
- 1计算机毕业设计ssm+vue基本微信小程序的新乡学院自习室预约系统 uniapp 小程序_基于微信小程序的新乡学院自习室预约系统
- 2自适应动态规划 matlab_CVPR 2020丨动态卷积:自适应调整卷积参数,显著提升模型表达能力...
- 3薛蛮子和前8848总裁吕春维共同创立的车托帮
- 4一款开源免费跨浏览器的视频播放器--videojs使用介绍
- 5测试版降级后软件还在么,如果你后悔安装iOS12想降到iOS11?几招教你删除iOS12测试版...
- 6Android——Handler一篇就看懂_android handler
- 7android 自定义dialog样式,Android 自定义dialog类
- 8基于Arduino的智能洗手机_arduino 三极管
- 9数据结构—树的实现(C语言)_树形结构c如何实现
- 10(2022.5)Pyhthon Matplotlib实现在图中绘制多子图(一纸多图)_ax = ax.ravel()
python 机器学习XGBoost,SVM图像分类与数据预测分析_xgboot svm 分类
赞
踩
文章目录
-
0 前言+
-
Step1:库函数导入+ Step2:模型训练+ Step3:模型参数查看+ Step4:数据和模型可视化+ Step5:模型预测
-
Step1:库函数导入+ Step2:数据读取/载入+ Step3:数据信息简单查看+ Step4:可视化描述+ Step5:利用 逻辑回归模型 在二分类上 进行训练和预测+ Step6:利用 逻辑回归模型 在三分类(多分类)上 进行训练和预测
设计项目案例演示地址: 链接
毕业设计代做一对一指导项目方向涵盖:
基于Python,MATLAB设计,OpenCV,,CNN,机器学习,R-CNN,GCN,LSTM,SVM,BP目标检测、语义分割、Re-ID、医学图像分割、目标跟踪、人脸识别、数据增广、
人脸检测、显著性目标检测、自动驾驶、人群密度估计、3D目标检测、CNN、AutoML、图像分割、SLAM、实例分割、人体姿态估计、视频目标分割,PyTorch、人脸检测、车道线检测、去雾 、全景分割、
行人检测、文本检测、OCR、姿态估计、边缘检测、场景文本检测、视频实例分割、3D点云、模型压缩、人脸对齐、超分辨、去噪、强化学习、行为识别、OpenCV、场景文本识别、去雨、机器学习、风格迁移、
视频目标检测、去模糊、活体检测、人脸关键点检测、3D目标跟踪、视频修复、人脸表情识别、时序动作检测、图像检索、异常检测等毕设指导,毕设选题,毕业设计开题报告,
- 1
- 2
- 3
- 4
-
Step1:函数库导入+ Step2:数据读取/载入+ Step3:数据信息简单查看+ Step4:可视化描述+ Step5:对离散变量进行编码+ Step6:利用 XGBoost 进行训练与预测+ Step7: 利用 XGBoost 进行特征选择+ Step8: 通过调整参数获得更好的效果
【机器学习】基于逻辑回归,LightGBM,XGBoost额的分类预测
-
一.基于逻辑回归的分类预测+
-
1 逻辑回归的介绍和应用+
-
1.1 逻辑回归的介绍+ 1.2逻辑回归的应用
-
2.Demo实践+
-
Step1:库函数导入+ Step2:模型训练+ Step3:模型参数查看+ Step4:数据和模型可视化+ Step5:模型预测
-
3.基于鸢尾花(iris)数据集的逻辑回归分类实践+
-
Step1:库函数导入+ Step2:数据读取/载入+ Step3:数据信息简单查看+ Step4:可视化描述+ Step5:利用 逻辑回归模型 在二分类上 进行训练和预测+ Step6:利用 逻辑回归模型 在三分类(多分类)上 进行训练和预测
-
二.基于XGBoost的分类预测+
-
1.XGBoost与应用+
-
XGBoost的介绍+ 1.2XGboost的应用
-
2.基于天气数据集的XGBoost分类实战+
-
Step1:函数库导入+ Step2:数据读取/载入+ Step3:数据信息简单查看+ Step4:可视化描述+ Step5:对离散变量进行编码+ Step6:利用 XGBoost 进行训练与预测+ Step7: 利用 XGBoost 进行特征选择+ Step8: 通过调整参数获得更好的效果
-
s
一.基于逻辑回归的分类预测
1 逻辑回归的介绍和应用
1.1 逻辑回归的介绍
逻辑回归(Logistic regression,简称LR)虽然其中带有"回归"两个字,但逻辑回归其实是一个分类模型,并且广泛应用于各个领域之中。虽然现在深度学习相对于这些传统方法更为火热,但实则这些传统方法由于其独特的优势依然广泛应用于各个领域中。
而对于逻辑回归而且,最为突出的两点就是其模型简单和模型的可解释性强。
逻辑回归模型的优劣势:
- 优点:实现简单,易于理解和实现;计算代价不高,速度很快,存储资源低+ 缺点:容易欠拟合,分类精度可能不高
1.2逻辑回归的应用
逻辑回归模型广泛用于各个领域,包括机器学习,大多数医学领域和社会科学。例如,最初由Boyd 等人开发的创伤和损伤严重度评分(TRISS)被广泛用于预测受伤患者的死亡率,使用逻辑回归 基于观察到的患者特征(年龄,性别,体重指数,各种血液检查的结果等)分析预测发生特定疾病(例如糖尿病,冠心病)的风险。逻辑回归模型也用于预测在给定的过程中,系统或产品的故障的可能性。还用于市场营销应用程序,例如预测客户购买产品或中止订购的倾向等。在经济学中它可以用来预测一个人选择进入劳动力市场的可能性,而商业应用则可以用来预测房主拖欠抵押贷款的可能性。条件随机字段是逻辑回归到顺序数据的扩展,用于自然语言处理。
逻辑回归模型现在同样是很多分类算法的基础组件,比如 分类任务中基于GBDT算法+LR逻辑回归实现的信用卡交易反欺诈,CTR(点击通过率)预估等,其好处在于输出值自然地落在0到1之间,并且有概率意义。模型清晰,有对应的概率学理论基础。它拟合出来的参数就代表了每一个特征(feature)对结果的影响。也是一个理解数据的好工具。但同时由于其本质上是一个线性的分类器,所以不能应对较为复杂的数据情况。很多时候我们也会拿逻辑回归模型去做一些任务尝试的基线(基础水平)。
说了这些逻辑回归的概念和应用,大家应该已经对其有所期待了吧,那么我们现在开始吧!!!
2.Demo实践
Step1:库函数导入
## 基础函数库 import numpy as np
## 导入画图库
import matplotlib.pyplot as plt
import seaborn as sns
## 导入逻辑回归模型函数
from sklearn.linear_model import LogisticRegression
- 1
- 2
- 3
- 4
- 5
- 6
Step2:模型训练
##Demo演示LogisticRegression分类
## 构造数据集
x_fearures = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]])
y_label = np.array([0, 0, 0, 1, 1, 1])
## 调用逻辑回归模型
lr_clf = LogisticRegression()
## 用逻辑回归模型拟合构造的数据集
lr_clf = lr_clf.fit(x_fearures, y_label) #其拟合方程为 y=w0+w1*x1+w2*x2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Step3:模型参数查看
## 查看其对应模型的w print(‘the weight of Logistic Regression:’,lr_clf.coef_)
## 查看其对应模型的w0
print('the intercept(w0) of Logistic Regression:',lr_clf.intercept_)
- 1
- 2

