- 1如何把AI聊天模型接入QQ_给qq接入ai
- 2文件上传下载容易引发的安全问题及如何预防_上传文件安全性考虑
- 3本地连接虚拟机中Redis出现的问题(远程连接redis)_本地连不上虚拟机的redis
- 4【案例分析】基于IMDb数据集的印度电影信息剖析_imdb电影信息
- 5已成功与服务器建立连接,但是在登录过程中发生错误。(provider: SSL提供程序,error:0-证书链是由不受信任的颁发机构颁发的。)_已成功与服务器建立连接,但是在登录过程中发生错误。 (provider: ssl 提供程序, e
- 6Android:双非大二3轮技术面+HR面(1),三面蚂蚁核心金融部_mateapp hr面
- 7第三章-AllData数据中台-开源团队_alldatadc
- 8如何下载视频号的视频文件?_视频号下载文件报错
- 9由maven sources.jar逆向成可运行的java工程_reverse-m2-sources
- 10面试?跳槽?涨薪?这些你必须先了解:互联网大厂的薪资和职级一览!_腾讯产品职级
力扣 动态规划题集 Python_力扣列表实现python
赞
踩
 有些题披着动态规划的外壳,但是有时候不如贪心、DFS 高效。多练多练,刷刷题感
有些题披着动态规划的外壳,但是有时候不如贪心、DFS 高效。多练多练,刷刷题感
括号生成
【问题描述】
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
【样例】
| 输入 | 输出 |
| n = 3 | ["((()))","(()())","(())()","()(())","()()()"] |
| n = 1 | ["()"] |
【解析及代码】
初始化一个一维列表来记录 括号对数 <= n 的所有状态,如 dp[3] 包含括号对数为 3 的所有序列。只要保证从第一个状态是正确的序列,设计好状态转移,就可以保证后续得到的所有括号序列都是正确的
初始条件:dp[0] = [""]
状态转移:"(" + neck + ")" + tail,其中 neck 是括号对数为 m 的序列 (取自 dp[m] ),tail 是括号对数 n 的序列 (取自 dp[n] )
- class Solution(object):
- def generateParenthesis(self, n):
- dp = [['']] + [[] for _ in range(n)]
- # 当前想得到的括号对数
- for i in range(1, n + 1):
- # tail 部分的括号对数
- for j in range(i):
- for neck in dp[i - 1 - j]:
- for tail in dp[j]:
- dp[i].append('(' + neck + ')' + tail)
- return dp[-1]
还有另一种思路是利用了括号序列的的一个性质,string[: n] 恒满足:"("的个数 >= ")"的个数。然后用递归函数来逐个添加字符。我个人不喜欢递归,做 Fibonacci 数列得到的教训。能用栈就用栈吧,如果栈太复杂再考虑递归

解码方法
【问题描述】
一条包含字母 A-Z 的消息通过以下映射进行了 编码 :
'A' -> "1"
'B' -> "2"
...
'Z' -> "26"
要 解码 已编码的消息,所有数字必须基于上述映射的方法,反向映射回字母(可能有多种方法)。例如,"11106" 可以映射为:
- "AAJF" ,将消息分组为 (1 1 10 6)
- "KJF" ,将消息分组为 (11 10 6)
注意,消息不能分组为 (1 11 06) ,因为 "06" 不能映射为 "F" ,这是由于 "6" 和 "06" 在映射中并不等价。
给你一个只含数字的 非空 字符串 s ,请计算并返回 解码 方法的 总数 。
题目数据保证答案肯定是一个 32 位 的整数。
【样例】
| 输入 | 输出 |
| s = "12" | 2 |
| s = "226" | 3 |
| s = "06" | 0 |
【解析及代码】
按照动态规划的思想,首先考虑前 n 位字符的解码方法数,在此基础上在往后推
用一维列表 dp 来记录状态,dp[0] 表示前 1 个字符的解码方法数,dp[3] 表示前 4 个字符的解码方法数,以此类推。分几种情况讨论:
