
- 1[ NLP ] 自然语言处理必读论文及预训练模型(2019.10.28更)_自然语言处理论文
- 2ollama离线与在线安装_linux ollama离线更换模型
- 3微信小程序 - 分享商品海报_微信小程序 商品海报
- 4Mac 下git环境升级_mac curl update git
- 5工作中写单片机代码,与学校里有什么不同?
- 6【本地大模型部署与微调】ChatGLM3-6b、m3e、one-api、Fastgpt、LLaMA-Factory_oneapi m3e
- 7Idea合并git分支_git用idea合并分支
- 8Linux文件权限_linux 文件权限
- 9ARM、MCU、DSP、FPGA、SOC各是什么?有什么区别?_mcuarmdspfpgacpu有什么区别
- 10完美解析车头时距THW与碰撞时间TTC的区别_车头时距计算公式
新架构Mamba更新二代!作者:别争了,数学上Transformer和SSM是一回事
赞
踩
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
Transformer挑战者、新架构Mamba,刚刚更新了第二代:
Mamba-2,状态空间扩大8倍,训练速度提高50%!
更重要的是,团队研究发现原来Transformer和状态空间模型(SSM)竟然是近亲??
两大主流序列建模架构,在此统一了。
没错,这篇论文的提出的重磅发现:Transformer中的注意力机制与SSM存在着非常紧密的数学联系。
