
- 1Hobbit玩转Zynq MPSoC系列之2:TPG输入+VCU编码+rtp网络传输_mpsoc gstreamer
- 2REPO镜像服务器的搭建_repo需要解压吗
- 3基于BiLSTM-CRF的命名实体识别_bilstm-crf命名实体识别
- 4Java高级面试精粹:疑难问题解析与答案(一)
- 5记录 libldap-2.4.so.2: cannot open shared object file: No such file or directory
- 6oracle nvl函数无效数字,Oracle ORA-01722 错误解决_oracle nvl 无效数字
- 7Xilinx PCIe IP核示例工程代码分析与仿真_xilinx pio例子
- 8深度学习环境的搭建_the program 'ubuntu-drivers' is currently not inst
- 9HDFS Java API 基本操作实验_头歌hdfs 的基本操作和 java api 操作
- 10【面试答疑】贝壳找房25实习生集中面试即将开启!HR当天答疑
【valse 2024】会议内容汇总(持续更新)_valse ppt
赞
踩

提示:更新中,一周左右更新完毕。需要具体课件的可私信
文章目录
Tutorial 1:开放词汇视觉感知
讲者:李冠彬-中山大学
时间:第二天下午

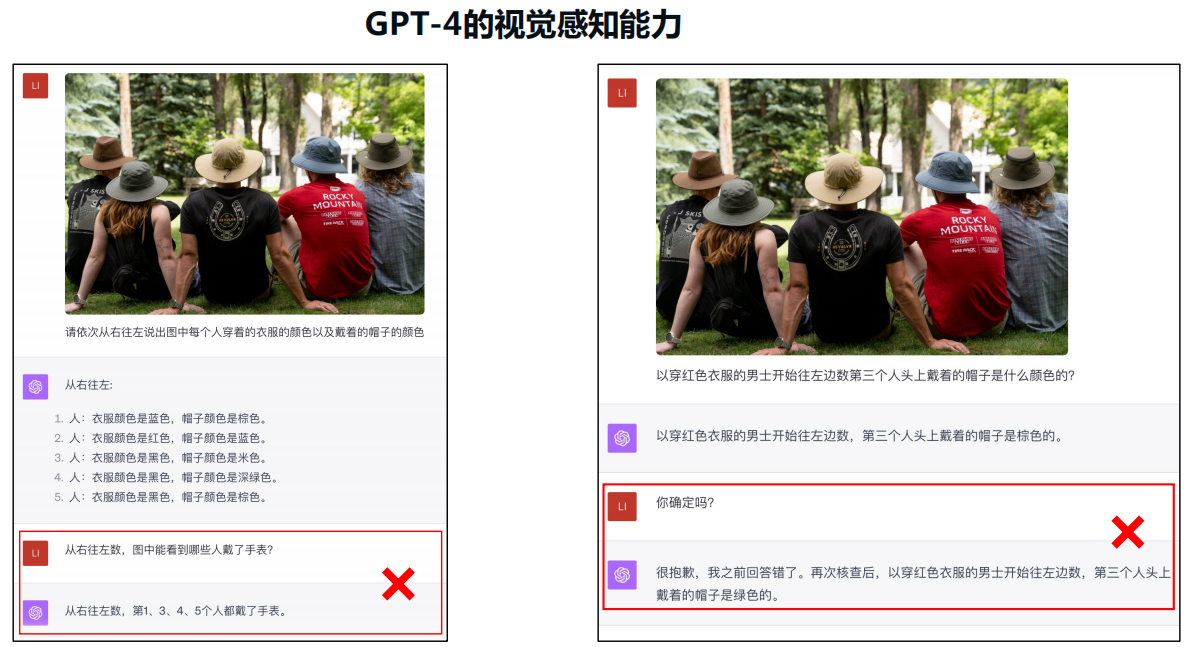
一、课题背景介绍
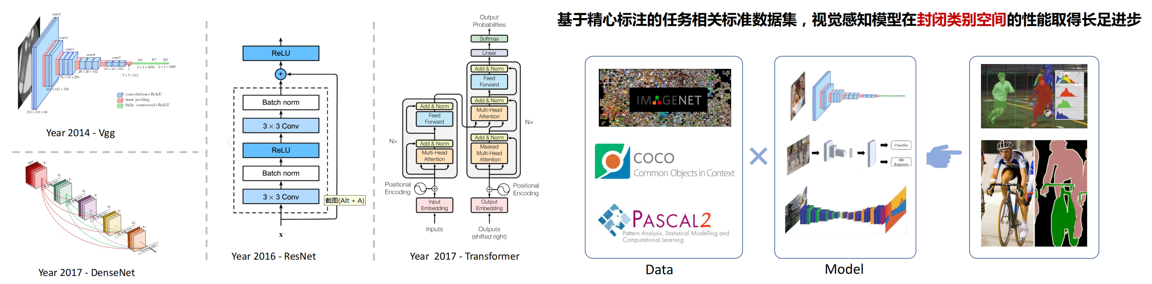
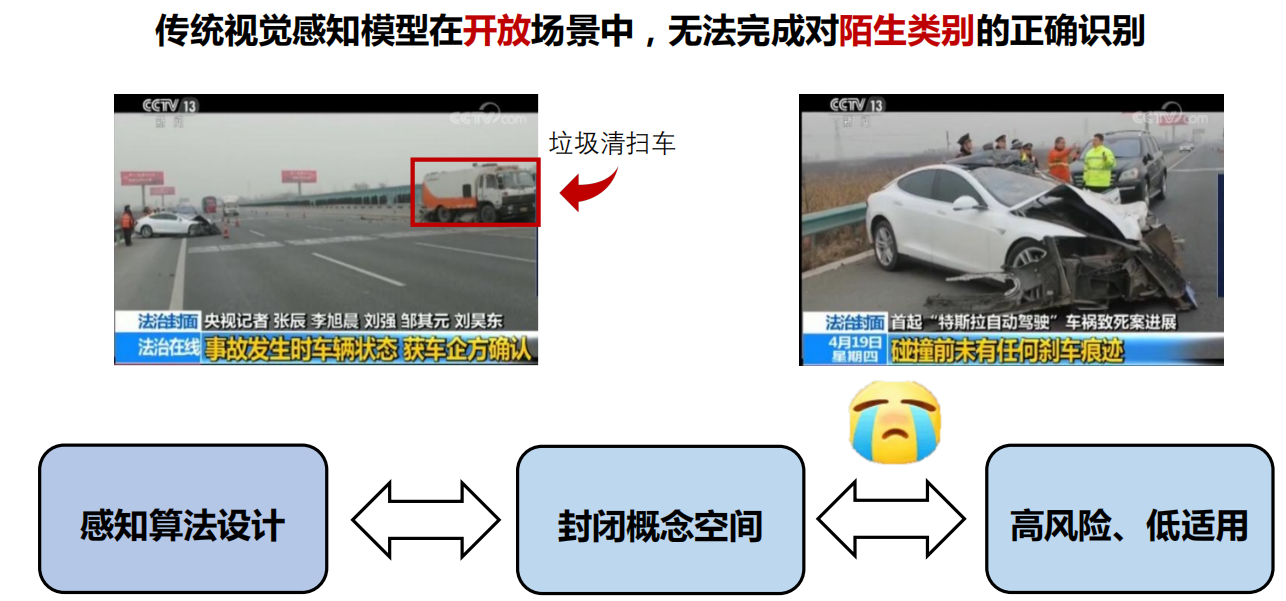
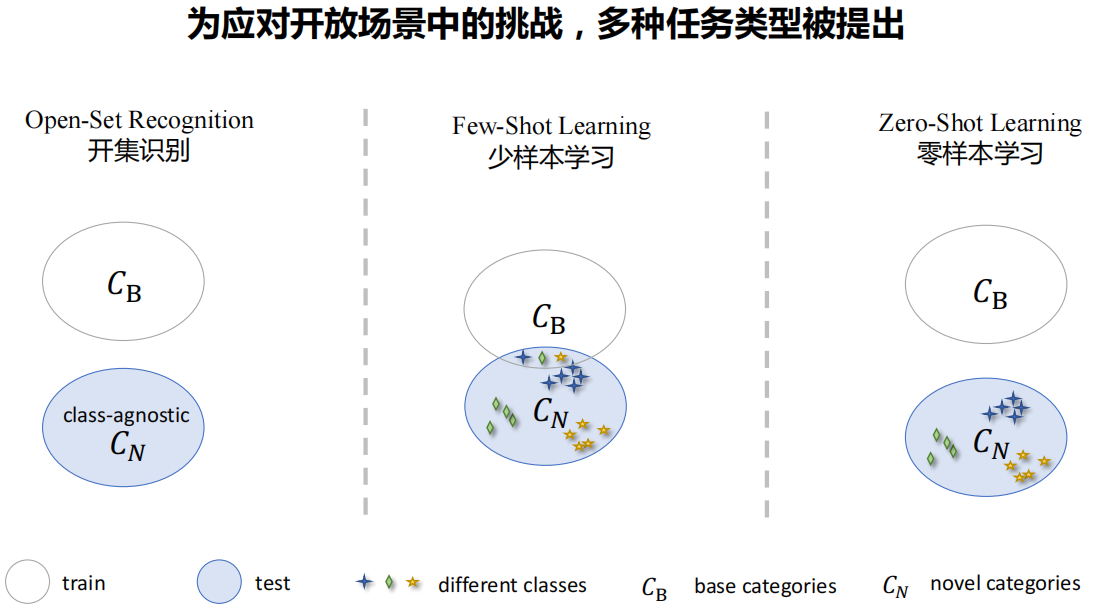
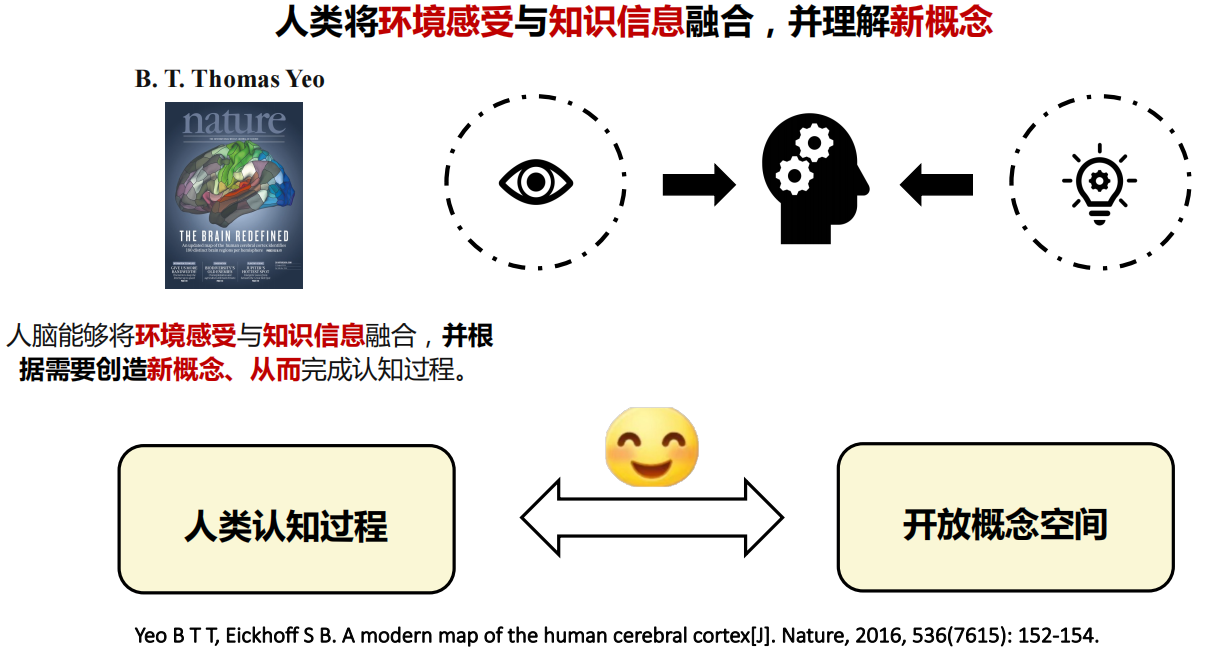
开放词汇视觉感知 要求模型从海量图文对数据中学习视觉概念知识,并在实际开放 场景中实现不限类别 的视觉感知。
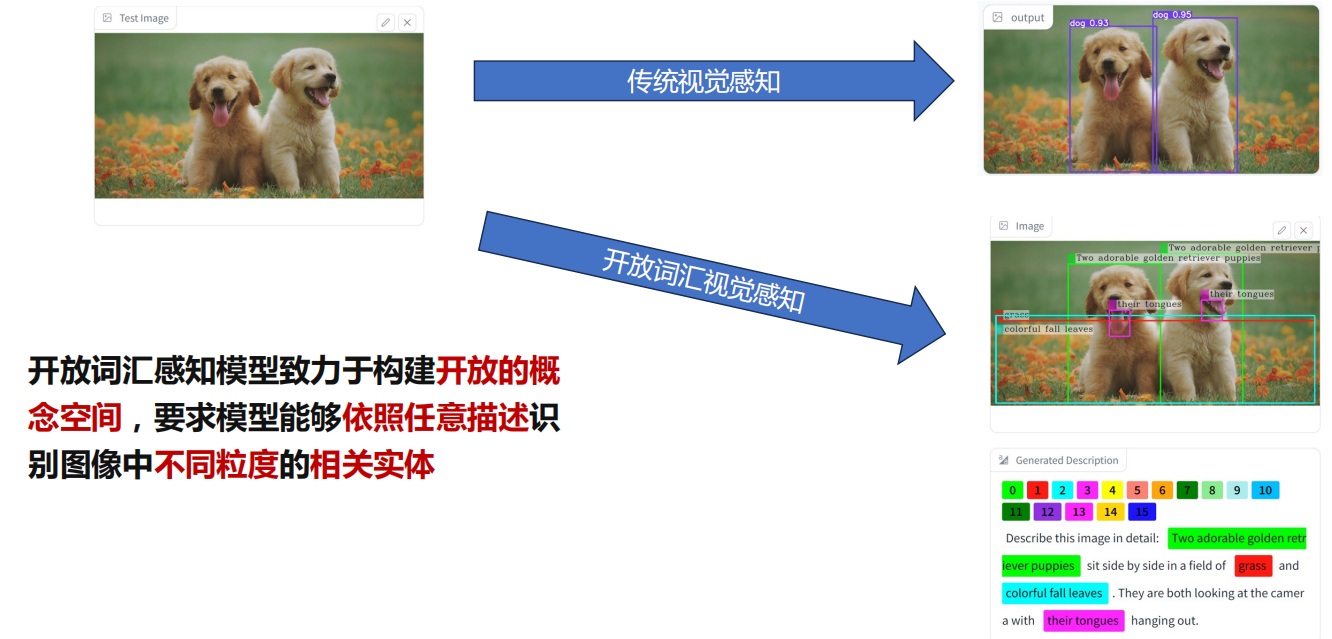
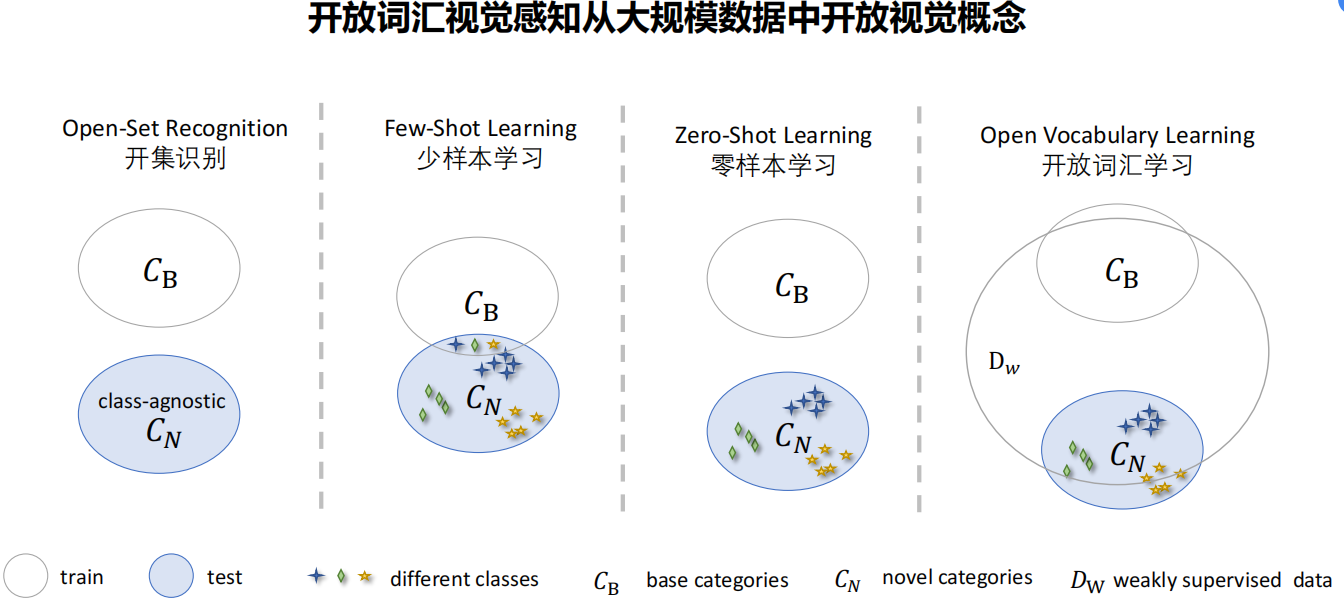
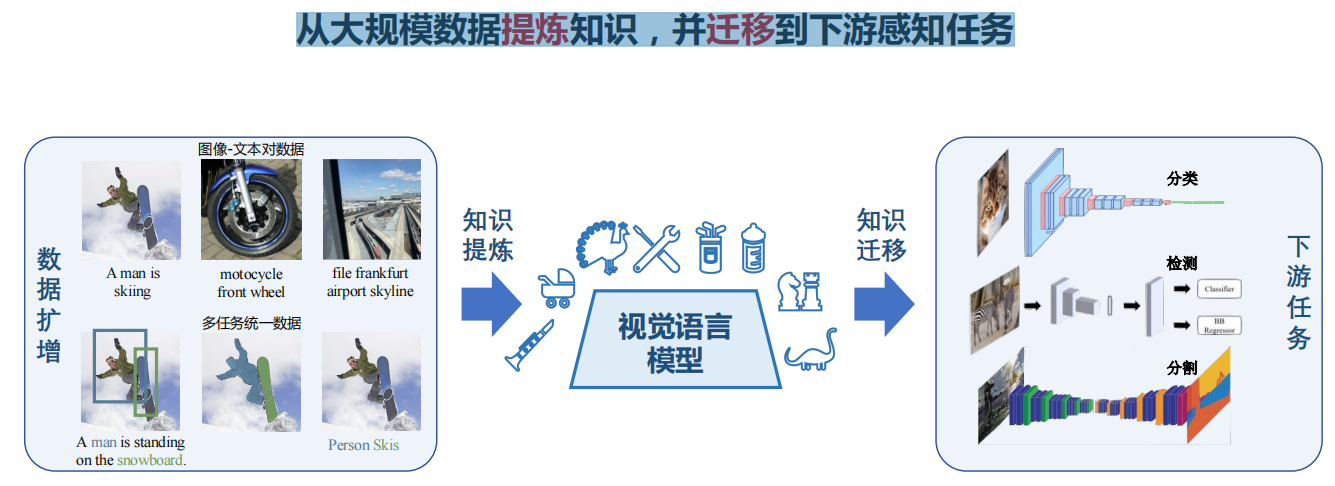
二、开放词汇分类
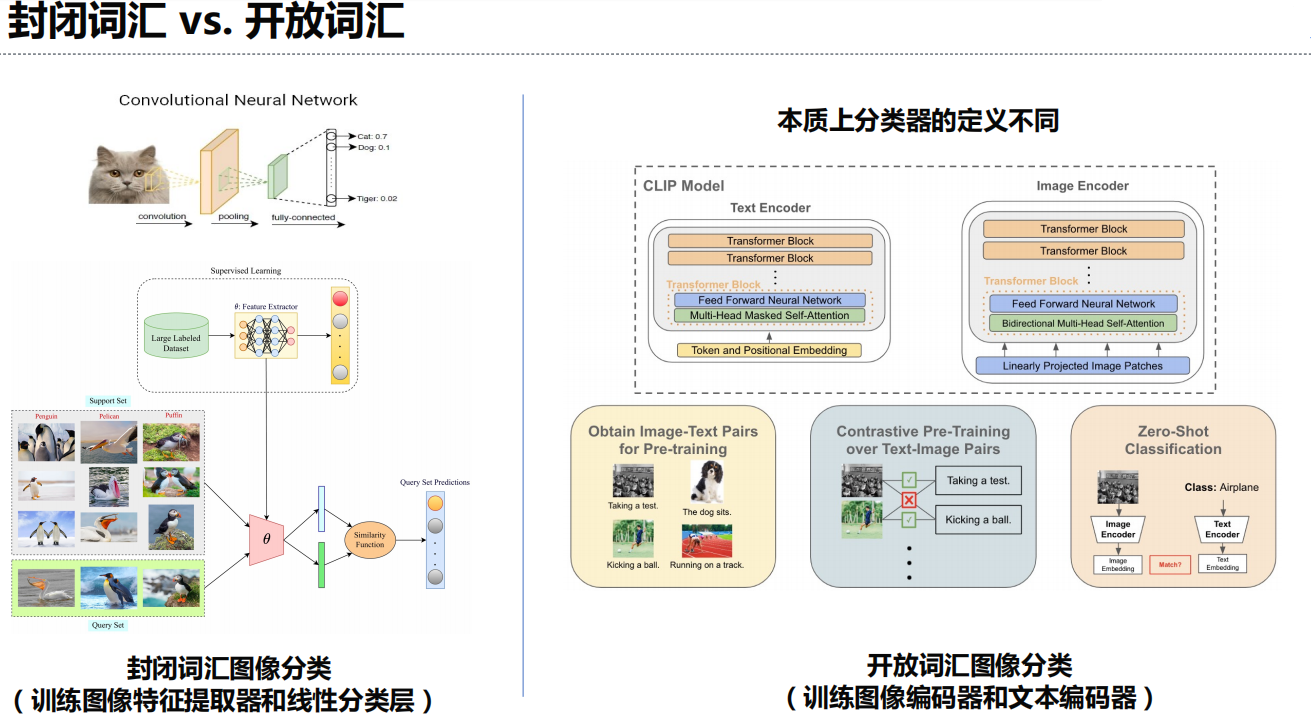
利用海量图像-文本对,将图像与文本映射到同一嵌入空间,实现概念跨模态语义对齐。
特点:
图文关联弱,噪声较大
海量数据易获取
泛化能力强
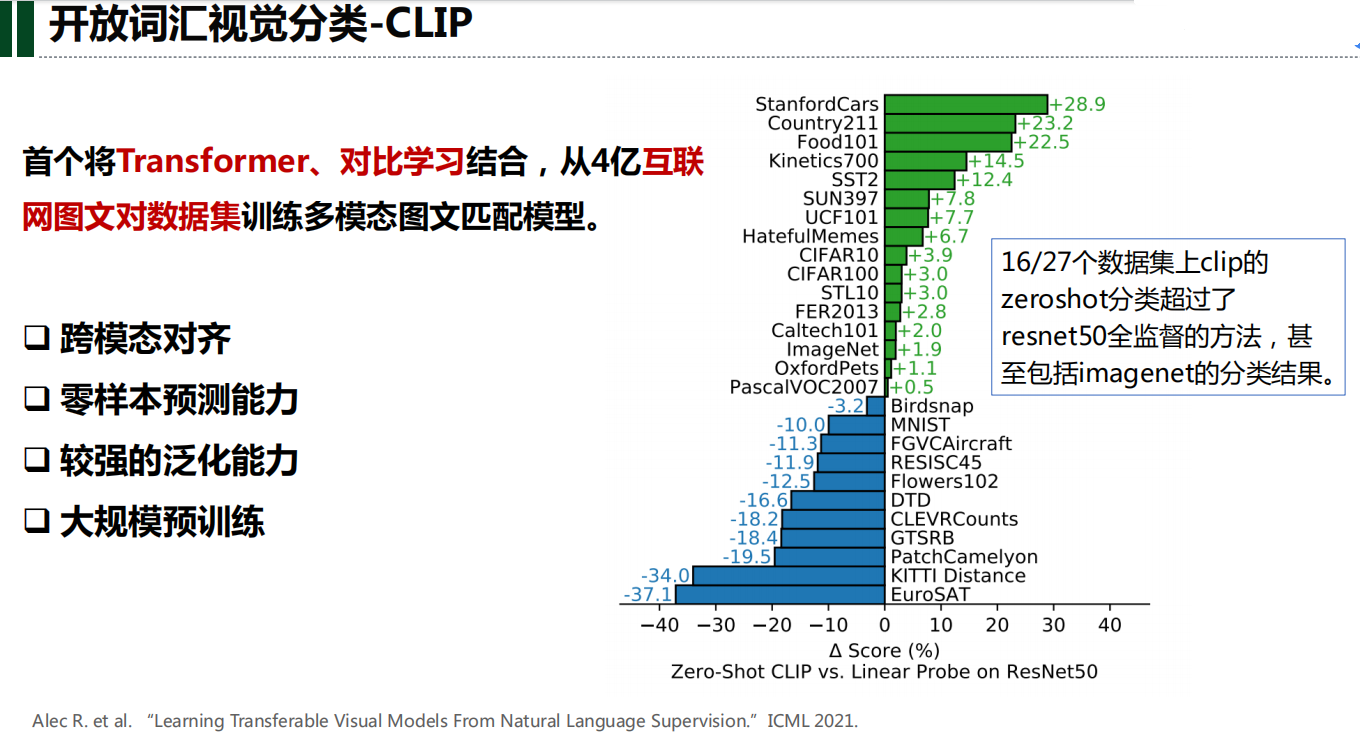
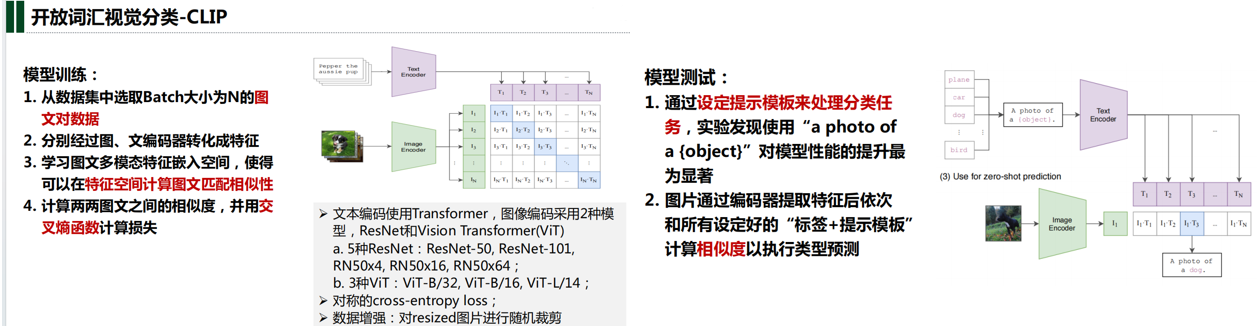