- 如果字符串是空串,答案是 0
- 如果字符串第一位是 0,答案是 0
- 字符串长度是 1,答案是 1
当字符串长度 > 1 且第一位不为 0,以 '11106' 为例:
- 因为第一位不为 0,dp[0] = 1
- 因为第一位和第二位的组合是 11,而且分开也是一种方法,所以 dp[1] = 2
- 第三位开始可以利用前面的结果进行递推。设当前考虑的字符索引是 i,
表示一个字符/两个字符组合 是不是符合解码标准,得:
。也就是当前考虑的字符,首先考虑单独成组的情况,有
;其次,当前考虑的字符和它的前一个字符组合的情况,有
- class Solution(object):
- def numDecodings(self, s):
- # 定义首位为 0 时不合法, 并判断子串是否在 [1, 26] 内
- is_valid = lambda x: int(x[0] != '0' and 1 <= int(x) <= 26)
- # 当为空串 / 第一位为 0
- if not s or not is_valid(s[0]): return 0
- if len(s) <= 1: return 1
- dp = [0] * len(s)
- dp[0] = 1
- # 两个字符分开 + 两个字符组合
- dp[1] = is_valid(s[1]) + is_valid(s[:2])
- for i in range(2, len(s)):
- dp[i] = is_valid(s[i]) * dp[i - 1] + is_valid(s[i - 1: i + 1]) * dp[i - 2]
- return dp[-1]

不同的二叉搜索树
【问题描述】
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树有多少种?返回满足题意的二叉搜索树的种数。
【样例】
| 输入 | 输出 | 说明 |
| n = 3 | 5 | 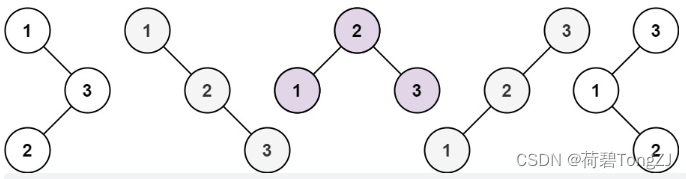 |
| n = 1 | 1 |
【解析及代码】
二叉搜索树的性质是:对于某节点,其左子树中的所有节点都小于它,其右子树中的所有节点都大于它
于是,固定了根节点的值,其左子树中含有多少个节点,右子树中含有多少个节点就知道了
用一维列表 dp 来记录,dp[0] 对应空树的种数,dp[2] 对应二节点树的种数,以此类推
- class Solution(object):
- def numTrees(self, n):
- if n <= 1: return 1
- # 初始化: 空树、无叶树的种树
- dp = [0 for _ in range(n + 1)]
- dp[0] = dp[1] = 1
- # 枚举节点数
- for i in range(2, n + 1):
- # 枚举左子树节点数
- dp[i] = sum(dp[l] * dp[i - 1 - l] for l in range(i))
- return dp[-1]

二叉树中的最大路径和
【问题描述】
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
【样例】
| 输入 | 输出 | 说明 |
| root = [1,2,3] | 6 | 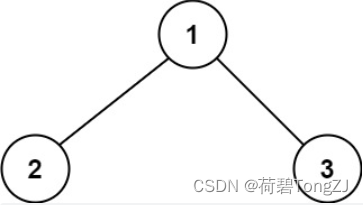 |
| root = [-10,9,20,null,null,15,7] | 42 | 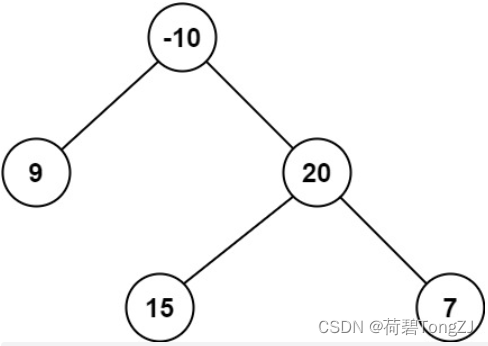 |
【解析及代码】
二叉树里面的路径只允许有一个拐点,分别以每个结点作为拐点,求得该拐点下的最大路径和,取所有拐点的最大路径和的最值即为答案
DFS 函数加上对负路径的舍弃即可搞定
- class Solution:
- def maxPathSum(self, root):
- # 记录所有结点作为拐点时的最大路径和
- res = - float('inf')
-
- def dfs(node):
- if not node: return 0
- # 返回左支路、右支路的最大路径和 (其值 >= 0)
