
- 1金三银四-帮你改简历:助你有份好工作
- 2数据驱动的产品创新项目管理:如何确保项目成功
- 3kafka在线扩展、并重新分区_kafka动态增加分区
- 4Git报错: error: RPC failed; curl 56 HTTP/2 stream 5 was reset; send-pack: unexpected disconnect_rpc failed;curl 56
- 5科普大佬说 | 智能仿生机器鱼
- 6重要:升级 Android14 后出现报错:One of RECEIVER_EXPORTED or RECEIVER_NOT_EXPORTED should be specified ……_com.jeremyliao.liveeventbus.core.liveeventbuscore.
- 7Dotnet接口-达梦数据库增删改查
- 8【LeetCode-面试-股票问题】算法中所有股票问题汇总_股票问题编程
- 9计算机的CPU和GPU的区别,GPU与CPU的区别
- 10鸿蒙OS开发:【一次开发,多端部署】(典型布局场景)
大模型时代,是 Infra 的春天还是冬天?
赞
踩
Highlights
-
大模型时代元年感悟
-
Scaling Laws 是大模型时代的摩尔定律,是最值得研究的方向
-
LLM 发展的三个阶段: 算法瓶颈 -> 数据瓶颈 -> Infra 瓶颈
-
为什么 GPT 一枝独秀, BERT、T5 日落西山?
-
大模型时代,是大部分 Infra 人的冬天,少部分 Infra 人的春天(算法研究者 同理)
前言
2023 是我过往人生经历中最传奇的一年(虽然只过去了 3/4),年初 ChatGPT 爆火让所有人看到了 AGI 可能实现的曙光,无数创业公司、大厂立即跟进 LLM 甚至 ALL IN, 紧随而来的 GPT-4 和 Office Copilot 让市场沸腾。当时感觉,AI 时代的技术迭代速度以天记,汹涌的 AI 技术革命将迅速影响每个人的生活。从技术发展曲线来看, GPT-4 的发布应该是市场关注度的峰值:
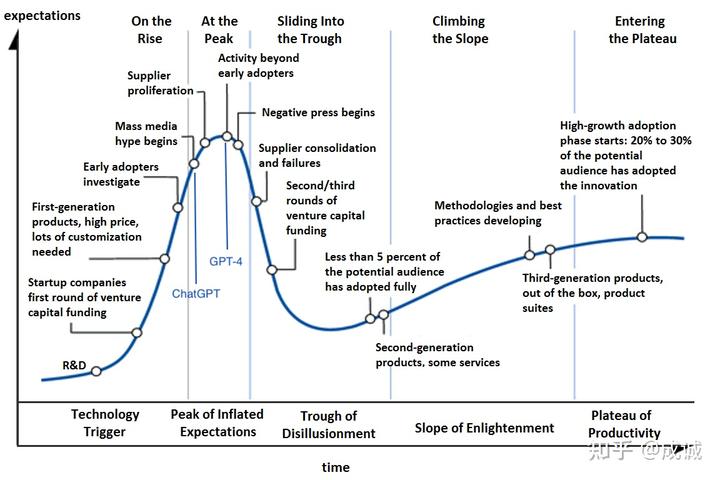
LLM 技术成熟度曲线(大致)
那时某人也有幸跟随袁老师加入老王创立的光年之外,在低头开发分布式深度学习框架 OneFlow 六年之后,幸运的站在了时代旋涡的中心(两个月 AI 独角兽 体验卡),也第一次体验了实操千卡集群做大模型训练究竟是怎样的,瓶颈在哪里(其实很多实际经验和预先设想的相悖)。
最近 DALL·E 3 和 GPT-4V 相继出炉,OpenAI 的图片理解和生成能力都有很大的提升。 不过无论是 资本市场 还是 媒体关注度 其实都相对冷静下来了, AI 时代的技术迭代速度也不是按天革新的, 商业化能力更是遭到投资人的质疑。虽然所有人都认可未来是 AI 的时代,但在中短期内 AI 如何盈利是一个头大的问题,只有卖 GPU 的 NVIDIA 着实赚了钱。
对于做 AI Infra / MLSys 方向的我来说, 大模型的机会是既激动又悲哀的。 激动的是:终于有机会在之前难以想象的尺度上解决复杂的、最前沿的工程问题,且能产生巨大的经济成本和时间成本收益。 悲哀的是: 随着 GPT 一统江湖,以及能真正训练超大模型的机会稀缺,一个通用的分布式深度学习框架和通用并行优化算法已经失去了其意义(深度学习编译器同理, 在大模型训练侧,一定是手工优化最优,参考 FlashAttention