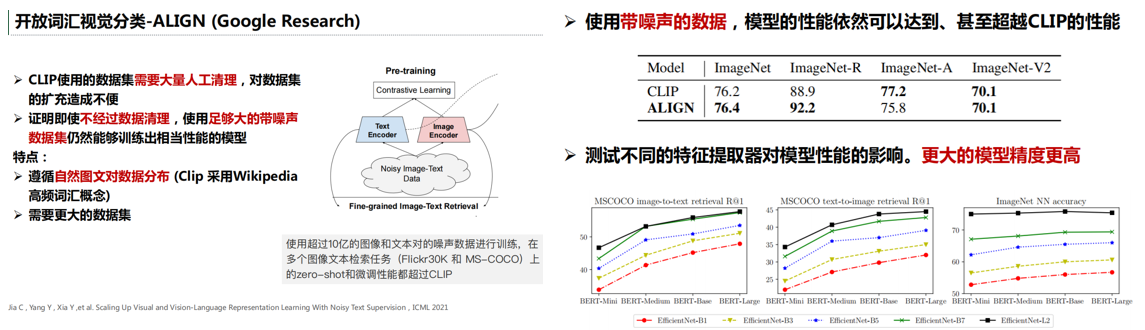



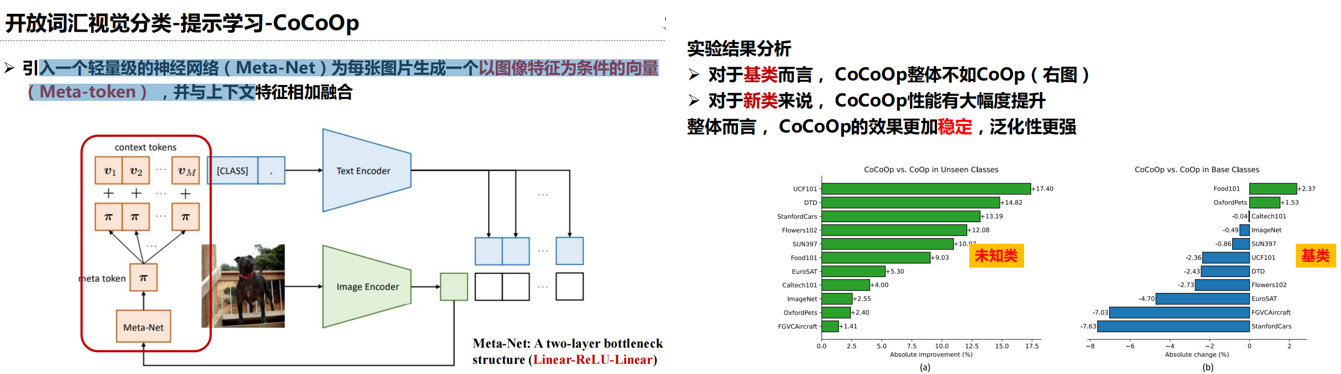
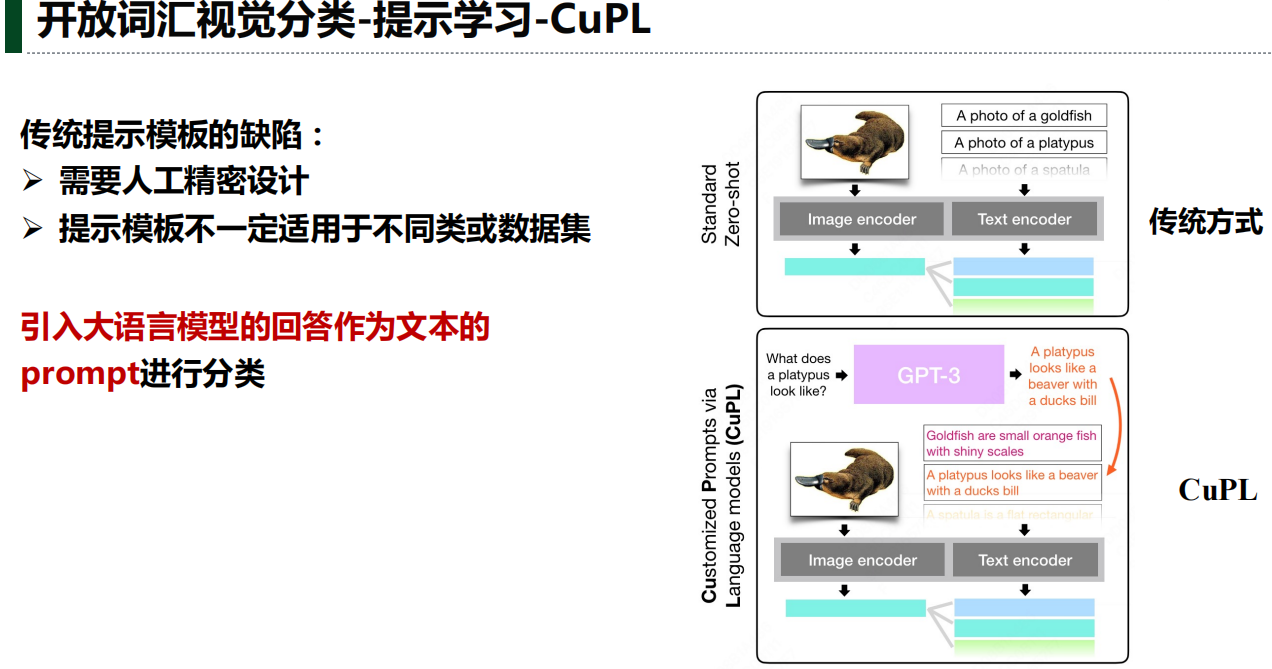


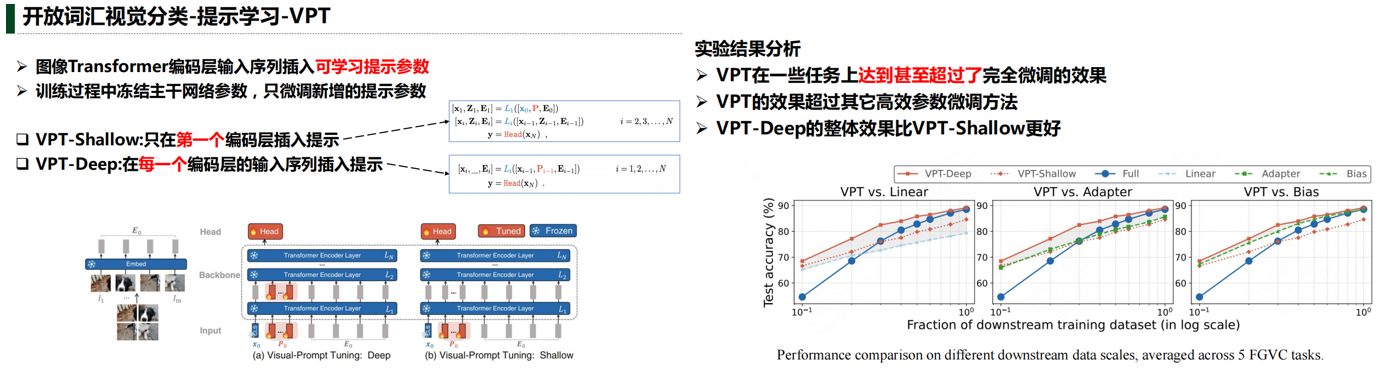
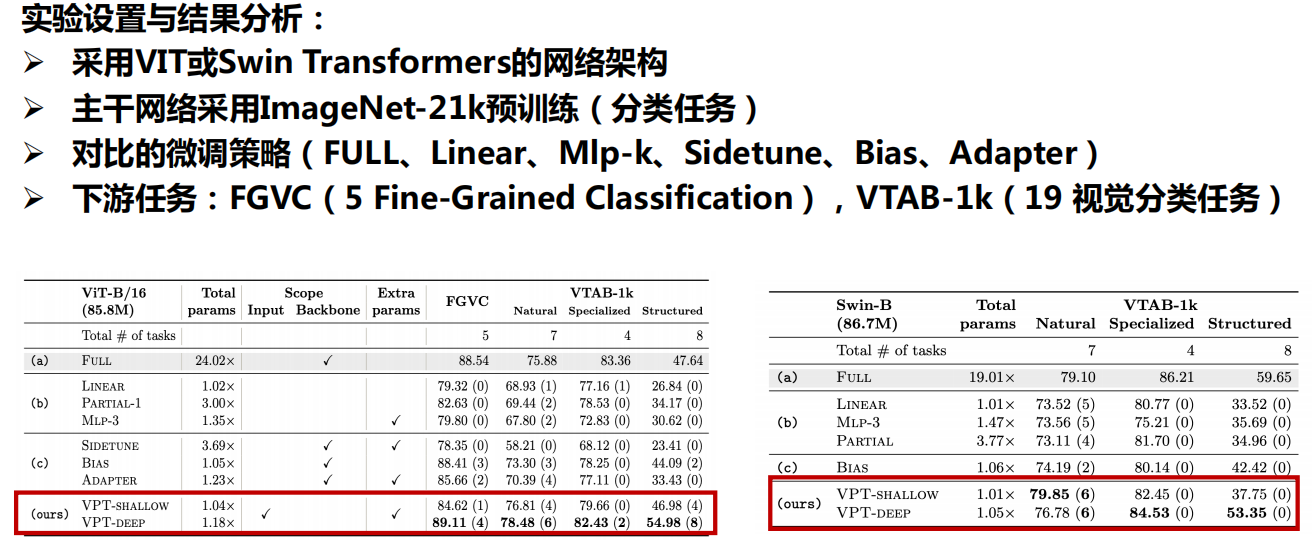
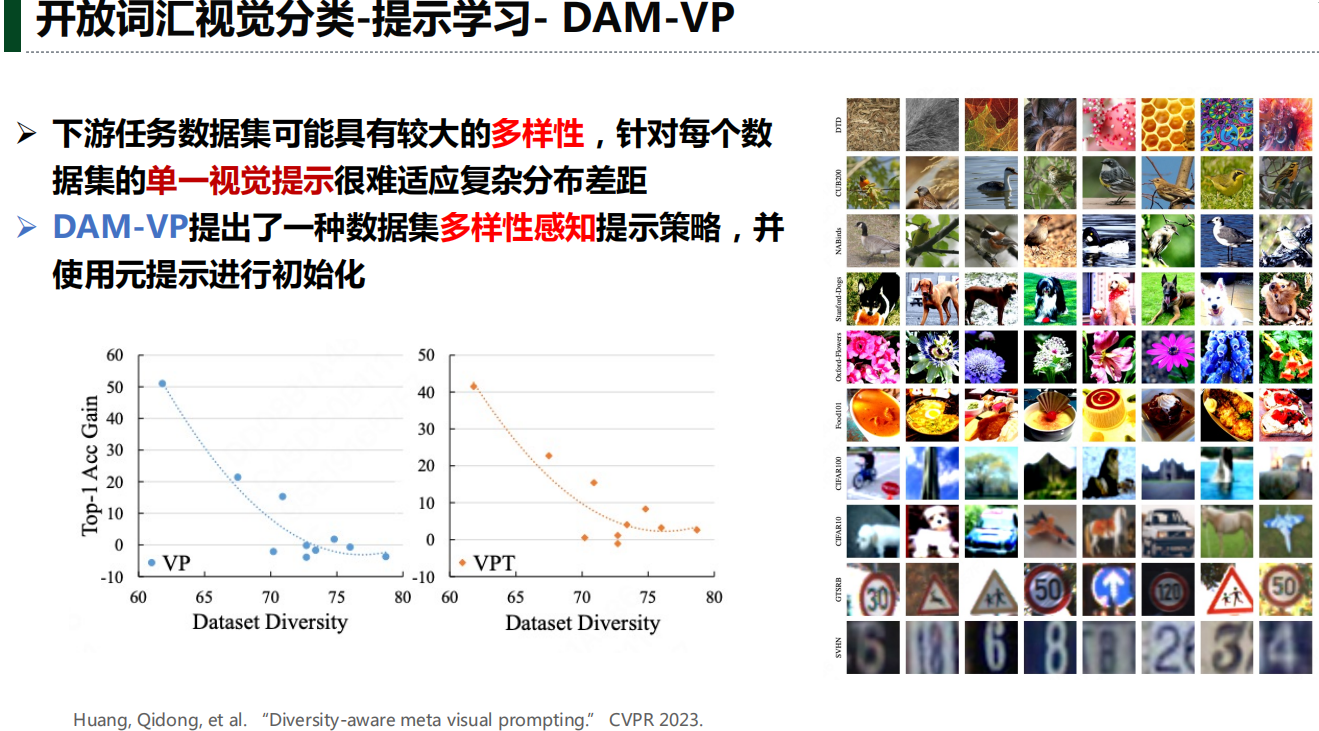
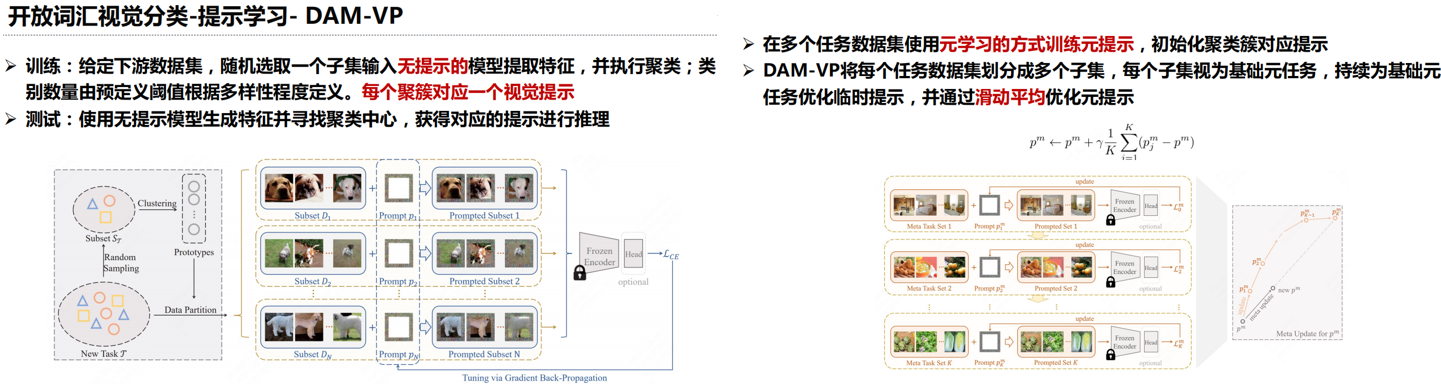
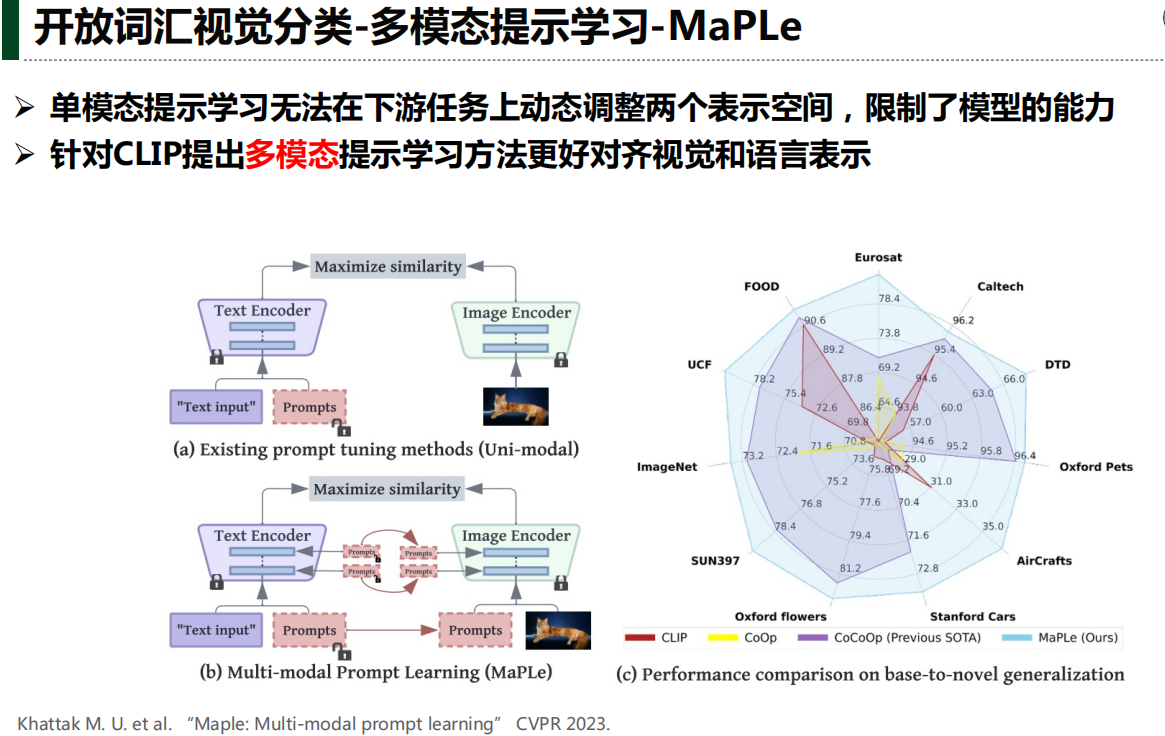
实验结果分析:
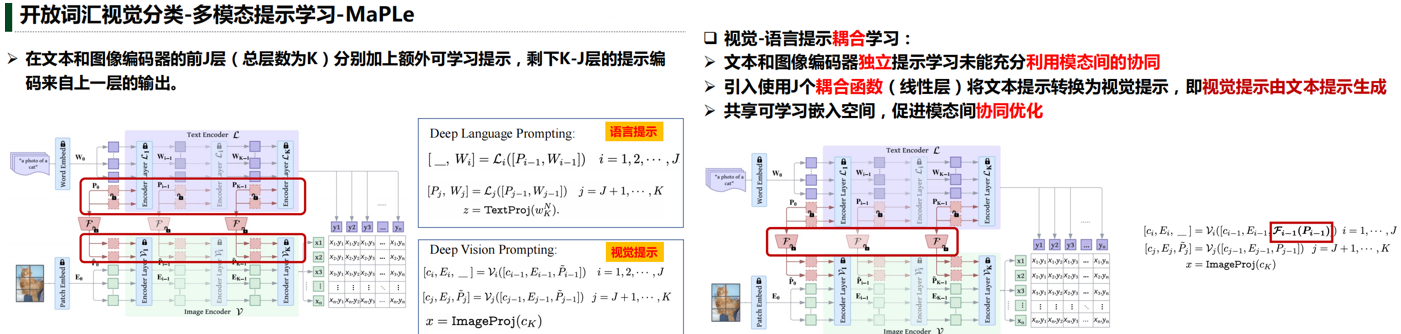
1.多模态提示学习优于单模态提示学习,耦合多模态提示优于独立多模态提示
2.对于新类泛化能力,MaPLe优于CoCoOp,原因归于MaPLe 利用了文本和视觉提示的协同学习
3.整体性能MaPLe都优于CoOp和CoCoOp

