
- 1GitHub上只下载部分文件的操作教程_github如何下载部分代码
- 2目标检测实战(五): 使用YOLOv5-7.0版本对图像进行目标检测完整版(从自定义数据集到测试验证的完整流程))_yolov5.7介绍
- 3Android动态权限详解
- 4【DevOps】Kibana:数据可视化与探索的强大工具
- 5MySQL索引下推(Index Condition Pushdown, ICP)优化深入解析_mysql 索引下推
- 6spss安装后 python_python从入门到入土教程(7)——用python实现SPSS的各种功能
- 7软件测试学习职业生涯必读的书籍【附电子版】_探索式软件测试电子书
- 8python爬虫及数据可视化分析_python爬虫与可视化项目简介怎么写
- 9【AI学习指南】七、PaddlePaddle自然语言处理-PaddleNLP的基础使用/中文分词/词性标注/实体识别/依存句法分析_paddlenlp 分词
- 10strongswan交叉编译与安装
RT-DETR论文笔记
赞
踩
Motivation
YOLO 一直是实时检测领域应用最广的检测框架,但是 YOLO 得到的结果需要经过 NMS 处理才能得到最终的输出结果,如 《目标检测大杂烩》-第14章-浅析RT-DETR - 知乎分析,NMS 在后处理流程中会带来很多问题。