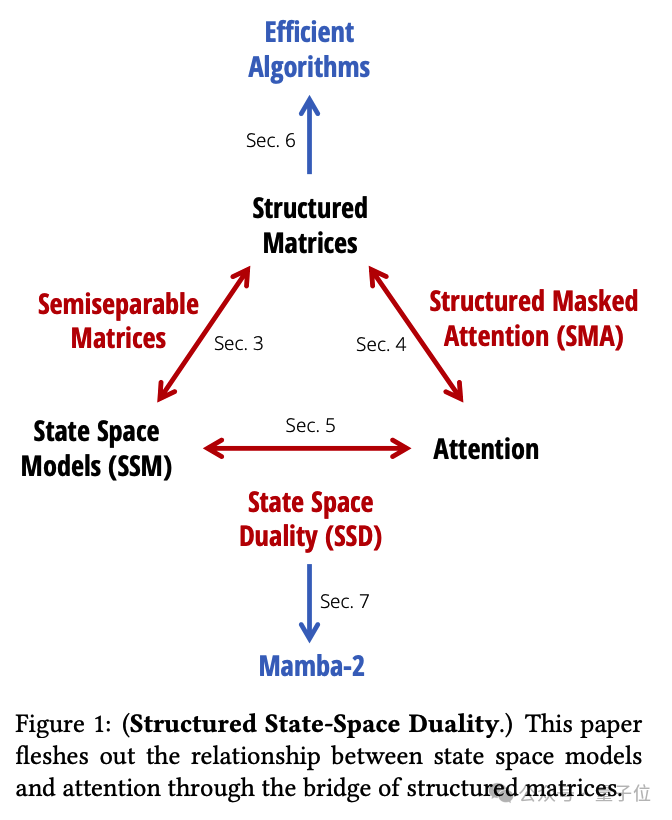
团队通过提出一个叫结构化状态空间二元性(Structured State Space Duality,SSD)的理论框架,把这两大模型家族统一了起来。
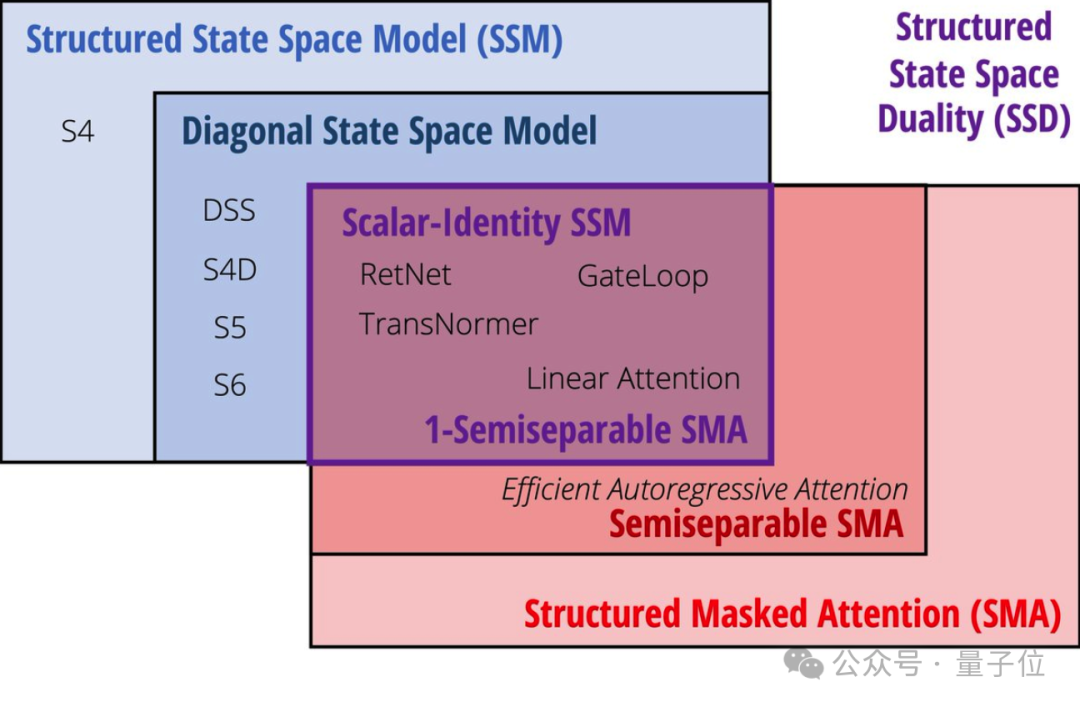
Mamba一代论文年初被ICLR拒稿,当时还让许多学者集体破防,引起一阵热议。
这次二代论文在理论和实验上都更丰富了,成功入选ICML 2024。

作者依然是Albert Gu和Tri Dao两位。
他们透露,论文题目中“Transformers are SSMs”是致敬了4年前的线性注意力经典论文“Transformers are RNNs”。

那么,SSM和注意力机制究竟是怎么联系起来的,Mamba-2模型层面又做出哪些改进?
统一SSM和注意力机制
Transformer的核心组件是注意力机制,SSM模型的核心则是一个线性时变系统。
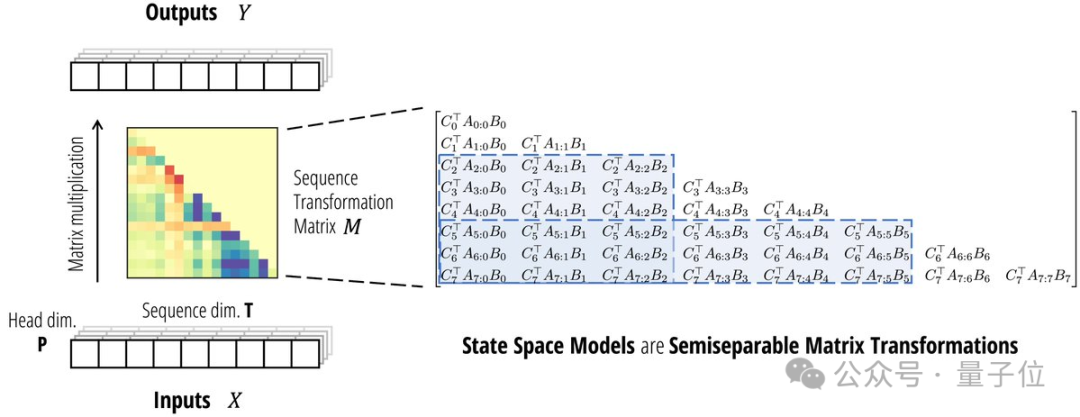
两者看似不相关,但论文指出:它们都可以表示成可半分离矩阵(Semiseparable Matrices)的变换。
先从SSM的视角来看。
SSM本身就定义了一个线性映射,恰好对应了一个半可分离矩阵。
半可分离矩阵有着特殊的低秩结构,这种结构又恰好对应了SSM模型中的状态变量。
于是,矩阵乘法就相当于SSM的线性时变系统了。带选择性的SSM本质上就是一种广义线性注意力机制。
从注意力的视角看又如何?