Step4:数据和模型可视化
## 可视化构造的数据样本点 plt.figure() plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap=‘viridis’) plt.title(‘Dataset’) plt.show()

# 可视化决策边界 plt.figure() plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap=‘viridis’) plt.title(‘Dataset’)
nx, ny = 200, 100
x_min, x_max = plt.xlim()
y_min, y_max = plt.ylim()
x_grid, y_grid = np.meshgrid(np.linspace(x_min, x_max, nx),np.linspace(y_min, y_max, ny))
z_proba = lr_clf.predict_proba(np.c_[x_grid.ravel(), y_grid.ravel()])
z_proba = z_proba[:, 1].reshape(x_grid.shape)
plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

### 可视化预测新样本
plt.figure() ## new point 1 x_fearures_new1 = np.array([[0, -1]]) plt.scatter(x_fearures_new1[:,0],x_fearures_new1[:,1], s=50, cmap='viridis') plt.annotate(s='New point 1',xy=(0,-1),xytext=(-2,0),color='blue',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red')) ## new point 2 x_fearures_new2 = np.array([[1, 2]]) plt.scatter(x_fearures_new2[:,0],x_fearures_new2[:,1], s=50, cmap='viridis') plt.annotate(s='New point 2',xy=(1,2),xytext=(-1.5,2.5),color='red',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red')) ## 训练样本 plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis') plt.title('Dataset') # 可视化决策边界 plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue') plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