反之,DETR 系列工作不需要 NMS 作为后处理,但 DETR 速度不够快,因此在实时检测领域无法应用。这篇文章在 DETR 的基础上,提出了一种能实现实时检测的 Transformer 检测框架,解决了前面提到的问题。
模型
Overview
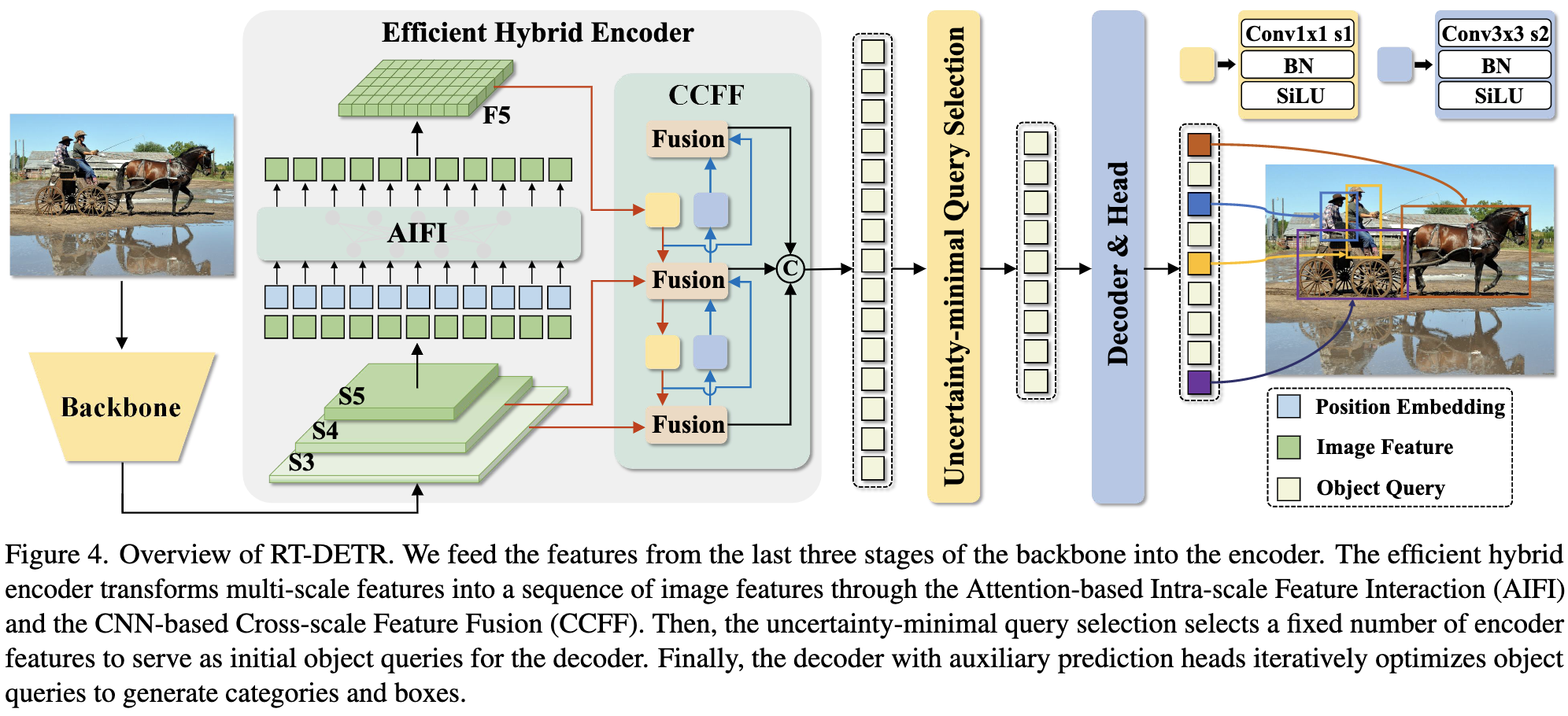
模型整体由 backbone、encoder、decoder 和 head 构成。本文的主要改进点在于 encoder 和 decoder 部分。
Efficient Hybrid Encoder
Computational bottleneck analysis
论文里面首先通过实验证明了 Deformable DETR 中的 encoder 方式存在冗余部分。
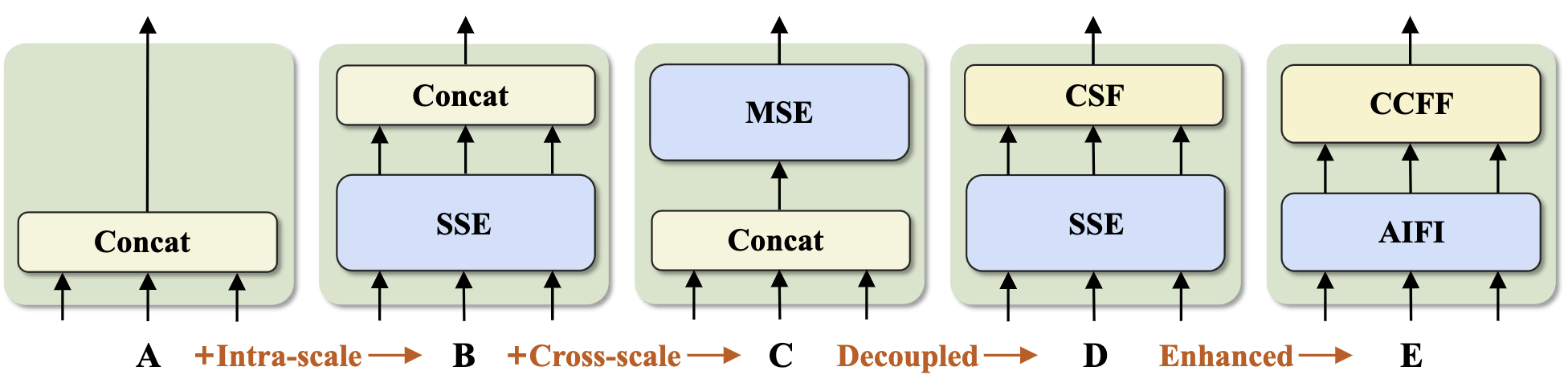
论文设计了不同的模块:
A:没有 encoder 模块;
B:在 S3、S4、S5 三个不同分辨率的 feature map 上,分别执行 single scale encoder,然后把 encoder 后的结果拼起来;
C:类似于 Deformable DETR 中的 encoder 方法,先拼起来,然后进行 multi scale encoder;
