
- 1Java常用类库之ArrayList_引用什么库含有arraylist
- 2p++与++p解读_p++和++p
- 3vue2.0搭配elementui实现dark暗黑主题_elementui黑色主题
- 4HTML中显示特殊字符“<”,“>“_span显示 html 类型
- 5『恶意代码分析实战』Windows API编程——通过修改注册表的方式实现自启动_编写代码,编辑注册表的run/runonce/runonceex键(任选其一,并明确三个键的区别
- 6【深度学习之YOLO8】视频流推断_yolov8视频流
- 7机器学习:BP神经网络,CNN卷积神经网络,GAN生成对抗网络_bp神经网络、随机森林以及cnn卷积神经网络三大机器学习算法预警模型
- 8UE4 实时渲染原理&优化策略笔记_ue4 pbr源码分析
- 9树莓派4B编译安装snowboy_libsnowboy-detect.a: error adding symbols: file in
- 104.Eigen Tensor详解【三】_eigen tensor sum
python数据结构推荐书-腾讯十年Python开发老司机推荐的入门书籍,你确定不看吗?...
赞
踩
原标题:腾讯十年Python开发老司机推荐的入门书籍,你确定不看吗?

稍微关心编程语言的使用趋势的人都知道,最近几年,国内最火的两种语言非 Python 与 Go 莫属,于是,隔三差五就会有人问:这两种语言谁更厉害/好找工作/高工资……
对于编程语言的争论,就是猿界的生理周期,每个月都要闹上一回。到了年末,各类榜单也是特别抓人眼球,闹得更凶。
其实,它们各有对方所无法比拟的优势以及用武之地,很多争论都是没有必要的。身为一个正在努力学习 Python 的(准)中年程序员,我觉得吧,先把一门语言精进了再说。没有差劲的语言,只有差劲的程序员,等真的把语言学好了,必定是“山重水复疑无路,柳暗花明又一村”。
Python高性能编程

Python高性能编程电子书籍下载: 链接:
https://pan.baidu.com/s/1xwF5dEYIbDmQOnZpy5amQA
提取码:2d0d
(百度云盘提供)
本书适合已入门 Python、还想要进阶和提高的读者阅读。
所有计算机语言说到底都是在硬件层面的数据操作,所以高性能编程的一个终极目标可以说是“高性能硬件编程”。然而,Python 是一门高度抽象的计算机语言,它的一大优势是开发团队的高效,不可否认地存在这样或那样的设计缺陷,以及由于开发者的水平而造成的人为的性能缺陷。
本书的一大目的就是通过介绍各种模块和原理,来促成在快速开发 Python 的同时避免很多性能局限,既减低开发及维护成本,又收获系统的高效。
1、性能分析是基础
首先的一个关键就是性能分析,借此可以找到性能的瓶颈,使得性能调优做到事半功倍。
性能调优能够让你的代码能够跑得“足够快”以及“足够瘦”。性能分析能够让你用最小的代价做出最实用的决定。
书中介绍了几种性能分析的工具:
(1)基本技术如 IPython 的 %timeit 魔法函数、time.time()、以及一个计时修饰器,使用这些技术来了解语句和函数的行为。
(2)内置工具如 cProfile,了解代码中哪些函数耗时最长,并用 runsnake 进行可视化。
(3)line_profiler 工具,对选定的函数进行逐行分析,其结果包含每行被调用的次数以及每行花费的时间百分比。
(4)memory_profiler 工具,以图的形式展示RAM的使用情况随时间的变化,解释为什么某个函数占用了比预期更多的 RAM。
(5)Guppy 项目的 heapy 工具,查看 Python 堆中对象的数量以及每个对象的大小,这对于消灭奇怪的内存泄漏特别有用。
(6)dowser 工具,通过Web浏览器界面审查一个持续运行的进程中的实时对象。
(7)dis 模块,查看 CPython 的字节码,了解基于栈的 Python 虚拟机如何运行。
(8)单元测试,在性能分析时要避免由优化手段带来的破坏性后果。
作者强调了性能分析的重要性,同时也对如何确保性能分析的成功提了醒,例如,将测试代码与主体代码分离、避免硬件条件的干扰(如在BIOS上禁用了TurboBoost、禁用了操作系统改写SpeedStep、只使用主电源等)、运行实验时禁用后台工具如备份和Dropbox、多次实验、重启并重跑实验来二次验证结果,等等。
性能分析对于高性能编程的作用,就好比复杂度分析对于算法的作用,它本身不是高性能编程的一部分,但却是最终有效的一种评判标准。
2、数据结构的影响
高性能编程最重要的事情是了解数据结构所能提供的性能保证。
高性能编程的很大一部分是了解你查询数据的方式,并选择一个能够迅速响应这个查询的数据结构。
书中主要分析了 4 种数据结构:列表和元组就类似于其它编程语言的数组,主要用于存储具有内在次序的数据;而字典和集合就类似其它编程语言的哈希表/散列集,主要用于存储无序的数据。
本书在介绍相关内容的时候很克制,所介绍的都是些影响“速度更快、开销更低”的内容,例如:内置的 Tim 排序算法、列表的 resize 操作带来的超额分配的开销、元组的内存滞留(intern机制)带来的资源优化、散列函数与嗅探函数的工作原理、散列碰撞带来的麻烦与应对、Python 命名空间的管理,等等。
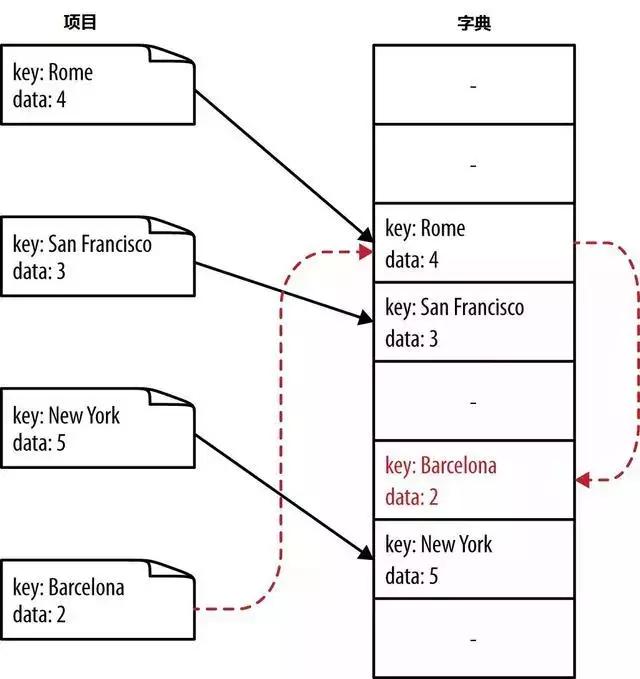
散列碰撞的结果
理解了这些内容,就能更加了解在什么情况下使用什么数据结构,以及如何优化这些数据结构的性能。
另外,关于这 4 种数据结构,书中还得出了一些有趣的结论:对于一个拥有100 000 000个元素的大列表,实际分配的可能是112 500 007个元素;初始化一个列表比初始化一个元组慢5.1 倍;字典或集合默认的最小长度是8(也就是说,即使你只保存3个值,Python仍然会分配 8 个元素)、对于有限大小的字典不存在一个最佳的散列函数。
3、矩阵和矢量计算
矢量计算是计算机工作原理不可或缺的部分,也是在芯片层次上对程序进行加速所必须了解的部分。