Step5:模型预测
## 在训练集和测试集上分别利用训练好的模型进行预测 y_label_new1_predict = lr_clf.predict(x_fearures_new1) y_label_new2_predict = lr_clf.predict(x_fearures_new2)
print('The New point 1 predict class:\n',y_label_new1_predict)
print('The New point 2 predict class:\n',y_label_new2_predict)
## 由于逻辑回归模型是概率预测模型(前文介绍的 p = p(y=1|x,\theta)),所以我们可以利用 predict_proba 函数预测其概率
y_label_new1_predict_proba = lr_clf.predict_proba(x_fearures_new1)
y_label_new2_predict_proba = lr_clf.predict_proba(x_fearures_new2)
print('The New point 1 predict Probability of each class:\n',y_label_new1_predict_proba)
print('The New point 2 predict Probability of each class:\n',y_label_new2_predict_proba)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
可以发现训练好的回归模型将X_new1预测为了类别0(判别面左下侧),X_new2预测为了类别1(判别面右上侧)。其训练得到的逻辑回归模型的概率为0.5的判别面为上图中蓝色的线。
3.基于鸢尾花(iris)数据集的逻辑回归分类实践
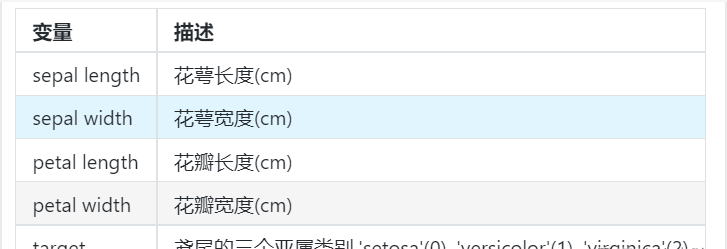
本次我们选择鸢花数据(iris)进行方法的尝试训练,该数据集一共包含5个变量,其中4个特征变量,1个目标分类变量。共有150个样本,目标变量为 花的类别 其都属于鸢尾属下的三个亚属,分别是山鸢尾 (Iris-setosa),变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris- virginica)。包含的三种鸢尾花的四个特征,分别是花萼长度(cm)、花萼宽度(cm)、花瓣长度(cm)、花瓣宽度(cm),这些形态特征在过去被用来识别物种。

Step1:库函数导入
## 基础函数库 import numpy as np import pandas as pd
## 绘图函数库
import matplotlib.pyplot as plt
import seaborn as sns
- 1
- 2
- 3
Step2:数据读取/载入
## 我们利用 sklearn 中自带的 iris 数据作为数据载入,并利用Pandas转化为DataFrame格式 from sklearn.datasets import load_iris data = load_iris() #得到数据特征 iris_target = data.target #得到数据对应的标签 iris_features = pd.DataFrame(data=data.data, columns=data.feature_names) #利用Pandas转化为DataFrame格式
Step3:数据信息简单查看
## 利用.info()查看数据的整体信息 iris_features.info()
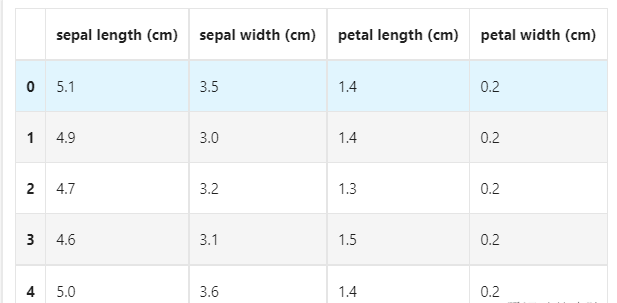
## 进行简单的数据查看,我们可以利用 .head() 头部.tail()尾部 iris_features.head()

## 其对应的类别标签为,其中0,1,2分别代表’setosa’, ‘versicolor’, 'virginica’三种不同花的类别。 iris_target
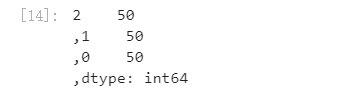
## 利用value_counts函数查看每个类别数量 pd.Series(iris_target).value_counts()
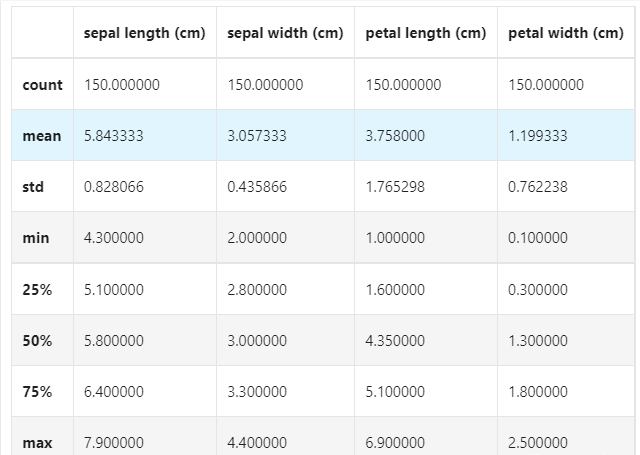
## 对于特征进行一些统计描述 iris_features.describe()