D:在 S3、S4、S5 三个不同分辨率的 feature map 上,分别执行 single scale encoder,然后用类似于 PANet 的结构将特征融合;
E:仅在 S5 上执行 single scale encoder(AIFI),以减少计算量,然后用 CCFF 融合不同分辨率的 feature map。
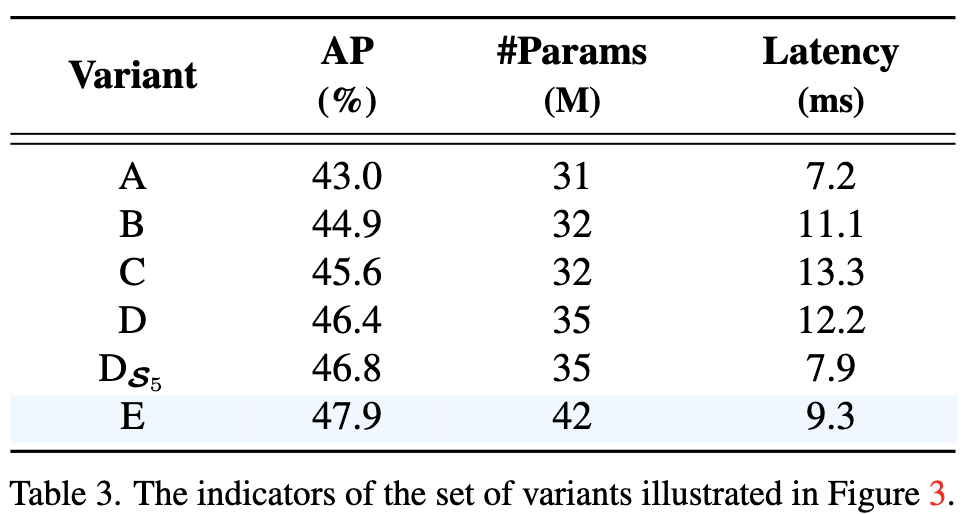
实验中可以看到,由 A 到 B 再到 C,模型性能逐渐提升的同时,计算延迟也大幅提升;由 C 到 D,性能提升的同时,小幅度减少了延迟,这说明不同 scale 的 feature 间的交互是必要的,但是不需要采用 multi scale encoder 的方式交互。由 D 到 D S 5 D_{S_5} DS5 在延迟大幅度降低的情况下,准确率有了微小的提升,说明仅在 S5 上进行 encoder 就可以,不需要在更大尺度的 future map 上进行 encoder 操作。
CCFF
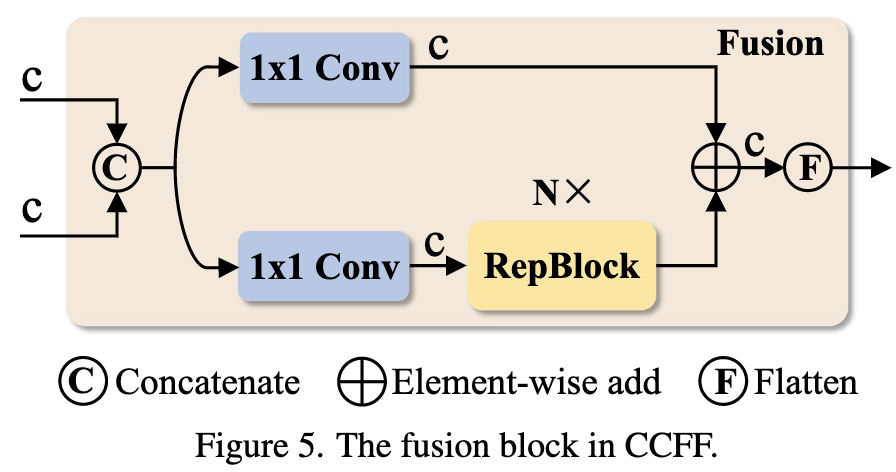
融合模块采用了上图的设计。有一点疑问,RepVGG 的设计思路是希望网络在 inference 阶段是一个单 branch 的结构,CCFF 的设计是否一定程度上违背了 RepVGG 的思路?
