
- 1八分钟就看懂 | 推荐系统 (协同过滤) 原来这么简单_协同过滤类推荐系统
- 2LibCurl HTTP部分详细介绍_libcurl设置 协议头
- 3每天看一个fortran文件(7)之寻找cesm边界层高度计算代码
- 4python实现强化学习_python中强化学习的概念
- 5头歌实践教学平台数据库原理与应用实训答案_头歌实践教学平台答案
- 6MySQL 自动根据年份动态创建范围分区_mysql 按年分区
- 7《自然语言处理的前沿探索:深度学习与大数据引领技术风潮》_采用最前沿的自然语言处理和大数据技术是什么
- 8使用Python的requests库,轻松实现网络爬虫和数据抓取_requests.models.response
- 9SQL语句,查询操作_sql 将最高工资的人和最低工资的人 查询出来
- 10Android 7.0中FileProvider
Hadoop大数据技术原理与应用-第一章初识Hadoop
赞
踩
1.1 大数据概述
1.1.1 什么是大数据
字面意思来看 大数据就是巨量的数据。
最早提出大数据概念的是麦肯锡公司,他是这样定义大数据的:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型以及价值密度低四大特征。
研究机构Gartner是这样定义大数据的:“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流转优化能力来适应海量、高增长率和多样化的信息资产。
若从技术角度来看,大数据的战略意义不在于掌握庞大的数据,而在于对这些含有意义的数据进行专业化处理,换言之,如果把大数据比作一种产业,那么这种产业盈利的关键在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”。
1.1.2 大数据的特征
一般认为,大数据主要具有以下4个特征:大量(Volume)、多样(Variety)、高速(Velocity)、价值(Value),即所谓的“4V”

-
大量(Volume)
数据规模大,数据达PB、EB级别

-
多样(Variety)
数据来源的广泛性,决定了数据形式的多样性。分为三类:一是结构化数据,例如财务系统数据、信息管理系统数据、医疗系统数据等,其特点是数据因果关系强;二是非结构化数据,例如视频、图片、音频等,其特点是数据间没有因果关系;三是半结构化数据,例如HTML、文档、邮件、网页等,其特点是数据间因果关系弱。有统建显示,目前结构化数据占互联网数据量的75%以上,而产生价值的数据,往往是非结构化数据。 -
高速(Velocity)
数据的增长速度和处理速度是大数据高速性的重要体现。与以往的报纸、书信等传统数据载体不同,在大数据时代,大数据的交换和传播主要通过互联网和云计算等方式实现,其产生和传播速度非常迅速。另外,数据的响应速度非常快,数据的输入,处理与丢弃必须立刻见效,几乎无延迟 -
价值(Value)
大数据的核心特征是价值,其实价值密度的高低和数据总量的大小是成反比的,即数据
价值密度越高数据总量越小,数据价值密度越低数据总量越大。任何有价值的信息的提取
依托的就是海量的基础数据。当然目前大数据背景下有个未解决的问题,如何通过强大的
机器算法更迅速地在海量数据中完成数据的价值提纯。
1.2 大数据的应用场景
1.2.1 医疗行业的应用
- 优化医疗方案,提供最佳治疗方法
- 有效预测预防疾病
1.2.2 金融行业的应用
- 构建用户画像,精准营销。
- 风险管控
- 决策支持
- 服务创新。改善与客户之间的交互、增加用户粘度
- 产品创新。有效对接银行、保险、信托、基金等各类金融产品
1.2.3 零售行业的应用
- 精准定位零售行业市场
- 支撑行业收益管理
- 挖掘新零售行业新需求
1.3 Hadoop 概述
1.3.1 Hadoop 的前世今生
Google 为了解决存储容量、读写速度、计算效率等问题,提出了以下三种大数据的处理手段:
- MapReduce : 开源分布式并行计算框架;
- BigTable: 大型的分布式数据库
- GFS: 分布式文件管理系统
上述三大技术可以说是革命性的技术,表现在:
- 降低成本,能用小型PC机,就不用大型机和高端存储
- 软件容错硬件故障视为常态,通过软件保证可靠性
- 简化并行分布式计算,无须控制节点同步和数据交换
2003-2004 你那,Nutch的创始人DougCutting 受到启发,用了若干年时间实现了DFS和MapReduce机制。
2005年,Hadoop作为Lucene子项目Nutch 的一部分正式被映入Apache基金会,随后又从Nutch中剥离,称为一套完整独立的软件,起名为Hadoop。
2011年12月,Hadoop 1.0.0 版本发布
2012年5月,Hadoop 2.0.0 alpha 版本发布
2017年12月,继Hadoop 3.0.0 的4个Alpha 版本和1个Beta版本后,第一个可用的Hadoop 3.0.0 版本发布
1.3.2 Hadoop 的优势
- 扩容能力强。内存、硬盘可横向扩展
- 成本低。通过普通廉价的及其组成服务器集群来分发处理数据
- 高效率。Hadoop能够并发处理数据,并且能够在节点之间动态的移动数据,并保证各个节点的动态平衡
- 可靠性。自动维护多分数据副本,能够针对失败的节点重新分布处理
- 高容错率。打数据被发送到一个单独的节点,该数据也被复制到集群的其他节点上,这意味着故障发生时,存在另一个副本可供使用
1.3.3 Hadoop的生态体系统