然而,原生 Python 并不支持矢量操作,因为 Python 列表存储的不是实际的数据,而是对实际数据的引用。在矢量和矩阵操作时,这种存储结构会造成极大的性能下降。比如,grid[5][2] 中的两个数字其实是索引值,程序需要根据索引值进行两次查找,才能获得实际的数据。
同时,因为数据被分片存储,我们只能分别对每一片进行传输,而不是一次性传输整个块,因此,内存传输的开销也很大。
减少瓶颈最好的方法是让代码知道如何分配我们的内存以及如何使用我们的数据进行计算。
Numpy 能够将数据连续存储在内存中并支持数据的矢量操作,在数据处理方面,它是高性能编程的最佳解决方案之一。
Numpy 带来性能提升的关键在于,它使用了高度优化且特殊构建的对象,取代通用的列表结构来处理数组,由此减少了内存碎片;此外,自动矢量化的数学操作使得矩阵计算非常高效。
Numpy 在矢量操作上的缺陷是一次只能处理一个操作。例如,当我们做 A * B + C 这样的矢量操作时,先要等待 A * B 操作完成,并保存数据在一个临时矢量中,然后再将这个新的矢量和 C 相加。
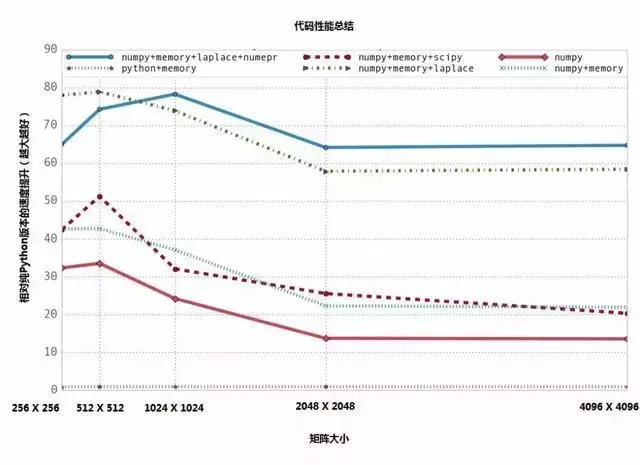
Numexpr 模块可以将矢量表达式编译成非常高效的代码,可以将缓存失效以及临时变量的数量最小化。另外,它还能利用多核 CPU 以及 Intel 芯片专用的指令集来将速度最大化。
书中尝试了多种优化方法的组合,通过详细的分析,展示了高性能编程所能带来的提升效果。
4、编译器
书中提出一个观点:让你的代码运行更快的最简单的办法就是让它做更少的工作。
编译器把代码编译成机器码,是提高性能的关键组成部分。
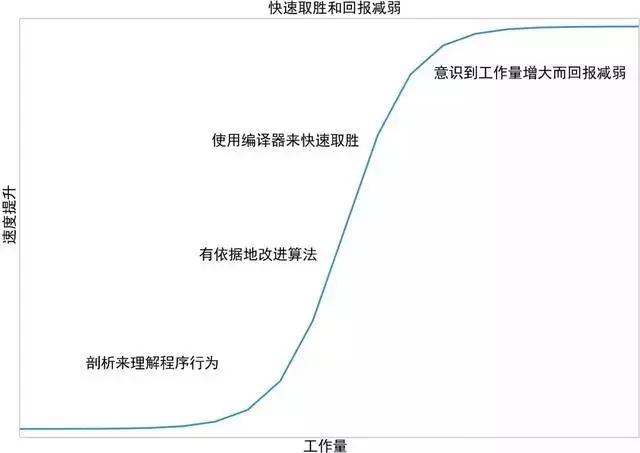
不同的编译器有什么优势呢,它们对于性能提升会带来多少好处呢?书中主要介绍了如下编译工具:
Cython ——这是编译成C最通用的工具,覆盖了Numpy和普通的Python代码(需要一些C语言的知识)。
Shed Skin —— 一个用于非Numpy代码的,自动把Python转换成C的转换器。
Numba —— 一个专用于Numpy的新编译器。
Pythran —— 一个用于Numpy和非numpy代码的新编译器。
PyPy —— 一个用于非Numpy代码的,取代常规Python可执行程序的稳定的即时编译器。
书中分析了这几种编译器的工作原理、优化范围、以及适用场景等,是不错的入门介绍。此外,作者还提到了其它的编译工具,如Theano、Parakeet、PyViennaCL、ViennaCL、Nuitka 与 Pyston 等,它们各有取舍,在不同领域提供了支撑之力。
5、密集型任务
高性能编程的一个改进方向是提高密集型任务的处理效率,而这样的任务无非两大类:I/O 密集型与 CPU 密集型。
I/O 密集型任务主要是磁盘读写与网络通信任务,占用较多 I/O 时间,而对 CPU 要求较少;CPU 密集型任务恰恰相反,它们要消耗较多的 CPU 时间,进行大量的复杂的计算,例如计算圆周率与解析视频等。