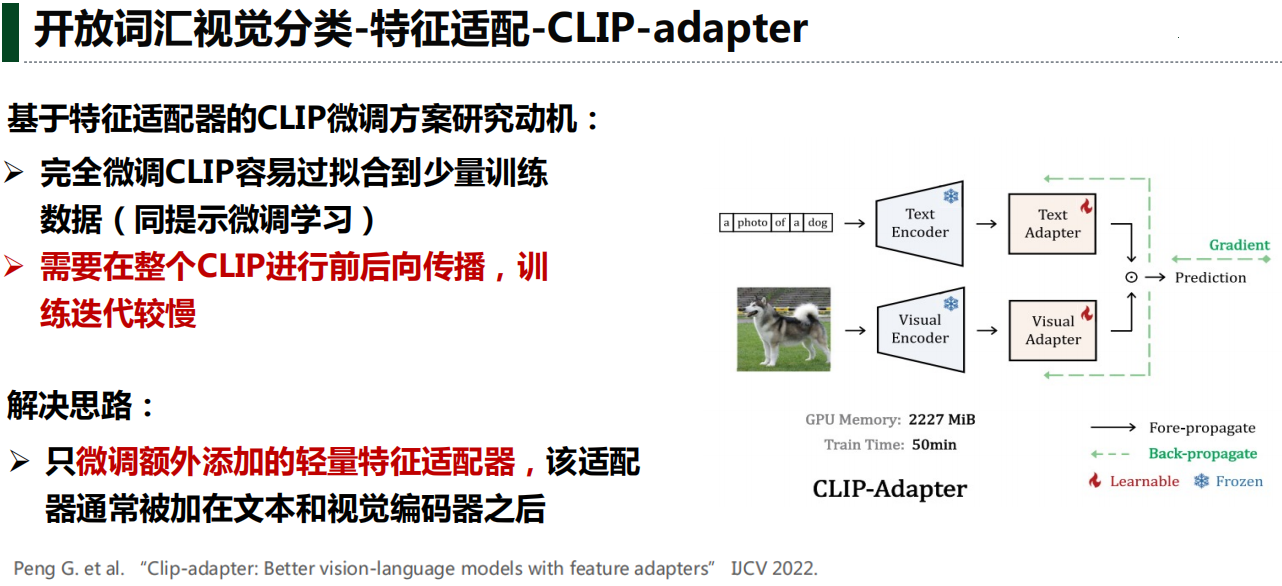

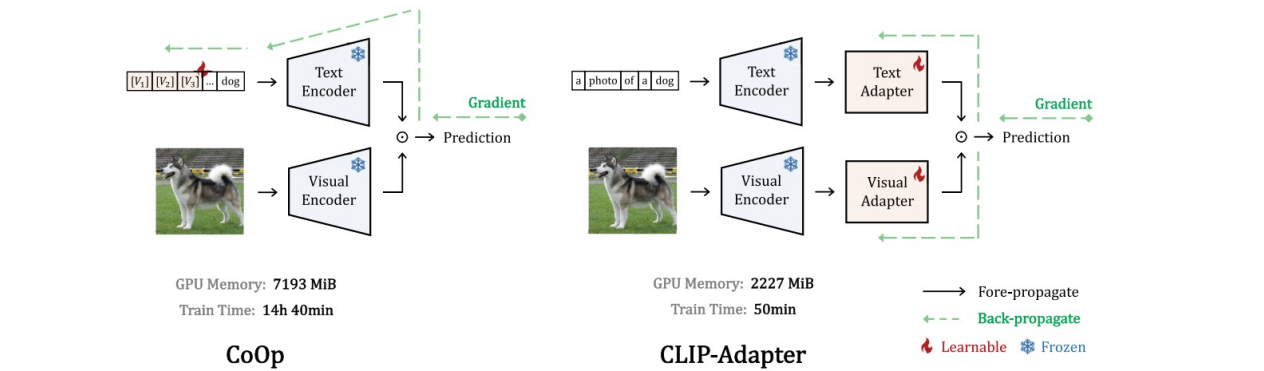
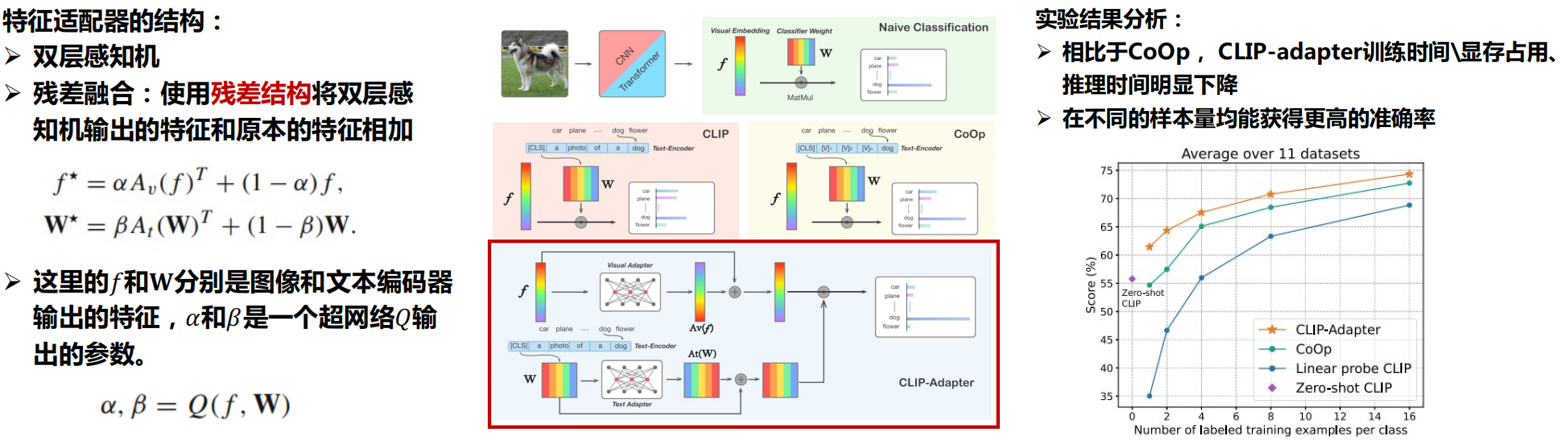
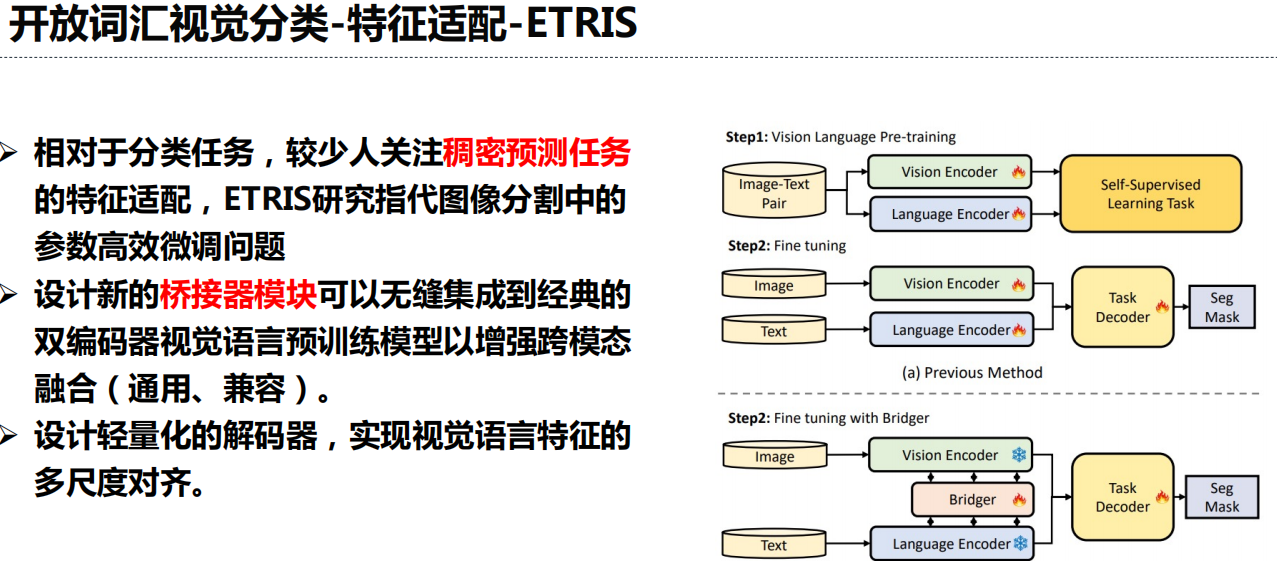

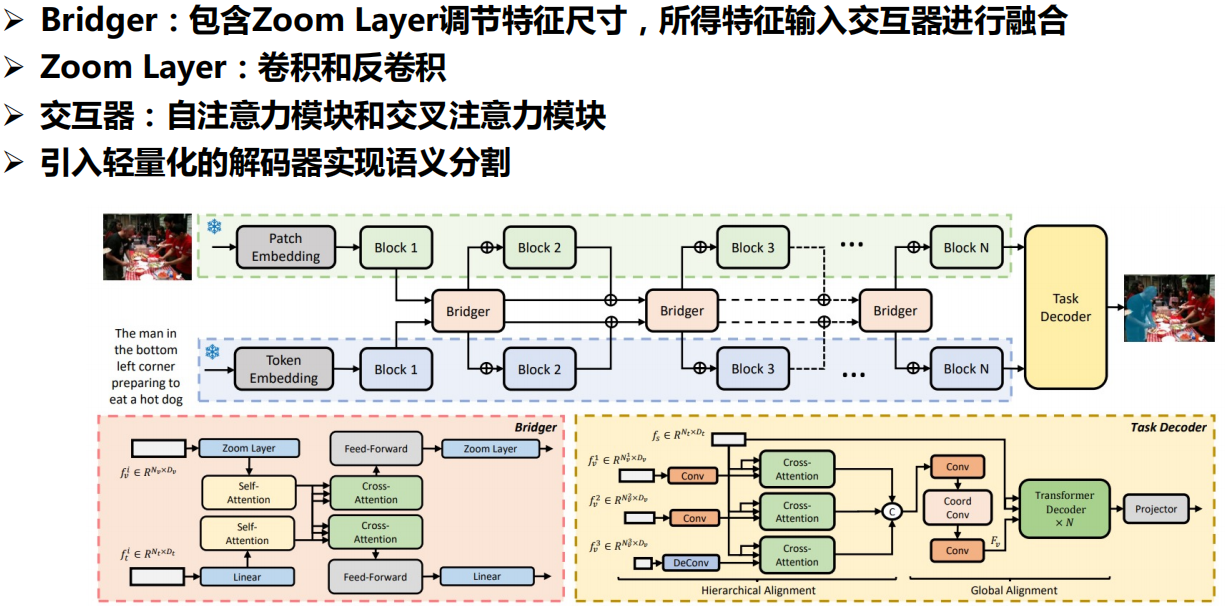
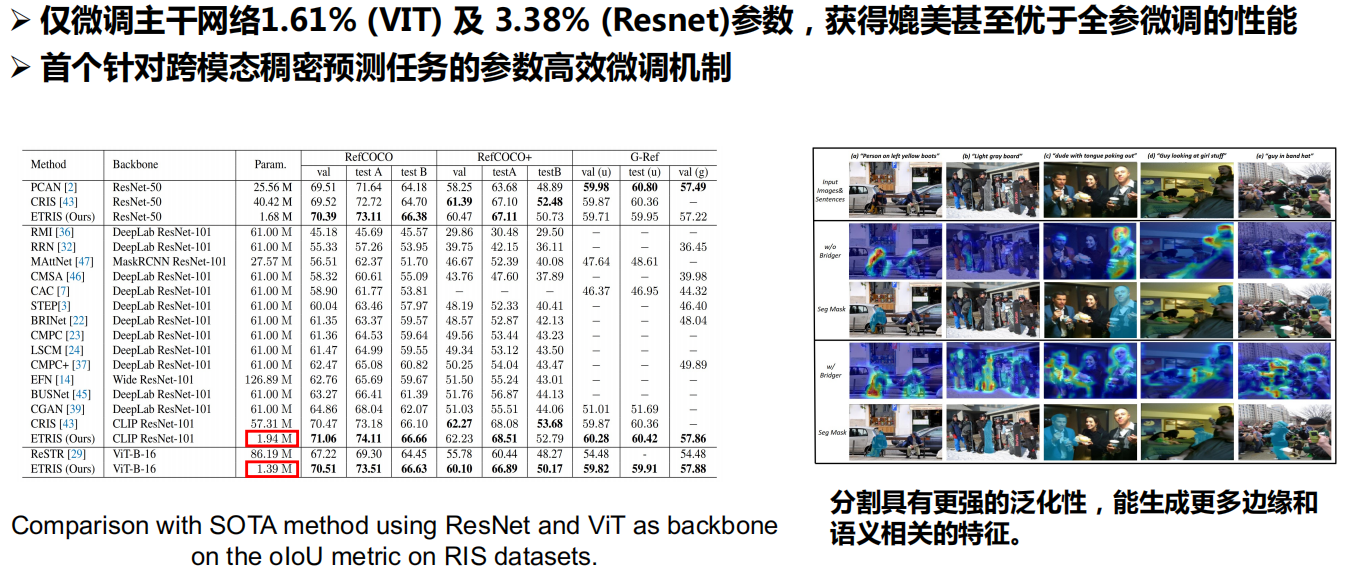



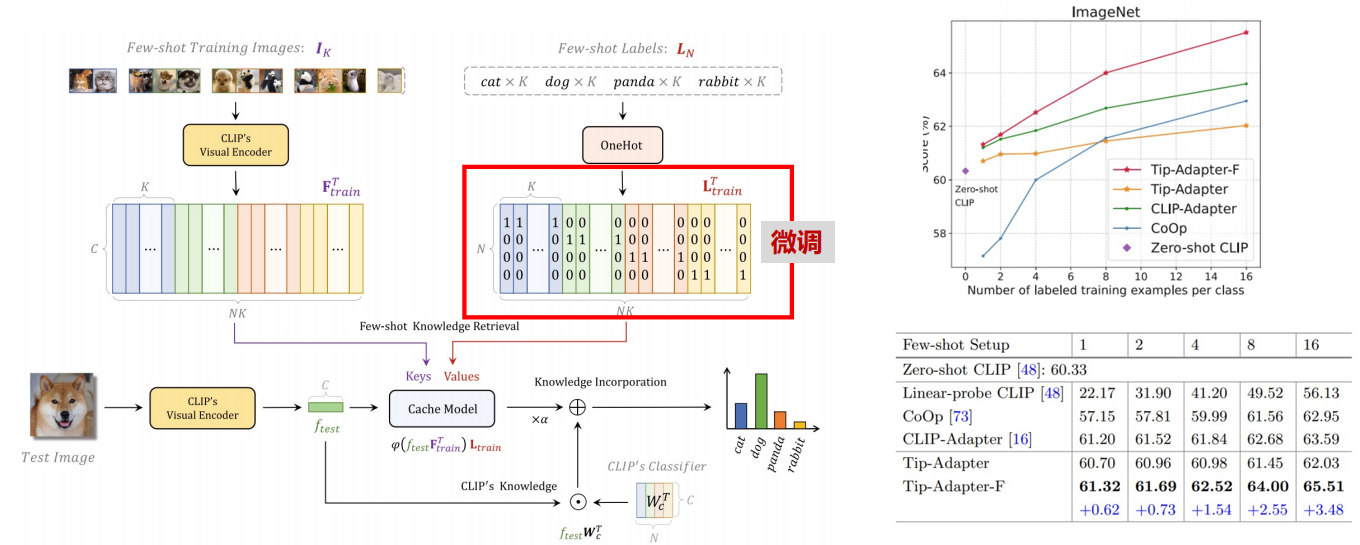

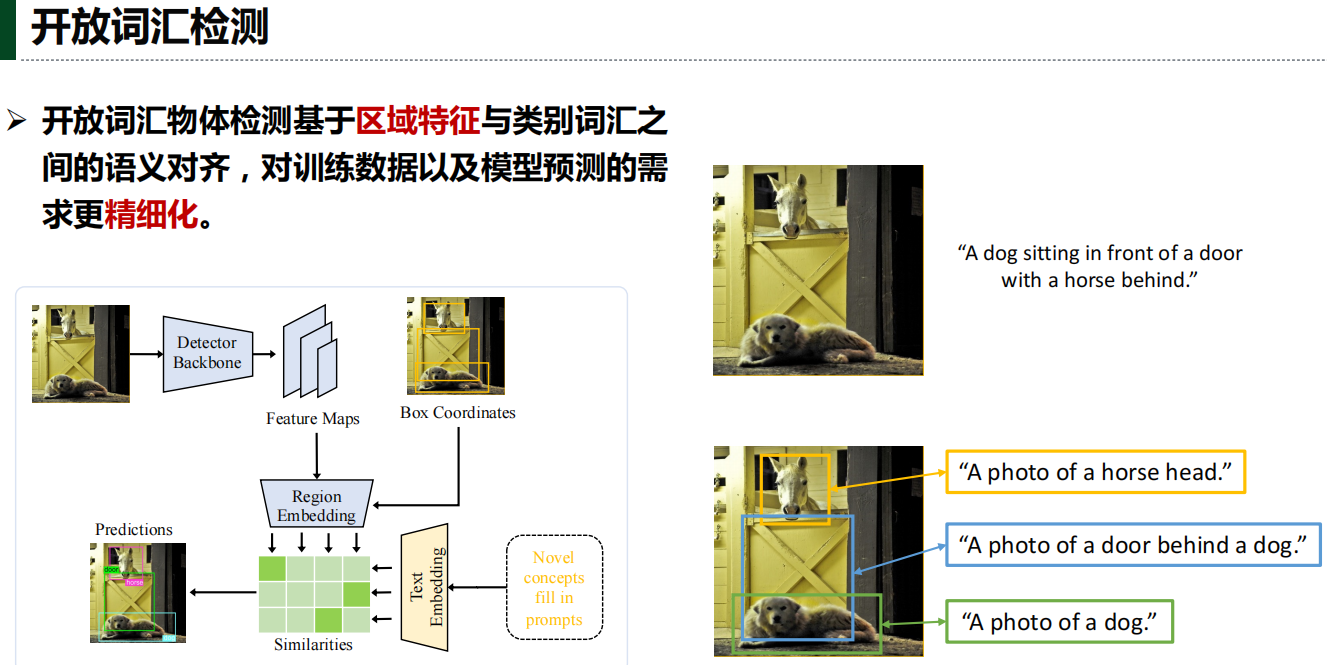
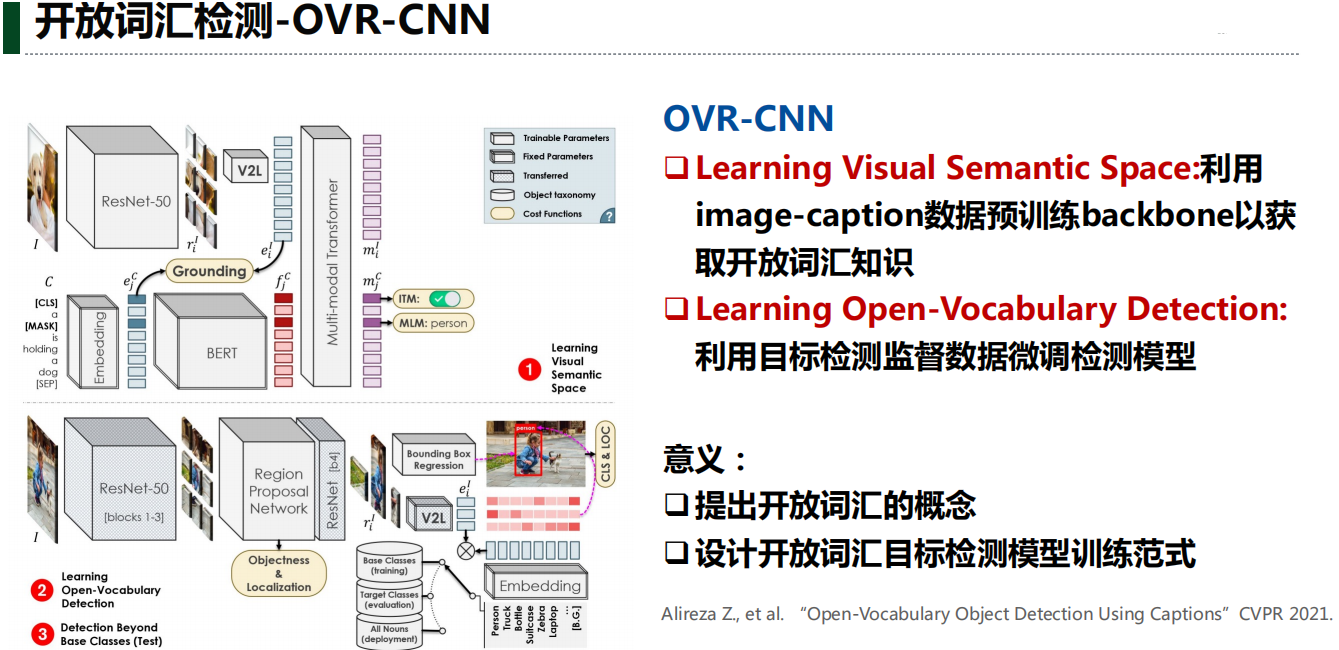
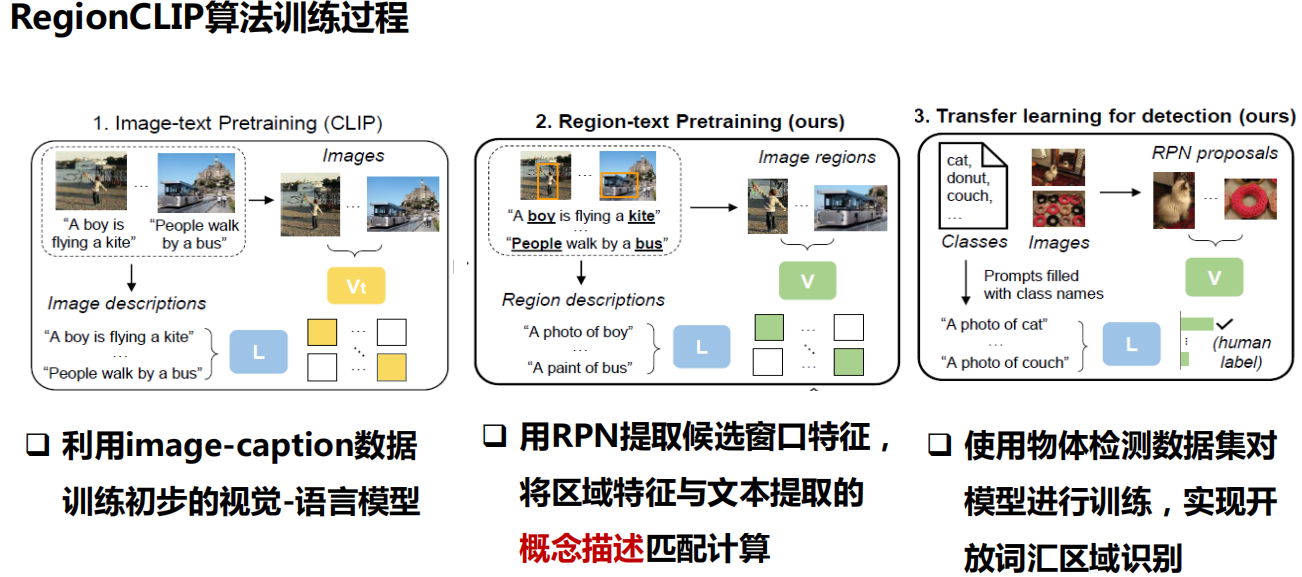
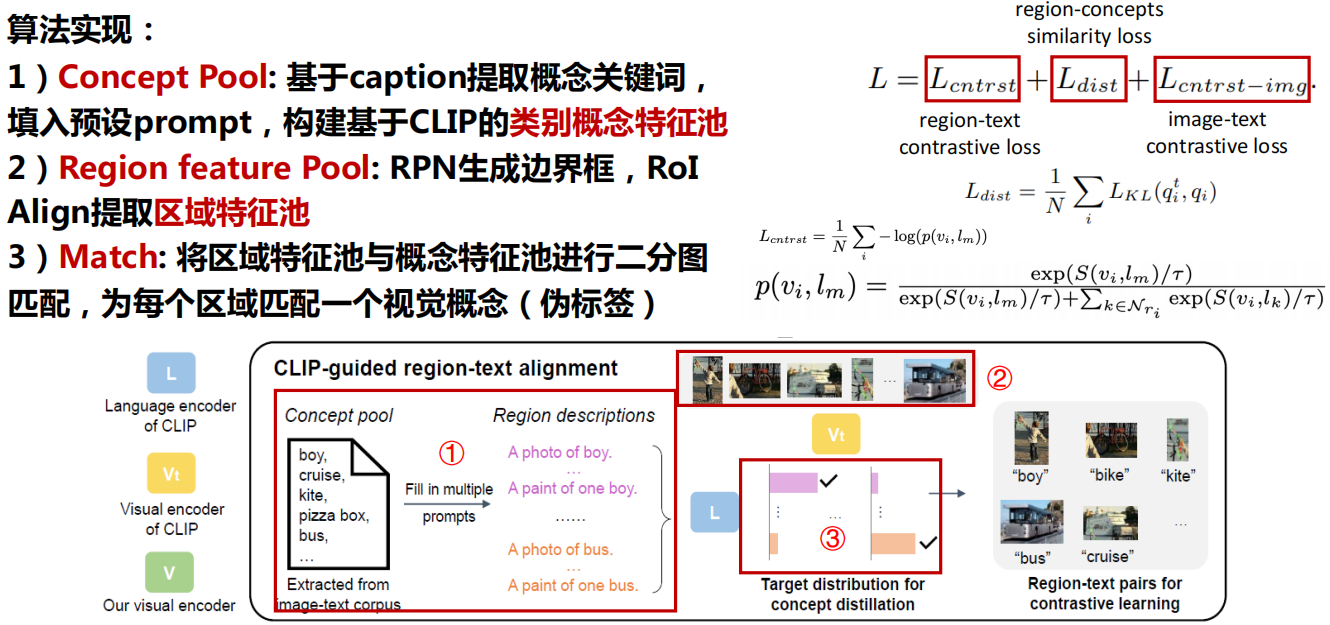
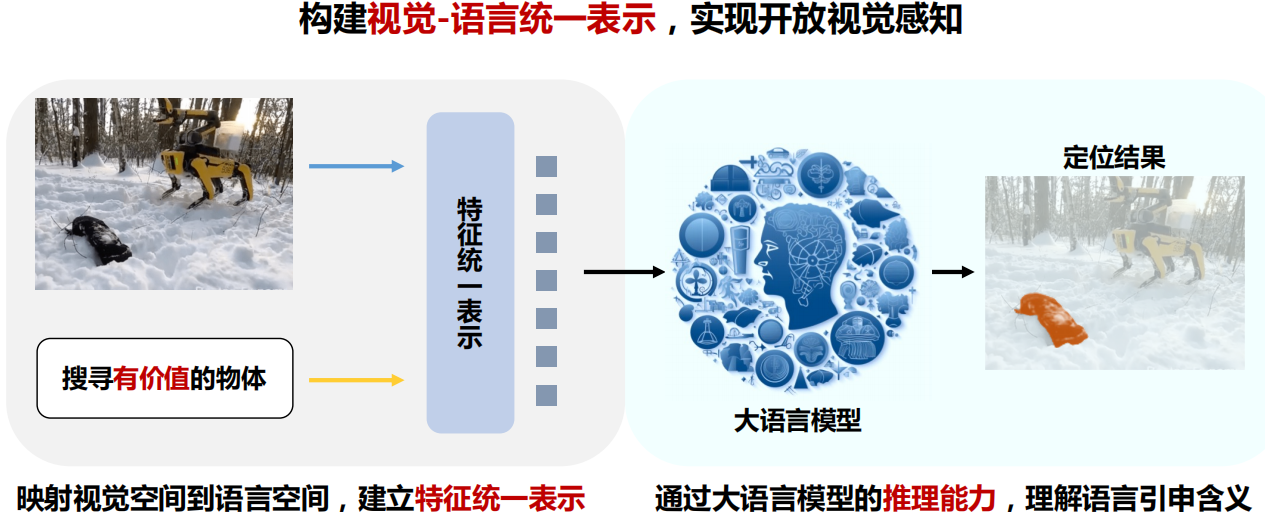
三、开放词汇检测




