
- 1回归模型使用实战xgb.XGBRegressor
- 2大模型接触(一)——模型蒸馏
- 3union查询 如何合成一个新表
- 4DPDK的PMD(uio/igb_uio/vfio-pci/uio_pci_generic)_dpdk pmd
- 5【转】微软研发职位介绍_微软首席研究员什么级别
- 6论文辅助笔记:TEMPO 之 utils.py
- 7人工电销机器人在销售行业中的重要性和作用,以及未来市场的发展前景
- 8【NLP】特征提取: 广泛指南和 3 个操作教程 [Python、CNN、BERT]
- 9vscode获取远程别人的分支_vscode上获取所有分支
- 10RabbitMQ部署指南_linux在线安装rabbitmq3.8
大模型微调LoRA训练与原理_lora训练原理
赞
踩
1.什么是LoRA?
LoRA的全称是LOW-RANK-ADAPTATION。是一种实现迁移学习的技术手段。
2. 矩阵的秩?
秩是一个向量空间的基向量的个数。例如:二维平面坐标系存在两个基向量,平面上任意的一个向量都可以使用这两个基向量进行线性表示,则秩为2。三维空间中则有3个基向量。3维空间存在很多对的基向量,而正交的基向量才是最简单的。秩是矩阵特有的属性。
3. Transforerm中的矩阵有哪些?
很明显最常见的就是Q,V,K这3个矩阵了。在transformer中,一个字母的被embeding之后,又会被Q,K,V这个3个参数矩阵进行映射到D_model的512维度。这里假设输入的序列长度为100,embeding为256,则Q,K,V这3个矩阵的维度都是(256,512)。设矩阵M=(256,512)。则矩阵M的秩是小于或等于256的,如果M是满秩的则说明embeding为256可能是不够的,需要往大了调整。
但是如果矩阵M不是满秩矩阵,则说明embeding为256维度的向量空间是搓搓有余的。如果M的秩为100,则说明任意一个字符的embeding空间向量都可以使用这100个基向量来进行表示。
LoRA就是这么认为的,他直接认为大模型生成的各种向量空间的秩都很低(模型太胖了,容量很大)。
在数学上,这种非满秩矩阵都可以表示成两个矩阵的乘积。举个例子:M=(256,512),假设他的秩是100,那么则有(256,100)*(100,512) = (256,512)。再假设A=(256,100),B=(100,512),也就是矩阵M=A*B,即M可以使用两个矩阵乘积进行表示了。在这里计算一下参数减少量:1-(256*100+100*512)/(256*512)=41%。可以看到使用A*B代表矩阵M直接减少了41%的参数量,简直美滋滋啊。
4. 如何应用LoRA进行模型微调?
模型微调是迁移学习的一张具体应用,而LoRA又是模型微调的一种技术手段。我们一般需要借助的是大模型强大的基础特征提取能力,再这个基础上fit特定领域的数据,也就是我们需要微调的部分。如下图所示,LoRA经常一种bypass的方式加在模型当中,训练时只更新LoRA部分的权重。可以看到大模型的权重是d×d的维度,而LoRA使用(d,r)*(r,d)两个矩阵进行相乘就可以得到d×d,然后两个特征进行相加即可,其中r是超参数,表示左边蓝色W矩阵的秩。
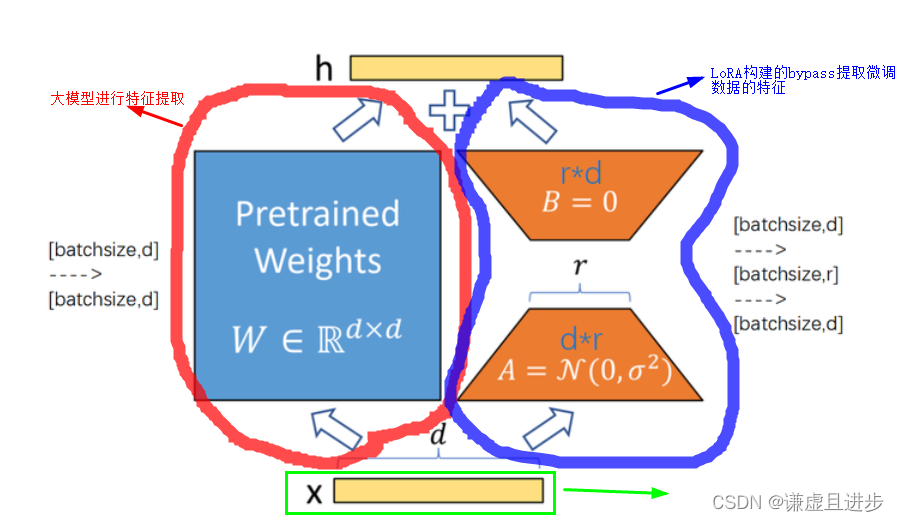
很明显,LoRA适用于模型中网络层体量很大的部分,比如Q,K,V这3个矩阵,即将每个字母的embeding映射到512维空间中是搓搓有余的,实际上可能映射到384维可能就是刚刚好的状态,LoRA就适用于这种映射维度过高的低秩矩阵,使用矩阵相乘的形式显著的降低模型参数数量,而且保持性能不变。