Uncertainty-minimal Query Selection
这部分描述的是选择 query 的方式,这里在论文里的描述有点绕,但是结合代码和别人的博客,我认为这里的实现实际上采用的是在 loss 中加入一个 vfl loss 的方式。Vfl loss 希望模型预测的类别概率与 iou 有关,iou 越高,类别概率也越高;反之亦然。
之前 detr-like 的方法里面,decoder 模型的 query 选择通常是按照类别概率高低来选择的,但是 query 实际上包含两个方面:类别和位置,仅考虑类别选出的 query 很可能并不是最优的。因此,rt-detr 在 loss 里面加入了 vfl loss,希望经过这样的训练,类别概率高的 query,iou 也能比较高。
论文里进行了实验:
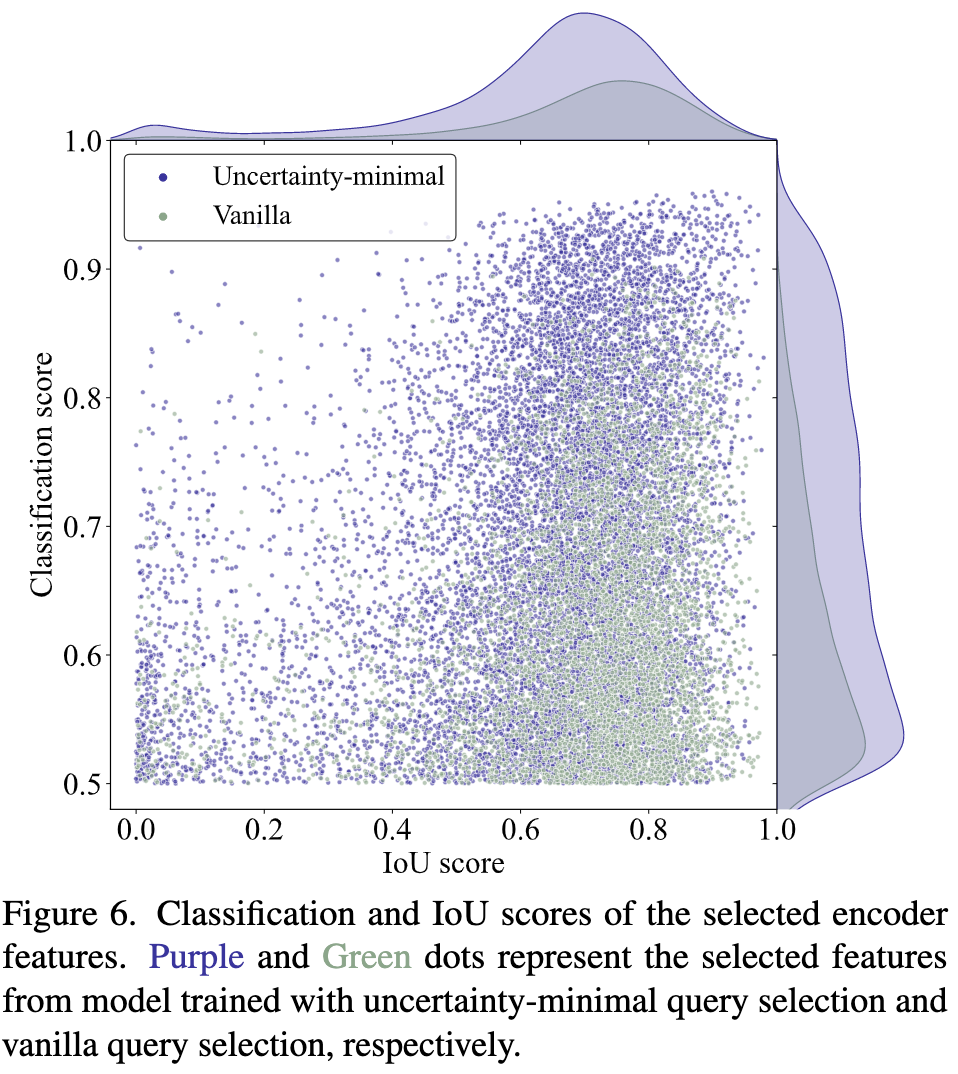
紫色是 rt-detr 用的方法,绿色是直接选择类别概率更高的 query。可以看出相比于原本的方法 rt-detr 可以使 query 在类别概率高的同时,iou 更高,即 rt-detr 可以选出质量更高的 query。
与 SOTA 方法比较
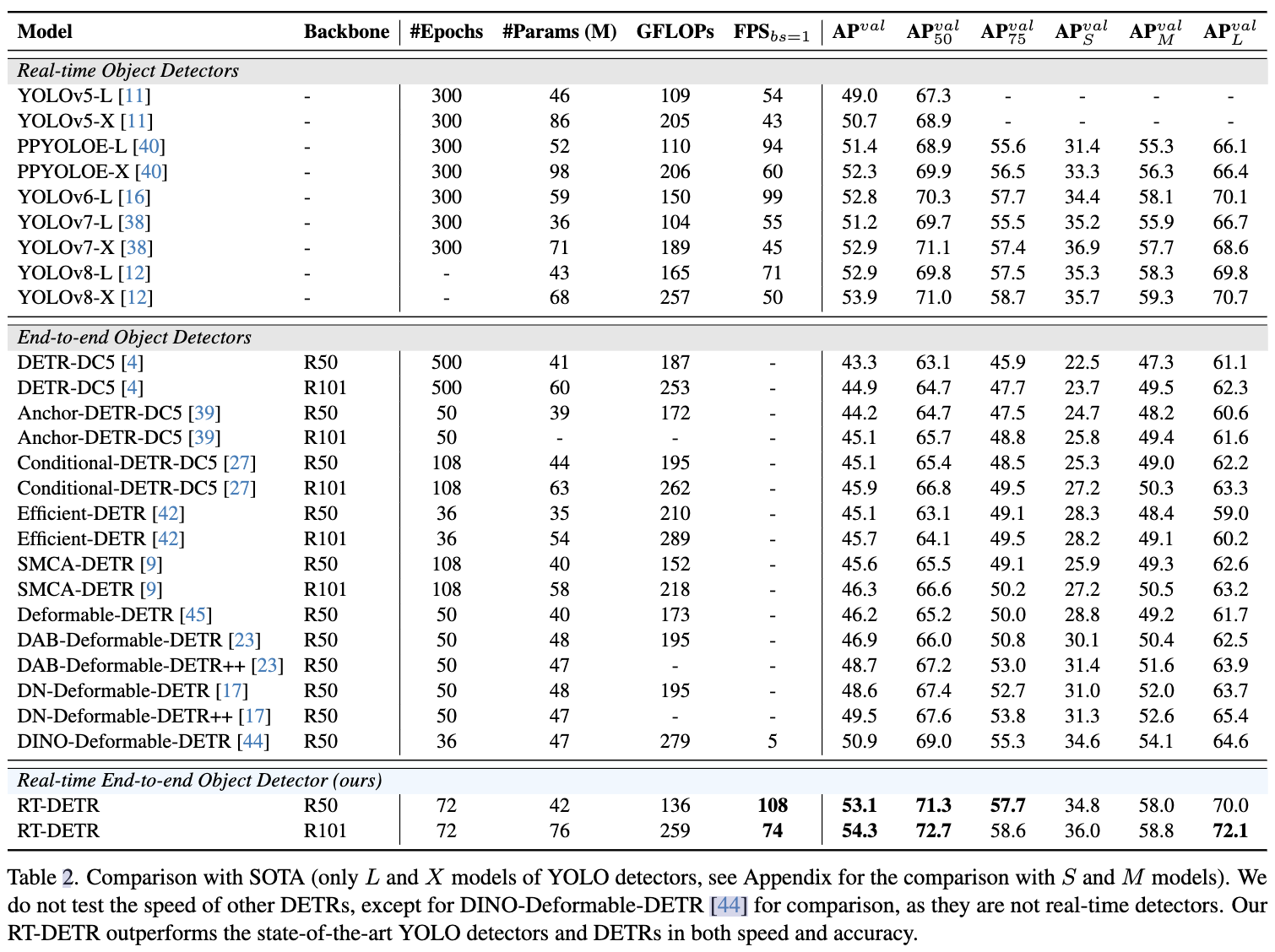
与 detr-like 的方法比较,rt-detr 性能和速度上都有提升;与最好的 YOLO 方法比较,性能略微提升的情况下速度也有提升。