《Grounded Language-Image Pre-training》
算法思想
1.将物体匹配与短语定位任务统一起来进行预训练;
2.利用区域定位能力从图文对数据中构建准确的区域文本对数据
核心贡献
1.统一的区域级图文匹配预训练模型
2.准确性高,泛用性强
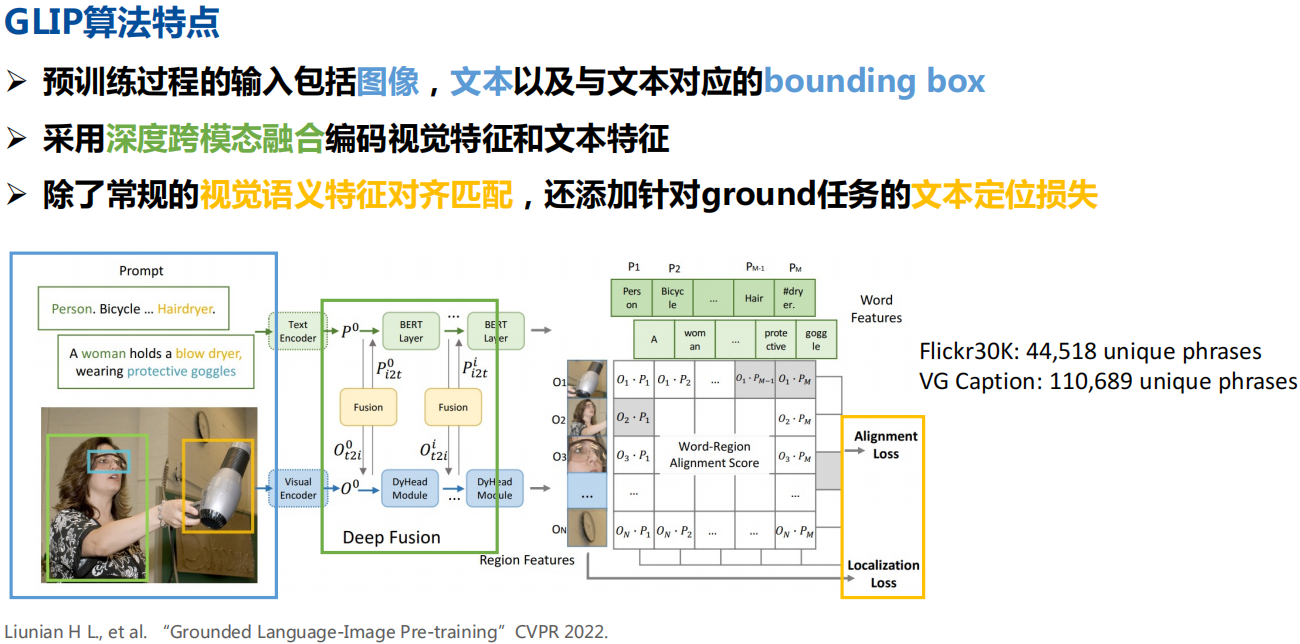

利用海量“图像-文本”数据扩大视觉概念:
1)利用已有的Grounding数据(80万)进行监督训练,得到教师模型
2)从图像文本对数据提取名词短语,基于“教师-学生” 半监督学习从“图像文本对”生成“区域文本对”伪标签,并加入训练学生模型。

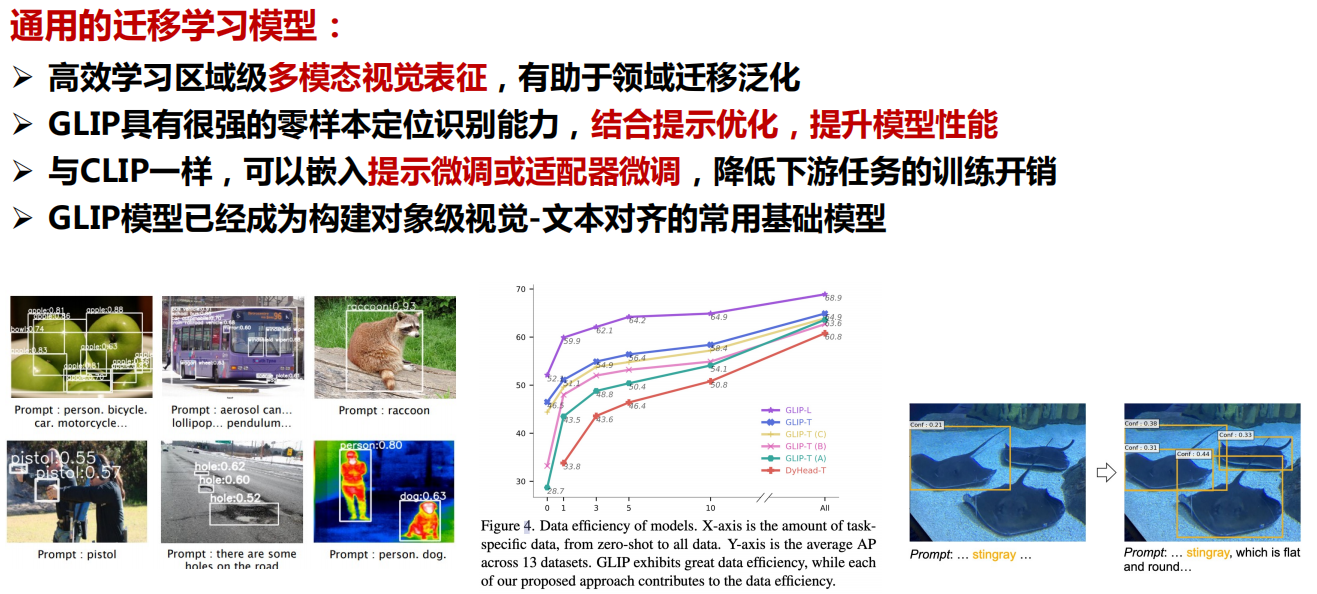







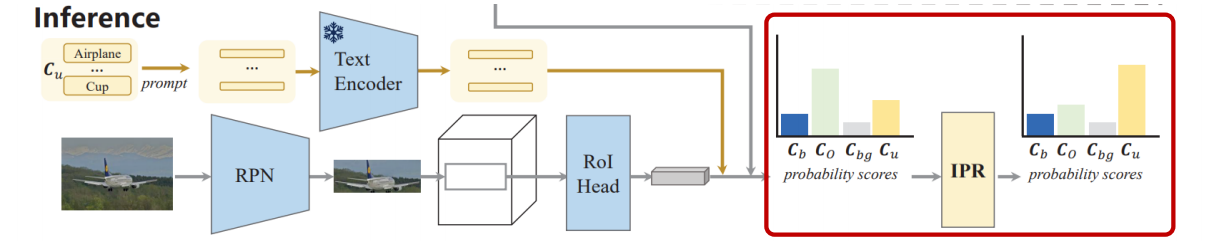


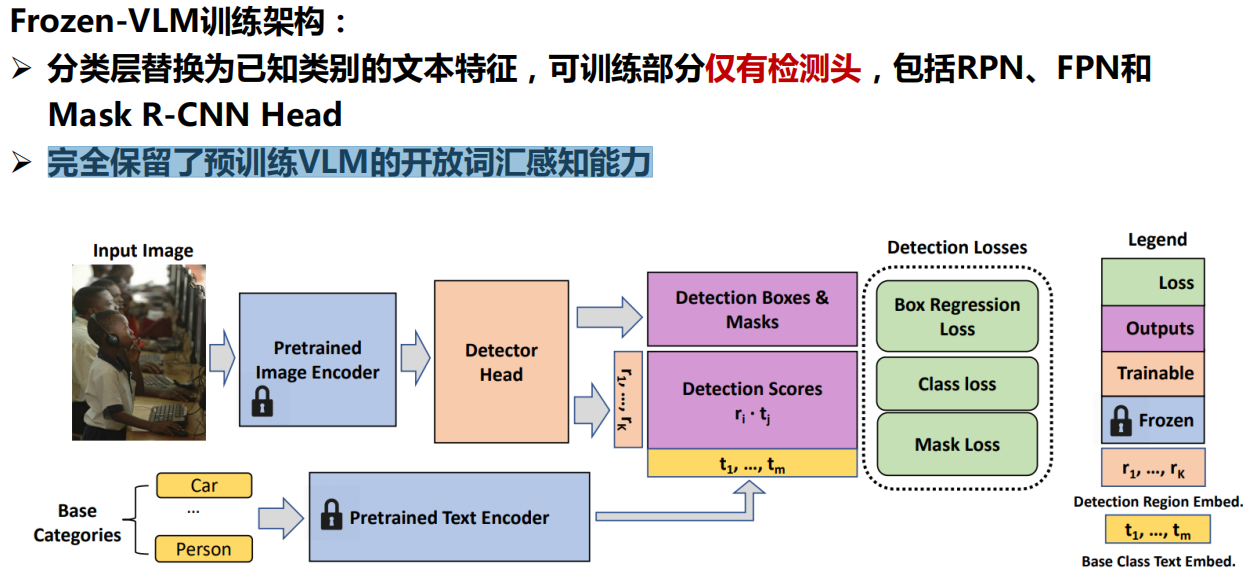








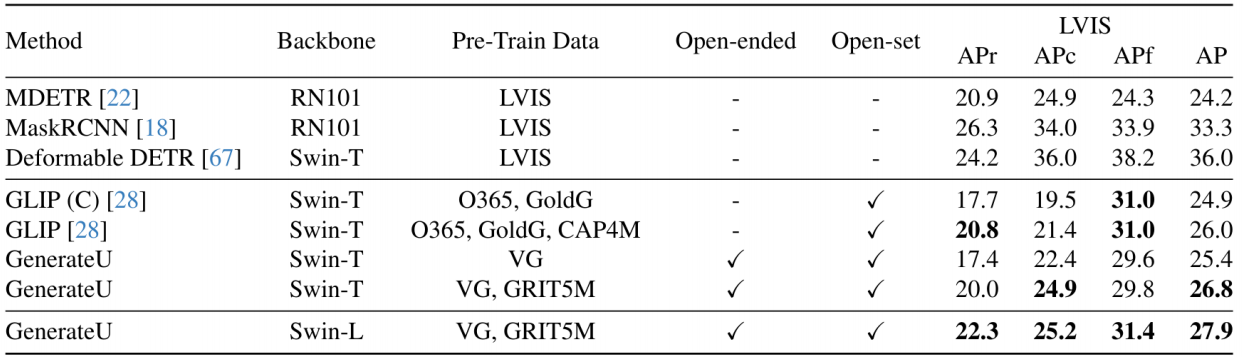
总结一下:

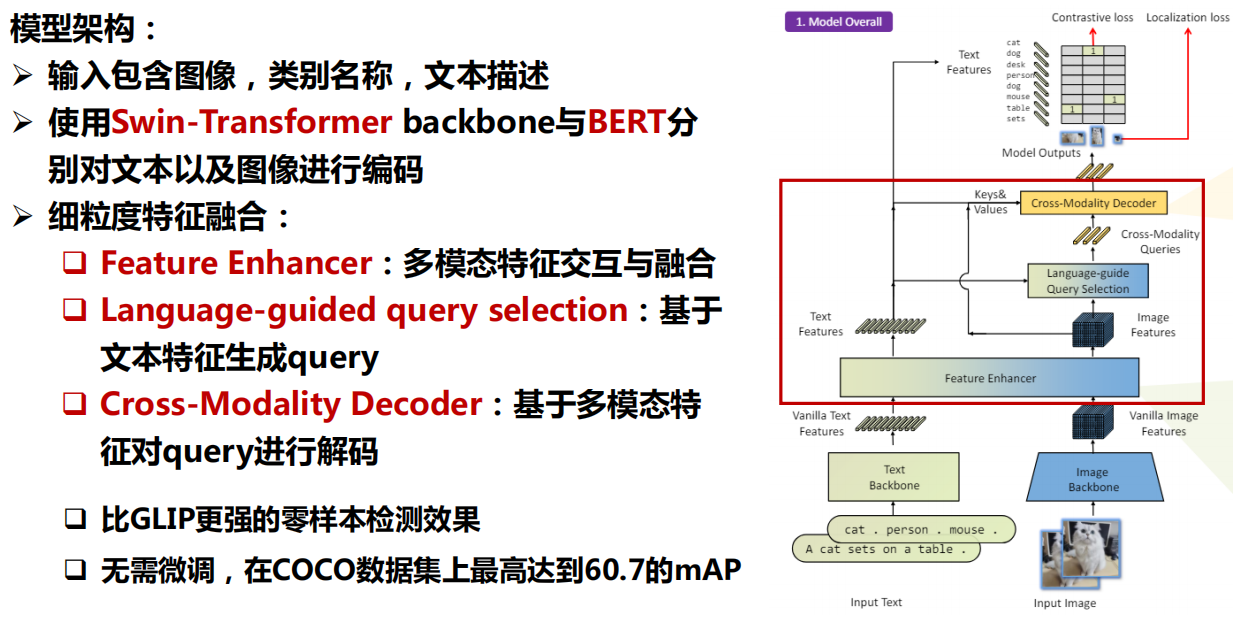
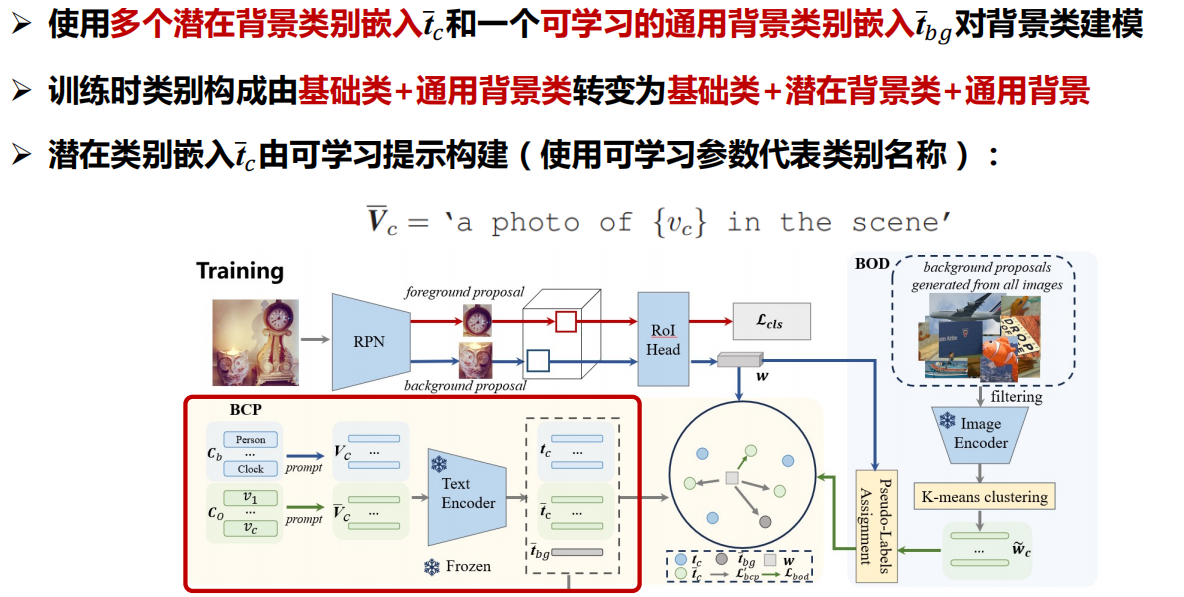
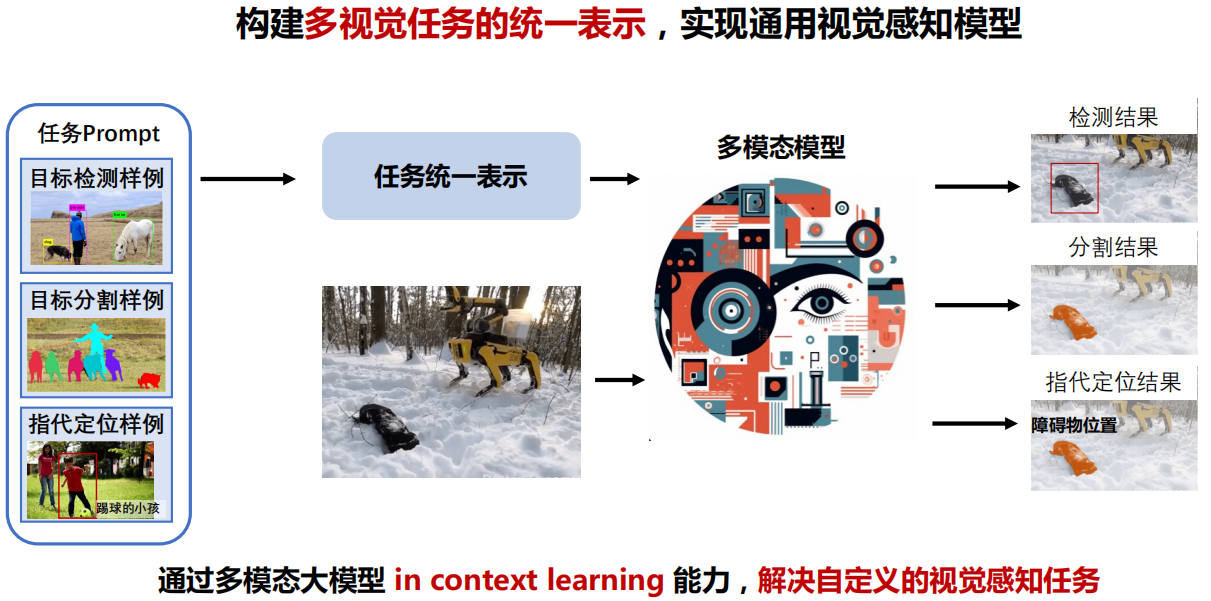
四、开放词汇分割
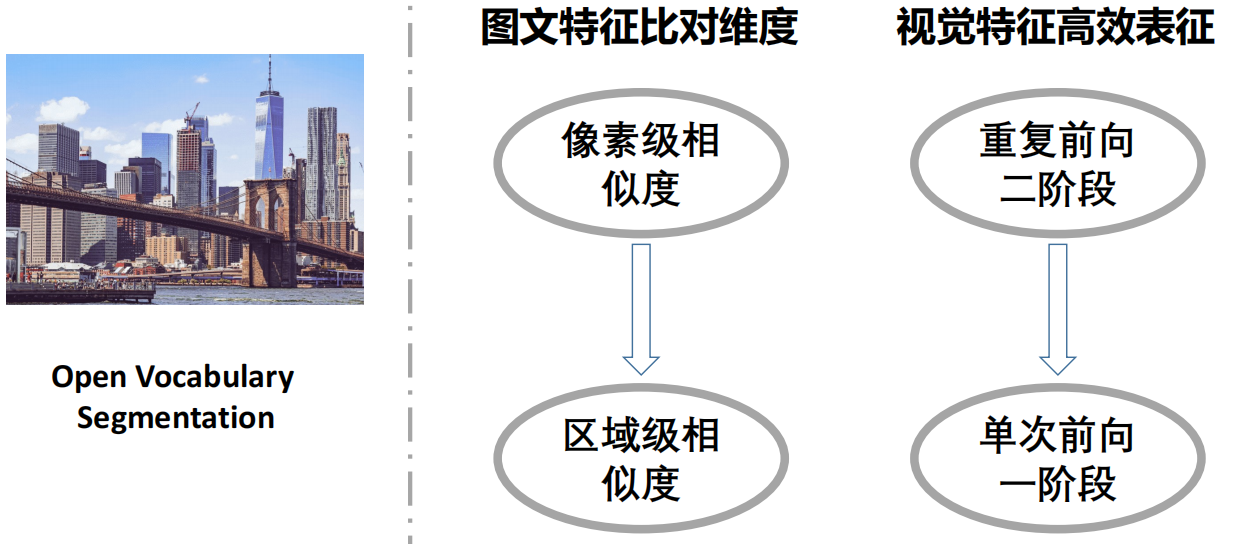


