i wi 是要素 i i i 的权重
- X ˉ w , Y ˉ w , Z ˉ w {\bar X_w,\bar Y_w, \bar Z_w} Xˉw,Yˉw,Zˉw 表示加权平均中心
- n n n 是 POI 总数
-
若 POI 点不含有权重字段,则 D m D_m Dm 为到平均中心距离的中值, n n n 是 POI 点数目, A A A 是标准距离 S D SD SD;
-
若 POI 点含有权重字段,则 D m D_m Dm 为到加权平均中心距离的中值, n n n 是 POI 点权重字段值的总和, A A A 是加权标准距离 S D w SD_w SDw。
数据爬取
使用 POIKit,爬取河南省 KFC POI 数据,参数设置如下:
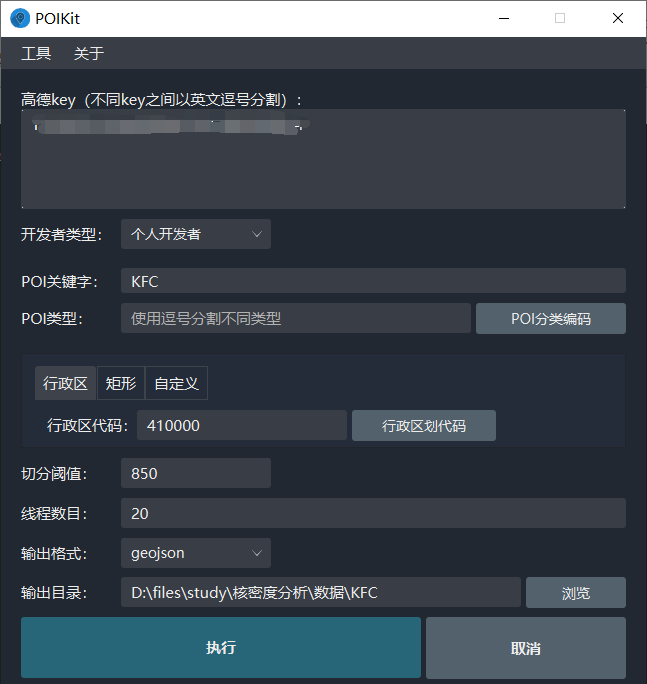
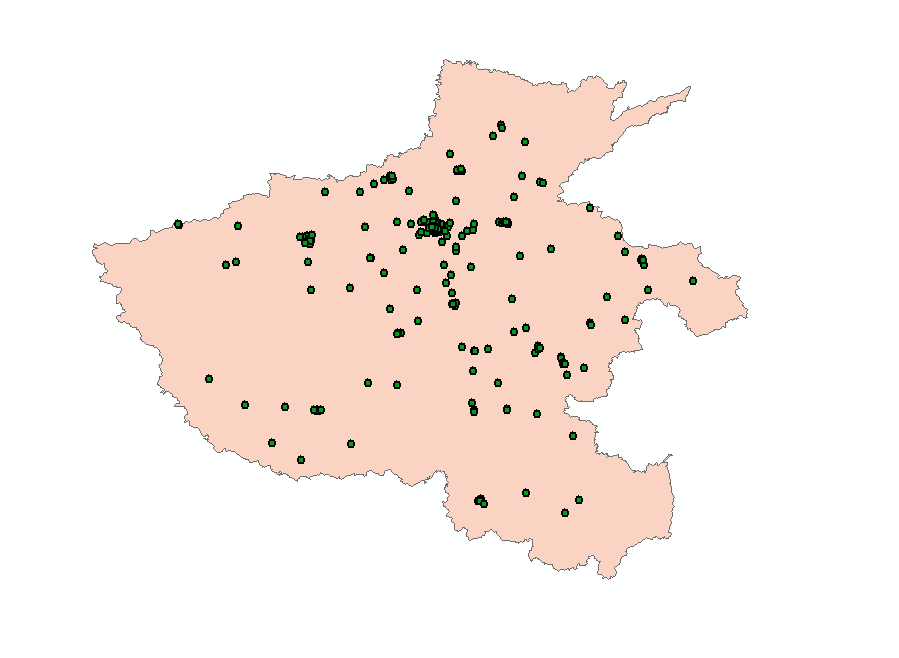
共爬取得到 219 条数据,如下图所示:
程序编写
核函数:
/**
* 核函数
* @param {Number} t 变量
* @returns
*/
function kernel(t) {
return (3 / Math.PI) * Math.pow(1 - t * t, 2);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
带宽:
/**
* 带宽
* @param {Point[]} pts 所有POI点
* @param {Point} avePt 平均中心
* @returns
*/
function h(pts, avePt) {
const SD_ = SD(pts, avePt);
const Dm_ = Dm(pts, avePt);
if (SD_ > Math.sqrt(1 / Math.log(2)) * Dm_) {
return 0.9 * Math.sqrt(1 / Math.log(2)) * Dm_ * Math.pow(pts.length, -0.2);
} else {
return 0.9 * SD_ * Math.pow(pts.length, -0.2);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
平均中心:
/**
* 平均中心
* @param {Point} pts 所有POI点
* @returns
*/
function ave(pts) {
let lon = 0,
lat = 0;
pts.forEach((pt) => {
lon += pt.lon;
lat += pt.lat;
});
return new Point(lon / pts.length, lat / pts.length);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
标准距离 SD:
/**
* 标准距离
* @param {Point[]} pts 所有POI点
* @param {Point} avePt 平均中心
* @returns
*/
function SD(pts, avePt) {
let SDx = 0,
SDy = 0;
pts.forEach((pt) => {
SDx += Math.pow(pt.lon - avePt.lon, 2);
SDy += Math.pow(pt.lat - avePt.lat, 2);
});
return Math.sqrt(SDx / pts.length + SDy / pts.length);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Dm(到平均中心距离的中值):
/**
* Dm
* @param {Point[]}} pts 所有POI点
* @param {Point} avePt 平均中心
* @returns
*/
function Dm(pts, avePt) {
let distance = [];
pts.forEach((pt) => {
distance.push(Dist(pt, avePt));
});
distance.sort();
return distance[distance.length / 2];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
核密度估计:
/**
* 核密度估计
* @param {Point[]} pts 所有POI点
* @param {Rect} rect POI点边界
