
- 1fork一个开源项目参与其中_fork此项目
- 2STM32学习笔记3——怎样将整型变量转换为字符变量 然后串口 或者LCD发送出来(STM32) 以及sprintf的用法_stm32 整形 转化字符串并发送
- 3自动驾驶模拟如此“吃”算力,你的工作站扛得住吗?
- 4JPS incremental annotation processing is disabled与Failed to read candidate component class_由于在类路径中发现了一个或多个处理程序,因此启用了 批注处理。未来发行版的 jav
- 5mapbox添加Geoserver发布矢量瓦片_4. geoserver配合mapbox的拓展
- 6Windows + PyPy+Sublime/PyCharm 运行python:提高python运行速度_在电脑上安装什么能让pycharm运行快一点
- 7论文读书笔记-主题-word representations learning & Evaluation_word representation learning
- 8数据结构——二叉树的原理与代码应用_数据结构二叉树与代码应用
- 9Neo4j版本升级(社区版)_如何升级neo4j版本
- 10网络攻防技术——shellcode编写
【机器翻译】transformer_position-wise dot product
赞
踩
【机器翻译】transformer
2018-05-01 | ML , app , nlp , translation , 2. 主流model-研究现状 , 2. NMT , transformer | 3129
本文字数: | 阅读时长 ≈
简介
在2017年5月Facebook发布了ConvSeq2Seq模型吊打了GNMT一个月之后,Google发出了最强有力的反击,发表了一篇论文Attention is all you need,文中提出了一种新的架构叫做Transformer,用以来实现机器翻译。它抛弃了传统的CNN、RNN,只采用attention,取得了很好的效果,激起了工业界和学术界的广泛讨论。
背景,motivation
如何获取context信息
常用的模型架构有RNN、CNN、CRF,详见 序列学习。
transformer横空出世
Transformer避开了recurrence,只用attention,便可以刻画出输入和输出的依赖关系。
对比RNN的决策步骤太长问题,transformer可单步决策。通过一层self-attention,bank能够直接attend到river上。
ConvS2S是线性时间复杂度,ByteNet是log时间复杂度。而Transformer则是常数时间复杂度
创新点
- dot product attention
- multi-head
- 彩蛋: restricted self-attention,
 |  | 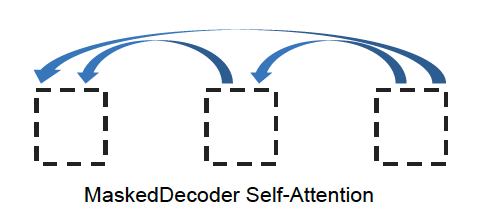 |
dot product attention
前面给出的是一般化的框架形式的描述,事实上Google给出的方案是很具体的。首先它定义了Attention一种泛化形式:
Attention(Q,K,V)=softmax(QK⊤dk−−√)VAttention(Q,K,V)=softmax(QK⊤dk)V
其中Q∈Rn×dk,K∈Rm×dk,V∈Rm×dvQ∈Rn×dk,K∈Rm×dk,V∈Rm×dv。如果忽略激活函数softmax的话,那么事实上它就是三个n×dk,dk×m,m×dvn×dk,dk×m,m×dv的矩阵相乘,最后的结果就是一个n×dvn×dv的矩阵。
这里将attention抽象成 q: query, k: key, v: value。
为什么要采用scale?