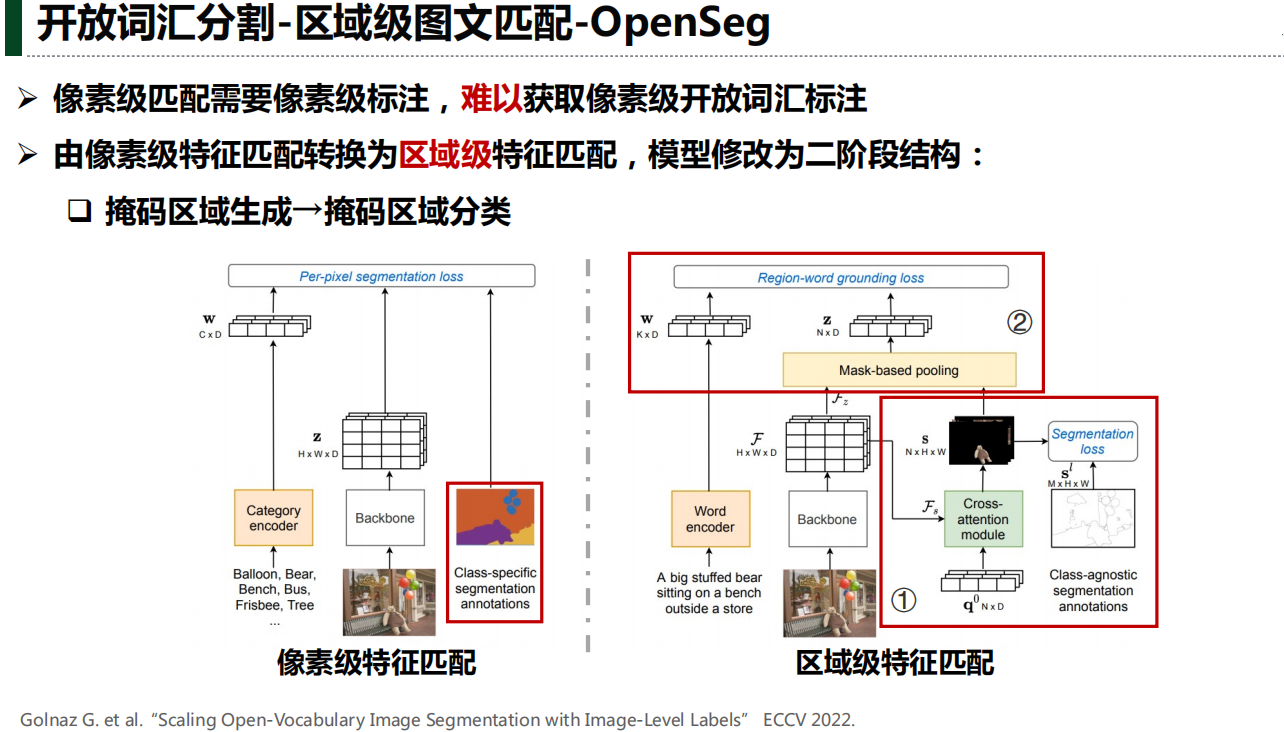
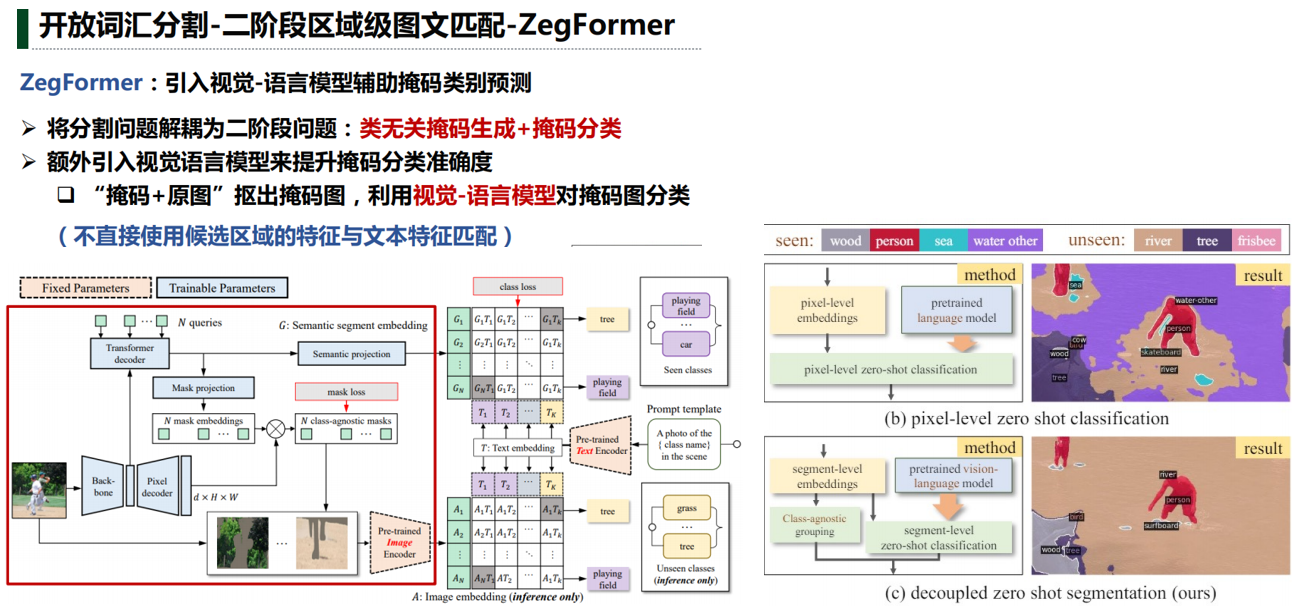
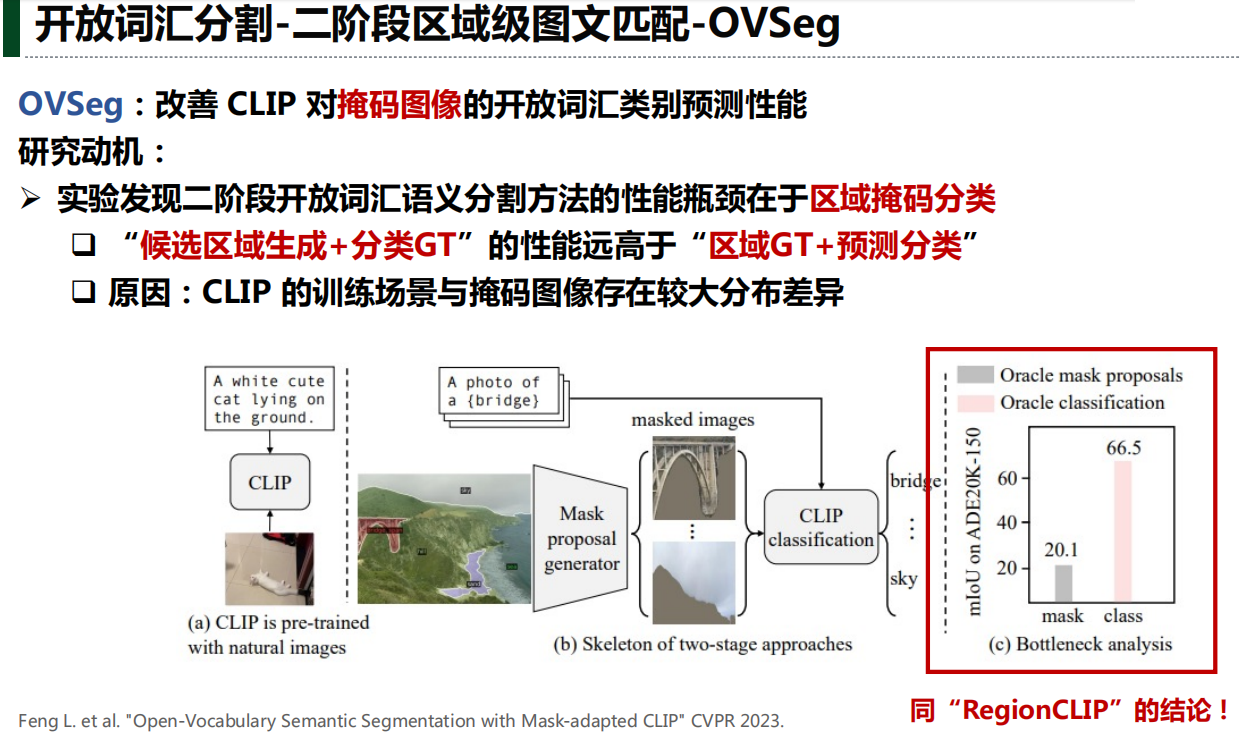
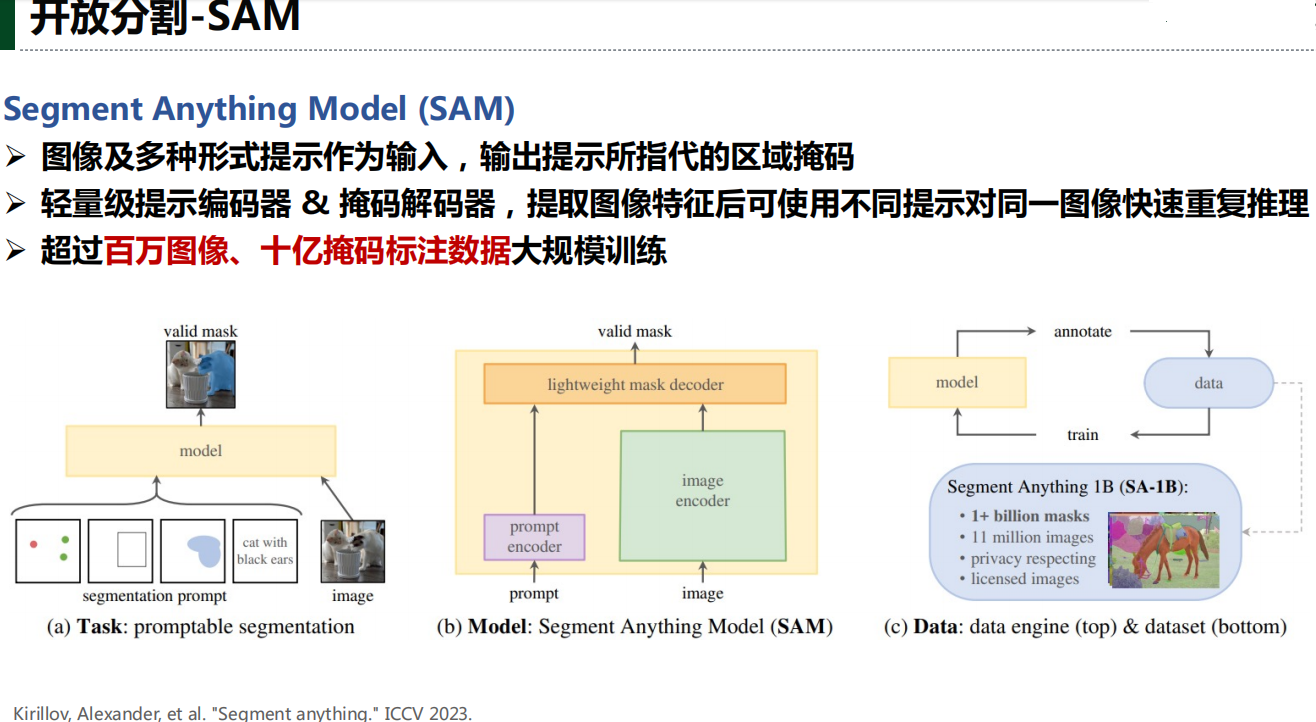
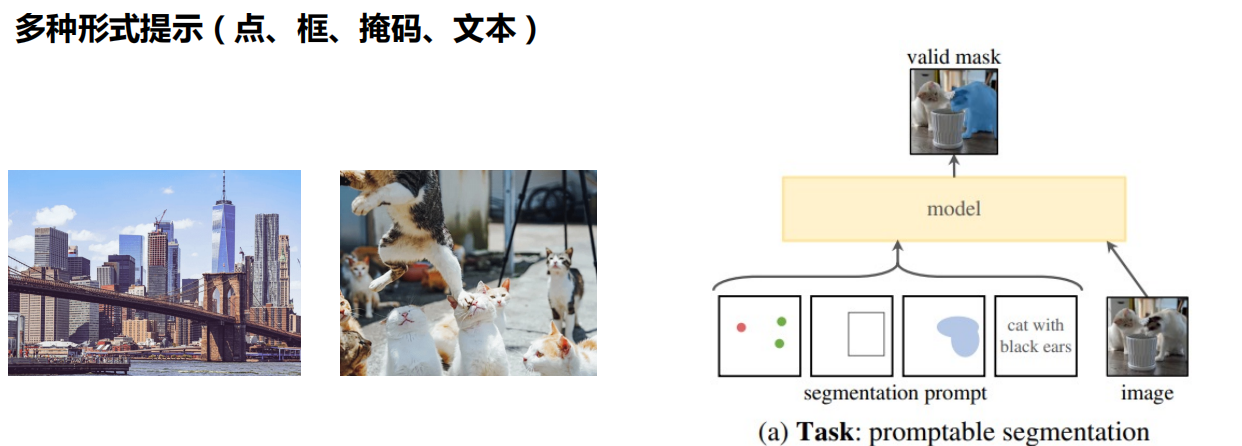
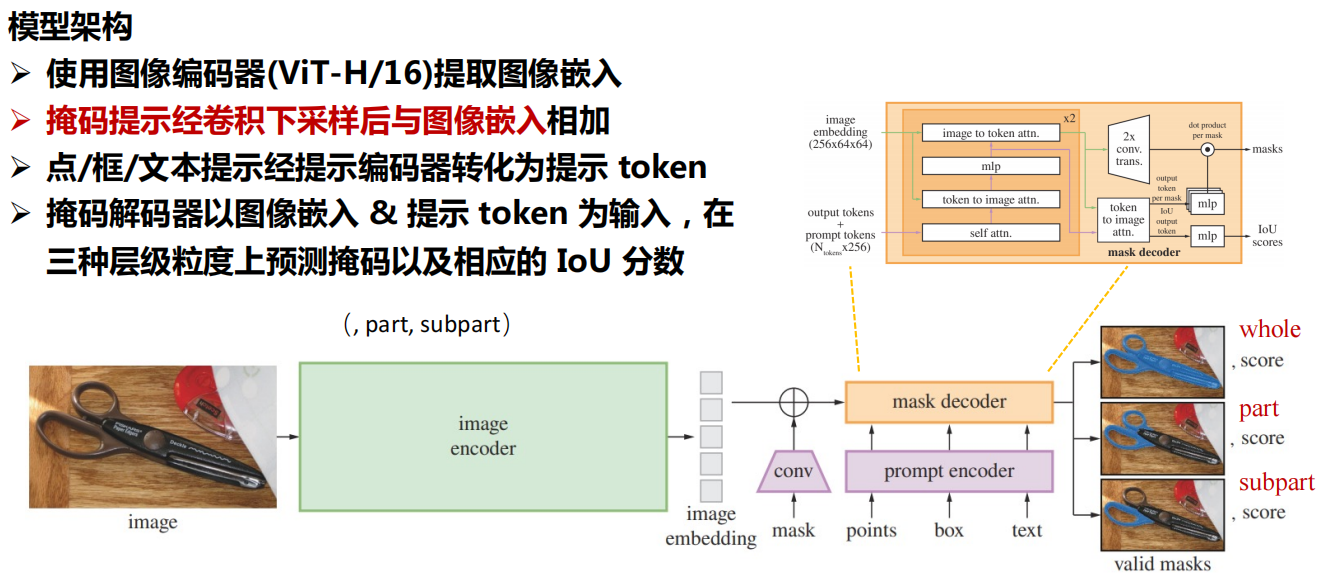
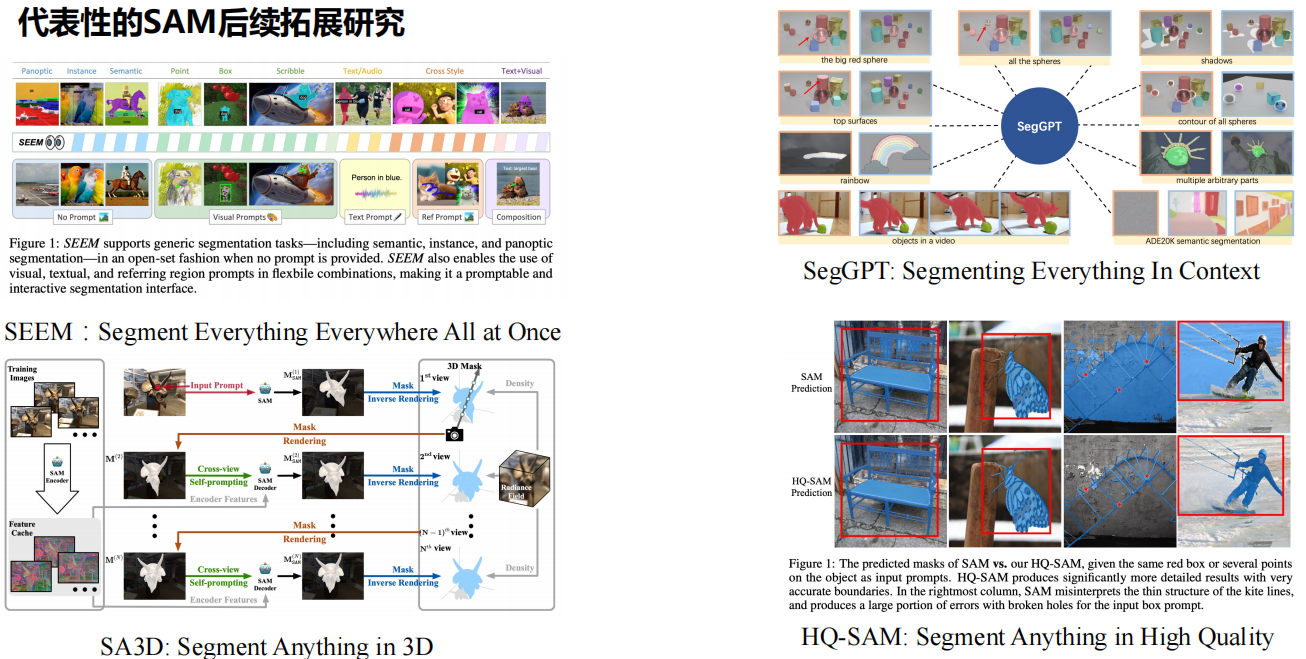
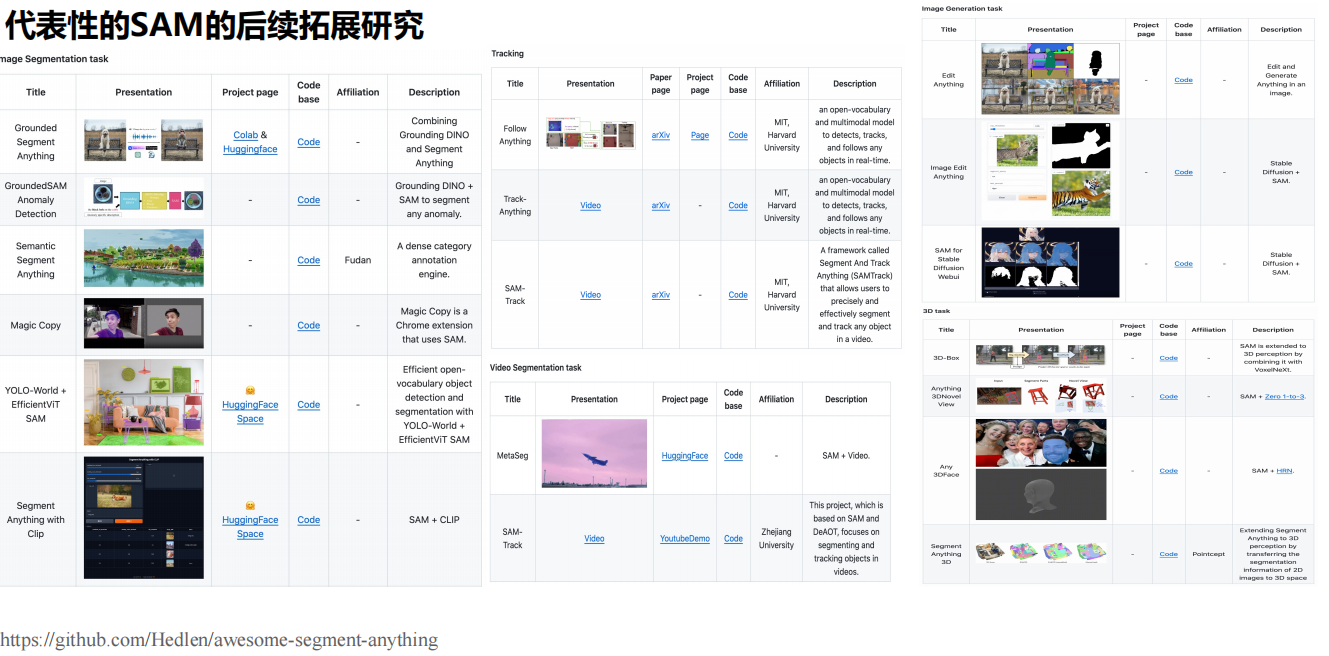
五、下游任务应用