* @param {Number} width 栅格图像宽度
* @param {Number} height 栅格图像高度
*/
function kde(pts, rect, width, height) {
const estimate = new Array(height)
.fill(0)
.map(() => new Array(width).fill(0));
let min = Infinity,
max = -Infinity;
const avePt = ave(pts);
const bandWidth = h(pts, avePt);
rect.top += bandWidth;
rect.bottom -= bandWidth;
rect.left -= bandWidth;
rect.right += bandWidth;
const itemW = (rect.right - rect.left) / width;
const itemH = (rect.top - rect.bottom) / height;
for (let x = 0; x < width; x++) {
const itemX = rect.left + itemW * x;
for (let y = 0; y < height; y++) {
const itemY = rect.bottom + itemH * y;
let fEstimate = 0;
for (let m = 0; m < pts.length; m++) {
const distance = Dist(pts[m], new Point(itemX, itemY));
if (distance < Math.pow(bandWidth, 2)) {
fEstimate += kernel(distance / bandWidth);
}
}
fEstimate = fEstimate / (pts.length * Math.pow(bandWidth, 2));
min = Math.min(min, fEstimate);
max = Math.max(max, fEstimate);
estimate[height - y - 1][x] = fEstimate;
}
}
return { estimate, min, max };
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
然后使用 html5 canvas 进行可视化:
/**
* 绘制核密度估计结果栅格图
* @param {CanvasRenderingContext2D} ctx canvas上下文
* @param {*} param0 核密度估测值,最大值,最小值
*/
function draw(ctx, { estimate, min, max }) {
const height = estimate.length,
width = estimate[0].length;
for (let x = 0; x < width; x++) {
for (let y = 0; y < height; y++) {
const val = (estimate[y][x] - min) / (max - min);
if (val > 0 && val < 0.4) {
ctx.fillStyle = "rgb(228, 249, 245)";
ctx.fillRect(x, y, 1, 1);
} else if (val >= 0.4 && val < 0.7) {
ctx.fillStyle = "rgb(48, 227, 202)";
ctx.fillRect(x, y, 1, 1);
} else if (val >= 0.7 && val < 0.9) {
ctx.fillStyle = "rgb(17, 153, 158)";
ctx.fillRect(x, y, 1, 1);
} else if (val >= 0.9 && val <= 1) {
ctx.fillStyle = "rgb(64, 81, 78)";
ctx.fillRect(x, y, 1, 1);
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
核密度估计结果
下图是核密度估计结果:

通过该图,可发现核密度估计的结果能很好的展示数据的热点区域。
全部代码
关注微信公众号古月有三木,回复核密度分析即可获取全部代码及数据。


{kind=link}
{kind=link}