
- 1使用netlify实现自动化部署前端项目(无服务器版本)
- 2 小记安装ElasticSearch遇到的小坑
- 3从零开始,SpringBoot搭建WebSocket_springboot创建websocket
- 4动手学深度学习——循环神经网络(原理解释与代码详解)
- 5【Python机器学习】零基础掌握DecisionTreeClassifier决策树
- 6高光谱遥感数值建模技术及在植被、水体、土壤信息提取领域应用_利用光学遥感数据能实现对地表的植被、土壤、水域、建筑物等信息进行提取,但光学
- 7Linux命令之 echo 详解
- 8笔记-《A Survey of Large Language Models》- 尾声
- 9小程序预加载数据实战_getbackgroundfetchdata
- 10vue-cli5.x 集成 cesium_vue5 cli集成cesium
原创:旗舰游戏显卡(980Ti,1080Ti,TiTan V,2080Ti,3090,4090),AI画图stable diffusion)和大模型(chatglm2-6b)推理性能横评_2080ti22跑大模型推理
赞
踩
前言:
自从去年10月份以ChatGPT和stable diffusion的发布引发了一波生成式AI浪潮,但很多人特别是某些领导整天在会议上说人工智能带来的各种风险和不足,其实自己几乎没用过ChatGPT和stable diffusion,对生成式AI(AIGC)只有偏见!缺少实践对新生事物的理解和抓住机会是有害的,由于这一波AI浪潮带着复杂难懂的各种专业术语和昂贵的平台,给习惯了点击购买云主机的IT从业者和个人开发者带来了不小的门槛,加之最近美国实体名单居然把游戏显卡RTX4090都加入禁止出售给中国的实体清单,我觉得有必要在”廉价”游戏显卡上把大模型对话和stable diffusion画小姐姐的生成式AI在自己的PC机上跑起来!这样才能谈后面的体验和带来的机会。
原文首次发表于:https://zhuanlan.zhihu.com/p/663179436
以下评测数据都是自己花钱、花时间原创测试得到,希望给所有开发者实践大模型和AI画图予参考,有帮助和喜欢的朋友请收藏、关注和点赞,让人人都能够参与的AI才是真正的AI
测试环境说明:
测试平台硬件为:Intel Xeon Platinum 8360Y,256G内存(当然你用i3 cpu+16G内存也没有问题)
操作系统:开始用Linux Ubuntu 22.0.4,由于对比windows发现性能差异很小后面也有部分测试用了windows 10,
软件组件:这部分是重点,对性能有明显差异,所以特别强调
驱动安装的是537.42(980Ti 特别点用的只有低版本536.40)
CUDA: 12.2
python: 3.10.11
Pytorch: 2.0.1+cu121
transformers :在大模型对话(chatglm2-6b)用的是4.34.0;Stable difusion画小姐姐用的是4.30.0
大模型选用的是智谱AI与清华KEG实验室发布的中英双语对话模型chatglm2-6b,有60亿个参数,控制得当在980Ti的6Gb显存也勉强可以跑起来。参考:https://github.com/THUDM/ChatGLM2-6B
大模型加载webui用的官方text-generation-webui snapshot-2023-10-15最新版,参考:https://github.com/oobabooga/text-generation-webui
stable diffusion webui加载器用的官方v1.6版本,没用xformers,启动参数除了端口全部都默认,参考:https://github.com/AUTOMATIC1111/stable-diffusion-webui
模型用的:chilloutmix_Ni.safetensors
测试分为两部分,第一部分为stable diffusion的测试,用SD生成10张512*512 的图片,提示词prompt如下:
- masterpiece, best quality, realistic, 1girl,solo,25 years old,blue vest, blue skirt,white shirt,short sleeves,standing,<lora:officelady:0.7>office-lady
- Negative prompt: EasyNegative,glasses
- Steps: 20, Size: 512x512, Seed: 1194320243, Model: chilloutmix_NiPrunedFp32Fix, Version: v1.4.0, Sampler: Euler a, CFG scale: 7, Model hash: fc2511737a, "officelady: a8444e611ffc", Face restoration: CodeFormer
记录所用时间和speed的it/s
第二部分为本地大模型测试用text-generation-webui 和chatglm2-6b来测试2个问题,记录总时间和token/s,这部分测试由于回答内容的长度有区别所以记录的总时间仅提供参考,并不是很严谨,但不同卡的速度差异感受起来还是非常明显的。
问题1:请用以下关键词写一段有意境的散文。深秋、小溪、小舟、红叶、明月
问题2: 1个苹果=2个梨,3个梨=4个橙子,6个橙子=7个香蕉,56个香蕉等于多少个苹果?