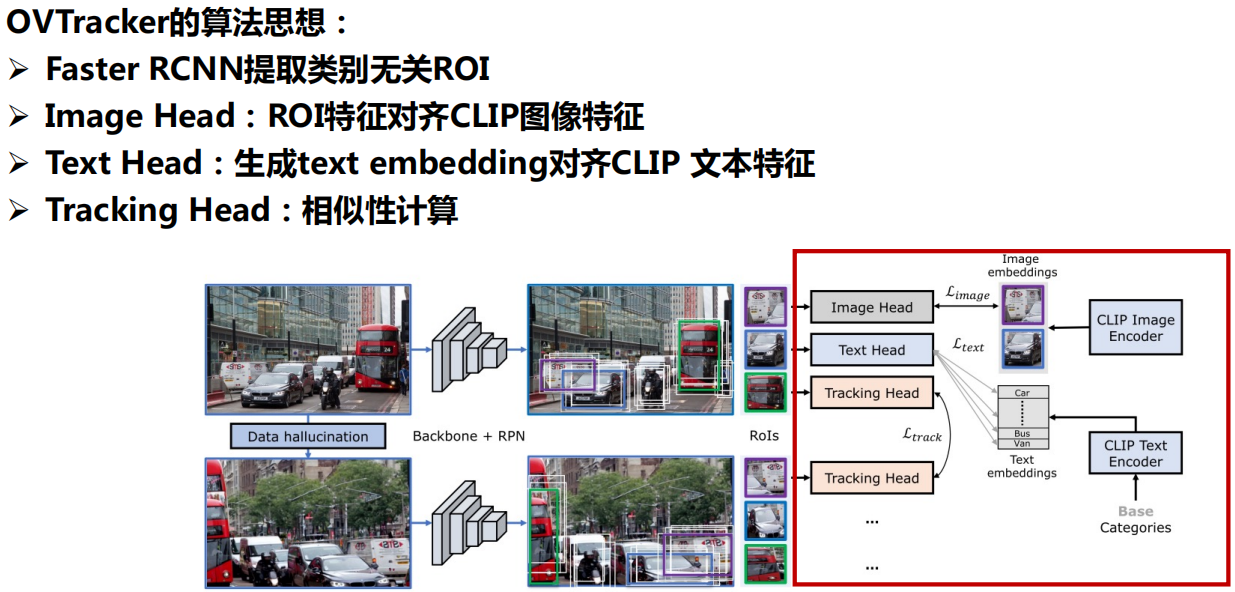


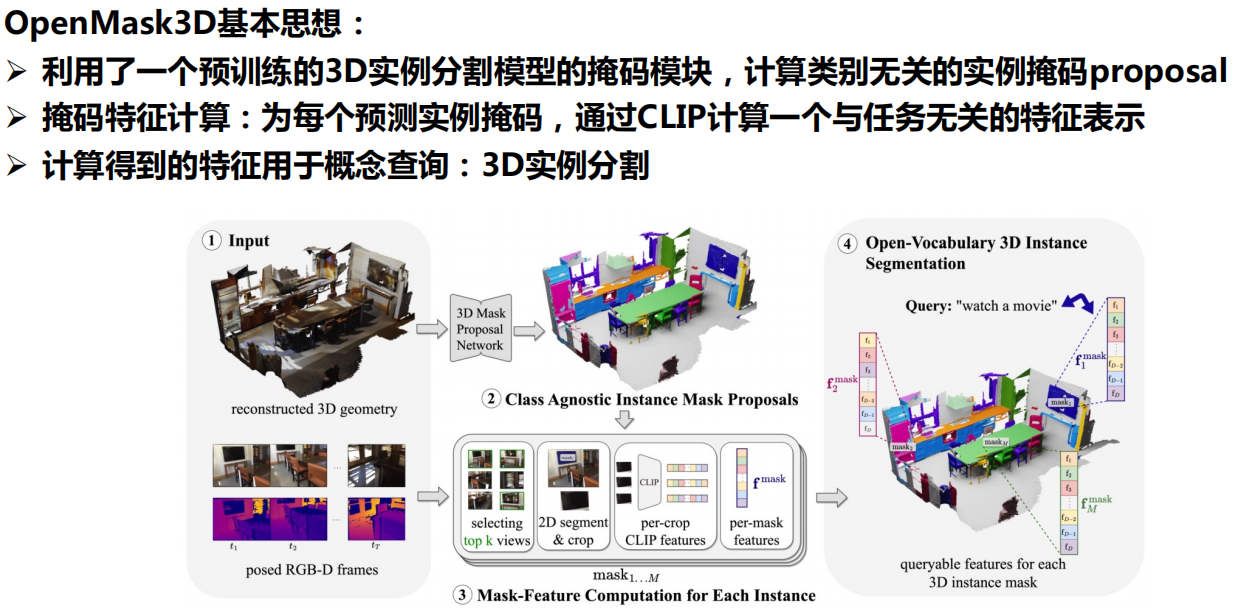


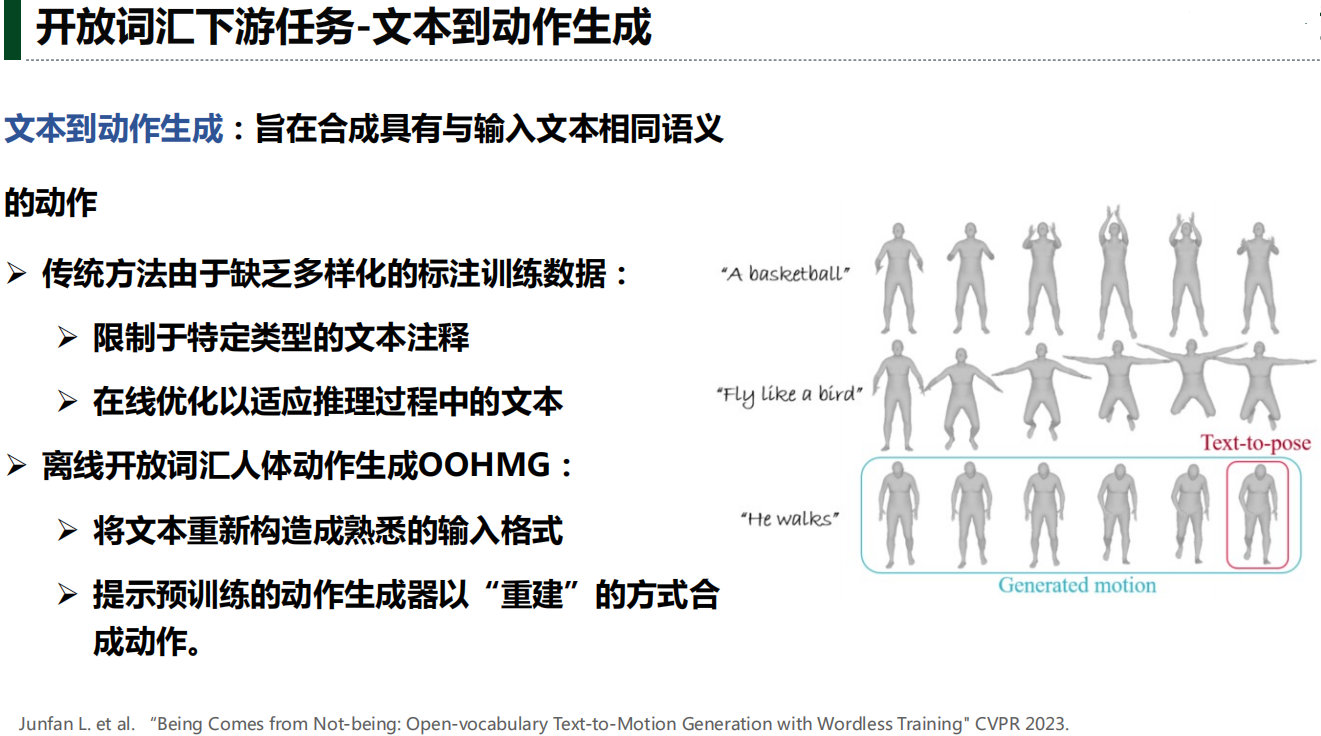
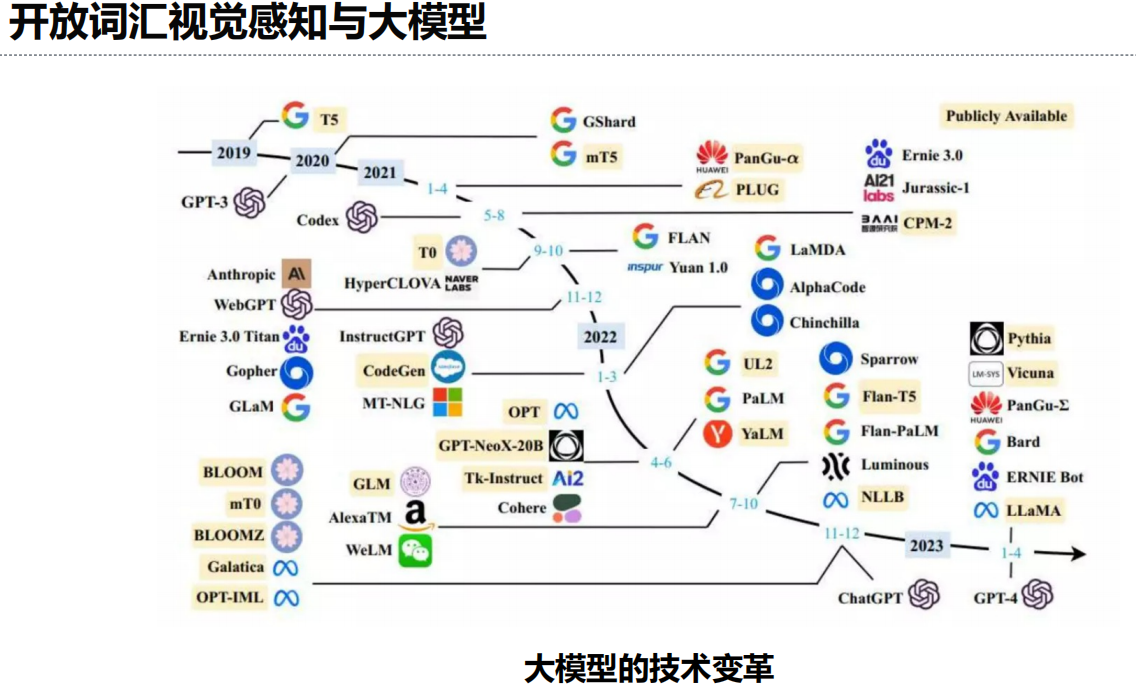
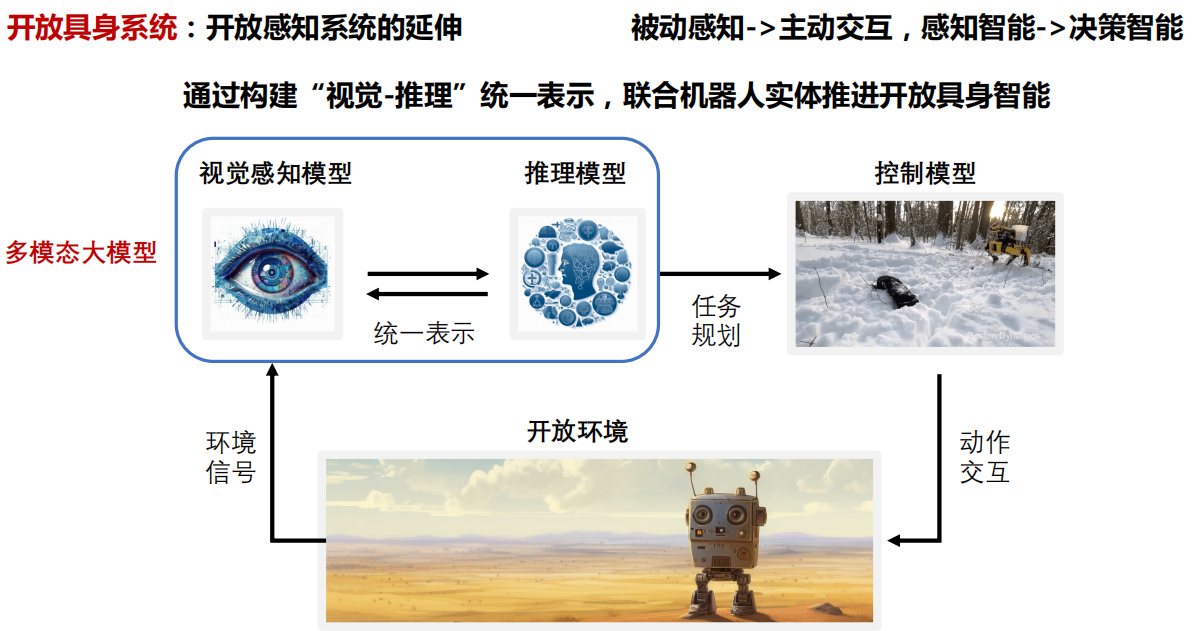
六、多模态大模型
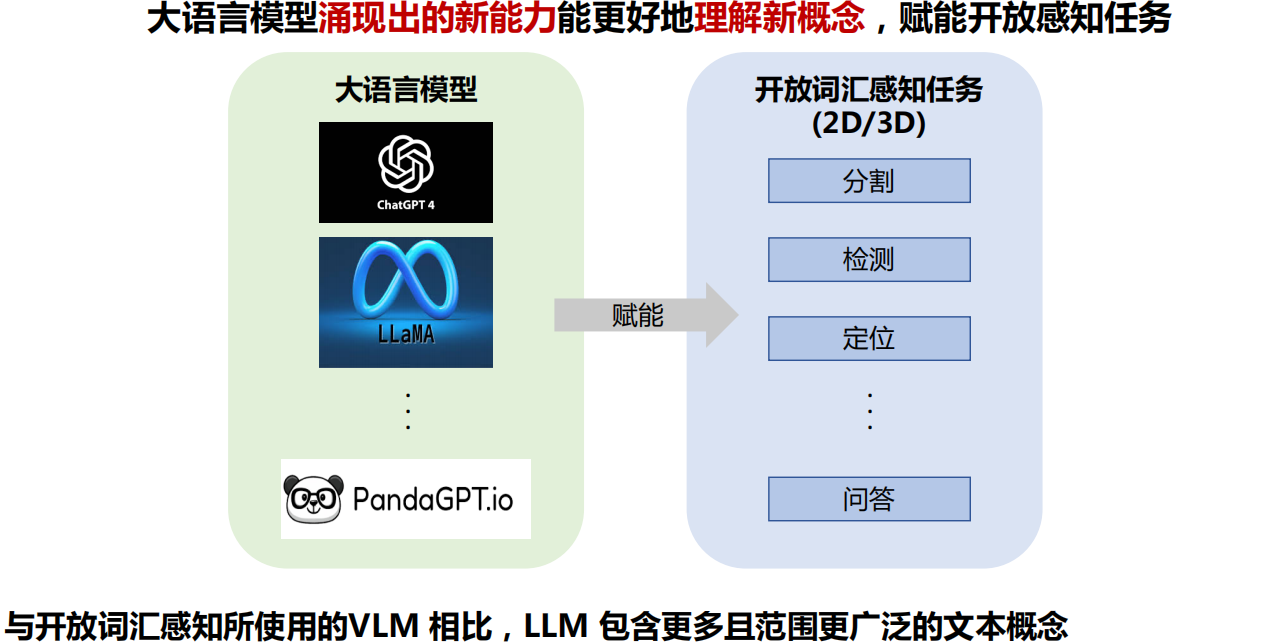
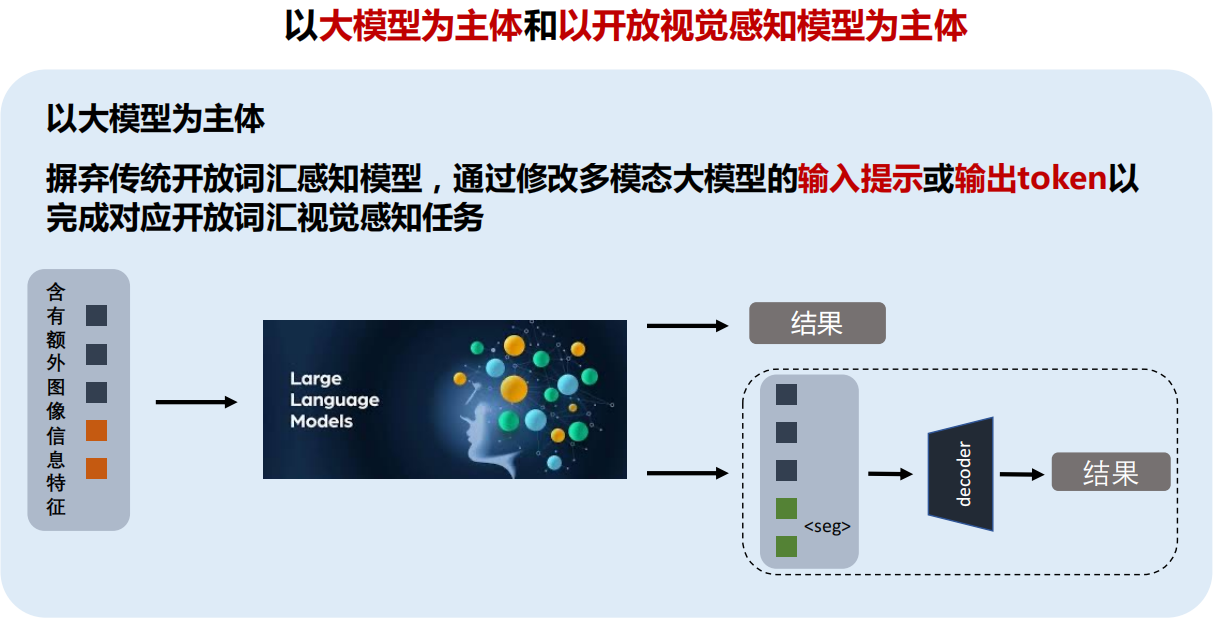
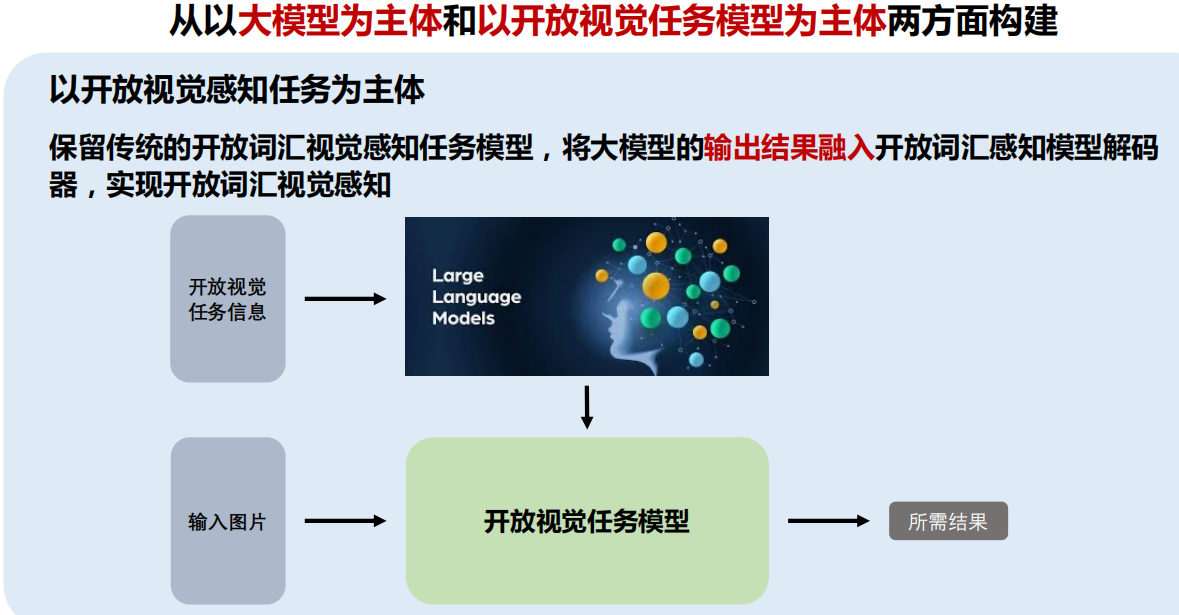

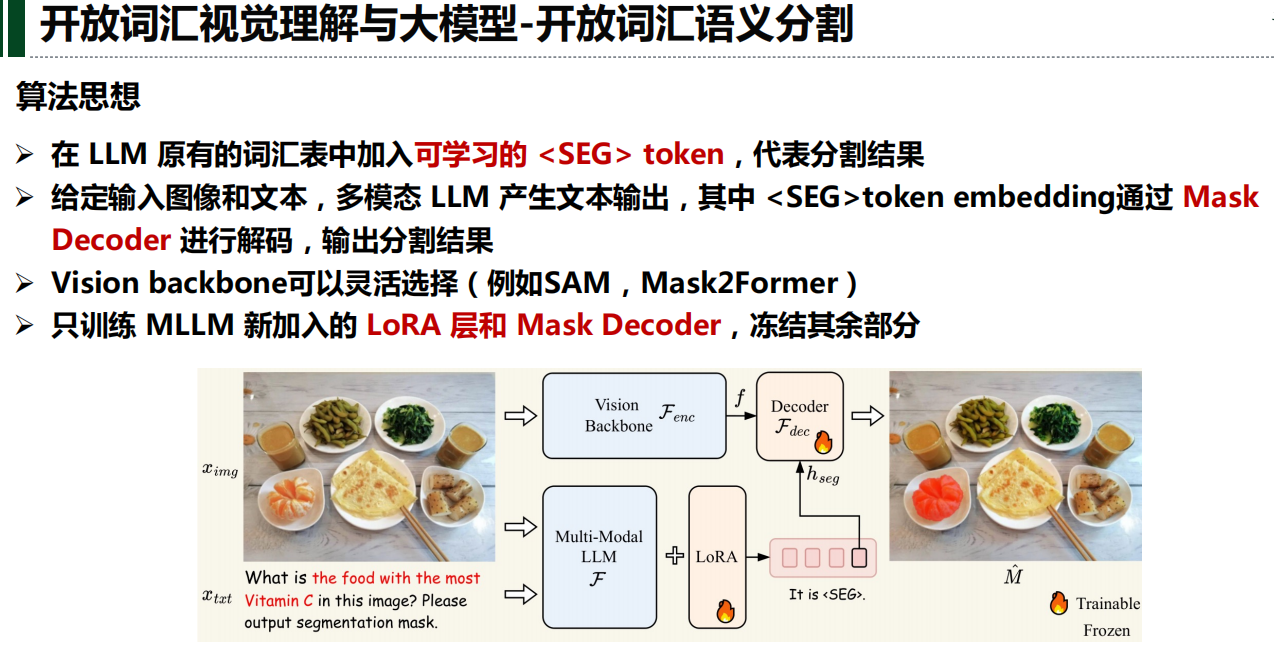
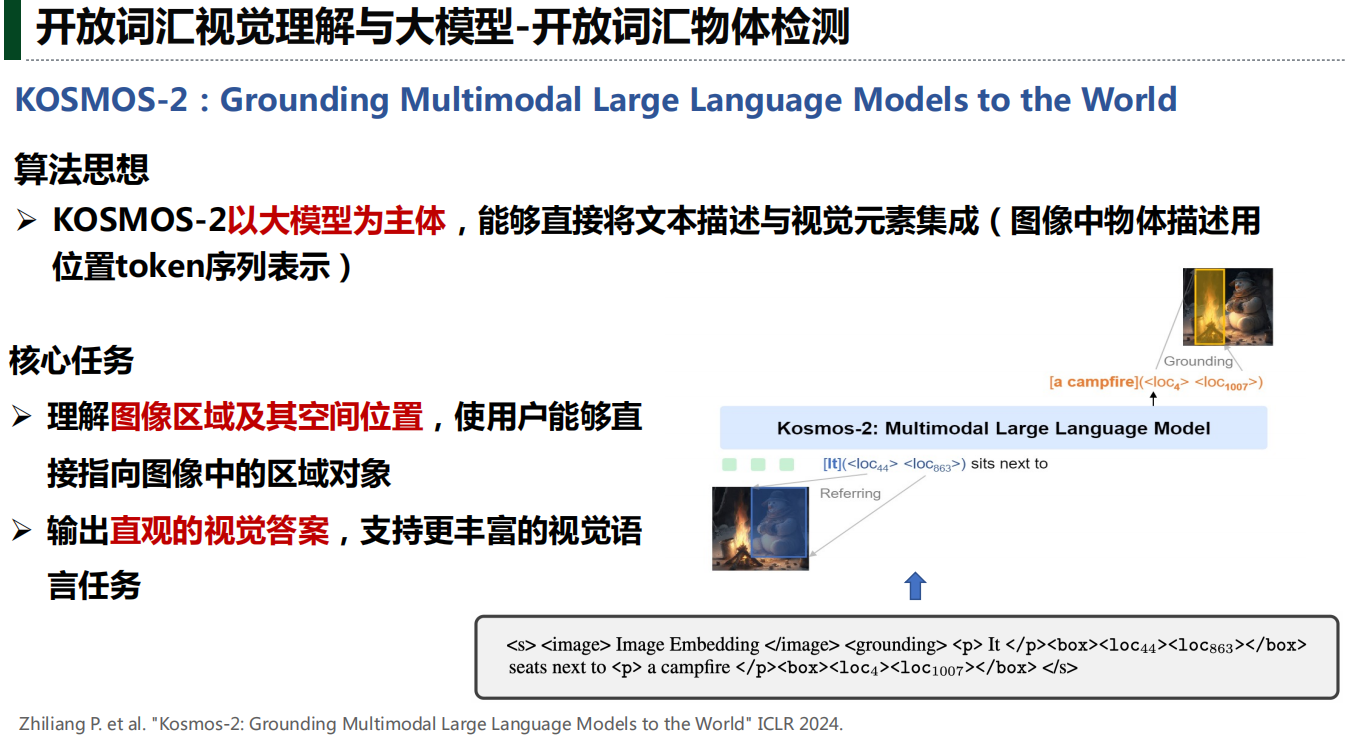
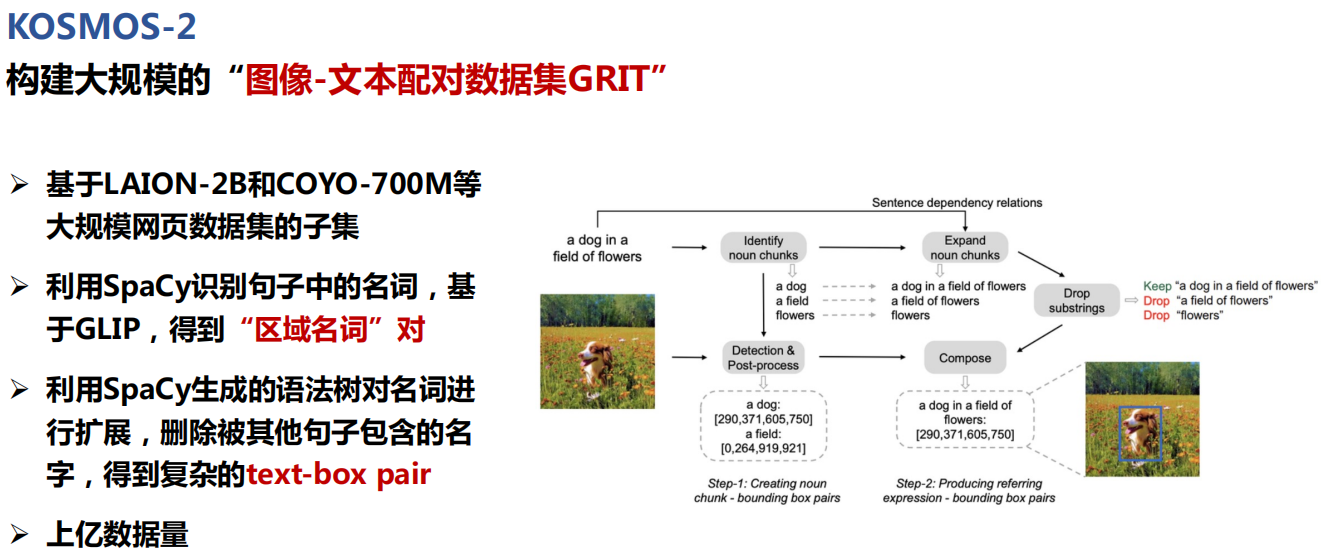
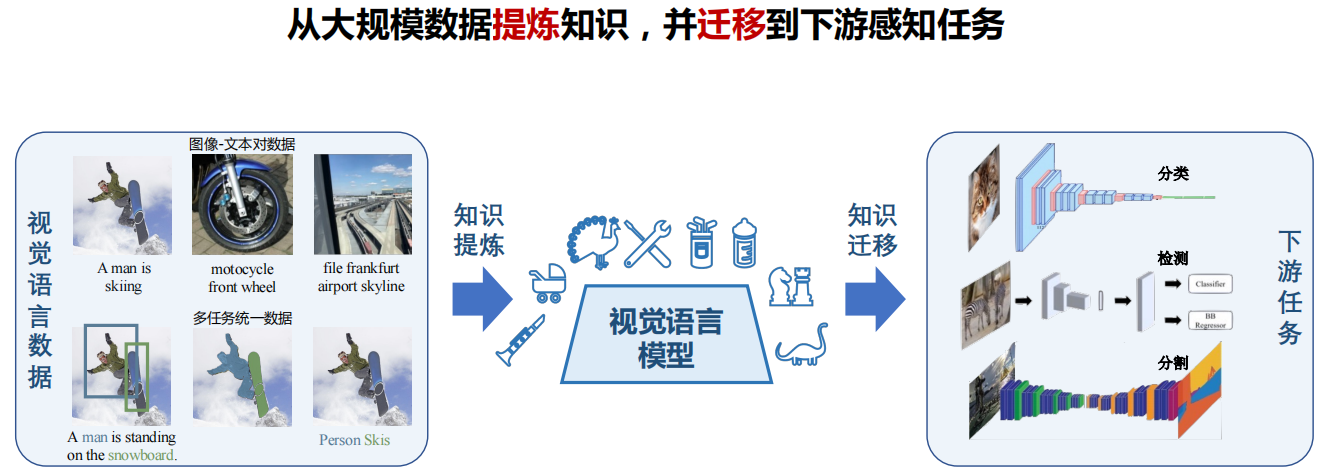
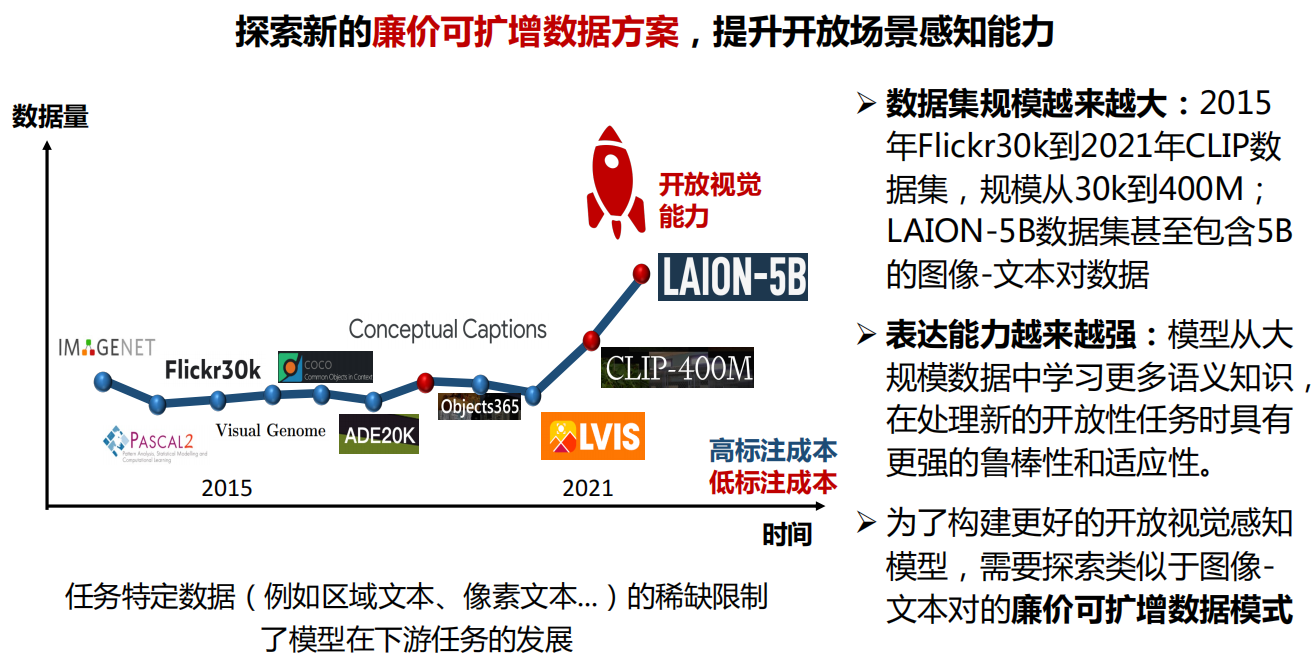
七、总结与展望


