
- 1完全背包问题-动态规划_动态规划 全背包问题。有n种重量和价值分别为wi、vi(1≤i≤n)的物品,
- 2Parallels Desktop 19 for Mac 发布, 简化 macOS 和 Windows 交互_parallels desktop 19 百度云
- 3时序数据处理模型:RNN与LSTM总结_处理时序 信息的网络模型
- 4顺序表的操作例题——已知一个顺序表L, 其中的元素递增有序排列,设计一个算法,插入一个元素x (x为int 后保持该顺序表仍然递增有序排列(假设插入操作总能成功)。_设计一个算法,判断顺序表l中所有元素是否是递增有序的。
- 5结构体链表 (创建)_结构体链表的创建
- 6【人工智能 | 知识表示方法】状态空间法 & 语义网络,良好的知识表示是解题的关键!(笔记总结系列)_状态空间法总结
- 7阿里P7架构师开源分享2023最新897道java面试题答案
- 8el-tree饿了么elementUI tree树结构插件设置全部展开折叠_饿了么ui树形组件
- 9时间频度,时间复杂度的计算
- 10ffmpeg和ImageMagick使用_failedtoexecutecommand `"gswin64c.exe
【爬虫】基础爬虫案例分析(一看就懂)_爬虫案例学习
赞
踩
什么是爬虫。简单一句话就是代替人去模拟浏览器进行网页操作。
爬虫的作用。为其他程序提供数据源,如搜索引擎(百度、Google等)、数据分析、大数据等等。
一、准备工作
我们需要先做好如下准备工作:
具体安装步骤可以看下这个链接:http://t.csdn.cn/RvBqQ
2.了解 Python HTTP请求库requests 的基本用法。
请求,英文为Request,由客户端发往服务器,分为四部分内容: 请求方法(Request Method).请求的网址(Request URL )、请求头( Request Headers )、请求体(Request Body )。
这里我就不系统的解释了,如果想要了解更完善可以点击这个链接:http://t.csdn.cn/unbf3
3.了解正则表达式的用法和 Python 中正则表达式库 re 的基本用法。
1.正则表达式的用法
(1)判断特定字符串
(2)切割字符串
(3)提取字符串信息
(4)替换字符串
2.正则表达式库 re 的基本用法
re模块主要定义了9个常量、12个函数、1个异常,re库,Python处理文本的标准库(标准库的意思表示这是一个Python内置模块,不需要额外下载)。
(1)sreach用法 :它会搜索整个 HTML 文本,找到符合上述正则表达式的第一个内容并返回。匹配连续的多个数值。
(2)match用法:向它传人要匹配的字符串以及正则表达式,就可以检测这个正则表达式是否和字符串相匹配。
(3)compile用法:可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用。
(4) findall用法:获取与正则表达式相匹配的所有字符串。
(5) sub 用法:使用正则表达式提取信息,有时候还需要借助它来修改文本。
二.爬取目标
本节我们以一个基本的静态网站作为案例进行爬取,需要爬取的链接为 https://ssr1.scrape.center这个网站里面包含一些电影信息,界面如图所示。
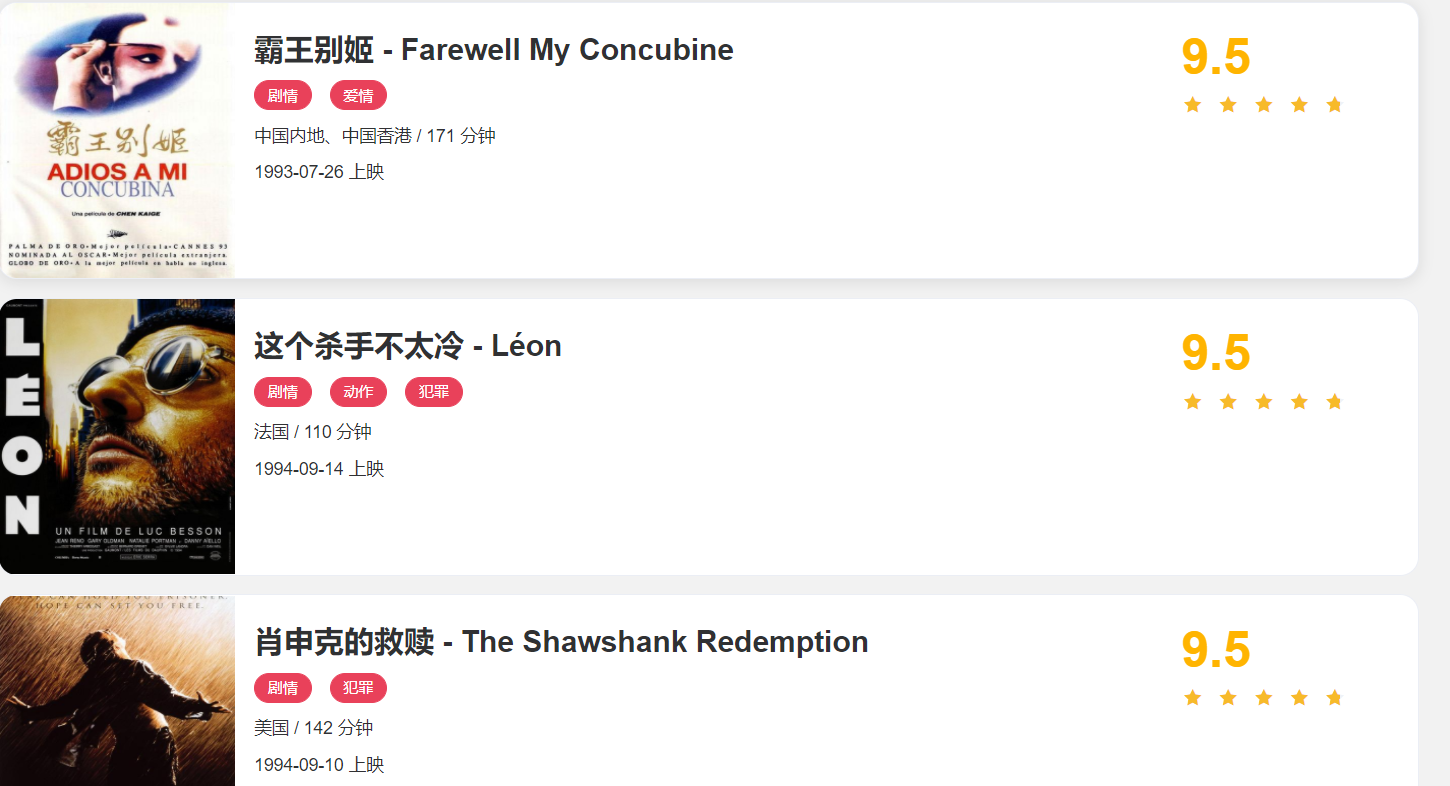
网站首页展示了一个由多个电影组成的列表,其中每部电影都包含封面、名称、分类、上映时间评分等内容,同时列表页还支持翻页,单击相应的页码就能进入对应的新列表页。如果我们点开其中一部电影,会进入该电影的详情页面,例如我们打开第一部电影《霸王别姬》.会得到如图 所示的页面。

这个页面显示的内容更加丰富,包括剧情简介、导演、演员等信息。
我们本次爬虫要完成的目标有:
1.利用 requests 爬取这个站点每一页的电影列表,顺着列表再爬取每个电影的详情页;
2.用正则表达式提取每部电影的名称、封面、类别、上映时间、评分、刷情简介等内容
把以上爬取的内容保存为JSON 文本文件;
已经做好准备,也明确了目标,那我们现在就开始吧。