因为量级太大,softmax后就非0即1了,不够“soft”了。也会导致softmax的梯度非常小。也就是让softmax结果不稀疏(问号脸,通常人们希望得到更稀疏的attention吧)。
- attention 可以不只是用于 decoder 里每步输入一个符号,而是可以用在网络中的任意一层,把一个序列转换成另一个序列。这个作用与 convolutional layer、recurrent layer 等是类似的,但有一个好处就是不再局限于局域性。attention是直接去capture dependency structure,摆脱了局限性魔咒
- attention 可以一般地描述为在一个 key-value mapping 中进行检索,只不过 query 跟 key 可以进行模糊匹配,检索结果是各个 key 对应的 value 的加权平均。
Query, key, value 其实并不是专门针对翻译的概念。不过可以举一些翻译中的例子。例如,当刚刚翻译完主语之后,attention 的内部状态就会想要去找谓语,这时它就把「想找谓语」这件事编码成 query。然后句子里本身是谓语的地方,会有一个 key,表明「我这里可以提供谓语」,它跟 query 一拍即合。这个 key 对应的 value 就是谓语本身的 embedding。
点乘注意力在何凯明的Non-local Neural Networks中被解释成Embedded Gaussian的一种特例。非要跟高斯扯上关系,好牵强。
VS additive attention
additive attention等价于一个前馈网络:
softmax([Q,K]W)=softmax(QWQ+KWK)softmax([Q,K]W)=softmax(QWQ+KWK)
这个的计算速度没有dot-product attention在GPU上快。
详见 Neural machine translation by jointly learning to align and translate
VS 其他attention
Multi-Head Attention
以Q为例,单个head的计算
将输入向量切成8份,这每一
份可以看成一个local partial,然后再分别attnetion最终再concat成一个context向量。如果将本文multi-head attention的V输入切成八份后的
向量类比关注不同local paritial的卷积核的话,我们可以看到CNN和这里multi-head attention异曲同工
优势:
- It expands the model’s ability to focus on different positions。 这个最强势。通过attention到不同的维度。细粒度的attention,超赞。
- 既是细粒度的attention,又不增加计算量
- 能在encode的时候并行化,(这里的并行是相对RNN吗?one-head是大矩阵也可以并行。convS2S同样可以)
- 降维到d/head,即bottleneck的思想,减少计算量
举例
忽略batch_size
复制
1 2 3 4 5 6 7 8 9 10 11 12 | num_units = 512 # 也叫 num_channel, emb_size max_length = 10 K,Q,V = [10, 512] W = [512,512] A = attention(KW, KQ, KW) 加上head后 num_head = 8 K_i,Q_i,V_i = [10,64] # W_i = [64,512] # 值得注意的是,这里不是 [64,64],即并未减少计算量和参数量 A_i = attention(K_i W_i, W_i,) |
- Multiple attention layers (heads) in parallel
- Each head uses different linear transformations.
- Different heads can learn different relationships.
思考
- self attention遗漏了什么?位置信息
- self attention中的k, q, v分别指代什么?
- self attention是否可逆向?
FFN层
FFN(Position-wise Feed-Forward Network)。
- Position-wise: 顾名思义,就是对每个position采用相同的操作。
- Feed-Forward Network: 就是最普通的全连接神经网络,这里采用的两层,relu作为激活函数
![]()
FFN层对接multi-head attention层,那么该层的输入 x∈Rbatchsize×length×dmodelx∈Rbatchsize×length×dmodel。
https://github.com/tensorflow/tensor2tensor/blob/v1.9.0/tensor2tensor/models/transformer.py#L1373
FFN(x)=max(0,xW1+b1)W2+b2FFN(x)=max(0,xW1+b1)W2+b2
其中输入和输出的维度都是$d{model}=512,中间维度是,中间维度是d{ff}=2048$。对于单个position
x∈R512,W1∈R512×2048,W2∈R2048×512x∈R512,W1∈R512×2048,W2∈R2048×512
与卷积的等价性
这里的全连接层,一种替代方案就是采用kernel size为1的卷积,即
tensor2tensor中有两种实现dense_relu_dense 和 conv_relu_conv,默认采用的前者。
其中卷积的维度是
复制
1 2 3 | input.shape = [batch_size, length, 512] kernel_1 = [2048,1] kernel_2 = [512, 1] |
tensor2tensor实现中,conv1d中的kernel_size如果为1,默认返回dense。源码
复制
1 2 3 4 | def tpu_conv1d(inputs, filters, kernel_size, padding="SAME", name="tpu_conv1d"):
if kernel_size == 1:
return dense(inputs, filters, name=name, use_bias=True)
...
|
逗比,conv到底比dense会不会加速?
为什么我觉得kernel_size=512才等价于全连接?
实际上,kernel_size没必要一定是1的。
层数与维度设计
很自然,我们有两个疑问。
- 为什么要两层?MLP?
- 为什么要先升维再降维? high-rank
通常的bottleNeck架构,先降维再升维(减小计算量)。
两大作用:
- multi-head attention之后的merge
- 类似group conv之后的merge,DWConv后的1*1卷积与channel shuffle
小结
- 为什么叫强调
position-wise?- 解释一: 这里FFN层是每个position进行相同且独立的操作,所以叫position-wise。对每个position独立做FFN。
- 解释二:从卷积的角度解释,这里的FFN等价于kernel_size=1的卷积,这样每个position都是独立运算的。如果kernel_size=2,或者其他,position之间就具有依赖性了,貌似就不能叫做position-wise了
- 为什么要采用全连接层?