Tutorial 2:NeRF和3DGS
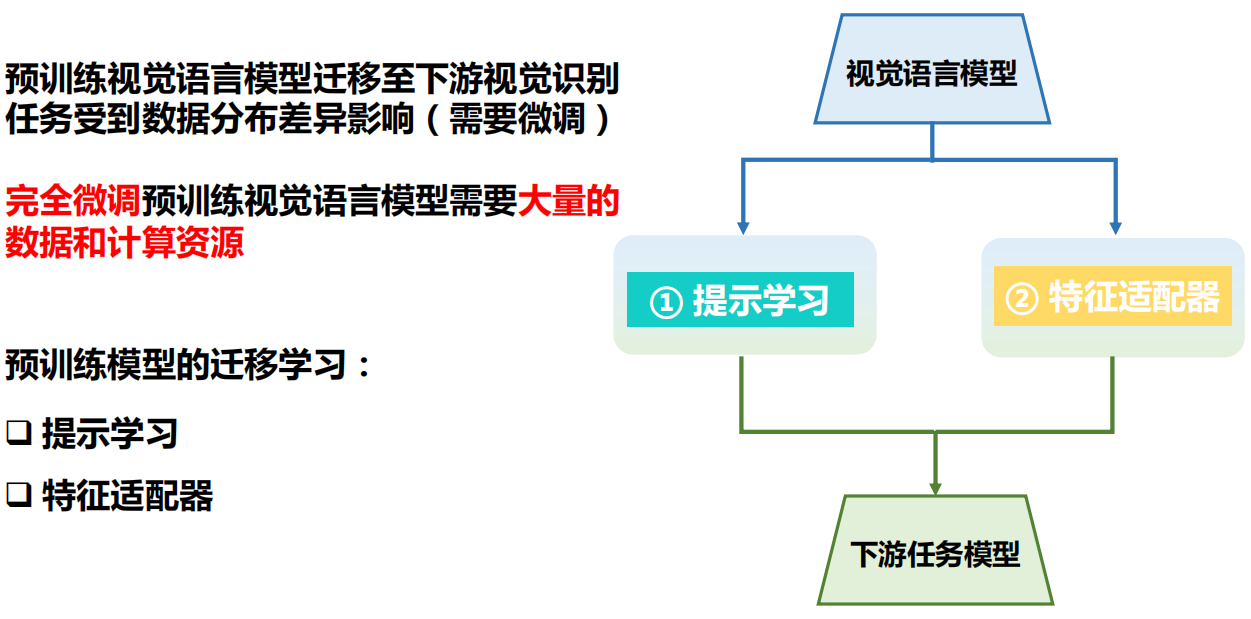
workshop0:视觉大模型高效迁移

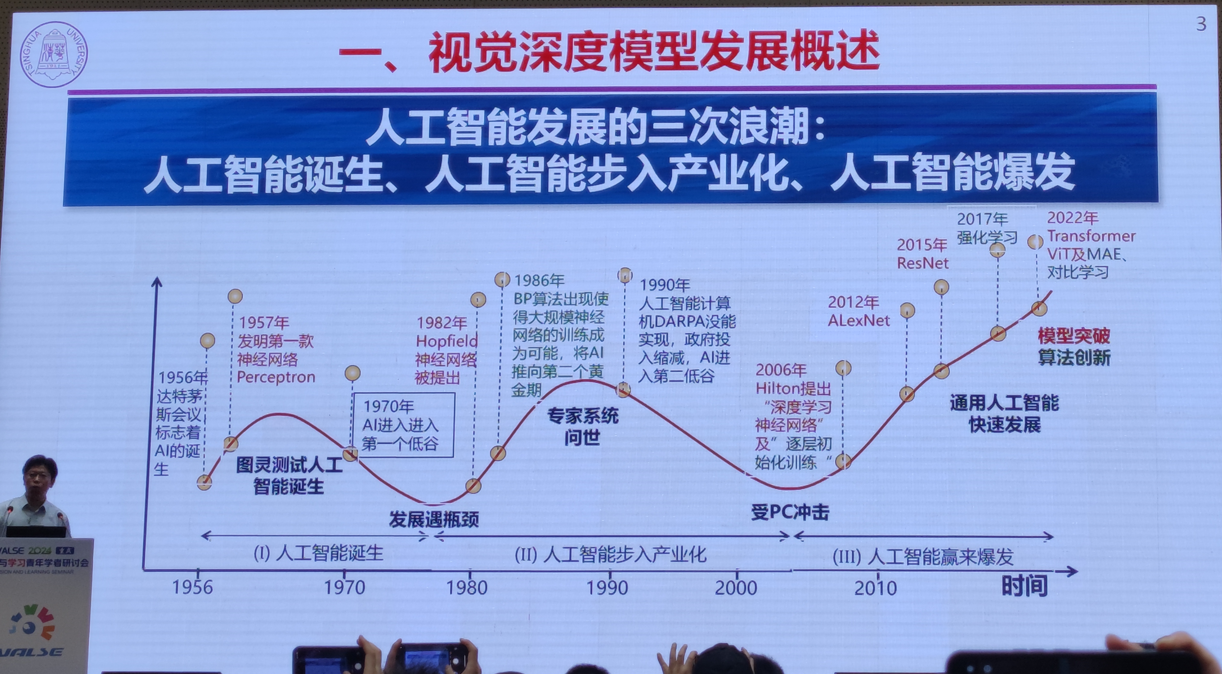
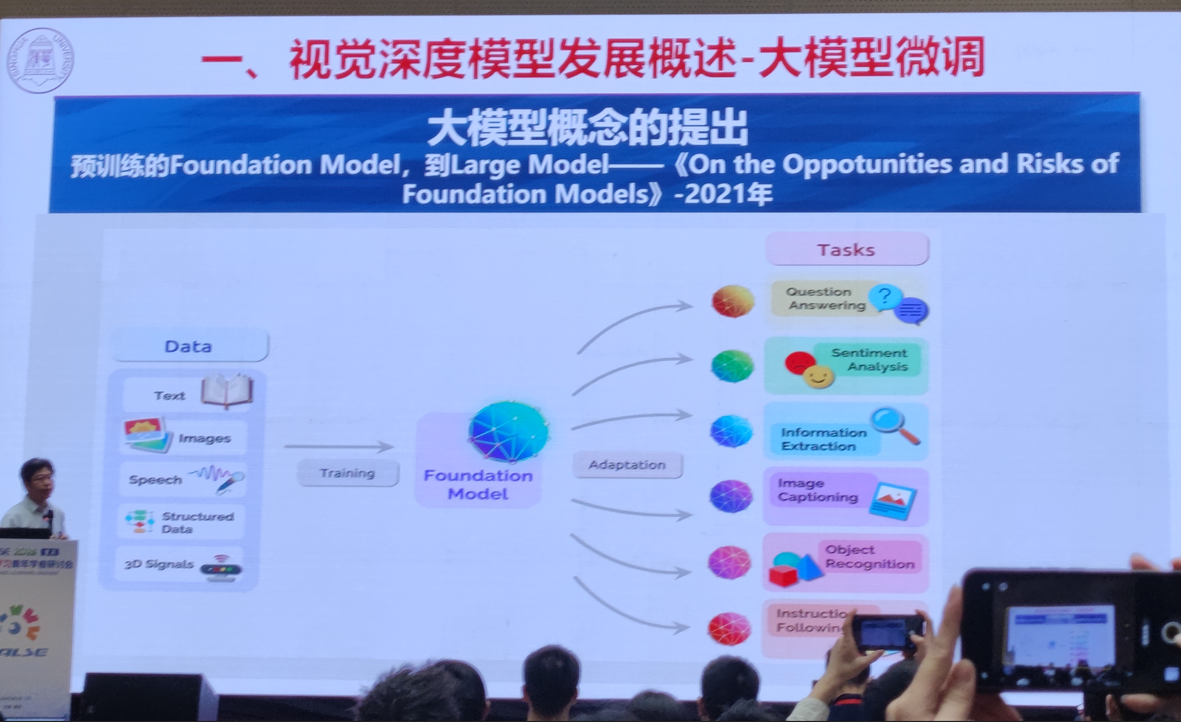
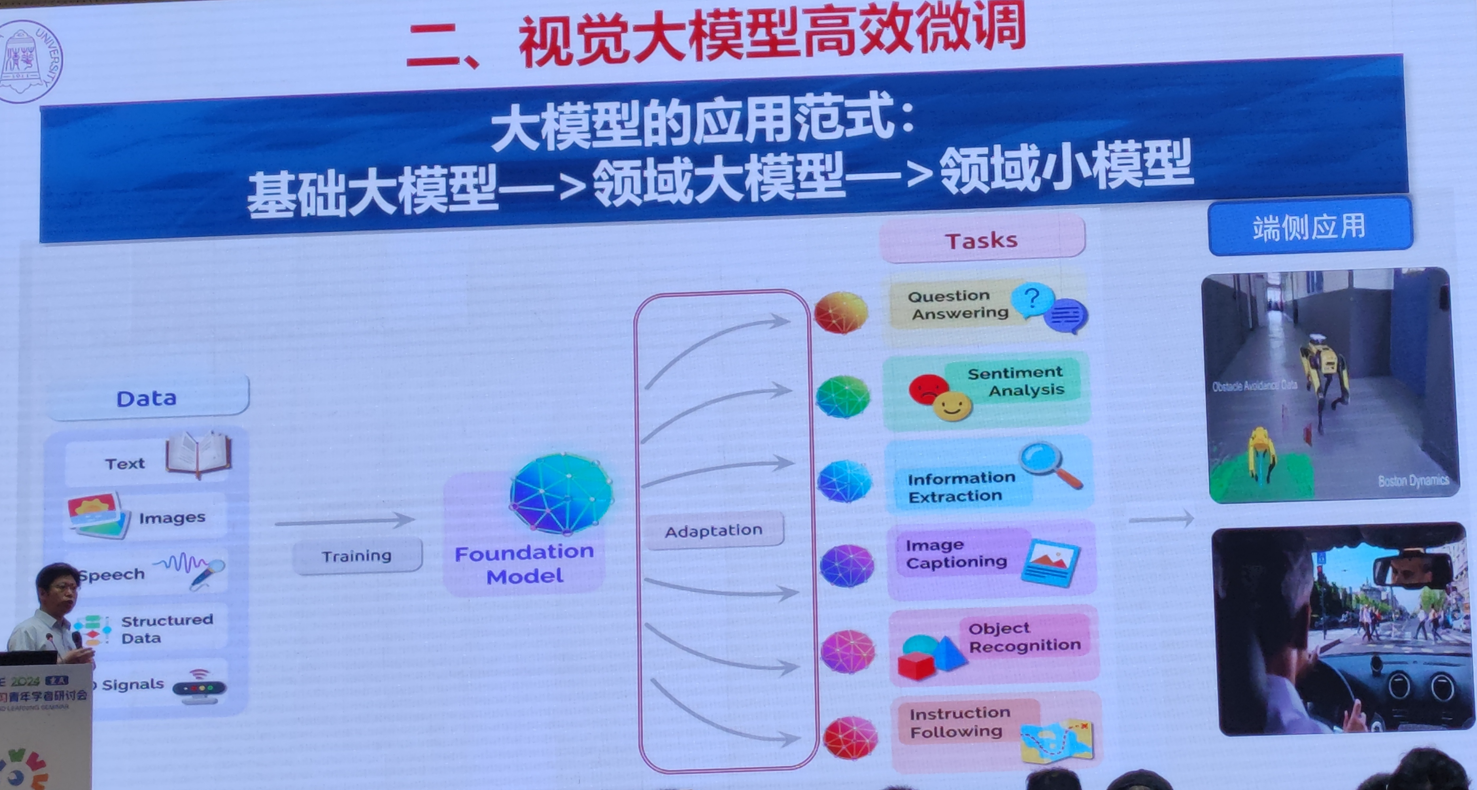
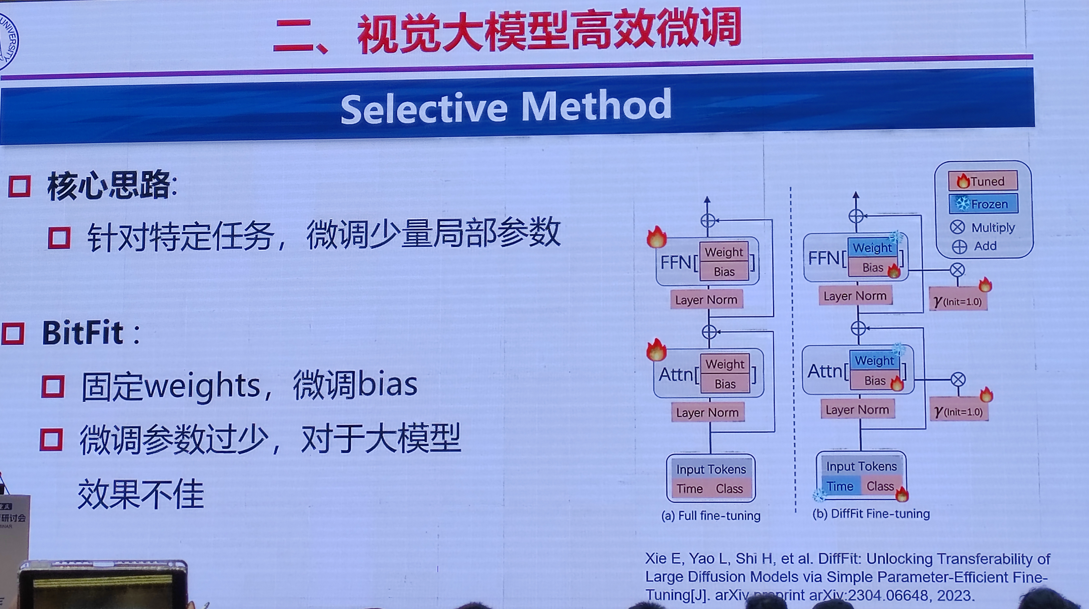
1.视觉大模型微调与轻量化结构设计技术
清华大学 丁贵广






