
- 1brew安装指定版本mysql,使用 Homebrew 安装指定版本的软件
- 2毕业设计-基于深度学习的苹果树叶面病虫害识别算法系统 机器学习
- 3【学习】FPGA verilog 编程使用vscode,资源占用多 卡顿 卡死 内存占用多解决方案
- 4【pkuseg】由于网络策略组织下载请求,因此直接在github中下载细分领域模型medicine_pkuseg github
- 5llama-factory微调大模型
- 6UnityEditor.Graphs.Edge.WakeUp () 关于此报错
- 7DFS:解决二叉树问题
- 8文献速递:PET-影像组学专题--PET衍生的影像组学和人工智能在乳腺癌中的应用:一篇系统综述_影像基因组学优秀文章
- 9Redis教程(二十一):Redis怎么保证缓存一致性
- 10Self-training and Pre-training are Complementary for Speech Recognition自训练和与预训练在语音识别中的互补
ubuntu18.04 安装yolov5环境及推理环境_ubuntu18.04下yolov5
赞
踩
1、安装anaconda3
官方网网址
https://www.anaconda.com/download#downloads
- 1
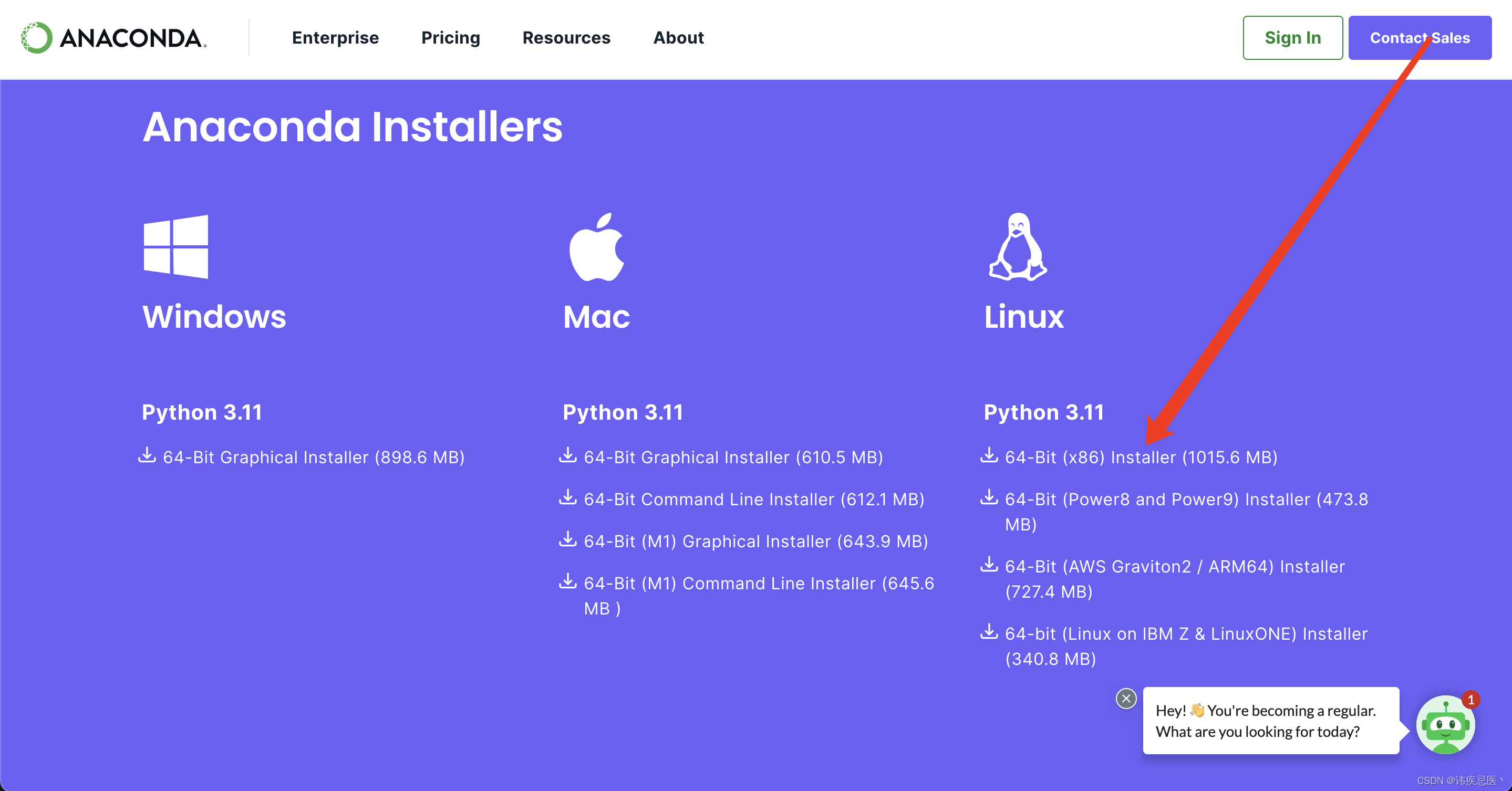
去到下载的文件夹内,执行命令:bash Anaconda3-2023.09-0-Linux-x86_64.sh


1.2、环境变量配置
vim ~/.bashrc
// 加入安装目录,换成你前面设置的安装目录
export PATH=/root/yes/condabin:$PATH
// 刷新当前用户环境(激活环境)
source ~/.bashrc
// 查看版本
conda -V
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1.3、添加/更换 conda 清华源
conda config --add channels 'https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/' #必需