从统计描述中我们可以看到不同数值特征的变化范围。
Step4:可视化描述
## 合并标签和特征信息 iris_all = iris_features.copy() ##进行浅拷贝,防止对于原始数据的修改 iris_all[‘target’] = iris_target ## 特征与标签组合的散点可视化 sns.pairplot(data=iris_all,diag_kind=‘hist’, hue= ‘target’) plt.show()

上图可以发现,在2D情况下不同的特征组合对于不同类别的花的散点分布,以及大概的区分能力。
for col in iris_features.columns: sns.boxplot(x=‘target’, y=col, saturation=0.5,palette=‘pastel’, data=iris_all) plt.title(col) plt.show()



利用箱型图我们也可以得到不同类别在不同特征上的分布差异情况。
# 选取其前三个特征绘制三维散点图 from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection='3d')
iris_all_class0 = iris_all[iris_all['target']==0].values
iris_all_class1 = iris_all[iris_all['target']==1].values
iris_all_class2 = iris_all[iris_all['target']==2].values
# 'setosa'(0), 'versicolor'(1), 'virginica'(2)
ax.scatter(iris_all_class0[:,0], iris_all_class0[:,1], iris_all_class0[:,2],label='setosa')
ax.scatter(iris_all_class1[:,0], iris_all_class1[:,1], iris_all_class1[:,2],label='versicolor')
ax.scatter(iris_all_class2[:,0], iris_all_class2[:,1], iris_all_class2[:,2],label='virginica')
plt.legend()
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
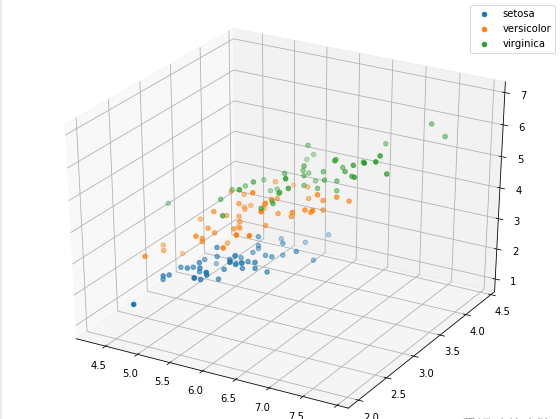
Step5:利用 逻辑回归模型 在二分类上 进行训练和预测
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。 from sklearn.model_selection import train_test_split
## 选择其类别为0和1的样本 (不包括类别为2的样本) iris_features_part = iris_features.iloc[:100] iris_target_part = iris_target[:100] ## 测试集大小为20%, 80%/20%分 x_train, x_test, y_train, y_test = train_test_split(iris_features_part, iris_target_part, test_size = 0.2, random_state = 2020) ## 从sklearn中导入逻辑回归模型 from sklearn.linear_model import LogisticRegression ## 定义 逻辑回归模型 clf = LogisticRegression(random_state=0, solver='lbfgs') # 在训练集上训练逻辑回归模型 clf.fit(x_train, y_train) ## 查看其对应的w print('the weight of Logistic Regression:',clf.coef_) ## 查看其对应的w0 print('the intercept(w0) of Logistic Regression:',clf.intercept_)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

## 在训练集和测试集上分布利用训练好的模型进行预测 train_predict = clf.predict(x_train) test_predict = clf.predict(x_test)
from sklearn import metrics
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
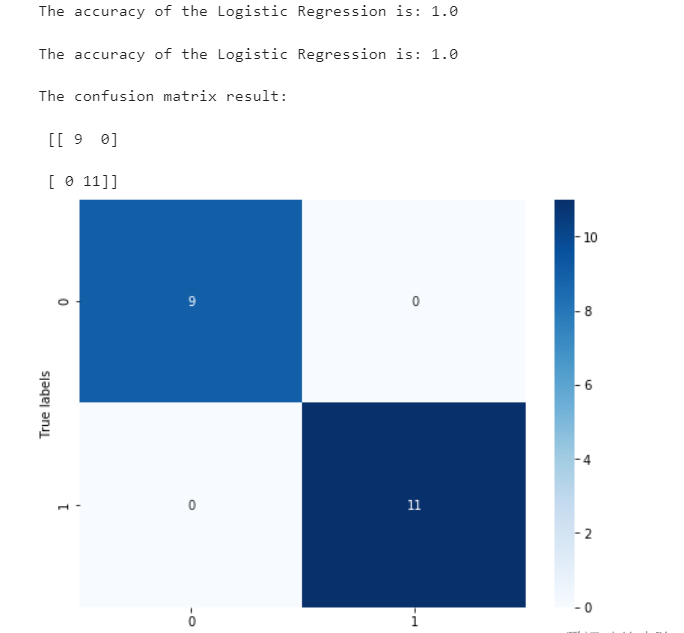
我们可以发现其准确度为1,代表所有的样本都预测正确了。
Step6:利用 逻辑回归模型 在三分类(多分类)上 进行训练和预测
## 测试集大小为20%, 80%/20%分 x_train, x_test, y_train, y_test = train_test_split(iris_features, iris_target, test_size = 0.2, random_state = 2020)
其余代码与二分类相同