- l, r = map(dfs, (node.left, node.right))
- # 以当前结点为路径拐点的路径长度
- nonlocal res
- res = max(res, node.val + l + r)
- # 返回最长的支路 + 该结点的值, 舍弃负路径和支路
- return max(0, max(l, r) + node.val)
-
- dfs(root)
- return res

完全平方数
【问题描述】
给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
【样例】
| 输入 | 输出 | 说明 |
| n = 12 | 3 | 12 = 4 + 4 + 4 |
| n = 13 | 2 | 13 = 4 + 9 |
【解析及代码】
先枚举所有 n 以内的完全平方数,然后存进列表 pace 里。用背包的思想做,初始化一个长度为 n + 1 的列表 bag,如 bag[13] 代表叠加到 13 需要的最少平方数
- class Solution:
- def numSquares(self, n):
- import math
-
- # 初始化背包和平方数列表
- bag = list(range(n + 1))
- pace = [i ** 2 for i in range(2, math.isqrt(n) + 1)]
- # 枚举背包的容量
- for i in range(n):
- # 枚举平方数
- for w in pace:
- next_ = i + w
- if next_ > n: break
- # 叠加一个数,比较取最优
- bag[next_] = min(bag[next_], bag[i] + 1)
- return bag[-1]

零钱兑换
【问题描述】
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
【样例】
| 输入 | 输出 |
| coins = [1, 2, 5], amount = 11 | 3 |
| coins = [2], amount = 3 | -1 |
| coins = [1], amount = 0 | 0 |
【解析及代码】
这道题要用背包。第一遍做这道题的时候,用了二维矩阵来记录状态 —— 测试结果感人
在我把空间复杂度从 O(mn) 降到 O(n) 的时候,在代码简化的同时,执行用时也降了一半左右,所以说降低空间复杂度也是很重要的
从基本的框架看起,后续再考虑边界条件
用一维列表 bag 来记录状态,bag[amount] 表示要叠到总金额需要硬币的最小个数。因为取最优的运算方式是 min,所以 bag 的初始值为 inf = amount + 1
假设:coins = [2, 1, 5, 3],amount = 6,则 bag = [0, inf, inf, inf, inf, inf, inf]
考虑第一种硬币的时候比较特殊,现取到面值为 2 的,则更新 bag = [0, inf, 1, inf, 2, inf, 3]
考虑剩余的硬币的时候则是在考虑 bag 的情况下进行更新,现取到面值为1的,如果按照上面的方式进行更新,则 bag = [1, 2, 3, 4, 5, 6],显然打破了最优的状态
如果这样更新:
- bag[1] = 1,一个 1 的硬币为最优
- bag[1 + 1] = min( bag[1 + 1], bag[1] + 1 ) = min(1, 1 + 1) = 1,一个 2 的硬币为最优
- bag[2 + 1] = min( bag[2 + 1], bag[2] + 1 ) = min( inf, 1 + 1 ) = 2,一个 1 的硬币 + 一个 2 的硬币为最优
照这样传递下去,在保持步步最优的同时,bag[-1] 就会是最优的答案
接下来考虑三种情况:
- coins 是空列表:没有硬币的情况下是达不到目标值的,所以要返回 -1。但是照着代码走一遍 —— 无法进入 for 循环,bag[-1] = inf,返回值是 inf,所以在 return 之前还要判断 bag[-1] 是不是不等于 inf
- amount 为 0:对应 bag 是空列表,会在 return 的时候报错