团队试图以更抽象方式来刻画注意力机制的本质,毕竟“Softmax自注意力”只是众多可能形式中的一种。
更一般地,任意带掩码的注意力机制,都可以表示为4个张量的缩并(Contraction)。
其中QKV对应注意力中的query,key,value,L对应掩码矩阵。

借助这一联系,它们在线性注意力的基础上提出了结构化掩码注意力SMA(Structured Masked Attention)。
当注意力的掩码矩阵是半可分离的,就与SSM等价了。
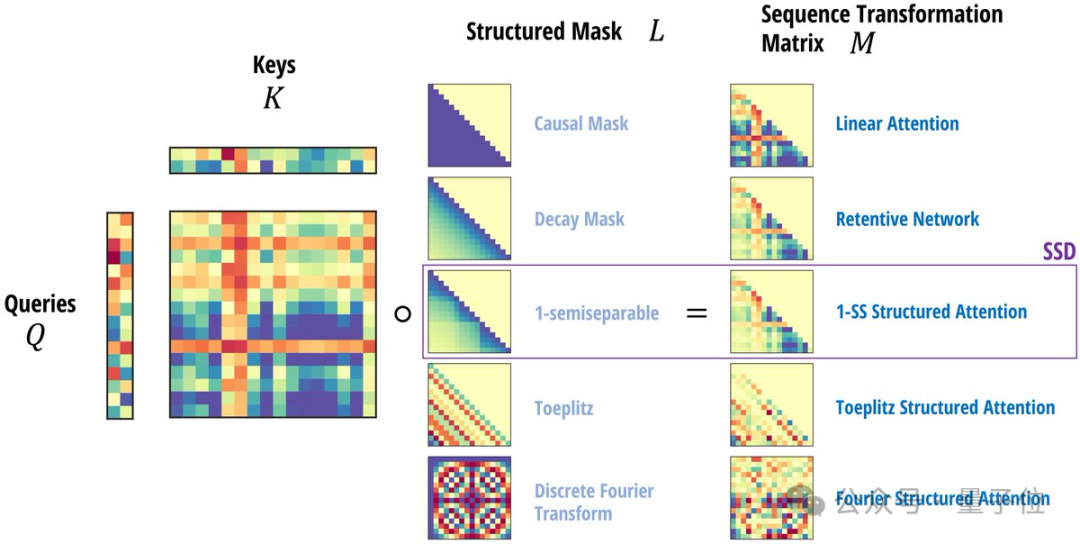
基于这个发现,作者进一步推导出两种等价的计算形式,这就是本文核心思想”状态空间二元性”SSD的由来。
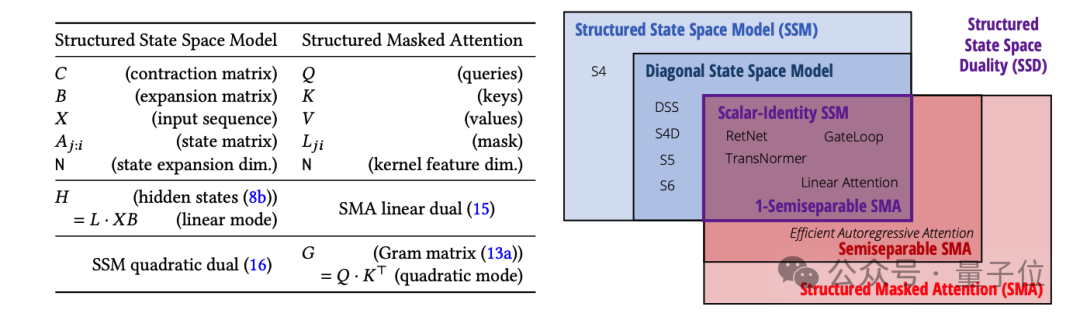
Mamba-2:更强学习能力,更快训练推理
基于SSD思想的新算法,Mamba-2支持更大的状态维度(从16扩大到256),从而学习更强的表示能力。