通过结果我们可以发现,其在三分类的结果的预测准确度上有所下降,其在测试集上的准确度为: 86.67 % ,这是由于’versicolor’(1)和 ‘virginica’(2)这两个类别的特征,我们从可视化的时候也可以发现,其特征的边界具有一定的模糊性(边界类别混杂,没有明显区分边界),所有在这两类的预测上出现了一定的错误。
二.基于XGBoost的分类预测
1.XGBoost与应用
XGBoost的介绍
XGBoost是2016年由华盛顿大学陈天奇老师带领开发的一个可扩展机器学习系统。严格意义上讲XGBoost并不是一种模型,而是一个可供用户轻松解决分类、回归或排序问题的软件包。它内部实现了梯度提升树(GBDT)模型,并对模型中的算法进行了诸多优化,在取得高精度的同时又保持了极快的速度,在一段时间内成为了国内外数据挖掘、机器学习领域中的大规模杀伤性武器。
更重要的是,XGBoost在系统优化和机器学习原理方面都进行了深入的考虑。毫不夸张的讲,XGBoost提供的可扩展性,可移植性与准确性推动了机器学习计算限制的上限,该系统在单台机器上运行速度比当时流行解决方案快十倍以上,甚至在分布式系统中可以处理十亿级的数据。
XGBoost的主要优点:
**简单易用。**相对其他机器学习库,用户可以轻松使用XGBoost并获得相当不错的效果。
**高效可扩展。**在处理大规模数据集时速度快效果好,对内存等硬件资源要求不高。
**鲁棒性强。**相对于深度学习模型不需要精细调参便能取得接近的效果。
XGBoost内部实现提升树模型,可以 自动处理缺失值 。
XGBoost的主要缺点:
相对于深度学习模型无法对时空位置建模,不能很好地捕获图像、语音、文本等高维数据。
在拥有海量训练数据,并能找到合适的深度学习模型时,深度学习的精度可以遥遥领先XGBoost。
1.2XGboost的应用
XGBoost在机器学习与数据挖掘领域有着极为广泛的应用。据统计在2015年Kaggle平台上29个获奖方案中,17只队伍使用了XGBoost;在2015年KDD- Cup中,前十名的队伍均使用了XGBoost,且集成其他模型比不上调节XGBoost的参数所带来的提升。这些实实在在的例子都表明,XGBoost在各种问题上都可以取得非常好的效果。
同时,XGBoost还被成功应用在工业界与学术界的各种问题中。例如商店销售额预测、高能物理事件分类、web文本分类;用户行为预测、运动检测、广告点击率预测、恶意软件分类、灾害风险预测、在线课程退学率预测。虽然领域相关的数据分析和特性工程在这些解决方案
2.基于天气数据集的XGBoost分类实战
数据集:[天气数据集](https://tianchi-media.oss-cn- beijing.aliyuncs.com/DSW/7XGBoost/train.csv)
Step1:函数库导入
## 基础函数库 import numpy as np import pandas as pd
## 绘图函数库
import matplotlib.pyplot as plt
import seaborn as sns
- 1
- 2
- 3
本次我们选择天气数据集进行方法的尝试训练,现在有一些由气象站提供的每日降雨数据,我们需要根据历史降雨数据来预测明天会下雨的概率。样例涉及到的测试集数据test.csv与train.csv的格式完全相同,但其RainTomorrow未给出,为预测变量。
数据的各个特征描述如下:
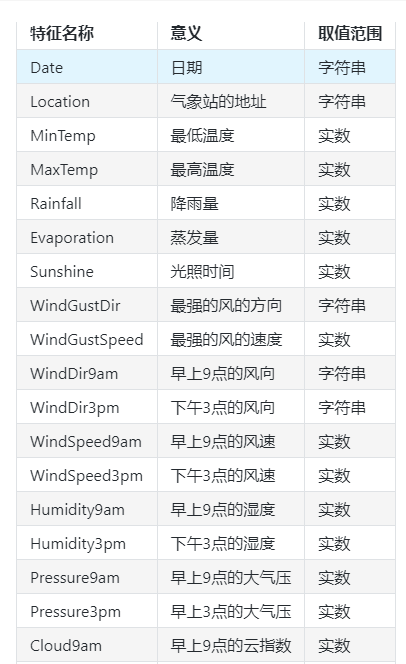
Step2:数据读取/载入
## 我们利用Pandas自带的read_csv函数读取并转化为DataFrame格式
data = pd.read_csv('train.csv')
- 1
Step3:数据信息简单查看
## 利用.info()查看数据的整体信息 data.info()