- 目的: 增加非线性变换
- 如果不采用FFN呢?有什么替代的设计?
- 为什么采用2层全连接,而且中间升维?
- 这也是所谓的bottle neck,只不过低维在IO上,中间采用high rank
Positional Encoding
回顾一下Transformer的整个架构,不难发现Transformer模型本身并不能捕捉序列的顺序。换句话说,如果将K,V按行打乱顺序(相当于句子中的词序打乱),那么Attention的结果还是一样的。这就表明了,到目前为止,Attention模型顶多是一个非常精妙的“词袋模型”而已。
Sinusoid Positional Encoding
1、以前在RNN、CNN模型中其实都出现过Position Embedding,但在那些模型中,Position Embedding是锦上添花的辅助手段,也就是“有它会更好、没它也就差一点点”的情况,因为RNN、CNN本身就能捕捉到位置信息。但是在这个纯Attention模型中,Position Embedding是位置信息的唯一来源,因此它是模型的核心成分之一,并非仅仅是简单的辅助手段。
2、在以往的Position Embedding中,基本都是根据任务训练出来的向量。而Google直接给出了一个构造Position Embedding的公式:
⎧⎩⎨⎪⎪PE2i(p)=sin(p/100002i/dpos)PE2i+1(p)=cos(p/100002i/dpos){PE2i(p)=sin(p/100002i/dpos)PE2i+1(p)=cos(p/100002i/dpos)
这里的意思是将id为pp的位置映射为一个$dpos维的位置向量,这个向量的第维的位置向量,这个向量的第i个元素的数值就是个元素的数值就是PE{i}(p)$。Google在论文中说到他们比较过直接训练出来的位置向量和上述公式计算出来的位置向量,效果是接近的。因此显然我们更乐意使用公式构造的Position Embedding了。
3、Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是:由于我们有 sin(α+β)=sinαcosβ+cosαsinβsin(α+β)=sinαcosβ+cosαsinβ以及cos(α+β)=cosαcosβ−sinαsinβcos(α+β)=cosαcosβ−sinαsinβ,这表明位置p+kp+k的向量可以表示成位置pp的向量的线性变换,这提供了表达相对位置信息的可能性。
小结
- Transformer并没有在结构上突破传统的LSTM和CNN,只是采用了position encoding的方式取巧。
如何在结构上突破CNN和LSTM的缺陷,达到获取position(时序)信息、任意长度依赖、易并行的效果? - 其他方案
- 拼接: 起来作为一个新向量,也可以把位置向量定义为跟词向量一样大小,然后两者加起来。FaceBook的论文和Google论文中用的都是后者。直觉上相加会导致信息损失,似乎不可取
- multi-channel:
其他
layer norm
Result
可视化
经过测试,列了以下可视化结果。
![]()
![]()
![]()
TODO,+动态可视化
维度设计
在NLP的很多网络里,一般
- hidden_dim和embedding_dim 相等
-
每层的维度都是相同的维度,(只在FFN层进行了局部升维)。
这与传统的
参数量 & 计算量
code
- TensorFlow
- https://github.com/Kyubyong/transformer 简易版,bucket、lr、decay等都没有实现
- https://github.com/tensorflow/models/tree/master/official/transformer TF官方code,基本不更新
- https://github.com/tensorflow/tensor2tensor#translation 官方code,产品级,更新频繁
- 代码解析: https://blog.csdn.net/mijiaoxiaosan/article/details/74909076
- Pytorch
缺陷
ss
Attention层的好处是能够一步到位捕捉到全局的联系,因为它直接把序列两两比较(代价是计算量变为O(n2)O(n2)),当然由于是纯矩阵运算,这个计算量相当也不是很严重);相比之下,RNN需要一步步递推才能捕捉到,而CNN则需要通过层叠来扩大感受野,这是Attention层的明显优势。
扩展阅读
- Transformer | Google-blog
- 《Attention is All You Need》浅读(简介+代码)| kexue.fm 很多还没看懂,后面继续看
- 从convS2S到transformer | 知乎
相关文章


{kind=link}
{kind=link}
{kind=link}
{kind=link}