
- 1能不能介绍一下USB传输协议的原理
- 2SpringDataJpa使用详解_spring data jpa使用
- 3jQuery ui effects详细用法_$effect详解
- 4NameError: name xx is not defined_input nameerror: name 'qwe' is not defined
- 5盘点人工智能十大经典应用领域、图解技术原理
- 6JavaScript、Kotlin、Flutter可以开发鸿蒙APP吗?
- 7APP测试Adb操作命令与Monkey使用、查错流程(入门+精通级)_monkey命令忽略崩溃
- 8AWS S3跨账号复制迁移数据_两个不同账户的aws 跨库复制
- 9Ineffective mark-compacts near heap limit Allocation failed-JavaScript heap out of memory vue项目内存溢出_v8 ineffective mark-compacts near heap limit alloc
- 10发掘非结构化数据价值:AI 在文档理解领域的现状与未来_非结构化数据 ai
Spark学习之路(十)——Spark Streaming_sparkstreaming语法
赞
踩
1、Spark Streaming工作方式
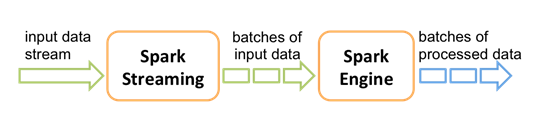
Spark Streaming引入了离散流(DStream)的概念。DStream本质上是存储在一系列RDD中的批数据,每个批代表一个时间窗口内的数据,时间窗口长度通常为秒级。
2、创建StreamingContext
from pyspark.streaming import StreamingContext
ssc = StreamingContext(sc, batchDuration=1)
……
# 初始化数据流
# DStream转化操作
……
ssc.start()
……
# ssc.stop()或ssc.awaitTermination()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
离散流(DStream)是Spark Streaming的基本编程对象。Dstream表示从连续的数据流创建的连续的一系列RDD,其中每个底层RDD表示数据流在一个时间窗口内的数据。
DStream支持两种类型的操作:转化操作和输出操作,输出操作类似于RDD的行动操作。
3、创建DStream的基本输入数据源
①.socketTextStream()
语法:StreamingContext.socketTextStream(hostname, port, storageLevel=StorageLevel(Ture, True, False, False, 1))
功能:.socketTextStream()方法可从参数hostname和参数port定义的TCP输入源创建DStream。参数storageLevel定义DStream的存储级别,默认为MEMORY_AND_DISK_SER。
②.textFileStream()
语法:StreamingContext.textFileStream(directory)
功能:.textFileStream()方法可监控当前系统或应用配置所指定的HDFS上的一个目录,从而创建DStream。.textFileStream()监听参数directory所指定的目录中新文件的创建,并捕获写入的数据,作为流式数据源。
4、DStream检查点
①StreamingContext.checkpoint()
语法:StreamingContext.checkpoint(directory)
功能:StreamingContext.checkpoint()方法让DStream操作可以定期保存检查点,以实现耐久性和容错性。参数directory一般配置为HDFS中的目录,用于持久化检查点数据。
②DStream.checkpoint()
语法:DStream.checkpoint(interval)
功能:DStream.checkpoint()方法可定期保存特定DStream中包含的RDD的检查点。参数interval是以秒为单位的时间,表示每隔interval秒DStream底层的RDD就会保存一次检查点。
5、DStream输出操作
①.pprint()
语法:DStream.pprint(num=10)
功能:.pprint()方法打印DStream中每个RDD的前几个元素,元素数量通过参数num指定,默认为10。
②.saveAsTextFile()
语法:DStream.saveAsTextFile(prefix, suffix-=None)
功能:.saveAsTextFile()方法把DStream底层的各个RDD保存为目标文件系统(本地文件系统、HDFS或其他文件系统)。
③.foreachRDD()
语法:DStream.foreachRDD(func)
功能:.foreachRDD()方法把参数func指定的函数应用于DStream底层的每个RDD。foreachRDD()方法由运行该流处理应用的驱动器进程执行,通常会强制触发DStream底层RDD的计算。
6、DStream状态操作
①updateStateByKey()
语法:DStream.updateStateByKey(undateFunc, numPartitions=None)
功能:.updateStateByKey()方法返回一个新的有状态DStream,根据对之前的状态和新的键应用参数updateFunc指定的函数所得的结果更新各键的状态。
.updateByKey()方法的参数updateFunc指定的函数预期接收键值对作为输入,并返回相应的键值对作为输出,键值对的值根据undateFunc函数进行更新。
#注:使用updateByKey()方法和创建更新有状态DStream之前,必须先在StreamingContext中使用ssc.checkpoint(directory)打开检查点机制。
7、滑动窗口操作
(.window()、.countByWindow()、.reduceBy-Window()、.reduceByKeyAndWindow()、.countByValueAndWindow())
①.window()
语法:DStream.window(windowLength, slideInterval)
功能:.window()方法从指定的输入DStream的批返回一个新的DStream。.window()方法每隔参数slideInterval指定的时间间隔创建一个新的DStream对象,其中的元素是输入DStream中由参数windowLength指定的元素。
#注:参数slideInterval和windowLength都必须是StreamingContext所设置的batchDuration的倍数。
②.reduceByKeyAndWindow()
语法:DStream.reduceByKeyAndWindow(func, invFunc, windowDuration, slideDuration=None, numPartitions=None, filterFunc=None)
功能:.reduceByKeyAndWindow()方法通过对参数windowDuration和slideDuration定义的滑动窗口执行参数func指定的归约函数,创建新的DStream。参数invFunc是参数func的逆函数,引入参数invFunc是为了高效地从之前的窗口中移除(减去)不用的计数。参数filterFunc可筛选出过期的键值对。
8、结构化流处理
Spark中的流处理不仅仅适用于RDD API。通过使用结构化流处理(structured streaming),Spark Streaming可实现与Spark DataFrame API的完整结合。使用结构化流处理时,流式数据源可看作不断写入数据的无限的表。

