
- 1零基础小白撸空投攻略:空投流程是什么样的? 如何操作?_web3怎么撸空投
- 2vue 单元测试_vue单元测试
- 3【数据结构-C语言】冒泡排序,插入排序,选择排序
- 4最短生成树 (超详细大全)
- 5crossover如何永久免费 crossover激活码分享 crossover软件安装使用 2024永久免费版CrossOver软件下载
- 6细节详解 | Bert,GPT,RNN及LSTM模型
- 7【2024华为OD机试C卷】476、矩阵匹配、数组中第 K 大的数中的最小值 | 机试真题+思路参考+代码解析(C语言、C++、Java、Py、JS)
- 82022 01 27 dnf 起号 搬砖 脚本源码开源 by ~戴眼镜的猫_dnf脚本源码
- 9软件测试面试八股文(答案+文档)_软件测试八股文.pdf
- 10配置Java开发环境
数据结构与算法--排序算法:冒泡排序 多种方法让你彻底搞懂冒泡排序_冒泡排序数据结构
赞
踩
排序的相关概念
排序算法(Sorting algorithm)是一种能将一串数据依照特定顺序进行排列的一种算法
排序算法的稳定性
稳定性:稳定排序算法会让原本有相等键值的纪录维持相对次序。
也就是如果一个排序算法是稳定的,当有两个相等键值的纪录R和S,且在原本的列表中R出现在S之前,
在排序过的列表中R也将会是在S之前。
当相等的元素是无法分辨的,比如像是整数,稳定性并不是一个问题。然而,
假设以下的数对将要以他们的第一个数字来排序。
(4, 1) (3, 1) (3, 7)(5, 6)
在这个状况下,有可能产生两种不同的结果,一个是让相等键值的纪录维持相对的次序,
而另外一个则没有:
(3, 1) (3, 7) (4, 1) (5, 6) (维持次序)稳定
(3, 7) (3, 1) (4, 1) (5, 6) (次序被改变)不稳定
不稳定排序算法可能会在相等的键值中改变纪录的相对次序,但是稳定排序算法从来不会如此。
不稳定排序算法可以被特别地实现为稳定。作这件事情的一个方式是人工扩充键值的比较,
如此在其他方面相同键值的两个对象间之比较,(比如上面的比较中加入第二个标准:第二个键值的大小)
就会被决定使用在原先数据次序中的条目,当作一个同分决赛。
然而,要记住这种次序通常牵涉到额外的空间负担。
十大排序算法的总结


- 相关术语解释:

冒泡排序
冒泡排序(英语:Bubble Sort)是一种简单的排序算法。
它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序算法的运作如下:
比较相邻的元素。如果第一个比第二个大(升序),就交换他们两个。
对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。
这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。

那么我们需要进行n-1次冒泡过程,每次对应的比较次数如下图所示:

实现冒泡排序

法一:通常方法
def bubble_sort(li):
for j in range(len(li) - 1): #【备注1】写成 for j in range(len(li)) 也行
# 取(0,n-1),产生 0~n-2 总共n-1个数,只需比较前一个和后一个的关系
for i in range(len(li) - 1 - j): # 需要两两比较的次数
if li[i] > li[i + 1]:
li[i], li[i + 1] = li[i + 1], li[i]
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
print(li)
bubble_sort(li)
print(li)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