- coins 中有面值大于 amount 的:bag[c] = 1 超出列表长度,会报错
- class Solution(object):
- def coinChange(self, coins, amount):
- if not amount: return 0
- # bag 不为空的条件: amount 不为 0
- inf = amount + 1
- bag = [inf] * (amount + 1)
- coins = filter(amount.__ge__, coins)
- try:
- # 初始化只考虑第一种硬币的状态
- c = next(coins)
- for i, tar in enumerate(range(0, amount + 1, c)):
- bag[tar] = i
- except StopIteration:
- pass
- # 获取剩余的硬币
- for c in coins:
- # 枚举的 src 满足: src + c <= amount
- for src in range(amount - c + 1):
- bag[src + c] = min(bag[src + c], bag[src] + 1)
- return bag[-1] if bag[-1] < inf else -1

多边形三角剖分的最低得分
【问题描述】
你有一个凸的 n 边形,其每个顶点都有一个整数值。给定一个整数数组 values ,其中 values[i] 是第 i 个顶点的值(即 顺时针顺序 )。
假设将多边形 剖分 为 n - 2 个三角形。对于每个三角形,该三角形的值是顶点标记的乘积,三角剖分的分数是进行三角剖分后所有 n - 2 个三角形的值之和。
返回 多边形进行三角剖分后可以得到的最低分 。
【样例】
| 输入 | 输出 | 说明 |
| values = [1,2,3] | 6 | |
| values = [3,7,4,5] | 144 | 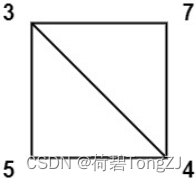 |
| values = [1,3,1,4,1,5] | 13 | 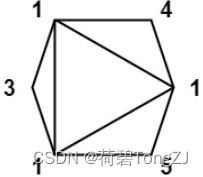 |
【解析及代码】
一个多边形,可以剖分成多个多边形,再进一步剖分成多个三角形,所以这道题应使用 DFS
而怎样表示这些中间状态 (剖分过程中的多边形) 是我们需要研究的一个问题
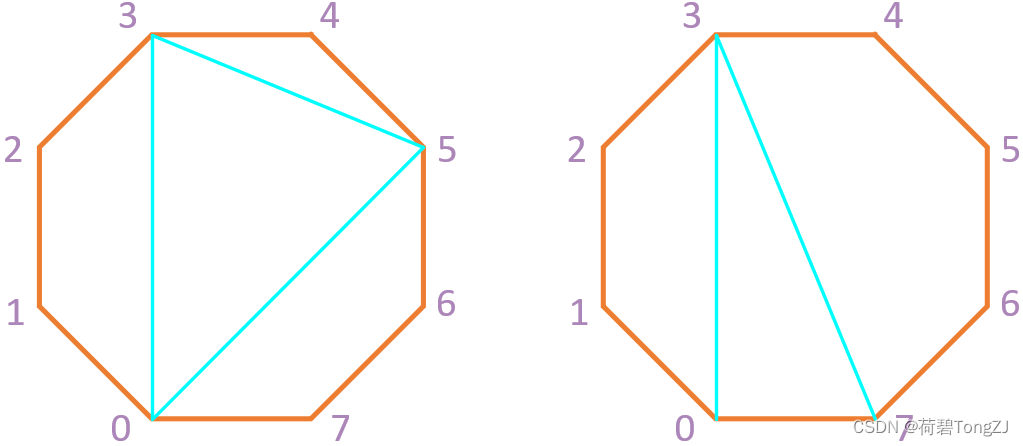
例如给定 8 个顶点,随机选择三个顶点 (上图左) 组成 三角形 (0, 3, 5),那么剩下的多边形可被表示为 四边形 (0~3)、三角形 (3~5)、四边形 (5~7, 0)
可以发现的是,最后一个四边形的顶点序号出现了不连续,给我们造成了传参的困难
而在 四边形 (5~7, 0) 中,必定有一个 三角形 以 (0, 7) 为边
如上图右所示,选择 (0, 7) 为边,剩下的多边形可被表示为 四边形 (0~3)、五边形 (3~7)
对于 五边形 (3~7) 继续选择 (3, 7) 为边 (即起点、终点),再任意选择一个顶点与之组成 三角形,剩下的多边形可以保持顶点序号的连续
解决了问题的分解、中间状态的表示之后,利用 lru_cache 编写记忆化递归即可
- class Solution(object):
- def minScoreTriangulation(self, values):
- from functools import lru_cache
-
- @lru_cache(maxsize=None)
- def dfs(s, e):
- # 如果顶点数小于 3
- if e - s < 2: return 0
- # 构成边 (s, e)
- edge = values[s] * values[e]
- if e - s == 2: return edge * values[s + 1]
- # 如果顶点数大于 3, 选择一个顶点 i 与 (s, e) 构成三角形
- return min(edge * values[i] + dfs(s, i) + dfs(i, e)
- for i in range(s + 1, e))
-
- return dfs(0, len(values) - 1)