改善 I/O 密集型任务的技术是异步编程 ,它使得程序在 I/O 阻塞时,并发执行其它任务,并通过“事件循环”机制来管理各项任务的运行时机,从而提升程序的执行效率。
书中介绍了三种异步编程的库:Gevent、Tornado 和 Asyncio,对三种模块的区别做了较多分析。
改善 CPU 密集型任务的主要方法是利用多核 CPU 进行多进程的运算。
Multiprocessing 模块基于进程和基于线程的并行处理,在队列上共享任务,以及在进程间共享数据,是处理CPU密集型任务的重要技术。
书中没有隐瞒它的局限性:Amdahl 定律揭示的优化限度、适应于单机多核而多机则有其它选择、全局解释锁 GIL 的束缚、以及进程间通信(同步数据和检查共享数据)的开销。针对进程间通信问题,书中还分析了多种解决方案,例如 Less Naïve Pool、Manager、Redis、RawValue、MMap 等。
6、集群与现场教训
集群是一种多服务器运行相同任务的结构,也就是说,集群中的各节点提供相同的服务,其优点是系统扩展容易、具备容灾恢复能力。
集群需要克服的挑战有:机器间信息同步的延迟、机器间配置与性能的差异、机器的损耗与维护、其它难以预料的问题。书中列举了两个惨痛的教训:华尔街公司骑士资本由于软件升级引入的错误,损失4.62亿美元;Skype 公司 24 小时全球中断的严重事故。
书中给我们重点介绍了三个集群化解决方案:Parallel Python、IPython Parallel 和 NSQ。引申也介绍了一些普遍使用的方案,如 Celery、Gearman、PyRes、SQS。
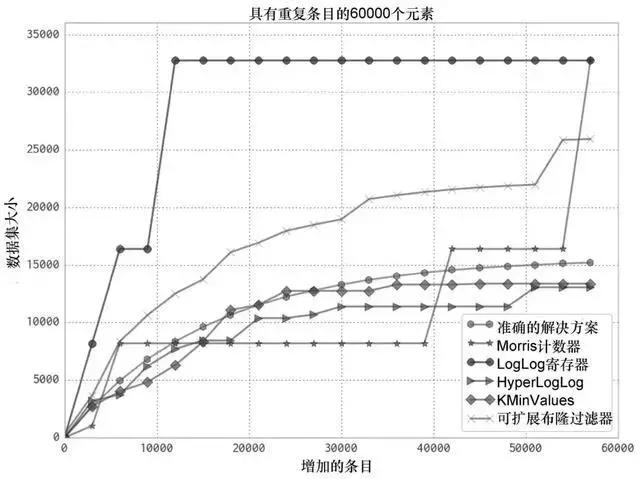
关于现场教训,它们不仅仅是一些事故或者故事而已,由成功的公司所总结出来的经验更是来之不易的智慧。书中单独用一章内容分享了六篇文章,这些文章出自几个使用 Python 的公司/大型组织,像是Adaptive Lab、RadimRehurek、Smesh、PyPy 与 Lanyrd ,这些国外组织的一线实践经验,应该也能给国内的 Python 社区带来一些启示。
7、写在最后
众所周知,Python 应用前景大、简单易学、方便开发与部署,然而与其它编程语言相比,它的性能几乎总是落于下风。如何解决这个难题呢?本期荐书的书目就是一种回应。
《Python高性能编程》全书从微观到宏观对高性能编程的方方面面做了讲解,主要包含以下主题:计算机内部结构的背景知识、列表和元组、字典和集合、迭代器和生成器、矩阵和矢量计算、编译器、并发、集群和工作队列等。这些内容为编写更快的 Python 指明了答案。
本篇文章主要以梳理书中的内容要点为主,平均而兼顾地理清了全书脉络(PS:太面面俱到了,但愿不被指责为一篇流水账的读书笔记才好……)。我认为,鉴于书中谈及的这些话题,它就足以成为我们荐书栏目的一员了。除去某些句段的糟糕翻译、成书时间比较早(2014年)而造成的过时外,这本书总体质量不错,可称为是一份优秀的高性能编程的指引手册。返回搜狐,查看更多
责任编辑:

