- 1Android输入法IME(三)之 管理端(IMMS)启动流程
- 2HBase高可用集群踩坑总结以及hbase-site.xml配置文件分享_配置hbase-site.xml出现的问题
- 3数据结构~~排序
- 4从零开始学习CANoe(一)—— 新建工程_canoe新建工程
- 5【计算机视觉 | 图像分割】arxiv 计算机视觉关于图像分割的学术速递(7 月 4 日论文合集)_hrsegnet
- 6FPGA - 4位数值比较器电路
- 7Python 一步一步教你用pyglet制作汉诺塔游戏(终篇)_python汉诺塔
- 8输入十个姓名,按首字母的大小排列顺序!_c 语言 人名按字母排序
- 9毕业设计:基于python动漫数据分析推荐系统+可视化+协同过滤推荐算法 Django框架(源码)✅
- 10前端大文件分片下载解决方案,没用你来砍我
AI Agent概念、能力初探_agent理解规划
赞
踩
AI Agent无疑是大语言模型当前最热门且最具前景的方向,也是通往AGI的必经之路,下面我们从基本概念和系统能力层面来逐步揭开AI Agent的神秘面纱。
一、概念解析
1、什么是AI Agent?
AI Agent(人工智能代理)是一种能够自主理解、规划决策、执行复杂任务的智能体。不同于传统的人工智能,AI Agent具备通过独立思考、调用工具去逐步完成给定目标的能力。比如,告诉AI Agent帮忙下单一份外卖,它就可以直接调用App选择外卖,再调用支付程序下单支付,无需人类去指定每一步的操作。
Agent的概念由明斯基(“AI之父”)在其1986年出版的《思维的社会》一书中提出,明斯基认为社会中的某些个体经过协商之后可求得问题的解,这些个体就是Agent。他还认为Agent应具有社会交互性和智能性。Agent的概念由此被引入人工智能和计算机领域,并迅速成为研究热点。但苦于当时数据和算力限制,想要实现真正智能的AI Agents缺乏必要的现实条件。

近年来,随着大型语言模型(LLMs)的发展,AI Agent的概念框架也在不断演进,包括大脑、感知和行动这三个主要组成部分。这些进展不仅推动了AI Agent在知识获取、指令理解、泛化、规划和推理等方面展现出的强大潜力,也为实现通用人工智能(AGI)提供了新的可能性。
LLM和AI Agent的区别在于AI Agent可以独立思考并做出行动,和RPA(机器人流程自动化,Robotic Process Automation)的区别在于它能够处理未知环境信息。
ChatGPT诞生后,AI从真正意义上具备了和人类进行多轮对话的能力,并且能针对相应问题给出具体回答与建议。随后各个领域的“Copilot”推出,如Microsoft 365 Copilot、GitHub Copilot、Adobe Firefly等,让AI成为了办公、代码、设计等场景的“智能副驾驶”。AI Agent和大模型的区别在于,大模型与人类之间的交互是基于prompt实现的,用户prompt是否清晰明确会影响大模型回答的效果,例如ChatGPT和这些Copilot都需要明确任务才能得到有用的回答。
而AI Agent的工作仅需给定一个目标,它就能够针对目标独立思考并做出行动,它会根据给定任务详细拆解出每一步的计划步骤,依靠来自外界的反馈和自主思考,自己给自己创建prompt,来实现目标。如果说Copilot是“副驾驶”,那么Agent则可以算得上一个初级的“主驾驶”。和传统的RPA相比,RPA只能在给定的情况条件下,根据程序内预设好的流程来进行工作的处理,在出现大量未知信息、难以预测的环境中时,RPA是无法进行工作的,AI Agent则可以通过和环境进行交互,感知信息并做出对应的思考和行动。
2、AI Agent的终极目标:AGI
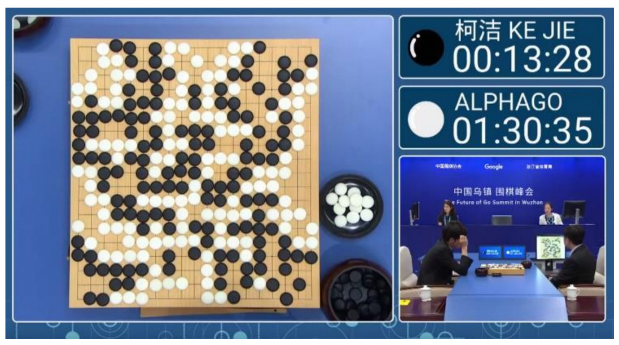
AI Agent并不是一个新兴的概念,早在多年前就已在人工智能领域有了研究。例如2014年由DeepMind推出的引发全球热议的围棋机器人AlphaGo,也可以看做是AI Agent的一种。与之类似的还有2017年Open AI推出的用于玩《Dota2》的OpenAI Five,2019年DeepMind公布用于玩《星际争霸2》的AlphaStar等,这些AI都能根据对实时接收到的信息的分析来安排和规划下一步的操作,均满足AI Agent的基本定义。
当时的业界潮流是通过强化学习的方法来对AI Agent进行训练,主要应用场景是在游戏这类具有对抗性、有明显输赢双方的场景中。但如果想要在真实世界中实现通用性,基于当时的技术水平还难以实现。
