
- 1“智算”雄起 | 青云科技:智算中心建设、运营两不误
- 2万界星空科技MES系统:食品加工安全的实时监控与智能管理
- 3【PyTorch】解决 No module named ‘torchvision.models.utils‘_no module named 'torchvision.models.utils
- 4如何提交代码到github仓库(2022最新最详细)_github上传代码到仓库
- 5概念:四种基于模型的嵌入式软件开发、测试与验证方法_嵌入式软件建模技术
- 6vscode找不到git
- 7springboot+mysql网上书店管理系统的设计与实现—计算机毕业设计03780
- 8SVN的使用---Windows环境:概述、安装配置、使用详解、多仓库与权限控制、服务配置与管理、扩展程序_svn配置
- 9Antd Form 表单实现单项自定义请求校验_antd form自定义校验
- 10<12>基础知识——进一步了解路由表_路由表和子网
transformer学习总结_transformer学习心得
赞
踩
Self-Attention
将输入x表示为向量a(通过Word2Vec,GloVe,one-hot等词嵌入方法),然后用向量a分别乘以三个矩阵,得到三个向量q,k,v

拿第一个q分别对每一个k做attention计算,得到结果α
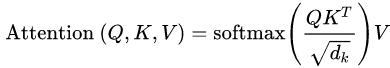
自注意力得分决定了在编码单词x1的过程中有多重视句子的其它单词。

将得到的所有α做softmax处理,得到ā
softmax分数决定了每个单词对编码当下位置x1的贡献
将ā与v相乘再相加,得到输出b

用同样的方法得到得到所有的输出b

所有的输出b都是同时计算出来的

下面的图展示的是上面几个步骤的向量化,然后通过矩阵运算实现




Multi-head Self-attention
在多头注意机制下,每个头保持独立的查询/键/值权重矩阵,从而产生不同的查询/键/值矩阵。


直接把得到的输出矩阵拼接在一起,然后用一个附加的权重矩阵WO与它们相乘,得到最终的输出矩阵

Position Encoding
self-attention中没有词语位置信息。Transformer在每个输入词向量上都会加上位置编码

输入的inputs embedding后都添加了位置编码positional encoding
positional encoding获取方式:
1.可以通过数据训练学习得到positional encoding,类似于训练学习词向量,bert中的positional encoding便是由训练得到地。
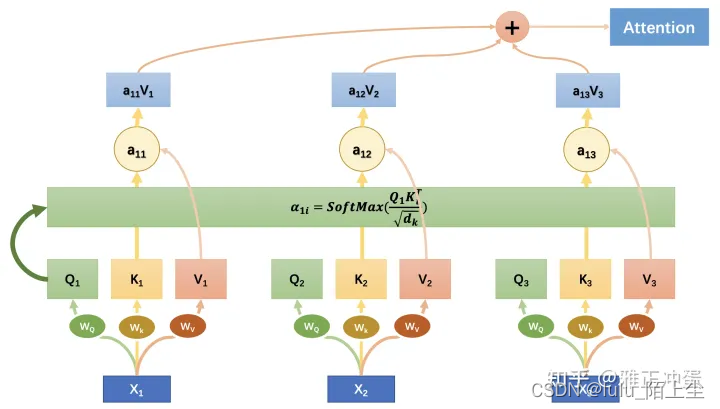
2.《Attention Is All You Need》论文中Transformer使用的是正余弦位置编码。位置编码通过使用不同频率的正弦、余弦函数生成,然后和对应的位置的词向量相加,位置向量维度必须和词向量的维度一致。PE(positional encoding)计算公式如下:
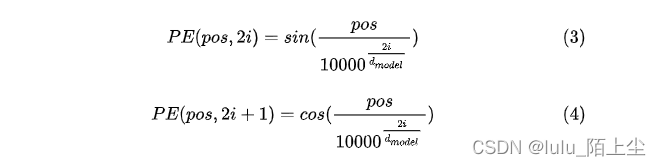
pos表示单词在句子中的绝对位置,pos=0,1,2…
dmodel表示词向量的维度,在这里dmodel=512
2i和2i+1表示奇偶性,i表示词向量中的第几维,例如这里dmodel=512,故i=0,1,2…255。
加入self-attention的seq2seq

Transformer
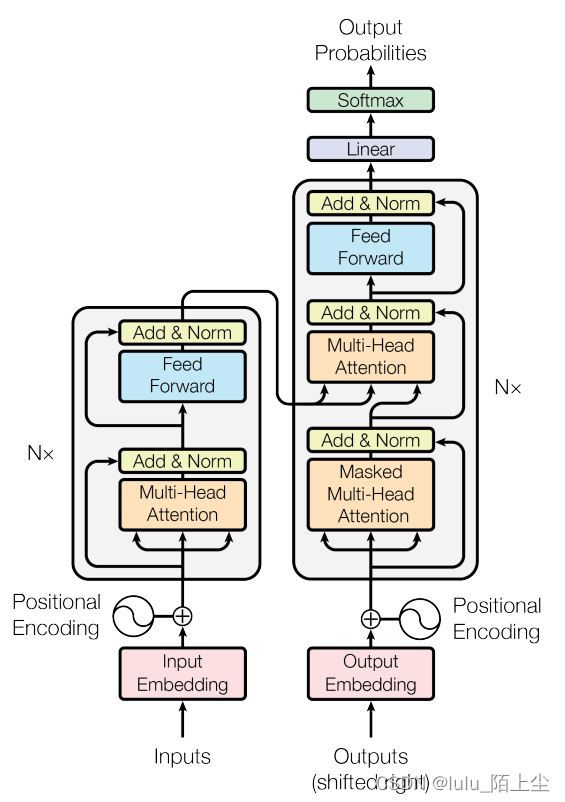


Encoder部分
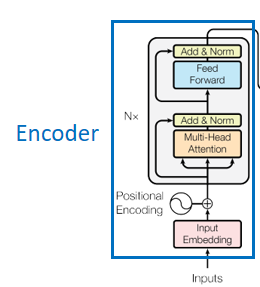
主要包括两部分,multi-head attention 和 feed forward
Multi-Head Attention
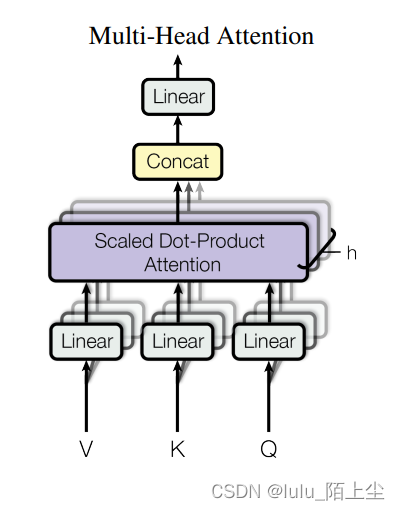
比起直接用
d
m
o
d
e
l
d_{model}
dmodel的Q, K, V来说,将Q, K, V用不同的h个线性投影得到的h个
d
v
d_{v}
dv的context vector,再concat起来,过一个线性层的结果更好,可以综合不同位置的不同表征子空间的信息。论文中设置了h=8个head,
d
k
d_{k}
dk =
d
v
d_{v}
dv =
d
m
o
d
e
l
/
h
d_{model}/h
dmodel/h
M
u
l
t
i
h
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
h
e
a
d
2
,
.
.
.
,
h
e
a
d
h
)
W
O
Multihead(Q,K,V)=Concat(head_{1},head_{2},...,head_{h})W^{O}
Multihead(Q,K,V)=Concat(head1,head2,...,headh)WO
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
head_{i}=Attention(QW_{i}^{Q},KW_{i}^{K},VW_{i}^{V})
headi=Attention(QWiQ,KWiK,VWiV)
W i Q ∈ R d m o d e l × d k W_{i}^{Q}\in \mathbb{R}^{d_{model}\times d_{k}} WiQ∈Rdmodel×dk, W i K ∈ R d m o d e l × d k W_{i}^{K}\in \mathbb{R}^{d_{model}\times d_{k}} WiK∈Rdmodel×dk, W i V ∈ R d m o d e l × d v W_{i}^{V}\in \mathbb{R}^{d_{model}\times d_{v}} WiV∈Rdmodel×dv, W O ∈ R h d v × d m o d e l W^{O}\in \mathbb{R}^{hd_{v}\times d_{model}} WO∈Rhdv×dmodel
Feed Forward
这是一个由两层神经元组成的前向传播网络,第一层的激活函数是relu,第二层的激活函数是identity。第二层的输出维度和第一层的输入维度相同。
Add&Norm
Add的意思就是将上一层的输出结果和它的输入值相加,Norm就是经典的LayerNorm了。
输入序列中每个位置的单词都有自己独特的路径流入编码器。在自注意力层中,这些路径之间存在依赖关系。而前馈(feed-forward)层没有这些依赖关系。因此在前馈(feed-forward)层时可以并行执行各种路径。
Decoder部分
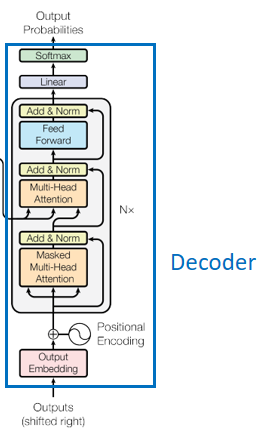
顶端编码器的输出之后会变转化为一个包含向量K(键向量)和V(值向量)的注意力向量集 。这些向量将被每个解码器用于自身的“编码-解码注意力层”,而这些层可以帮助解码器关注输入序列哪些位置合适
Masked multi-head attention: 和编码部分的multi-head attention类似
解码器中的自注意力层表现的模式与编码器不同:在解码器中,自注意力层只被允许处理输出序列中更靠前的那些位置。在softmax步骤前,它会把后面的位置给隐去。

Multi-Head Attention
这个“编码-解码注意力层”工作方式基本就像多头自注意力层一样,它是通过在它下面的自注意力层来创造查询矩阵,并且从Encoder编码器的输出中取得键/值矩阵。
Linear
解码组件最后会输出一个实数向量。线性变换层要做的工作是把浮点数变成一个单词。
线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。
Softmax 层
不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。
接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。
解码(decoding )阶段的每一个时间步都输出一个翻译后的单词(这里的例子是英语翻译)。重复这个过程,直到输出一个结束符,Transformer 就完成了所有的输出。每一步的输出都会在下一个时间步输入到下面的第一个解码器。Decoder 就像 Encoder 那样,从下往上一层一层地输出结果。正对如编码器的输入所做的处理,我们把解码器的输入向量,也加上位置编码向量,来指示每个词的位置。