法二:过程和次数 联动
def bubble_sort(alist):
for j in range(len(alist) - 1, 0, -1): # 【备注2】写成 for j in range(len(alist) - 1, -1, -1) 也行
# j表示每次遍历需要比较的次数,是逐渐减小的
for i in range(j):
if alist[i] > alist[i + 1]:
alist[i], alist[i + 1] = alist[i + 1], alist[i]
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
print(li)
bubble_sort(li)
print(li)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
法三:从最后一个数和它前面的数依次比较
def bubble_sort(array): for i in range(len(array)): 【备注3】 for i in range(len(array-1)) 也行 flag = False for j in range(len(array) - 1, i, -1): # 注意 每次 都到 一个 i if array[j] < array[j - 1]: array[j - 1], array[j] = array[j], array[j - 1] flag = True print('测试本行是否执行') if flag is False: # if not flag: return array = [1, 5, 3, 4, 8, 6, 7] bubble_sort(array) print(array)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
解释上面两个【备注】对于这个外层界限,其实是关于 当数列只有两个 元素时,需不需要比较都是可以的,两个元素没有严格意义的存在排序,这是对于 过程数来说,多一次和少一次是不重要的;重要的是:内层最后比较的两个数,一定是要到 最尾端 前一个数,这样才存在 前后关系
复杂度
最优时间复杂度:O(n) (表示遍历一次发现没有任何可以交换的元素,排序结束)
最坏时间复杂度:O(n2)
稳定性:稳定
冒泡排序对n个数据操作n-1轮,每轮找出一个最大(小)值。
操作只对相邻两个数比较与交换,每轮会将一个最值交换到数据列首(尾),像冒泡一样。
每轮操作O(n)次,共O(n)轮,时间复杂度O(n^2)。
额外空间开销出在交换数据时那一个过渡空间,空间复杂度O(1)
过程示意图
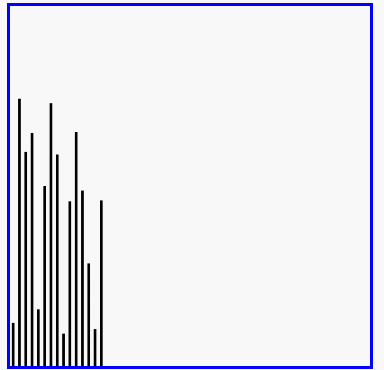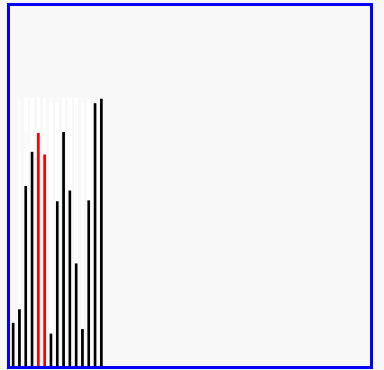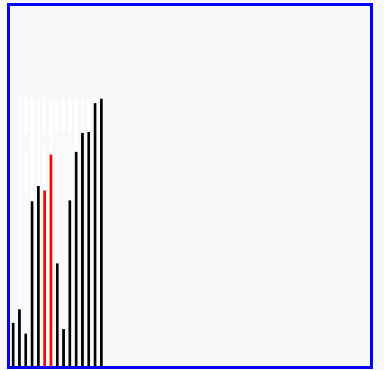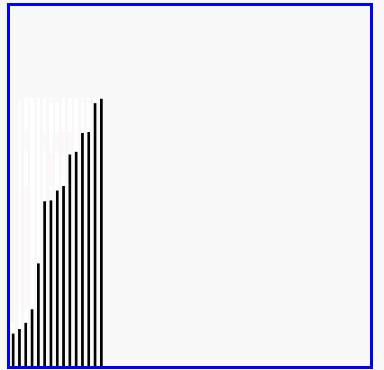
冒泡排序实质和优化
实质
''' 每次比较的次数都递减,整个过程总次数是要进行最坏程度时的次数 0 1 2 3 4 5 6 7 1 0 1 2 3 4 5 6 2 0 1 2 3 4 5 . 0 1 2 3 4 . 0 1 2 3 0 1 2 0 1 0 n-1 for i in range(n-1) for j in range(n-1-j) 或者: for i in range(n-1,0,-1) for j in range(i) '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
冒泡排序优化
未优化时,当检测一次从头走到尾,发现不需要进行任何交换,说明已经是有序了,
此时时间复杂度为O(n)
冒泡排序优化一
def bubble_sort(li): for j in range(len(li) - 1): count = 0 # 记录交换的次数 for i in range(len(li) - 1 - j): if li[i] > li[i + 1]: li[i], li[i + 1] = li[i + 1], li[i] count += 1 # 只有在满足判断条件才会被计数 if count == 0: return li = [54, 26, 93, 17, 77, 31, 44, 55, 20] print(li) bubble_sort(li) print(li) ''' 说明:上述,因为是在给列表排序,列表只要内部改变了,外部也会跟着改变;但是上述给的终止条件,直接return,虽然能正常排序,但是存在错误!不妨 试一下这样写也可以! def bubble_sort(li): for j in range(len(li) - 1): count = 0 # 记录交换的次数 for i in range(len(li) - 1 - j): if li[i] > li[i + 1]: li[i], li[i + 1] = li[i + 1], li[i] count += 1 # 只有在满足判断条件才会被计数 if count == 0: break # return li 或者同时在外层循环加上返回列表也行 li = [54, 26, 93, 17, 77, 31, 44, 55, 20] print(li) bubble_sort(li) print(li) 【不妨尝试做一下这题,就能发现出错的情况】 题目:输入一个整数数组,实现一个函数来调整该数组中数字的顺序, 使得所有的奇数位于数组的前半部分,所有的偶数位于数组的后半部分, 并保证奇数和奇数,偶数和偶数之间的相对位置不变。 这道题可以用冒泡排序的思维解答: def reorder(array): for i in range(len(array)): flag = False # 设置一个falg for j in range(len(array) - 1, i, -1): # 后奇前偶再交换 if array[j] % 2 == 1 and array[j - 1] % 2 == 0: array[j - 1], array[j] = array[j], array[j - 1] flag = True # 如果发生的交换,置为True if flag is False: # 如果一次过程下来,还是False,说明已经排好,后序可以不用进行了 break # 跳出外层for循环,不可以用return,return会直接退出函数 return array array = [10, 8, 5, 2, 3, 4, 6] print(reorder(array)) ''' # 规范写法: def bubble_sort(li): for j in range(len(li) - 1): count = 0 # 记录交换的次数 for i in range(len(li) - 1 - j): if li[i] > li[i + 1]: li[i], li[i + 1] = li[i + 1], li[i] count += 1 # 只有在满足判断条件才会被计数 if count == 0: # 判断一个过程后,发现都没有发生变化,那么后序也不用判断了,跳出循环即可 break return li # 返回排序好的列表 li = [54, 26, 93, 17, 77, 31, 44, 55, 20] print(li) bubble_sort(li) print(li) ''' # 用 flag 是一样的道理 def bubble_sort(items): for i in range(len(items) - 1): flag = False for j in range(len(items) - 1 - i): if items[j] > items[j + 1]: items[j], items[j + 1] = items[j + 1], items[j] flag = True if not flag: # if flag is False: break return items li = [54, 26, 93, 17, 77, 31, 44, 55, 20] print(li) bubble_sort(li) print(li) '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
冒泡排序优化 二:搅拌排序/鸡尾酒排序
上面这种写法还有一个问题,就是每次都是从左边到右边进行比较,这样效率不高,
你要考虑当最大值和最小值分别在两端的情况。写成双向排序提高效率,
即当一次从左向右的排序比较结束后,立马从右向左来一次排序比较。
def bubble_sort(items): for i in range(len(items) - 1): flag = False for j in range(len(items) - 1 - i): if items[j] > items[j + 1]: items[j], items[j + 1] = items[j + 1], items[j] flag = True if flag: flag = False for j in range(len(items) - 2 - i, 0, -1): if items[j - 1] > items[j]: items[j], items[j - 1] = items[j - 1], items[j] flag = True if not flag: break return items li = [54, 26, 93, 17, 77, 31, 44, 55, 20] print(li) bubble_sort(li) print(li)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