大语言模型的浪潮推动了AI Agent相关研究快速发展。AI Agent需要做到能够像人类一样进行交互,大语言模型强大的能力为AI Agent的突破带来了契机。大模型庞大的训练数据集中包含了大量人类行为数据,为模拟类人的交互打下了坚实基础;另一方面,随着模型规模不断增大,大模型涌现出了上下文学习能力、推理能力、思维链等类似人类思考方式的多种能力。将大模型作为AI Agent的核心大脑,就可以实现以往难以实现的将复杂问题拆解成可实现的子任务、类人的自然语言交互等能力。大模型的快速发展大幅推动了AI Agent的发展。
通往AGI的道路仍需探索,AI Agent是当前的主要路线。在大模型浪潮席卷全球之时,很多人认为大模型距离真正的通用人工智能AGI已经非常接近,很多厂商都投入了基础大模型的研究。但经过了一段时间后,大家对大模型真实的能力边界有了清晰的认知,发现大模型仍存在大量的问题如幻觉、上下文容量限制等,导致其无法直接通向AGI,于是AI Agent成为了新的研究方向。
通过让大模型借助一个或多个Agent的能力,构建成为具备自主思考决策和执行能力的智能体,来继续实现通往AGI的道路。Open AI联合创始人Andrej Karpathy在一次开发者活动中讲到,Open AI内部对AI Agents非常感兴趣,AI Agent将是未来AI的前沿方向。

AI Agent可以类比为自动驾驶的L4阶段,距离真正实现仍有差距。根据甲子光年报告,AI与人类的协作程度可以和自动驾驶等级进行类比。像ChatGPT这类对话机器人可以类比L2级别自动驾驶,人类可以向AI寻求意见,但AI不直接参与工作;Copilot这类副驾驶工具可以类比为L3级别的自动驾驶,人类和AI共同协作完成工作,AI根据prompt生成初稿,人类仅需进行修改调整;而Agent则进一步升级为L4,人类给定一个目标,Agent可以自己完成任务规划、工具调用等。但就如同L4级别的自动驾驶还未真正实现一样,AI Agents容易想象和演示,却难以实现,AI Agents的真正应用还在不确定的未来。

二、能力拆解
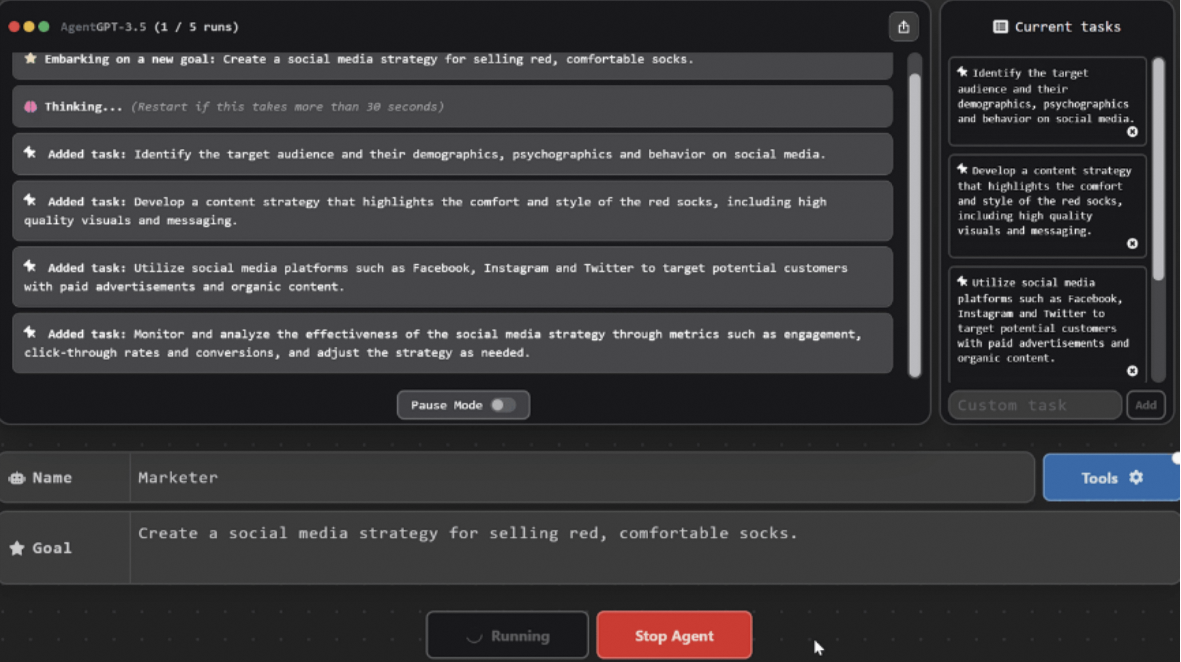
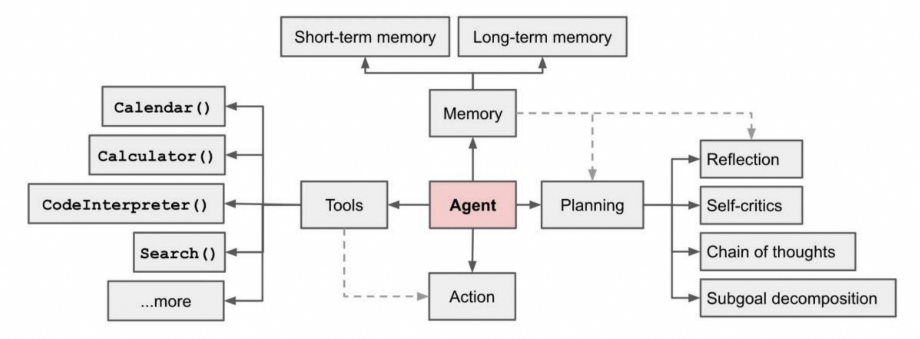
一个基于大模型的AI Agent系统可以拆分为大模型、规划、记忆与工具使用四个组件部分。2023年6月,Open AI的应用研究主管Lilian Weng撰写了一篇博客,认为AI Agent可能会成为新时代的开端。她提出了Agent=LLM+规划技能+记忆+工具使用的基础架构,其中LLM扮演了Agent的“大脑”,在这个系统中提供推理、规划等能力。
1、规划(Planning):通过Cot实现任务类型分解
LLM具备逻辑推理能力,Agent可以将LLM的逻辑推理能力激发出来。当模型规模足够大的时候,LLM本身是具备推理能力的。在简单推理问题上,LLM已经达到了很好的能力;但在复杂推理问题上,LLM有时还是会出现错误。
事实上,很多时候用户无法通过LLM获得理想的回答,原因在于prompt不够合适,无法激发LLM本身的推理能力,通过追加辅助推理的prompt,可以大幅提升LLM的推理效果。在《Large language models are zero-shot reasoners》这篇论文的测试中,在向LLM提问的时候追加“Let’s think step by step”后,在数学推理测试集GSM8K上的推理准确率从10.4%提升到了40.7%。而Agent作为智能体代理,能够根据给定的目标自己创建合适的prompt,可以更好地激发大模型的推理能力。
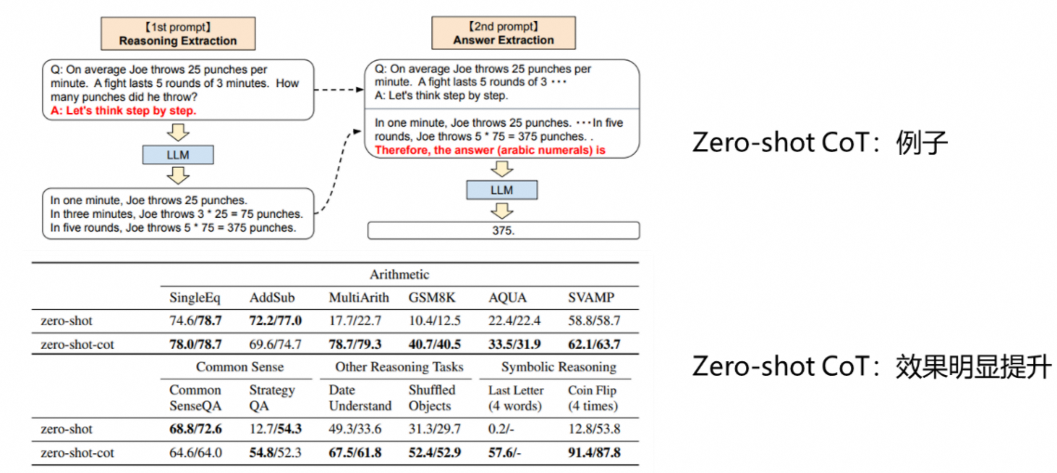
对于需要更多步骤的复杂任务,Agent能够调用LLM通过思维链能力实现任务分解与规划。在AI Agent的架构中,任务分解规划的过程是基于大模型的能力来实现的。大模型具备思维链(Chain of Thoughts,CoT)能力,通过提示模型“逐步思考”,利用更多的计算时间来将困难任务分解为更小,更简单的步骤,降低每个子任务的规模。
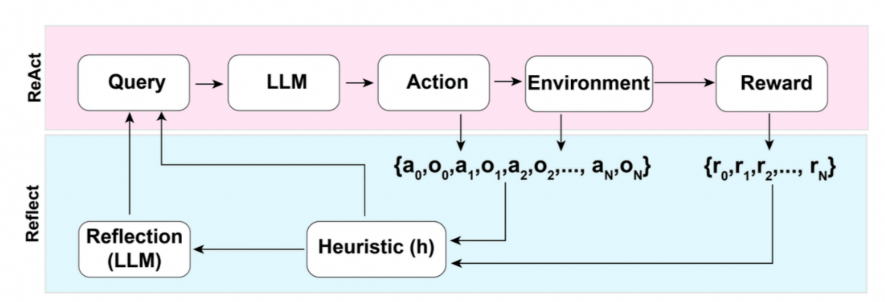
通过反思与自省框架,Agents可以不断提升任务规划能力。AI Agent可以对过去的行为进行自我批评和反思,从错误中学习,并为未来的步骤进行完善,从而提高最终结果的质量。自省框架使Agents能够修正以往的决策、纠正之前的失误,从而不断优化其性能。在实际任务执行中,尝试和错误是常态,反思和自省两个框架在这个过程中起到了核心作用。
2、记忆(Memory):利用上下文长度实现更多记忆
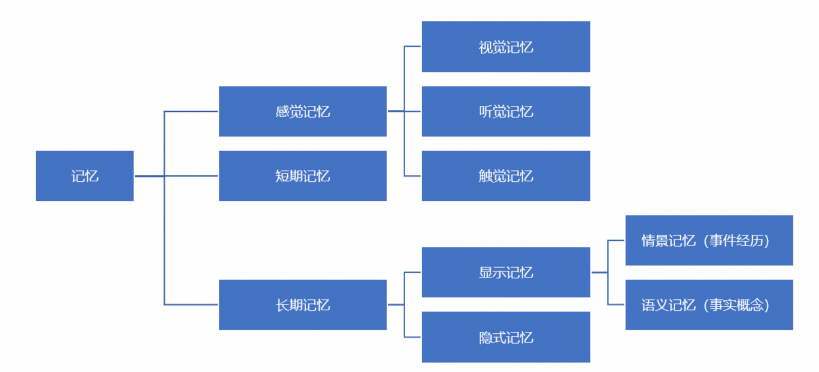
对AI智能体系统的输入会成为系统的记忆,与人类的记忆模式可实现一一映射。记忆可以定义为用于获取、存储、保留以及随后检索信息的过程。人脑中有多种记忆类型,如感觉记忆、短期记忆和长期记忆。而对于AI Agent系统而言,用户在与其交互过程中产生的内容都可以认为是Agent的记忆,和人类记忆的模式能够产生对应关系。
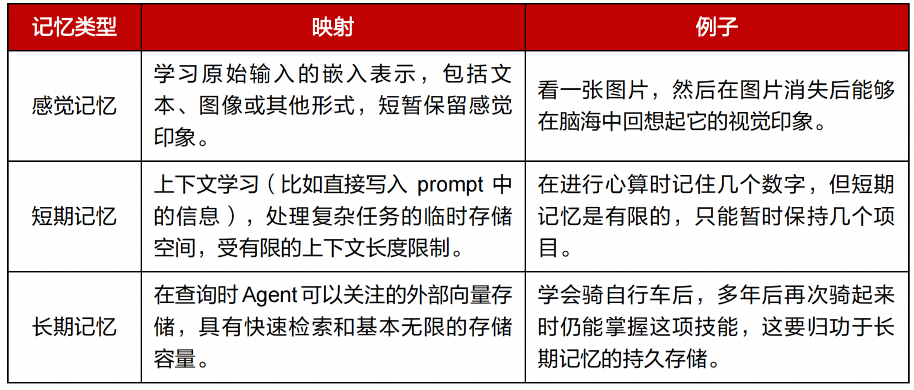
感觉记忆就是作为学习嵌入表示的原始输入,包括文本、图像或其他模态;短期记忆就是上下文,受到有限的上下文窗口长度的限制;长期记忆则可以认为是Agent在工作时需要查询的外部向量数据库,可通过快速检索进行访问。
目前Agent主要是利用外部的长期记忆,来完成很多的复杂任务,比如阅读PDF、联网搜索实时新闻等。任务与结果会储存在记忆模块中,当信息被调用时,储存在记忆中的信息会回到与用户的对话中,由此创造出更加紧密的上下文环境。
向量数据库通过将数据转化为向量存储,解决大模型海量知识的存储、检索、匹配问题。向量是AI理解世界的通用数据形式,大模型需要大量的数据进行训练,以获取丰富的语义和上下文信息,导致了数据量的指数级增长。
向量数据库利用人工智能中的Embedding方法,将图像、音视频等非结构化数据抽象、转换为多维向量,由此可以结构化地在向量数据库中进行管理,从而实现快速、高效的数据存储和检索过程,赋予了Agent“长期记忆”。同时,将高维空间中的多模态数据映射到低维空间的向量,也能大幅降低存储和计算的成本,向量数据库的存储成本比存到神经网络的成本要低2到4个数量级。
Embedding技术和向量相似度计算是向量数据库的核心。Embedding技术是一种将图像、音视频等非结构化数据转化为计算机能够识别的语言的方法,例如常见的地图就是对于现实地理的Embedding,现实的地理地形的信息其实远远超过三维,但是地图通过颜色和等高线等来最大化表现现实的地理信息。
在通过Embedding技术将非结构化数据例如文本数据转化为向量后,就可以通过数学方法来计算两个向量之间的相似度,即可实现对文本的比较。向量数据库强大的检索功能就是基于向量相似度计算而达成的,通过相似性检索特性,针对相似的问题找出近似匹配的结果,是一种模糊匹配的检索,没有标准的准确答案,进而更高效地支撑更广泛的应用场景。
3、工具使用(ToolUse):懂得使用工具才会更像人类
AI Agent与大模型的一大区别在于能够使用外部工具拓展模型能力。懂得使用工具是人类最显著和最独特的地方,同样地,我们也可以为大模型配备外部工具来让模型完成原本无法完成的工作。
ChatGPT的一大缺点在于,其训练数据只截止到了2021年底,对于更新一些的知识内容它无法直接做出回答。虽然后续Open AI为ChatGPT更新了插件功能,能够调用浏览器插件来访问最新的信息,但是需要用户来针对问题指定是否需要使用插件,无法做到完全自然的回答。
AI Agent则具备了自主调用工具的能力,在获取到每一步子任务的工作后,Agent都会判断是否需要通过调用外部工具来完成该子任务,并在完成后获取该外部工具返回的信息提供给LLM,进行下一步子任务的工作。
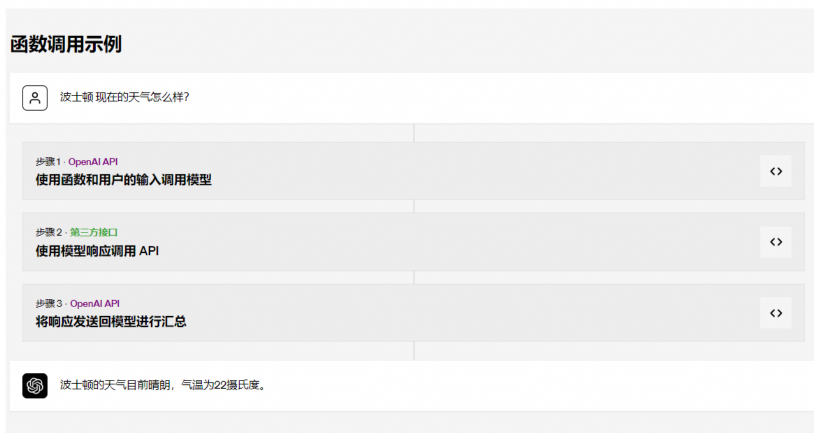
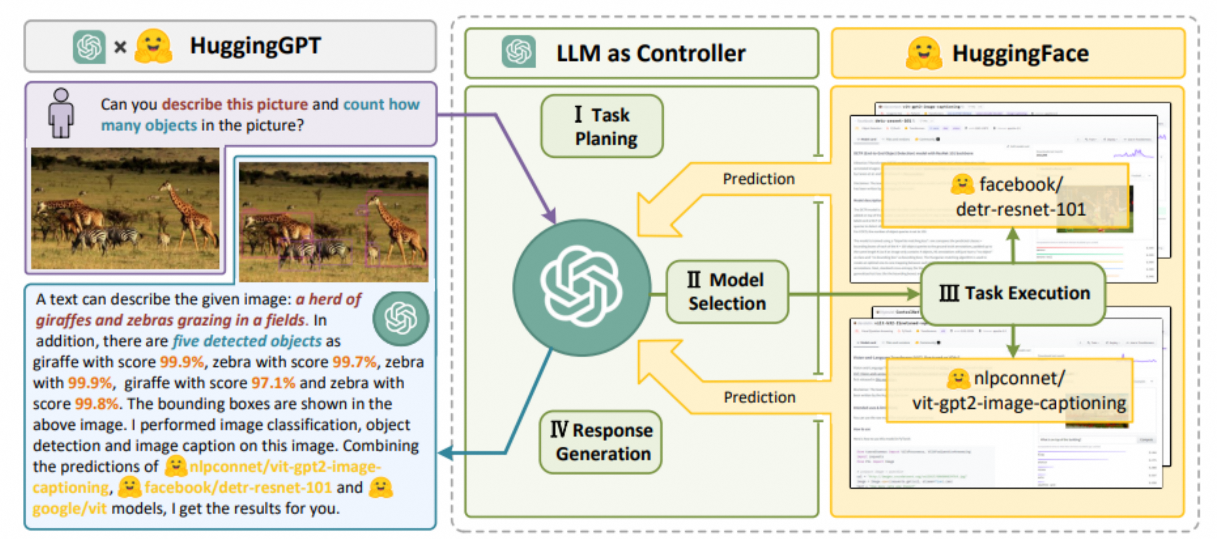
以HuggingGPT为例,HuggingGPT将模型社区HuggingFace和ChatGPT连接在一起,形成了一个AI Agent。2023年4月,浙江大学和微软联合团队发布了HuggingGPT,它可以连接不同的AI模型,以解决用户提出的任务。HuggingGPT融合了HuggingFace中成百上千的模型和GPT,可以解决24种任务,包括文本分类、对象检测、语义分割、图像生成、问答、文本语音转换和文本视频转换。具体步骤分为四步:
(1)任务规划:使用ChatGPT来获取用户请求;
(2)模型选择:根据HuggingFace中的函数描述选择模型,并用选中的模型执行AI任务;
(3)任务执行:使用第2步选择的模型执行的任务,总结成回答返回给ChatGPT;
(4)回答生成:使用ChatGPT融合所有模型的推理,生成回答返回给用户。