conda config --add channels 'https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/' #必需
conda config --set show_channel_urls yes
- 1
- 2
- 3
- 4
2、安装pytorch1.6
1、创建虚拟环境
conda create -n pytorch1.6 python=3.8
2、python安装pytorch1.6
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
3、设置python的环境变量
alias python='/root/yes/envs/yolov5/bin/python3.8'
4、下载yolov5-v3版本代码
git clone https://github.com/ultralytics/yolov5.git
或下载yolov5版本v3.1 https://github.com/ultralytics/yolov5/releases/tag/v3.1
5、在volov5路径下执行
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
6、验证
python detect.py --source ./inference/images/ --weight weights/yolov5s.pt --conf 0.4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3、CUDA安装
# 选择生成软链接,不需要安装驱动
sudo sh cuda_11.7.89_440.33.01_linux.run
# 查看CUDA版本
cat /usr/local/cuda/version.txt
# 测试CUDA,安装成功则显示PASS
cd /usr/local/cuda-11.7/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4、安装cuDNN
官网网址
https://developer.nvidia.com/rdp/cudnn-download
- 1
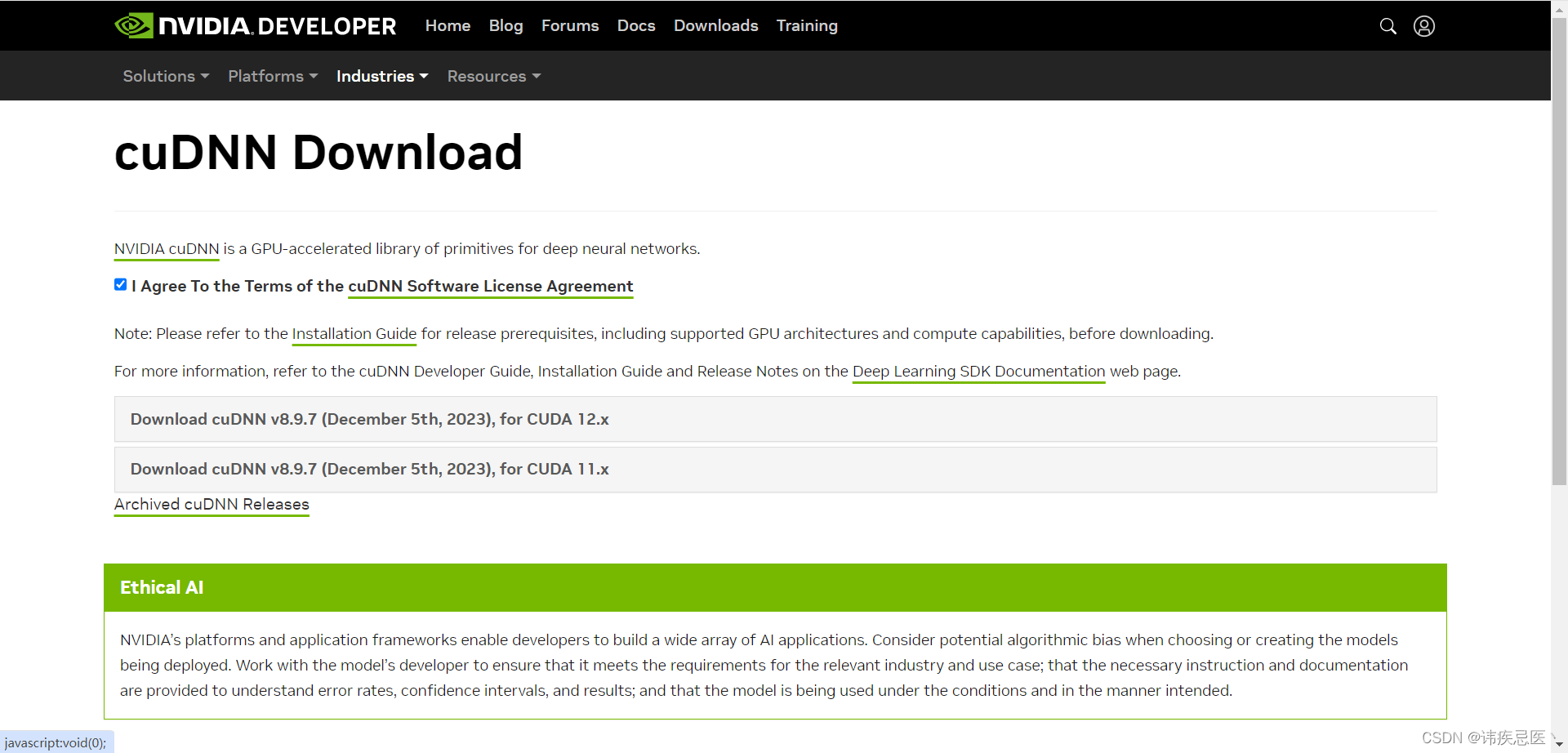