接下来我们就准备正式开始测试,在开始之前简单说明一下测试的背景知识,AI领域需要算力的地方主要分为2种,一种叫做训练,第二种叫做推理。训练简单来说就是用原始数据去教AI知识最终“变成”为有知识的模型的过程,目前主流技术用的都是无监督学习。模型研究和开发者例如OpenAI在发布新模型之前都需要巨大的算力去训练模型,由于不是几块计算卡可以搞定的所以训练需要极高的互联带宽,这也是英伟达推出nvlink的初衷,在训练领域特别是大模型训练由于互联带宽差距比较大还不是游戏显卡的主战场。推理是已经有了模型用算力来接收各种请求,并且推理出答案的过程。比如我们有了训练完成的chatglm2-6b大语言模型需要加载聊天服务来对话,就需要算力做推理了。这部分由于对数据量和带宽的压力没有训练这么大,所以完全可以用游戏显卡来做,我们接下来测试的也是AI推理环境下各张游戏显卡的能力。

测试的主角登场,980Ti,1080Ti,TiTan V,2080Ti,3090,4090,价格从1000块钱到1万多块钱不等,都是各代旗舰游戏显卡,之所以用旗舰游戏显卡是综合考虑了价格和显存带宽之后的结果,毕竟各代旗舰卡和甜品卡无论显存大小还是显存带宽差距都非常大。以上几块卡的GPU-Z显示的基础规格如下:
980Ti:是2015年英伟达Maxwell架构产品,当年”泰坦皮”的公版就是从980Ti开始叫起来的,主要改进了上一代Kepler架构的效率问题,控制住了发热提升了效率成为一代经典游戏显卡。这张8年前的卡在stable diffusion中可以运行起来,测试一共用时2分33秒,speed:1.37it/s,平均每张图用时14秒,但可以看出来6G显存明显太小了,512*512都用了4.6G显存,尺寸再大一点就爆现存了!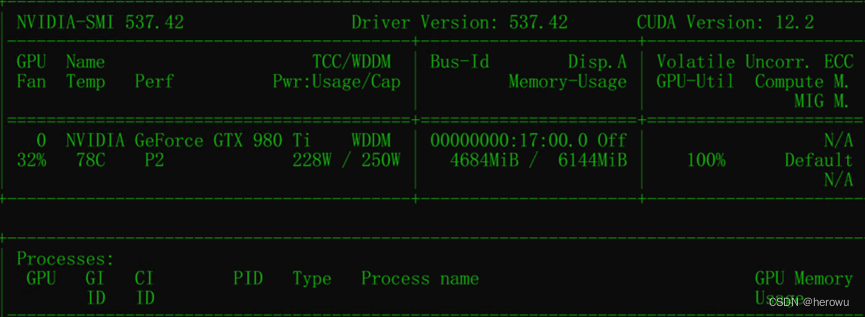
在60亿参数的chatglm2大模型测试中,6G显存差一点没有跑起来,由于显存限制980Ti其实不适合做AIGC。 在大模型测试中,推理速度很慢,问题1成绩为时 291.83秒,速度只有为:0.39tokens/s, 114 tokens, context 401 seed 42465164;问题2成绩为308.89 秒 速度为:0.37 tokens/s, 113 tokens, context 556 seed 529669374,两道题都是要等3分钟左右才出来,像看幻灯片一样的一个字一个字的蹦,着急的人完全看不下去声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
在大模型测试中,推理速度很慢,问题1成绩为时 291.83秒,速度只有为:0.39tokens/s, 114 tokens, context 401 seed 42465164;问题2成绩为308.89 秒 速度为:0.37 tokens/s, 113 tokens, context 556 seed 529669374,两道题都是要等3分钟左右才出来,像看幻灯片一样的一个字一个字的蹦,着急的人完全看不下去声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