新方法基于块分解矩阵乘法,利用了GPU的存储层次结构,提高训练速度。
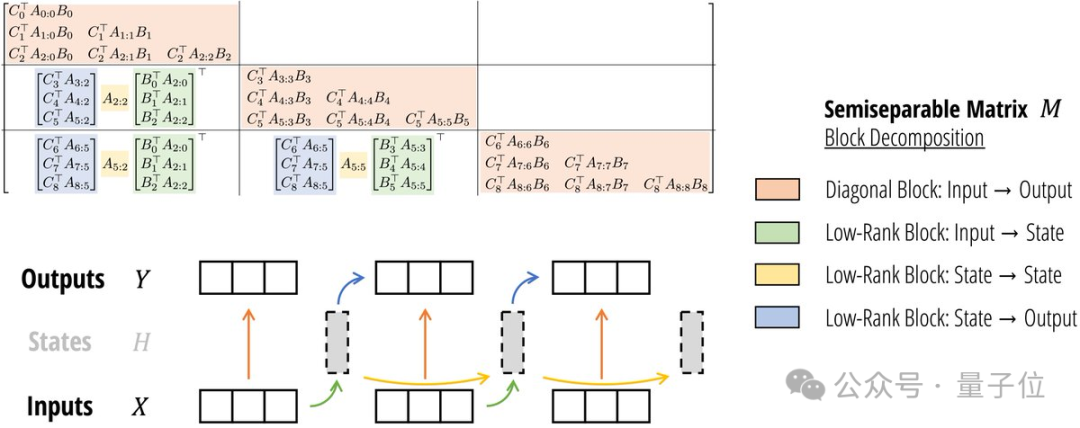
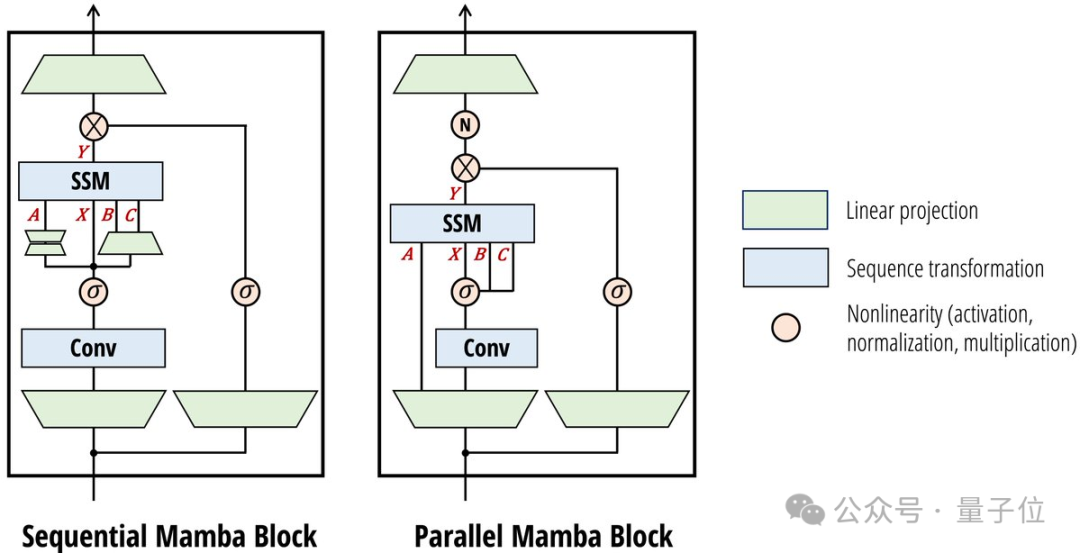
架构设计上,Mamba-2简化了块的设计,同时受注意力启发做出一些改动,借鉴多头注意力创建了多输入SSM。
有了与注意力之间的联系,SSD还可以轻松将Transformer架构多年来积累起来的优化方法引入SSM。
比如引入张量并行和序列并行,扩展到更大的模型和更长的序列。
又比如引入可变序列长度,以实现更快的微调和推理。
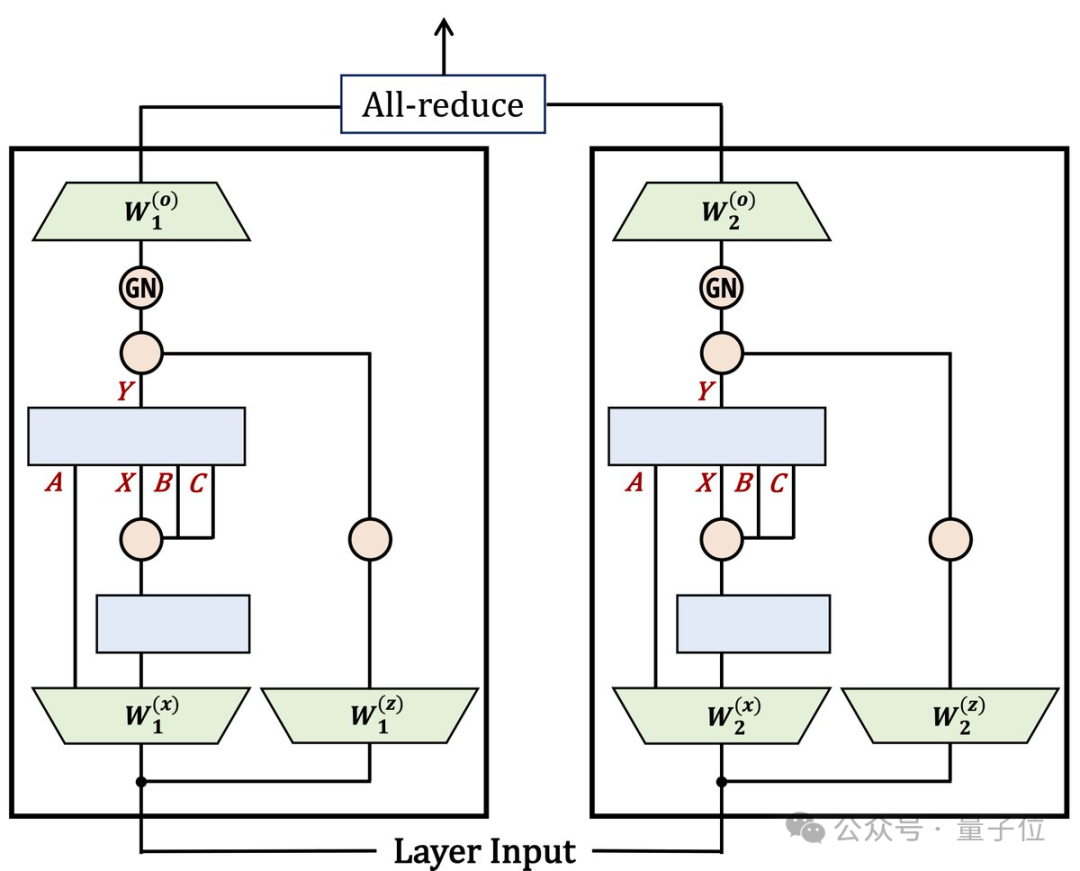
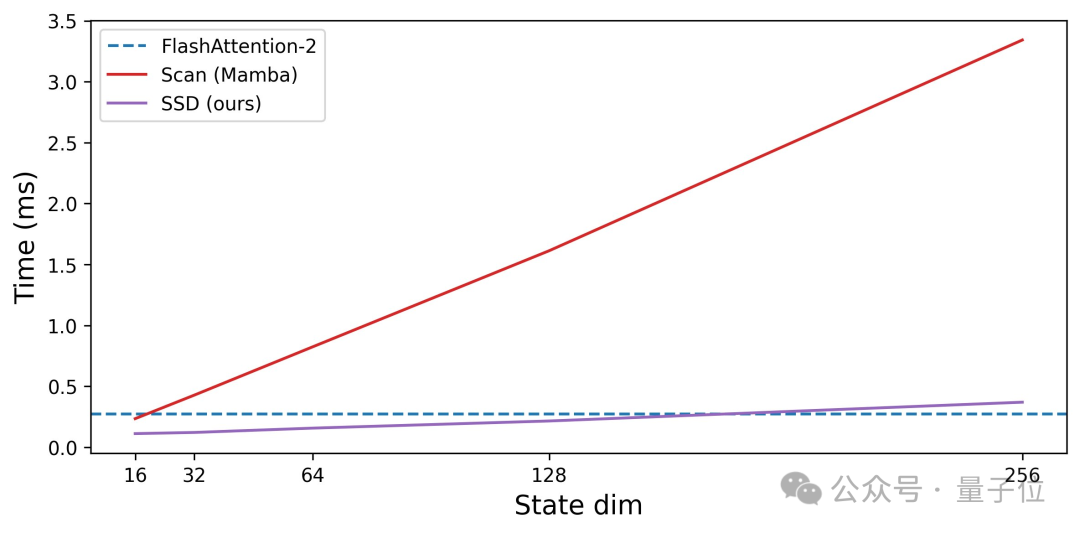
Mamba-2的SSD层比Mamba-1中的关联扫描快很多,使团队能够增加状态维度并提高模型质量。