1、解压到当前目录
tar -xf cudnn-linux-x86_64-8.9.7.29_cuda11-archive.tar.xz
2、拷贝头文件和库到cuda目录下
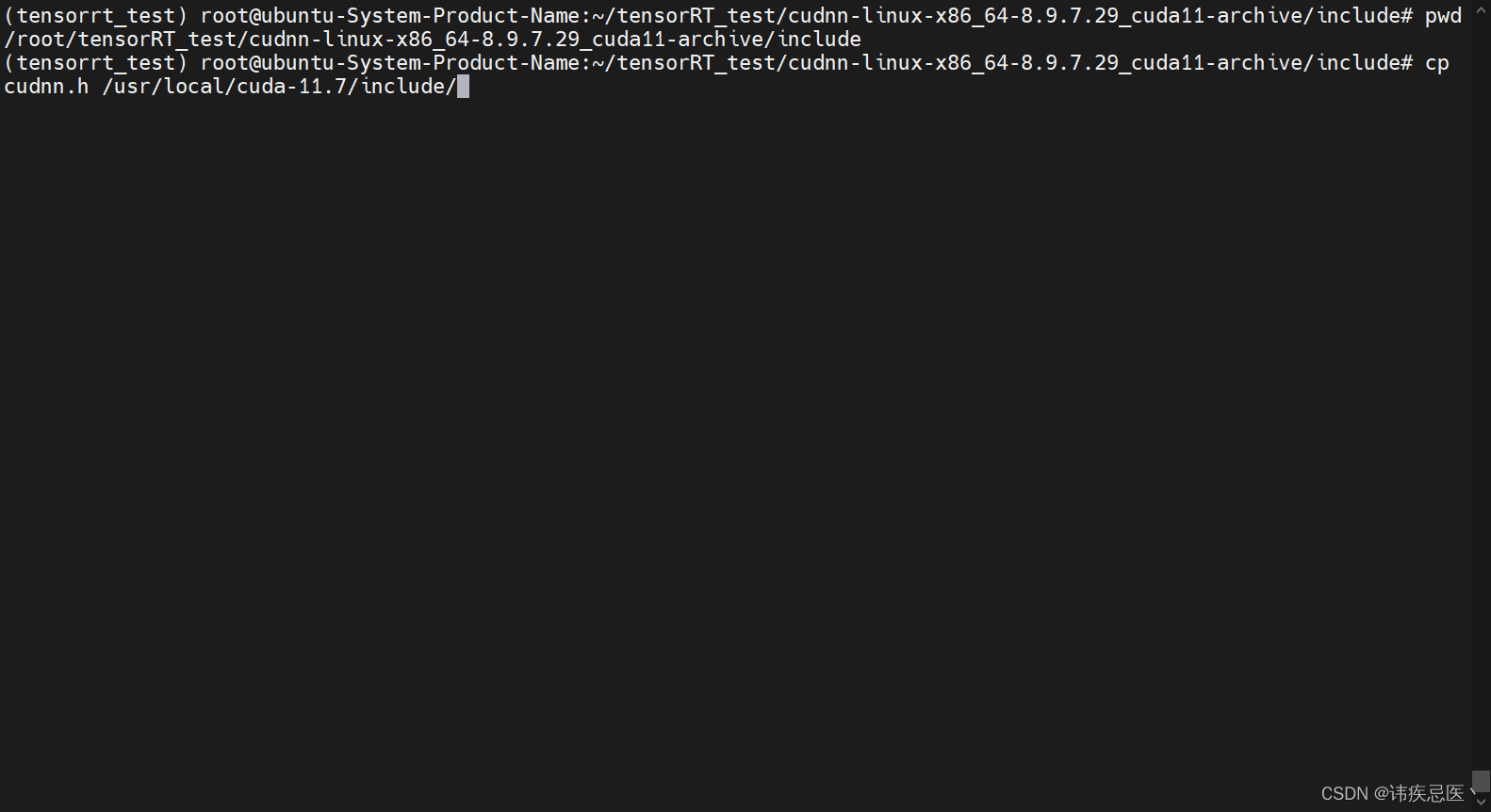
进入目录(拷贝头文件)
cd /cudnn-linux-x86_64-8.9.7.29_cuda11-archive/include
cp cudnn.h /usr/local/cuda-11.7/include/
进入目录(拷贝库)
cd cudnn-linux-x86_64-8.9.7.29_cuda11-archive/lib
cp libcudnn* /usr/local/cuda-11.7/lib64
chmod a+r /usr/local/cuda-11.7/include/cudnn.h
chmod a+r /usr/local/cuda-11.7/lib64/libcudnn*
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
查看版本
cat cudnn-linux-x86_64-8.9.7.29_cuda11-archive/include | grep CUDNN_MAJOR -A 2
- 1
至此CUDN + cuDNN安装完成,可以执行相关训练文件查看是否有gpu信息输出,或监控一下gpu状态
watch -n 1 nvidia-smi
- 1
5、安装tensorRT
查看是否安装NVIDIA显卡
lspci | grep -i nvidia
- 1
查看显卡信息
nvidia-smi
- 1
tensorRT官网网址(GA表示正式发布稳定版本、EA抢先版)
https://developer.nvidia.com/nvidia-tensorrt-8x-download
- 1
1、解压
tar zxf TensorRT-8.0.1.6.Linux.x86_64-gnu.cuda-11.3.cudnn8.2.tar.gz
2、移动
mv TensorRT-8.0.1.6 /opt
测试:
cd /opt/TensorRT-8.5.1.7/samples
make
cd cd /opt/TensorRT-8.5.1.7/bin
./sample_mnist
