
- 1如何低成本的在Docker中运行TensorFlow_docker tensorflow no avx
- 2Vue3项目运行Error: Cannot find module ‘vue-loader-v16/package.json‘问题处理_loader error 3
- 3MySQL的分区方法_mysql的分区方式
- 4红队内网攻防渗透:内网渗透之域内攻击利用方式和技巧
- 5ThingsBoard教程(一):ThingBoard介绍及安装_thingsbroad
- 6flume日志级别_flume配置定义日志级别
- 7树莓派3b+通过i2c驱动bmp280大气压模块_bmp280驱动程序树莓派
- 8视频AI自动拍摄剪辑解决方案,高光瞬间不再错过
- 9以人为本是AI大模型的最终落脚点——读《大模型时代:ChatGPT开启通用人工智能浪潮》_大模型时代:chatgpt开启通用人工智能浪潮
- 10食堂安全检测必备设备:手持式可燃气体报警器
机器学习漫谈:深度学习的辉煌
赞
踩
来源:王宏琳科学网博客
如今,当有人提到人工智能引起社会变革潜力时,他们很可能是在谈论机器学习中的人工神经网络。当一篇文章谈人工神经网络突破性进展时,作者很可能指的是深度学习。
人工神经网络是一种非线性统计建模工具,可以用于发现输入和输出之间的关系,或在大型数据库中发现模式。人工神经网络已应用于统计模型开发、自适应控制系统、数据挖掘模式识别和不确定性下的决策。
深度学习是基于人工神经网络和表示学习的一系列机器学习方法的一部分。学习可以是有监督的、半监督的或无监督的,甚至强化学习的。
【深度学习有别于传统机器学习】
有人称,“实际上,深度学习是一种称为神经网络的人工智能方法的新名称,这种方法已经流行了70多年了”。但是,这样的说法并不准确。深度学习有别于传统机器学习。这里的“传统机器学习”,是指20世纪普通的神经网络,或浅层神经网络。
的确,计算机与大脑的关系,曾经吸引了20世纪40年代计算机先驱的关注。例如,1945年6月,约翰·冯·诺伊曼(John von Neumann)在《EDVAC报告草稿》首次描述现代计算的关键体系结构概念时,就使用了“memory(记忆)”,“organ(器官)”和“neuron(神经元)”等生物学术语。冯·诺伊曼生前还撰写《计算机与人脑》未完成稿,从数学的角度解析了计算机与人脑神经系统的关系。又如,1943年,沃伦·麦卡洛克(Warren McCullough)和沃尔特·皮茨(Walter Pitts)首次提出神经网络,他们的神经元模型,能够实现布尔逻辑语句。
第一次重大的神经网络突破,出现在20世纪60年代中期,苏联数学家亚历克赛·伊瓦克年科(Alexey Ivakhnenko)在他的助手拉帕(V.G.Lapa)的帮助下创建了小型但功能较强的神经网络,采用有监督深度前馈多层感知器的学习算法。而单层感知机是20世纪50年代罗森布拉特发明的。
上世纪80年代初,约翰·霍普菲尔德(John Hopfield)的循环神经网络(recurrent neural networks)引起了轰动,紧接着特里·塞伊诺夫斯基(Terry Sejnowski)的程序NetTalk可以发音英语单词。
2006年,卡内基梅隆大学教授、计算机科学家杰弗里·辛顿使用了“深度学习”这个词,此后,“深度学习”术语很快广泛流行。虽然,这个术语并非辛顿第一个使用的,早在1986年,R.德克特(R. Dechter)的一篇论文就将“深度学习”一词引入机器学习。2000年,艾森伯格(Aizenberg)等人首次将其引入人工神经网络。
21世纪的深度学习与传统神经网络区别在哪里呢?
首先,人工神经网络包含输入层和输出层之间的隐藏层。传统的神经网络只包含一个或几个隐藏层。深度学习是一个非常大的神经网络,包含多得多的隐藏层(通常为150个),它们可以存储和处理更多信息。这是深度学习有别于传统神经网络的最重要的一点。因此,名称“深层”用于此类网络。
其次,深度学习不需要手工提取特征,而直接将图像作为输入。这是深度学习有别于传统神经网络的另一点。图1描述了在机器学习和深度学习中识别对象所遵循的过程。
第三,深度学习需要高性能的GPU和大量数据。特征提取和分类是通过称为卷积神经网络(CNN)的深度学习算法进行的。CNN负责特征提取以及基于多个图像的分类。当数据量增加时,深度学习算法的性能也会提高。相反,当数据量增加时,传统学习算法的性能会降低。
 图1 机器学习与深度学习
图1 机器学习与深度学习
在机器学习中,需要提供给算法更多的信息(例如,通过执行特征提取)来做出准确的预测。在深度学习中,由于采用了深度人工神经网络的结构,算法可以通过自身的数据处理学习如何做出准确的预测。表1更详细地比较了这两种技术:
表1 深度学习与传统机器学习比对
传统机器学习 | 深度学习 | |
隐藏层数目 | 一个或少数几个隐藏层。 | 非常多的隐藏层。 |
数据点数量 | 可以使用少量数据进行预测。 | 需要使用大量的训练数据进行预测。 |
硬件依赖性 | 可以在低端机器上工作。它不需要大量的计算能力。 | 依赖高端机器。它执行大量的矩阵乘法运算。GPU可以有效地优化这些操作。 |
特征化过程 | 需要用户参与。 | 从数据中自动学习特征。 |
执行时间 | 训练所需时间相对较少,从几秒钟到几个小时不等。 | 由于深度学习算法涉及多个层次,因此通常需要很长时间进行训练。 |
输出 | 输出通常是一个数值,如分数或分类。 | 输出可以有多种格式,如文本、乐谱或声音。 |
【深度学习的三教父】
约书亚·本吉奥(Yoshia Bengio,出生1964.3.5)是加拿大的计算机科学家,最著名的是他在人工神经网络和深度学习方面的工作。 他是蒙特利尔大学计算机科学与运筹学系的教授,并且是蒙特利尔学习算法研究所的科学主任。
扬·勒村(Yann LeCun,出生1960.7.8)是一位法国计算机科学家,主要从事机器学习,计算机视觉,移动机器人和计算神经科学领域的研究。 他是纽约大学库兰特数学科学研究所的银教授,并且是Facebook副总裁兼首席AI科学家。
杰弗里·辛顿(Geoffrey Everest Hinton,出生1947.12.6),是英国和加拿大认知心理学家和计算机科学家,最著名的是他在人工神经网络方面的工作。自2013年以来,他将在谷歌和多伦多大学工作的时间一分为二。2017年,他共同创立并成为多伦向量研究所(Vector Institute,人工智能研究机构)的首席科学顾问。
 图2 勒村(左)和辛顿(中)和本吉奥(右),
图2 勒村(左)和辛顿(中)和本吉奥(右),
2018年图灵奖授予了三位研究人员,他们为当前的人工智能繁荣奠定了基础。本吉奥,勒村和辛顿有时被称为“ AI的教父”,因其开发深度学习领域的工作而获奖。这三人在20世纪90年代和21世纪00年代开发的技术,在计算机视觉和语音识别等任务上实现了重大突破。他们的工作支持了从无人驾驶汽车到自动医疗诊断的AI技术的发展。
早在1970年代中期,“ AI寒冬”减少了对人工智能研究的资金投入和热情。但杰弗里·辛顿却坚守在神经网络研究的领域:模拟神经节点网络的发展,以模仿人类思想的能力。1986年,辛顿和其他几位研究人员,通过证明不止一小部分神经网络可以通过反向传播进行训练,帮助神经网络用于改进形状识别和单词预测。2012年,杰弗里·辛顿与他的学生亚历克斯·克里泽夫斯基(Alex Krizhevsky,出生于乌克兰,在加拿大长大)、伊利亚·萨茨凯(Ilya Sutskever)一起,改进了卷积神经网络,共同开发的一个程序,大大超越了ImageNet的所有其他参赛者,这是一项涉及上千种不同对象类型的图像识别竞赛。辛顿团队在一个“6000万个参数和65万个神经元”的网络(由“5个卷积层,其中一些层后面是最大池化层”组成的)中使用图形处理器芯片。“卷积层”是勒村最初设想的一种方法,辛顿的团队对此进行了重大改进。辛顿长期以来还坚持他对“无监督”训练系统潜力的信念,在这种系统中,学习算法试图在不提供大量标记示例的情况下识别特征。辛顿认为,这些无监督学习方法不仅有用,而且使我们更接近于了解人脑所使用的学习机制。