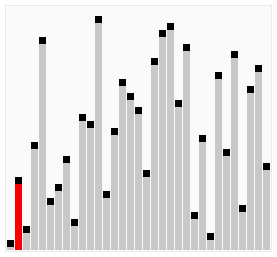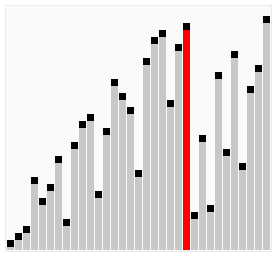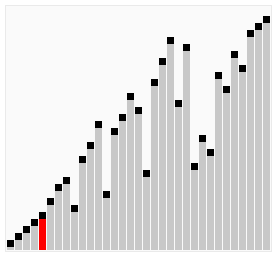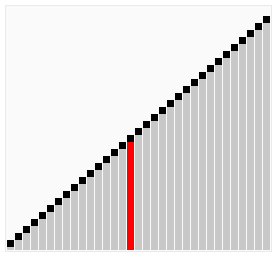
冒泡排序优化三
最后要考虑的情况就是,如果给你的不是列表,而是对象,或者列表里面都是字符串,
那么上述的代码也就没有用了,这时候你就要自定义函数了,并将其当成参数传入bubble_sort函数

输出结果:[‘pear’, ‘apple’, ‘pitaya’, ‘waxberry’, ‘watermelon’]
类似的,当给一个类对象排序时,也可以传入lambda 自定义函数
def __init__(self, name, age): self.name = name self.age = age def __repr__(self): return f'{self.name}: {self.age}' items1 = [ Student('Wang Dachui', 25), Student('Di ren jie', 38), Student('Zhang Sanfeng', 120), Student('Bai yuanfang', 18) ] print(bubble_sort(items1, lambda s1, s2: s1.age > s2.age)) ''' 输出结果:按照年龄从小到大排序 [Bai yuanfang: 18, Wang Dachui: 25, Di ren jie: 38, Zhang Sanfeng: 120] '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