## 进行简单的数据查看,我们可以利用 .head() 头部.tail()尾部 data.head()
由于变量太多,这里只展示部分变量
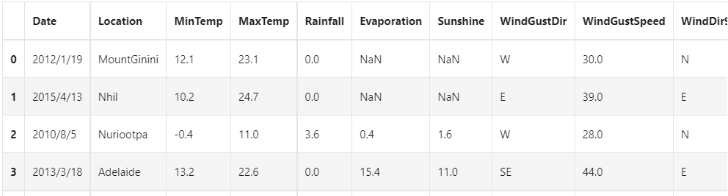
这里我们发现数据集中存在NaN,一般的我们认为NaN在数据集中代表了缺失值,可能是数据采集或处理时产生的一种错误。这里我们采用-1将缺失值进行填补,还有其他例如“中位数填补、平均数填补”的缺失值处理方法
data = data.fillna(-1) data.tail()
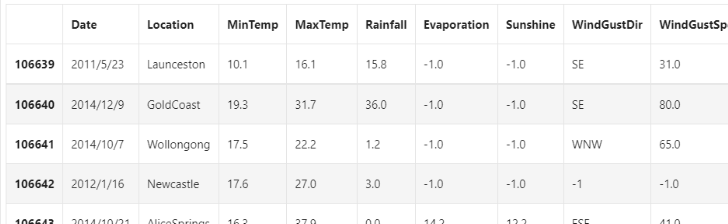
## 利用value_counts函数查看训练集标签的数量 pd.Series(data[‘RainTomorrow’]).value_counts()
No 82786 ,Yes 23858 ,Name: RainTomorrow, dtype: int64
我们发现数据集中的负样本数量远大于正样本数量,这种常见的问题叫做“数据不平衡”问题,在某些情况下需要进行一些特殊处理。解决数据不平衡的办法有数据变换或者数据插补等等。
## 对于特征进行一些统计描述 data.describe()
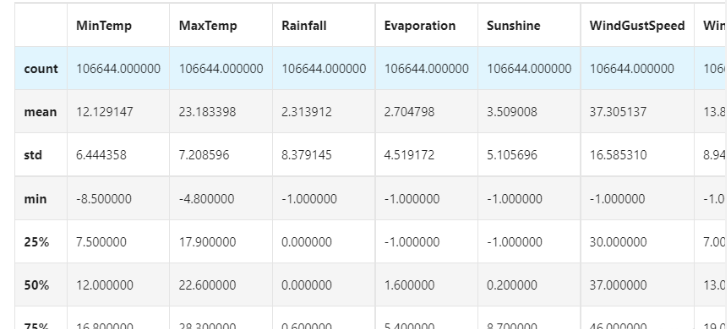
Step4:可视化描述
为了方便,我们先纪录数字特征与非数字特征:
numerical_features = [x for x in data.columns if data[x].dtype == np.float] numerical_features = [x for x in data.columns if data[x].dtype == np.float]
## 选取三个特征与标签组合的散点可视化
sns.pairplot(data=data[['Rainfall',
'Evaporation',
'Sunshine'] + ['RainTomorrow']], diag_kind='hist', hue= 'RainTomorrow')
plt.show()
- 1
- 2
- 3
- 4
- 5
从上图可以发现,在2D情况下不同的特征组合对于第二天下雨与不下雨的散点分布,以及大概的区分能力。相对的Sunshine与其他特征的组合更具有区分能力
for col in data[numerical_features].columns: if col != ‘RainTomorrow’: sns.boxplot(x=‘RainTomorrow’, y=col, saturation=0.5, palette=‘pastel’, data=data) plt.title(col) plt.show()








利用箱型图我们也可以得到不同类别在不同特征上的分布差异情况。我们可以发现Sunshine,Humidity3pm,Cloud9am,Cloud3pm的区分能力较强
tlog = {} for i in category_features: tlog[i] = data[data[‘RainTomorrow’] == ‘Yes’][i].value_counts() flog = {} for i in category_features: flog[i] = data[data[‘RainTomorrow’] == ‘No’][i].value_counts()
plt.figure(figsize=(10,10)) plt.subplot(1,2,1) plt.title(‘RainTomorrow’) sns.barplot(x = pd.DataFrame(tlog[‘Location’]).sort_index()[‘Location’], y = pd.DataFrame(tlog[‘Location’]).sort_index().index, color = “red”) plt.subplot(1,2,2) plt.title(‘Not RainTomorrow’) sns.barplot(x = pd.DataFrame(flog[‘Location’]).sort_index()[‘Location’], y = pd.DataFrame(flog[‘Location’]).sort_index().index, color = “blue”) plt.show()

从上图可以发现不同地区降雨情况差别很大,有些地方明显更容易降雨
plt.figure(figsize=(10,2)) plt.subplot(1,2,1) plt.title(‘RainTomorrow’) sns.barplot(x = pd.DataFrame(tlog[‘RainToday’][:2]).sort_index()[‘RainToday’], y = pd.DataFrame(tlog[‘RainToday’][:2]).sort_index().index, color = “red”) plt.subplot(1,2,2) plt.title(‘Not RainTomorrow’) sns.barplot(x = pd.DataFrame(flog[‘RainToday’][:2]).sort_index()[‘RainToday’], y = pd.DataFrame(flog[‘RainToday’][:2]).sort_index().index, color = “blue”) plt.show()

上图我们可以发现,今天下雨明天不一定下雨,但今天不下雨,第二天大概率也不下雨。
Step5:对离散变量进行编码
由于XGBoost无法处理字符串类型的数据,我们需要一些方法讲字符串数据转化为数据。一种最简单的方法是把所有的相同类别的特征编码成同一个值,例如女=0,男=1,狗狗=2,所以最后编码的特征值是在 [0,特征数数量-1]之间的整数。除此之外,还有独热编码、求和编码、留一法编码等等方法可以获得更好的效果。
## 把所有的相同类别的特征编码为同一个值 def get_mapfunction(x): mapp = dict(zip(x.unique().tolist(), range(len(x.unique().tolist())))) def mapfunction(y): if y in mapp: return mapp[y] else: return -1 return mapfunction for i in category_features: data[i] = data[i].apply(get_mapfunction(data[i]))
## 编码后的字符串特征变成了数字
data['Location'].unique()
- 1

Step6:利用 XGBoost 进行训练与预测
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。 from sklearn.model_selection import train_test_split
## 选择其类别为0和1的样本 (不包括类别为2的样本)
data_target_part = data['RainTomorrow']
data_features_part = data[[x for x in data.columns if x != 'RainTomorrow']]
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2, random_state = 2020)
- 1
- 2
- 3
- 4
- 5
- 6
## 导入XGBoost模型 from xgboost.sklearn import XGBClassifier ## 定义 XGBoost模型 clf = XGBClassifier() # 在训练集上训练XGBoost模型 clf.fit(x_train, y_train)
## 在训练集和测试集上分布利用训练好的模型进行预测 train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) from sklearn import metrics
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
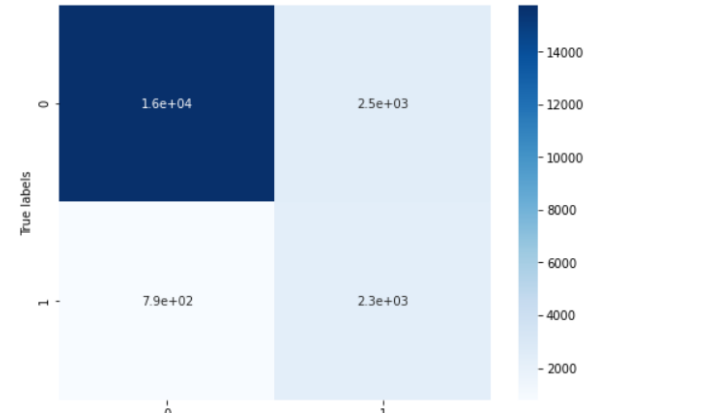
我们可以发现共有15759 + 2306个样本预测正确,2470 + 794个样本预测错误。
Step7: 利用 XGBoost 进行特征选择
sns.barplot(y=data_features_part.columns, x=clf.feature_importances_)