1988年,雅恩·勒村开发了一种生物启发的图像识别模型——卷积神经网络,并将其应用于光学字符识别。勒村提出了一个早期版本的反向传播算法,并基于变分原理对其进行了清晰的推导。1998年开发了LeNet5,并制作了被杰弗里·辛顿称为“机器学习界的果蝇”的经典数据集MNIST。勒村于2003年离开工业研究,在纽约大学的库兰特数学科学研究所(Courant Institute of Mathematical Institute)担任计算机科学教授,这是美国应用数学研究的领先中心。它在科学计算中有很强的地位,尤其侧重于机器学习。在纽约大学,勒村在计算和生物学习实验室,继续从事机器学习算法和计算机视觉应用的研究。勒村保持了他对建造的热爱,包括建造飞机、电子乐器和机器人的兴趣爱好。从2013年12月起,他被Facebook聘用从事人工智能研究,现在是Facebook的首席AI科学家。
2000年,约书亚·本吉奥撰写了一篇里程碑式的论文《神经概率语言模型》(参考资料[2]),对自然语言处理任务(包括语言翻译、问答和视觉问答)产生了巨大而持久的影响。自2010年以来,本吉奥关于生成性深度学习的论文,特别是与他的博士生伊恩·古德费洛(Ian Goodfellow)共同开发的生成性对抗网络(GAN),在计算机视觉和计算机图形学领域引发了一场革命。本吉奥本人曾与他人共同创立了几家初创公司,其中最著名的是2016年的Element AI,该公司为深度学习技术开发工业应用程序。2017年约书亚·本吉奥和伊恩·古德费洛、亚伦·库维尔出版了《深度学习》一书,是深度学习领域奠基性教材,又名“花书”,被誉为深度学习的“圣经”。
【21世纪10年代深度学习技术突破】
以物体识别为标志,从传统机器学习到深度学习的转变,大约发生在21世纪10年代初。但在2010年之前几年,已经已经为此转变做了准备,包括算法(“深度学习”)、建立图像数据库(“ImageNet”)和提升算力(“GPU”)。
大约在2016年之后,深度学习显示出令人印象深刻的结果,首先是在语音识别,然后是计算机视觉,最近是在自然语言处理方面。由此产生的算法,在学术和工业应用领域,引发了一场深度学习革命。
以下简单回顾发展历程。
2006年,杰弗里·辛顿等人说。发表了一篇论文(参考资料[1]),展示了如何训练一个能够以最先进的精度识别手写数字的深度神经网络(>98%)。他们称这种技术称为“深度学习”。深度神经网络是大脑皮层一个非常简化的模型,由一叠人工神经元层组成。
2008年,吴恩达(Andrew NG)在斯坦福的研究小组开始提倡使用GPU来训练深层神经网络,以将训练时间缩短数倍。这为在海量数据上进行有效的训练带来了深度学习领域的实用性。
2009年,斯坦福大学的人工智能教授李飞飞(Fei Fei Li)推出了ImageNet。李飞飞是一位华裔美国计算机科学家。ImageNet项目是一个大型可视化数据库,设计用于视觉对象识别软件的研究。超过1400万张图片已经被该项目手工标注,包含20000多个类别。李飞飞教授说:“我们的愿景是,大数据将改变机器学习的工作方式。数据驱动学习。”

图3 李飞飞
2011年,约舒亚·本吉奥等在他们的论文“深度稀疏整流神经网络”中表明,ReLU激活函数可以避免消失梯度问题。这意味着,除了GPU,深度学习社区还有另一个工具,来避免深度神经网络训练时间过长和不切实际的问题。
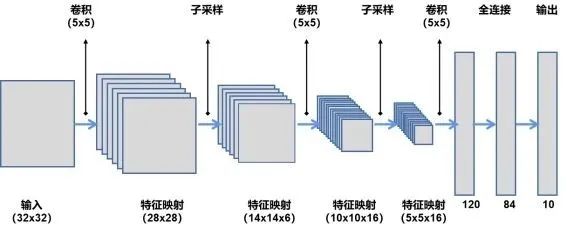
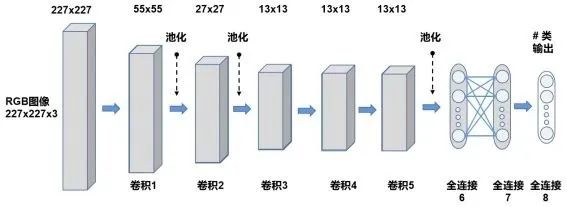
2012年,多伦多大学教授杰弗里·辛顿和他的学生亚历克斯·克里热夫斯基(Alex Krizhevsky)以及另外一个学生,建立了一个名为AlexNet的计算机视觉神经网络模型,参加ImageNet的图像识别比赛。参赛者将使用他们的系统处理数以百万计的测试图像,并以尽可能高的精度识别它们。AlexNet以不到亚军一半的错误率赢得了比赛。这场胜利在全球引发了一场新的深度学习热潮。AlexNet是在多年前由雅恩·勒村建造的LeNet5(图4A)基础上,发展和改进的。AlexNet是一种用于图像分类的多层卷积神经网络(图4B)。AlexNet架构包括5个卷积层和3个完全连接层(对比而言,LeNet是一个5层的卷积神经网络模型,它有两个卷积层和3个全连接层)。
 (A)
(A)
 (B)
(B)
图4 LeNet-5(A)和AlexNet的计算机视觉神经网络模型(B)
2012年,Google Brain发布了一个被称为“猫实验”的不寻常项目的结果。该项目探索了“无监督学习”的困难。猫实验使用了分布在一个由16000台电脑组成的网络,通过观看YouTube视频中的1000万张“未标记”的图片,训练自己识别猫。在训练结束时,发现最高层的一个神经元对猫的图像有强烈的反应。该项目的创始人吴恩达说:“我们还发现了一种对人脸反应非常强烈的神经元。”。
2014年,生成型对抗性神经网络也称为GAN,是由伊恩·古德费洛(Ian Goodfellow)创建的。GANs凭借其合成真实数据的能力,在时尚、艺术、科学等领域开启了一扇全新的深度学习应用之门。
2016年,DeepMind的深度强化学习模型AlphaGo在复杂的围棋游戏中击败了人类冠军。
2019年,本吉奥、勒村和辛顿因其在深度学习和人工智能领域的巨大贡献,获得2018年度图灵奖。
2020年,OpenAI发布GPT-3,这是一种具有1,750亿个参数的自然语言深度学习模型。同年,DeepMind公司开发的人工智能程序AlphaFold2预测蛋白质结构堪比实验室水平。
【结语】
20世纪探索感知机和人工神经网络的科学家,都是基于这样的想法,即类似的网络可能像人的大脑一样,能够学习识别物体或执行其他任务。深度学习在21世纪10年代取得了辉煌的成就,成为驱动人工智能繁荣的动力。深度学习的成功已经用于在照片中识别物体或分类,自动驾驶汽车,游戏,自动机器翻译,图像字幕生成,文本生成,不同化学结构的毒性检测,预测蛋白质的 3D 结构形状等。深度学习已经变成了一种颠覆性的技术。总有一天,无人驾驶汽车会比你更了解道路,驾驶技能更高;深入的学习网络会诊断你的疾病。
“漫谈”的四篇博客(人工智能的第一项工作、感知机的兴衰、神经网络的复苏和深度学习的辉煌),回顾了神经网络和深度学习的从20世纪40年代至今的发展的若干重要事件,可以看出:(1)多学科协同研究很重要。(2)对新技术不要仓促否定,也不要夸张宣传。(3)科学家的坚持不懈的努力,造就了今天深度学习的辉煌和人工智能的繁荣。
深度学习的繁荣,也反映在出版有许多有关深度学习的图书,特别是有关深度学习编程的工具箱,对进一步学习提供很多便利(例如,[3],[4]和[5])。
参考资料:
[1] Geoffrey E. Hinton et al., “A Fast Learning Algorithm for Deep Belief Nets,” Neural Computation 18 (2006): 1527–1554
[2] Yoshua Bengio, Rejean Ducharme and Pascal Vincent . A Neural Probabilistic Language Model . NIPS'2000, 932-938. MIT Press
[3] Ivan Vasilev, Daniel Slater, Gianmario Spacagna, Peter Roelants, Valentino Zocca. Python Deep Learning. 2nd Edition. Packt. 2019
[4] Aurélien Géron. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition. Oreilly. 2019
[5] Pramod Singh, Avinash Manure. Learn TensorFlow 2.0: Implement Machine Learning And Deep Learning Models With Python. Apress. 2020
链接地址:http://blog.sciencenet.cn/blog-3005681-1281688.html
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