3、配置环境变量
vim ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/TensorRT-8.0.1.6/lib
export LD_INCLUDE_PATH=$LD_INCLUDE_PATH:/opt/TensorRT-8.0.1.6/include
source ~/.bashrc
4、安装python API
cd /opt/TensorRT-8.5.1.7/python
pip install tensorrt-7.1.3.4-cp37-none-linux_x86_64.whl
5、安装 Python UFF 包,支持tensorflow模型转化
cd /opt/TensorRT-8.5.1.7/uff
pip install uff-0.6.9-py2.py3-none-any.whl
# 测试 Python UFF 是否安装成功
which convert-to-uff
6、安装 graphsurgeon,支持自定义结构
cd /opt/TensorRT-8.5.1.7/graphsurgeon
pip install graphsurgeon-0.4.5-py2.py3-none-any.whl
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32

查看tensorRT python api 版本
python
import tensorrt as trt
print(trt.__version__)
- 1
- 2
- 3
安装pycuda
pip install cuda-python==11.7
6、安装opencv4.6
官网网址
https://opencv.org/releases/
- 1
1、解压
unzip opencv-4.6.0.zip
2、进入目录
cd opencv-4.6.0
3、创建目录进入目录
mkdir build
cd build
4、编译
cmake -D CMAKE_INSTALL_PREFIX=/usr/local -D CMAKE_BUILD_TYPE=Release -D OPENCV_GENERATE_PKGCONFIG=ON -D OPENCV_ENABLE_NONFREE=True ..