从图中我们可以发现下午3点的湿度与今天是否下雨是决定第二天是否下雨最重要的因素
初次之外,我们还可以使用XGBoost中的下列重要属性来评估特征的重要性。
weight:是以特征用到的次数来评价
gain:当利用特征做划分的时候的评价基尼指数
cover:利用一个覆盖样本的指标二阶导数(具体原理不清楚有待探究)平均值来划分。
total_gain:总基尼指数
total_cover:总覆盖
from sklearn.metrics import accuracy_score from xgboost import plot_importance
def estimate(model,data): #sns.barplot(data.columns,model.feature_importances_) ax1=plot_importance(model,importance_type="gain") ax1.set_title('gain') ax2=plot_importance(model, importance_type="weight") ax2.set_title('weight') ax3 = plot_importance(model, importance_type="cover") ax3.set_title('cover') plt.show() def classes(data,label,test): model=XGBClassifier() model.fit(data,label) ans=model.predict(test) estimate(model, data) return ans ans=classes(x_train,y_train,x_test) pre=accuracy_score(y_test, ans) print('acc=',accuracy_score(y_test,ans))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20



这些图同样可以帮助我们更好的了解其他重要特征。
Step8: 通过调整参数获得更好的效果
XGBoost中包括但不限于下列对模型影响较大的参数:
learning_rate: 有时也叫作eta,系统默认值为0.3。每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。
subsample:系统默认为1。这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合, 取值范围零到一。
colsample_bytree:系统默认值为1。我们一般设置成0.8左右。用来控制每棵随机采样的列数的占比(每一列是一个特征)。
max_depth: 系统默认值为6,我们常用3-10之间的数字。这个值为树的最大深度。这个值是用来控 制过拟合的。max_depth越大,模型学习的更加具体。 调节模型参数的方法有贪心算法、网格调参、贝叶斯调参等。这里我们采用网格调参,它的基本思想是穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果
## 从sklearn库中导入网格调参函数 from sklearn.model_selection import GridSearchCV
## 定义参数取值范围
learning_rate = [0.1, 0.3, 0.6]
subsample = [0.8, 0.9]
colsample_bytree = [0.6, 0.8]
max_depth = [3,5,8]
parameters = { 'learning_rate': learning_rate,
'subsample': subsample,
'colsample_bytree':colsample_bytree,
'max_depth': max_depth}
model = XGBClassifier(n_estimators = 50)
## 进行网格搜索
clf = GridSearchCV(model, parameters, cv=3, scoring='accuracy',verbose=1,n_jobs=-1)
clf = clf.fit(x_train, y_train)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
## 在训练集和测试集上分布利用最好的模型参数进行预测
## 定义带参数的 XGBoost模型 clf = XGBClassifier(colsample_bytree = 0.6, learning_rate = 0.3, max_depth= 8, subsample = 0.9) # 在训练集上训练XGBoost模型 clf.fit(x_train, y_train) train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) ## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果 print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict)) print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict)) ## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵) confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print('The confusion matrix result:\n',confusion_matrix_result) # 利用热力图对于结果进行可视化 plt.figure(figsize=(8, 6)) sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues') plt.xlabel('Predicted labels') plt.ylabel('True labels') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

原本有2470 + 790个错误,现在有 2112 + 939个错误,带来了明显的正确率提升。
Regression is:',metrics.accuracy_score(y_train,train_predict))
print(‘The accuracy of the Logistic Regression is:’,metrics.accuracy_score(y_test,test_predict))
查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print(‘The confusion matrix result:\n’,confusion_matrix_result)
利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap=‘Blues’)
plt.xlabel(‘Predicted labels’)
plt.ylabel(‘True labels’)
plt.show()
``### 设计项目案例演示地址: 链接
毕业设计代做一对一指导项目方向涵盖:
基于Python,MATLAB设计,OpenCV,,CNN,机器学习,R-CNN,GCN,LSTM,SVM,BP目标检测、语义分割、Re-ID、医学图像分割、目标跟踪、人脸识别、数据增广、
人脸检测、显著性目标检测、自动驾驶、人群密度估计、3D目标检测、CNN、AutoML、图像分割、SLAM、实例分割、人体姿态估计、视频目标分割,PyTorch、人脸检测、车道线检测、去雾 、全景分割、
行人检测、文本检测、OCR、姿态估计、边缘检测、场景文本检测、视频实例分割、3D点云、模型压缩、人脸对齐、超分辨、去噪、强化学习、行为识别、OpenCV、场景文本识别、去雨、机器学习、风格迁移、
视频目标检测、去模糊、活体检测、人脸关键点检测、3D目标跟踪、视频修复、人脸表情识别、时序动作检测、图像检索、异常检测等毕设指导,毕设选题,毕业设计开题报告,
- 1
- 2
- 3
- 4