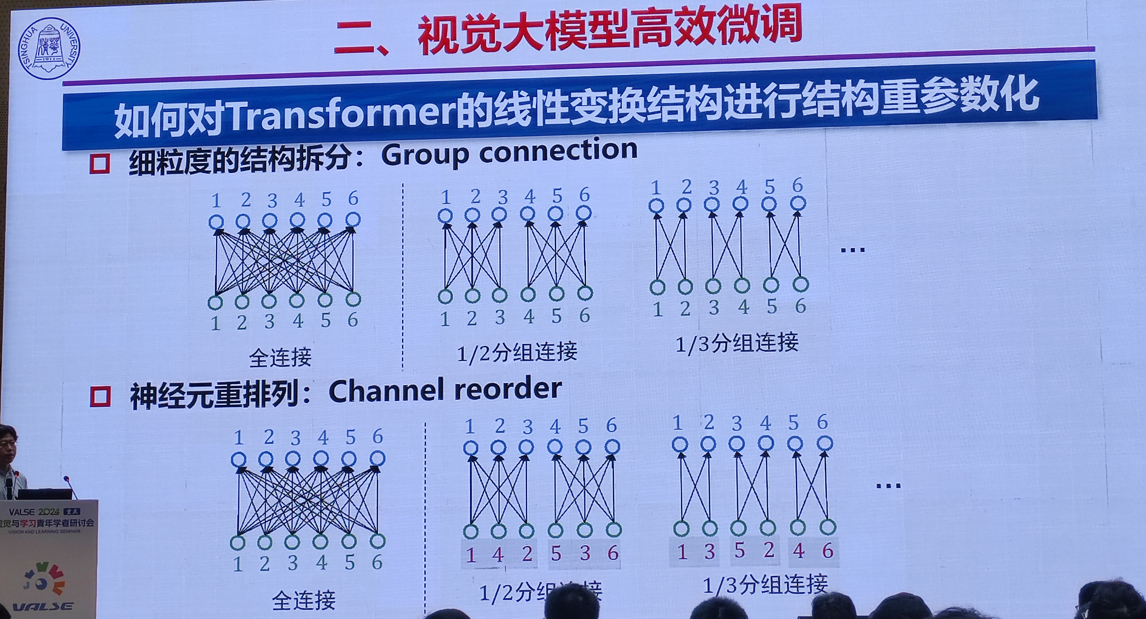

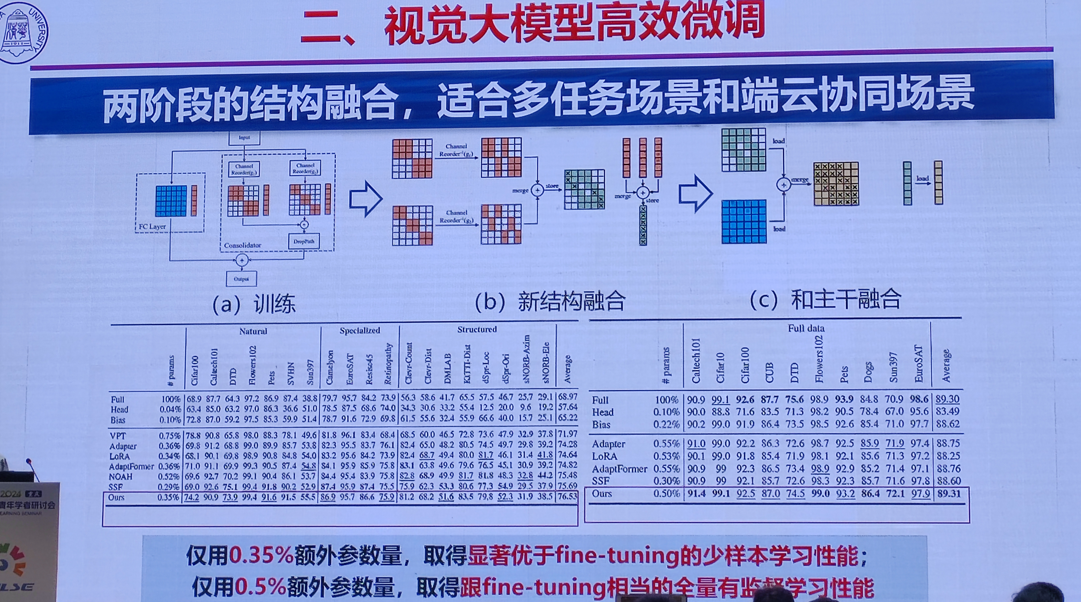
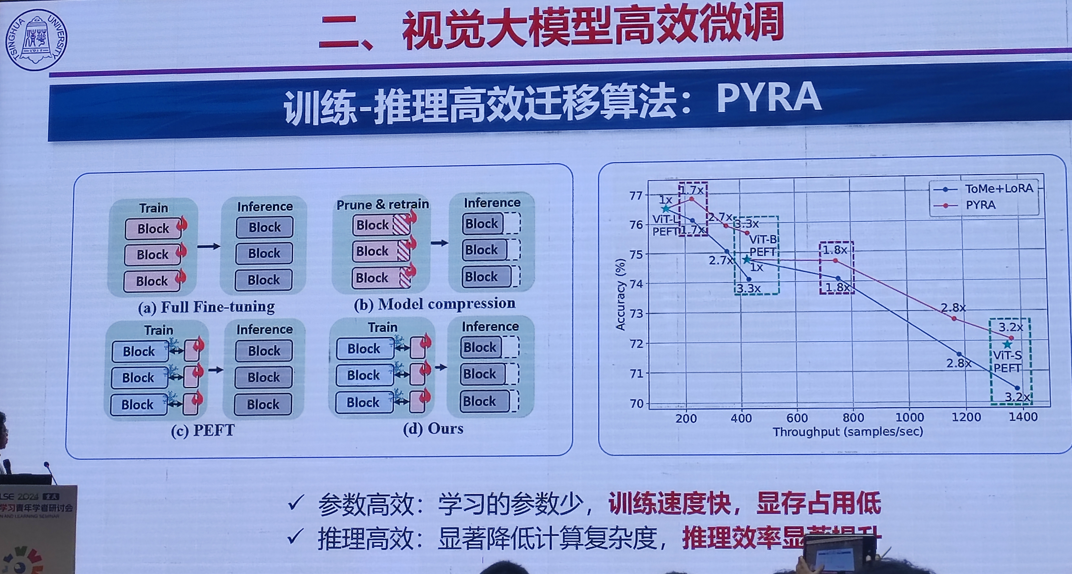
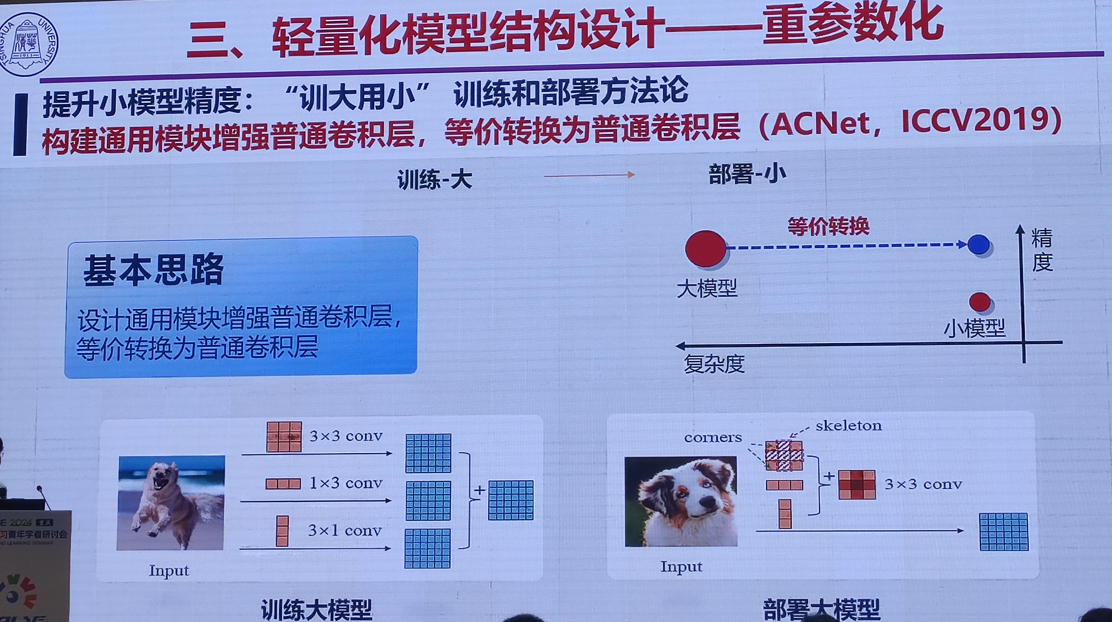
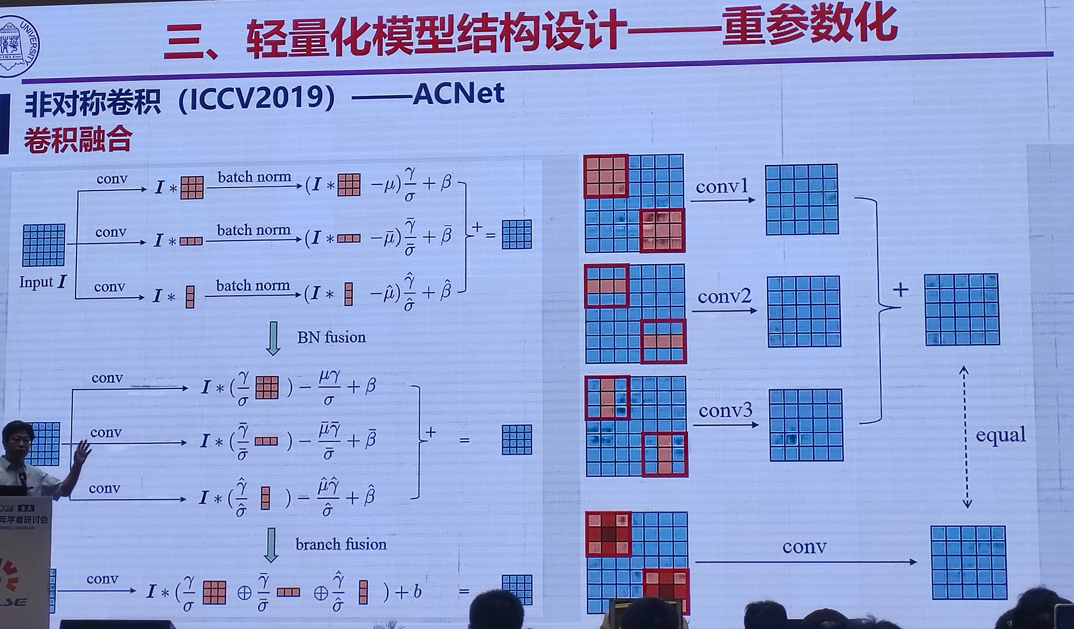
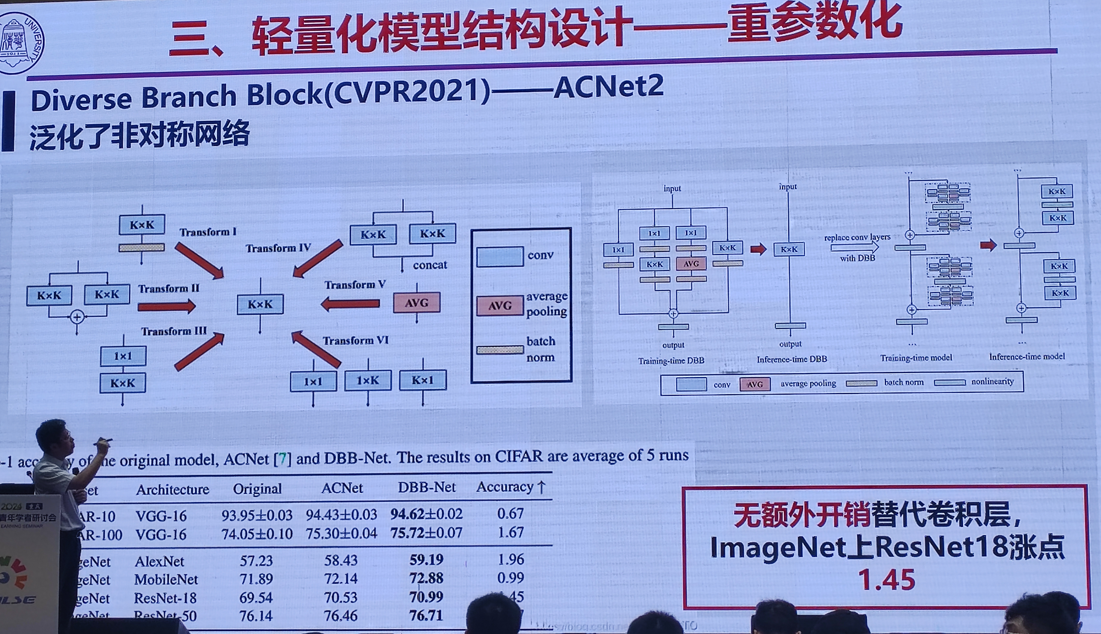
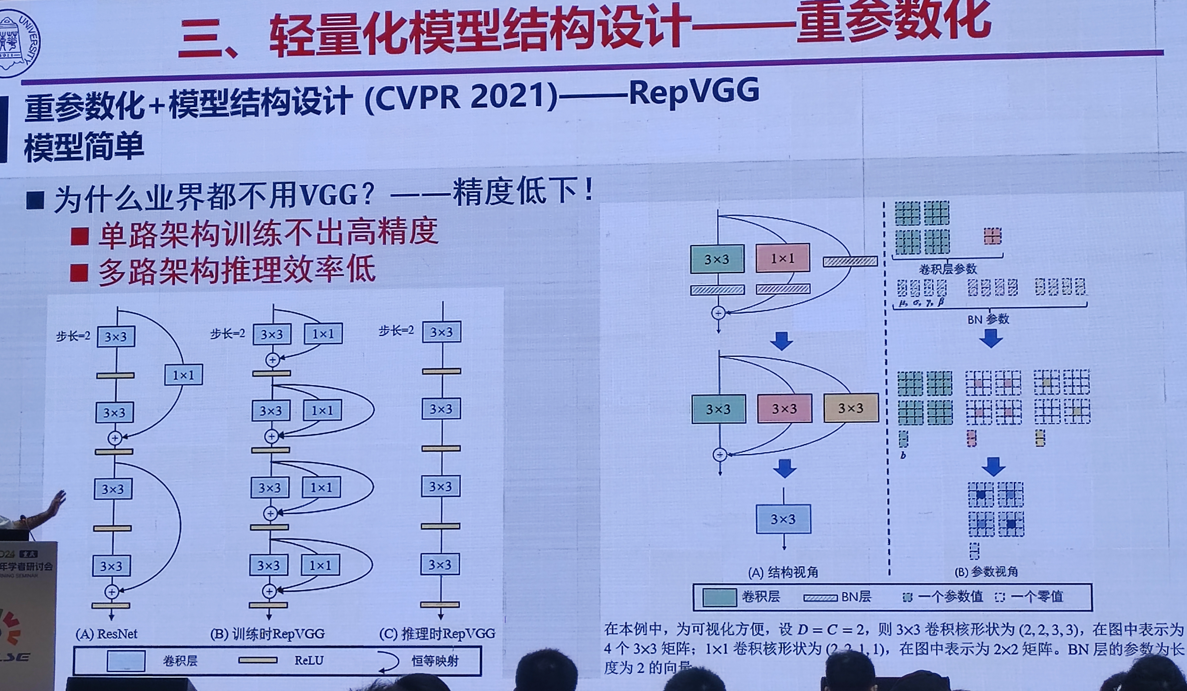
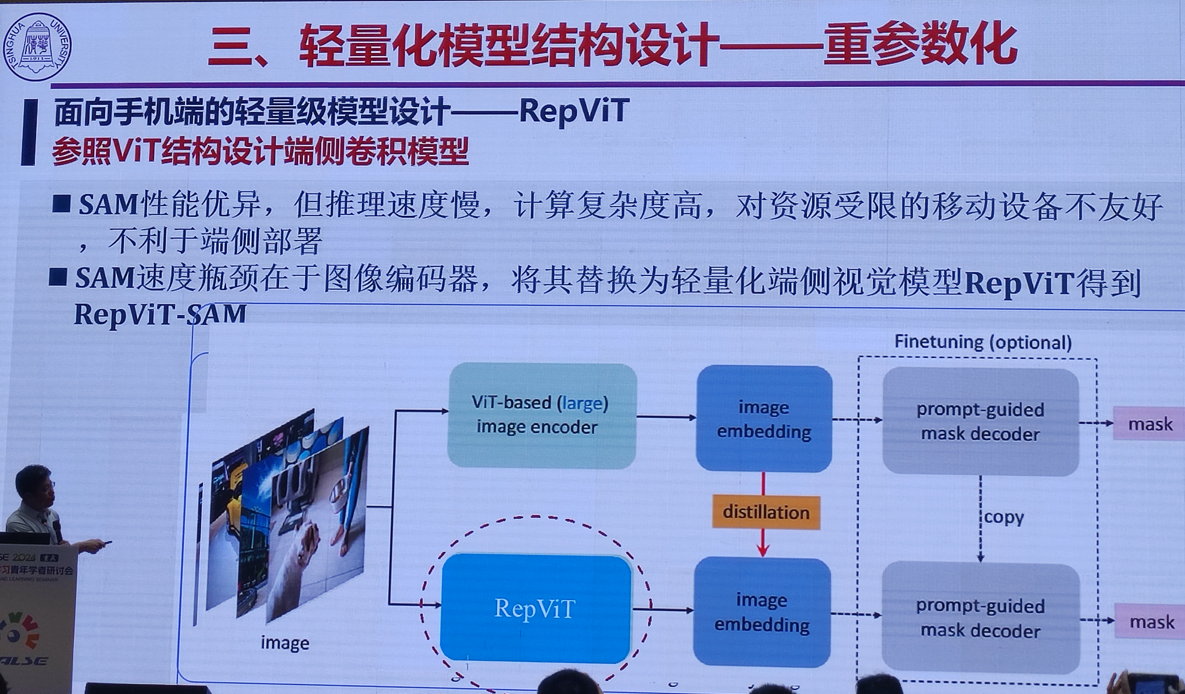


2.高效能个性化图像生成
程明明 南开大学

workshop1:艺术智能
需要完整课件的可私信
1.从计算人文到计算电影Al时代电影研究的新范式
薄一航-北京电影学院美术学院





















2.绘画中的AI
董未名-中国科学院自动化研究所


























3.人工智能的舞蹈创作与情感融入
姚鸿勋-哈工大



















4.智能艺术与创新设计—智能篆刻
张克俊-浙大





























workshop 2:三维重建与生成
1.3DGS重建和生成-方杰民




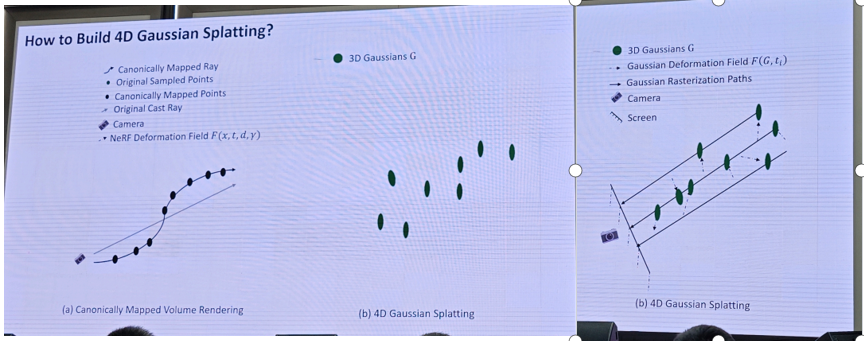
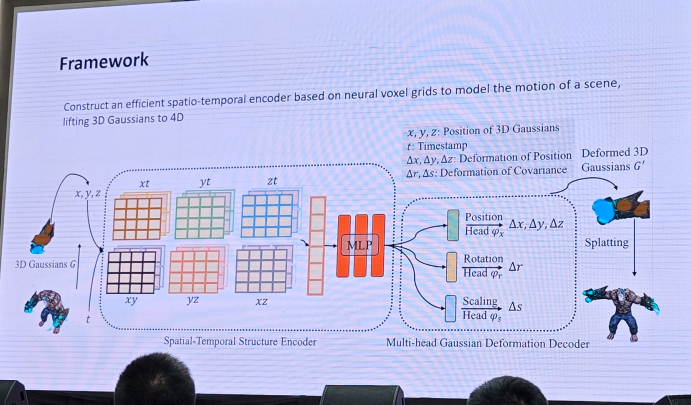

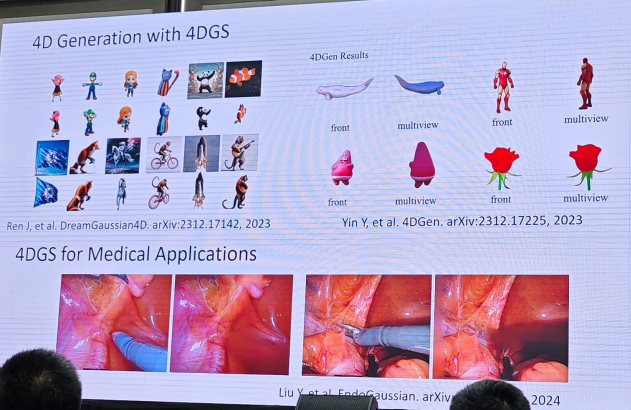

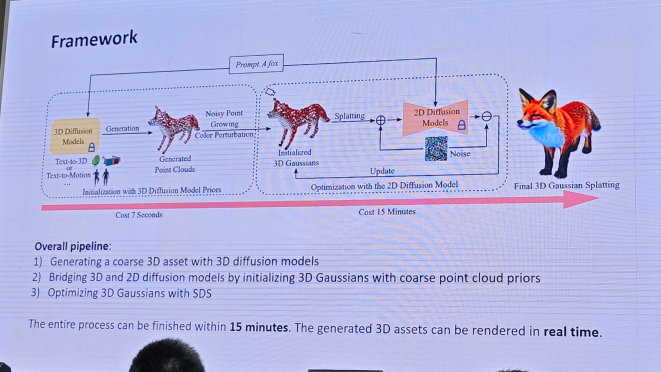


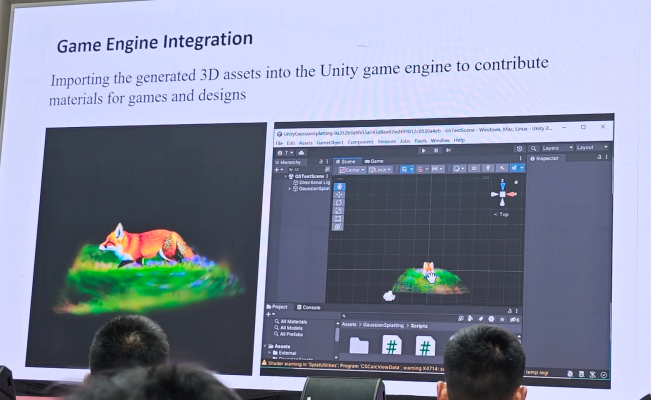

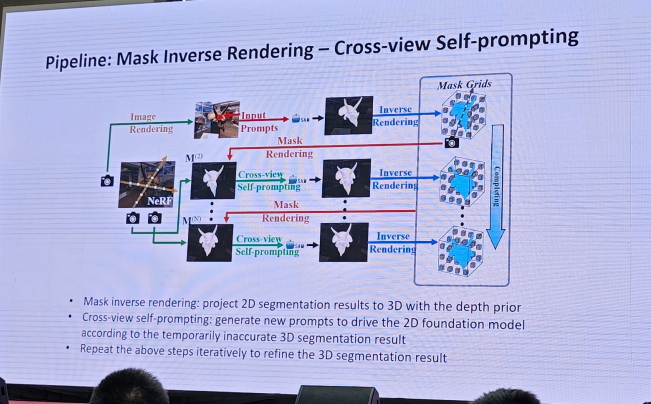

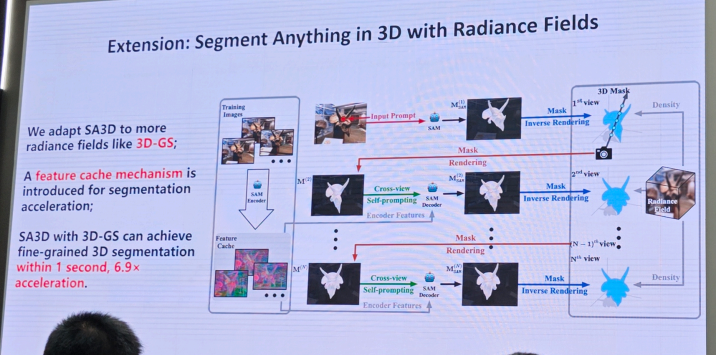


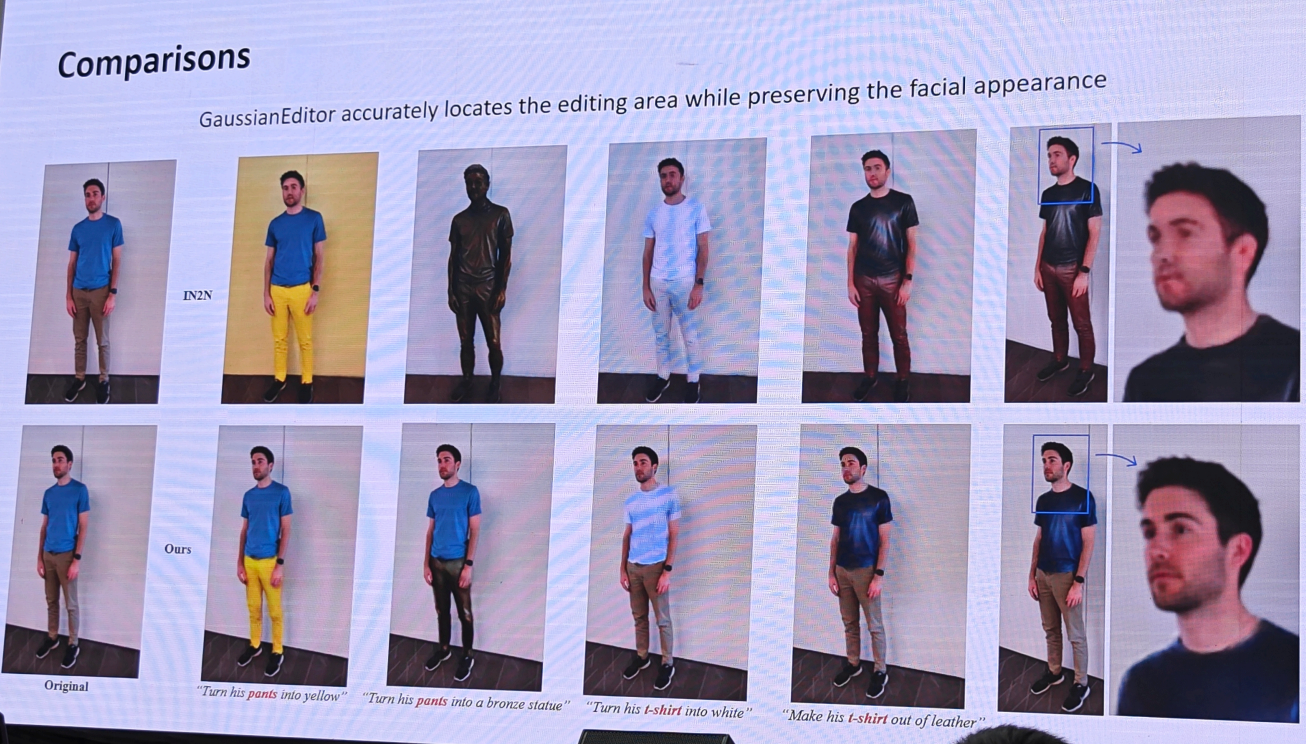


2.自动驾驶-廖依依
3.神经形态相机视觉计算-施柏鑫
4.激光雷达全球定位-王程
5.鲁棒可扩展的在线三维重建相机跟踪优化与地图表示学习-徐凯
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。