注解:
1. CMAKE_INSTALL_PREFIX 是opencv的安装地址 默认安装在 usr/local
2. CMAKE_BUILD_TYPE 是opencv安装的版本,Release和Debug两种可选,默认安装Release
3. OPENCV_ENABLE_NONFREE 是否使用部分被申请了专利的算方法 这里选True的话就可以使用了
4. OPENCV_GENERATE_PKGCONFIG 强烈建议开启这个 设置为ON OPENCV_GENERATE_PKGCONFIG 因为opencv4默认不生成.pc文件,所以加上这句用于生成opencv4.pc文件,支持pkg-config功能。opencv4版本及以上 这里用ON
5、cmake 结束后执行 make指令
注:终端输入nproc 命令可以查看自己电脑有多少线程。我的电脑有8个,使用其中6个线程编译。
sudo make -j6 #在build 文件内 执行该命令 数字越大 后续make的过程就越快。
6、拷贝库
sudo make install
7、配置环境变量
vim ~/.bashrc
#文件末尾添加以下内容 并保存
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export PKG_CONFIG_PATH
执行
source ~/.bashrc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
修改动态库
#打开下列文件
sudo vim /etc/ld.so.conf.d/opencv.conf
# 添加lib路經 在 末尾 保存退出
/usr/local/lib
# 更新
sudo ldconfig
#终端输入以下两命令,显示正常则安装成功
pkg-config --modversion opencv4 #查看版本号
pkg-config --libs opencv4 #查看libs库
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
编译指令
CXX ?= g++
CXXFLAGS += -c -Wall $(shell pkg-config --cflags opencv4)
LDFLAGS += $(shell pkg-config --libs --static opencv4)
all: opencv_example
opencv_example: example.o; $(CXX) $< -o $@ $(LDFLAGS)
%.o: %.cpp; $(CXX) $< -o $@ $(CXXFLAGS) $(INC)
clean: ; rm -f example.o opencv_example
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
7、tensorRT部署yolov5模型推理
torch官网
https://pytorch.org/
- 1
进入虚拟环境
pip install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu117
- 1
模型转换
python export.py --weights yolov5s.pt --include engine --device 0
# 需要指定尺寸,因为tensort推理的时候不会做缩放,要求尺寸统一(FP32)
python export.py --weights yolov5s.pt --include engine --device 0 --img 384 640
# 半精度推理(推理也需要加上half)FP16
python export.py --weights yolov5s.pt --include engine --device 0 --img 384 640 --half
测试推理
python detect.py --weights yolov5s.engine
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
yolov5-pytorch推理速度
image 1/2 /root/tensorRT_test/test/yolov5-7.0/data/images/bus.jpg: 640x480 4 persons, 1 bus, 41.1ms
image 2/2 /root/tensorRT_test/test/yolov5-7.0/data/images/zidane.jpg: 384x640 2 persons, 2 ties, 41.2ms
Speed: 0.2ms pre-process, 41.1ms inference, 0.7ms NMS per image at shape (1, 3, 640, 640)
tensort推理
image 1/2 /root/tensorRT_test/test/yolov5-7.0/data/images/bus.jpg: 640x640 4 persons, 1 bus, 2.9ms
image 2/2 /root/tensorRT_test/test/yolov5-7.0/data/images/zidane.jpg: 640x640 2 persons, 2 ties, 2.9ms
Speed: 0.5ms pre-process, 2.9ms inference, 0.8ms NMS per image at shape (1, 3, 640, 640)
tensort推理(384*640)
image 1/2 /root/tensorRT_test/test/yolov5-7.0/data/images/bus.jpg: 384x640 3 persons, 1 bus, 2.0ms
image 2/2 /root/tensorRT_test/test/yolov5-7.0/data/images/zidane.jpg: 384x640 2 persons, 2 ties, 1.9ms
Speed: 0.5ms pre-process, 2.0ms inference, 0.8ms NMS per image at shape (1, 3, 384, 640)
Torchhub模型预测使用