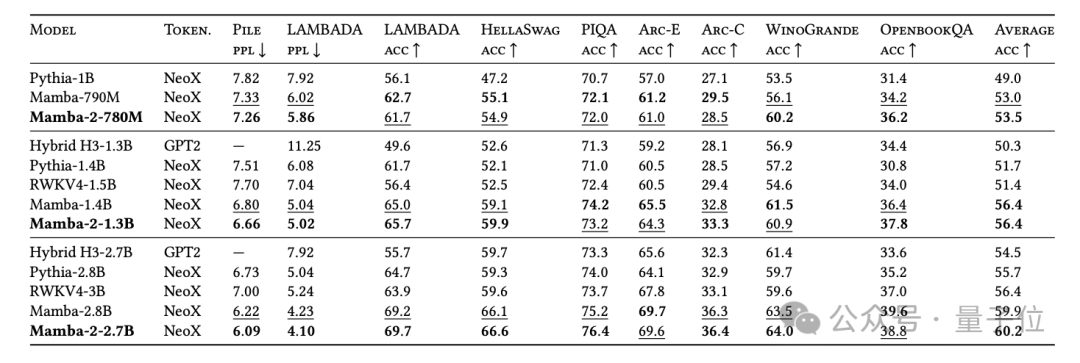
实验中,3B参数规模的Mamba-2,在300B tokens训练,超越了相同规模的Mamba-1和Transformer。
Mamba-2在需要更大状态容量的任务上比Mamba-1有了显著改进,例如硬关联召回任务 (MQAR)。
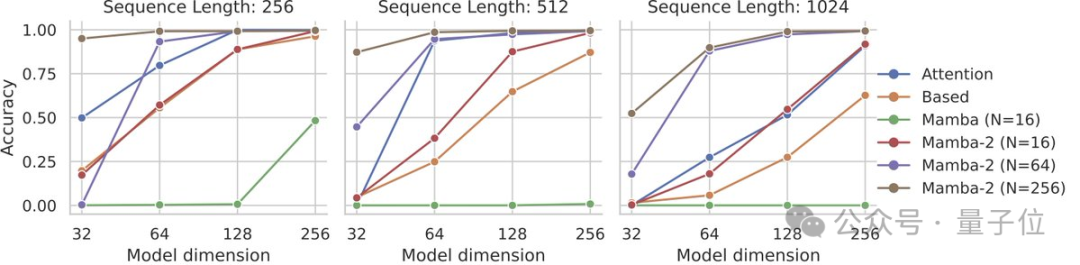
团队还对Mamba-2+注意力的混合架构模型做了一些实验。发现4-6个注意力层与Mamba-2层混合模型的性能,甚至优于Transformer++(原版结构+现代最佳实践)和纯Mamba-2。

作者Tri Dao认为,这说明了Attention和SSM两种机制可以互为补充,另外他还提出了对未来研究方向的思考。

最后,除了52页的论文之外,两位作者还撰写了四篇更易读的系列博客文章。

他们特别建议:先看博客,再看论文。
对Mamba-2模型或者状态空间二元性理论感兴趣的,可以读起来了~
博客(两个地址内容一样):
https://tridao.me/blog/
https://goombalab.github.io/blog/
论文:
https://arxiv.org/abs/2405.21060
代码和模型权重:
https://github.com/state-spaces/mamba
参考链接:
[1]https://x.com/_albertgu/status/1797651240396144758
[2]https://x.com/tri_dao/status/1797650443218436165
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/692640

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