- 分布式存储系统(HDFS)
核心项目之一。具有高容错性的数据备份机制,能够检测和应对硬件故障,并在低成本的通用硬件上运行。HDFS 具备流失的数据访问特点,提供高吞吐量应用程序访问功能,适合带有大型数据集的应用程序。 - MapReduce 分布式计算框架
是一种计算模型,用于大规模数据集(大于1TB)的并行运算。"Map"对数据集上的独立元素记性指定的操作,生成键值对形式的中间结果;“Reduce”则对中间结果中相同“键”的所有“值”进行规约,已得到最终的结果。这种“分而治之”的思想,极大的方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上 - YARM资源管理平台
是Hadoop 2.0 中的资源管理器,它可为上层应用提供统一的资源管理和调度,他的引入为集群在利用率、资源统一管理和数据共享等方面带来巨大的好处 - Sqoop 数据迁移工具
开源的数据导入导出工具,主要用于在Hadoop与传统数据库见进行数据的转换,他可以将一个关系数据库中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中 - Mahout 数据挖掘算法库
提供可扩展的机器学习领域经典算法的实现 - HBase分布式数据库
HBase是GoogleBigtable克隆版,它是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。 - Zookeeper分布式协调服务
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和I-dBase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括配置维护、域名服务、分布式同步、组服务等用于构建分布式应用,减少分布式应用程序所承担的协调任务。 - Hive基于Hadoop的数据仓库
Hive是基于Hadoop的一个分布式数据仓库工具,可以将结构化的数据文件映射为一张数据库表,将SQL语句转换为MapReduce任务进行运行。其优点是操作简单,降低学习成本,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 - Flume日志收集工具
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
1.3.4 Hadoop 的版本
Hadoop发行版本分为开源社区版和商业版,社区版是指由Apache软件基金会维护的版本,是官方维护的版本体系。商业版Hadoop是指山第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本,比较著名的有Cloudera公司的CDH版本。
为了方便学习,本书采用开源社区版,而Hadoop自诞生以来,主要分为Hadoop1、Hadoop2和Hadoop3三个系列的多个版本。由于目前市场上最主流的是Hadoop-2.x版本,因此,本书只针对Hadoop-2.x版本进行相关介绍。
Hadoop-2.x版本指的是第2代Hadoop,它是从Hadoop-1.x发展而来的,并且相对于Hadoop-1.x来说,有很多改进。下面从Hadoop-1.x到Hadoop-2.x发展的角度,对两版本进行讲解,如图1一4所示。
通过图1-4可以看出,Hadoop1.0内核主要由分布式存储系统(HDFS)和分布式计算框架MapReduce两个系统组成,而Hadoop-2.x版本主要新增了资源管理框架YARN以及其他工作机制的改变。

在Hadoop-1.X 版本中,HDFS 与MapReduce结构如图1-5和图1-6所示。

从图1一5可以看出,HDFS由一个NameNode和多个DateNode组成,其中,DataNode负责存储数据,但是数据具体存储到哪个DtaNode(节点),则是由NameNode决定的。
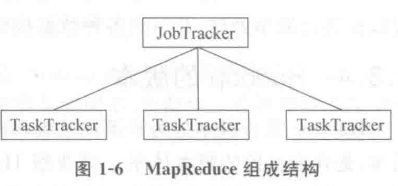
从图1一6可以看出MapReduce由一个JobTracker和多个TaskTracker组成,其中,MapReduce的主节点JobTracker只有一个,从节点TaskTracker有很多个,JobTracker与TaskTracker在MapReduce中的角色就像是项目经理与开发人员的关系,而JobTracker负责接收用户提交的计算任务,将计算任务分配给TaskTracker 执行、跟踪,JobTracker同时 监控 TaskTracker的任务执行状况等。当然,TaskTracker只负责执行JobTracker分配的计算任务,正是由于这种机制,Hadoop-1.x架构中的HDFS和MapReduce存在以下缺陷:
- HDFS中的NameNode、SecondaryNode单点故障,风险比较大。其次,NameNode
内存受限不好扩展,因为Hadoop-1.x版本中的HDFS只有一个NameNode,并且要管理所有的DataNode。 - MapReduce中的JobTracker 职责过多,访问压力太大,会影响系统稳定。除此之外,MapReduce难以支持除自身以外的框架,扩展性较低。
Hadoop-2.x版本为克服Hadoop-1.x中的不足,对其架构进行了以下改进: - Hadoop-2.x可以同时启动多个 NameNode,其中一个处于工作(Active)状态,另一个处于随时 **待命(Standby)状态 **,这种机制被称为HadoopHA(Hadoop高可用)。当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,自动切换到另一个NameNode持续提供服务。
- Had001Y2.x将JobTracker中的资源管理和作业控制分开,分别由ResourceManager(负责所有应用程序的资源分配)和ApplicationMaster(负责管理一个应用程序)实现,即引人了资源管理框架YARN,它是一个通用的资源管理框架,可以为各类应用程序进行资源管理和调度,不仅限于MapReduce一种框架,也可以为其他框架使用,如Tez、Spark、Storm,这种设计不仅能够增强不同计算模型和各种应用之间的交互,使集群资源得到高效利用,而且能更好地与企业中已经存在的计算结构集成在一起。
- Hadoop-2,x中的MapReduce是运行在YARN上的离线处理框架,它的运行环境不再由JobTracker和TaskTracker等服务组成,而是变成通用资源管理YARN和作业控制进程ApplicationMaster,从而使MapReduce在速度上和可用性上都有很大的提高。关于Hadoop-2.0的HDFS、MapReduce以及YARN的具体介绍,将在后续章节详细讲解,这里大家有个印象即可。

