
- 1Spark应用案例:推荐系统
- 2ChatGPT重磅福利:语音对话功能正式免费,它有这些好玩的用法_苹果开通chatgpt4
- 3线性代数|机器学习-P23梯度下降
- 4NVMe系统内存结构 - 命令聚合与仲裁_五选二轮转仲裁
- 5史上最强Windows震撼登场:Copilot全面接入,日常AI伴侣正式到来!
- 6持续集成与Devops关系_持续集成关系
- 7手把手教你在VSCODE下写C/C++代码(内附如何连接远端服务器教程)_vscode怎么写c++程序
- 8Java 多线程与高并发,高级java面试题及答案整理_高并发面试题java
- 9VSCode+Latex 环境配置_latex添加到环境变量中 win11 vscode
- 10Ubuntu下安装和配置Redis_ubuntu redis
TensorFlow部署:使用FastAPI部署TF模型_fastapi 机器学习模型部署服务
赞
踩

概述
本文详细介绍了如何使用 FastAPI 部署 TensorFlow 模型。它涉及设置 Tensorflow FastAPI 项目、开发用于模型推理的 API 端点、处理请求和响应格式、增强性能和可扩展性、测试和监控已部署的模型,以及将模型置于部署前的最后阶段。本文的结论中提供了该方法的摘要。
介绍
在当今的 Web 开发世界中,将机器学习模型部署为 API 端点变得越来越重要。这使得应用程序能够利用机器学习的力量进行实时预测以及与其他系统的集成。FastAPI 是一个现代 Python Web 框架,为将 TensorFlow 模型部署为 API 端点提供了高效且简单的解决方案。

无论您是 Web 开发人员还是机器学习专家,本文都将为您提供使用 FastAPI 部署 TensorFlow 模型的有用提示和分步教程。让我们研究一下 TensorFlow FastAPI 在将机器学习模型部署为 API 端点时的强大协同作用。
什么是 FastAPI?
FastAPI 是一个用于创建 Python API 的现代且快速的 Web 框架。其出色的速度、易用性和强大的功能使其在 Web 开发人员中非常受欢迎。FastAPI 具有卓越的性能和可扩展性,因为它基于ASGI(异步服务器网关接口)标准,这使其能够异步处理请求。
![fastapi]

FastAPI支持各种数据格式,包括JSON、表单数据和多部分文件,使其能够灵活地处理不同类型的请求。它提供自动数据验证、序列化和反序列化,减少 API 开发中通常所需的样板代码量。
准备 TensorFlow 模型以进行部署
在部署 TensorFlow Fastapi 模型之前,必须按照以下步骤准备部署:
训练和优化模型:使用 TensorFlow 的 API 来训练和优化您的模型。这涉及定义模型架构、选择合适的损失函数和优化器以及微调超参数。在代表性数据集上训练模型,直到达到令人满意的性能和准确性。
- import tensorflow as tf
- from sklearn.datasets import load_iris
- from sklearn.model_selection import train_test_split
- # Step 1: Load and Preprocess the Iris Dataset
- iris_data = load_iris()
- features = iris_data.data
- labels = iris_data.target
- X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
- model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
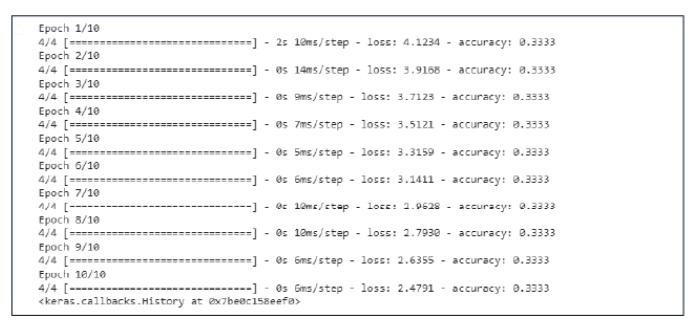
- model.fit(X_train, y_train, epochs=10)
保存训练模型: 使用tf.saved_model.save()函数将模型保存到磁盘。这将创建一个包含模型架构、变量和资产的目录。
- # Save the trained model
- tf.saved_model.save(model, '/content/save')
转换模型(可选):根据部署场景,您可能需要将模型转换为更优化的格式。例如,如果您计划在移动或边缘设备上部署模型,则可以使用 TensorFlow Lite 将 SavedModel 转换为 TensorFlow Lite 模型。转换过程可能涉及量化或其他优化,以便在资源受限的设备上获得更好的性能。
测试保存的模型:使用tf.saved_model.load()函数 加载保存的模型,并对示例数据运行推理以验证模型是否产生预期结果。此步骤有助于在部署之前发现保存的模型的任何问题。
- # Step 3: Test the Saved Model
- loaded_model = tf.saved_model.load(r'/content/save')
- # Run inference on sample data to verify the model
- sample_input = tf.constant(X_test[:1], dtype=tf.float32)
- output = loaded_model(sample_input)
-
- # Print the predicted class probabilities
- print(output)
-
输出:
- tf.Tensor ([ [0.9199518 0.050503190 0.02954495] , shape =(1,3) dtype=float32)
-
设置 FastAPI 项目
创建新的项目目录:首先为 FastAPI 项目创建一个新目录。在您的系统上选择合适的位置。
安装 FastAPI 和其他依赖项:使用 pip 安装 FastAPI 和其他所需的包:
- pip install fastapi uvicorn
-
创建 FastAPI 应用程序文件:在项目目录中创建一个新的 Python 文件,例如 main.py。该文件将包含 FastAPI 应用程序代码。
编写 FastAPI 应用程序代码:在文本编辑器中打开 main.py 文件,然后编写 FastAPI 应用程序的代码。首先导入必要的模块:
- from fastapi import FastAPI
- app = FastAPI()
-
- @app.get("/")
- def read_root():
- return {"message": "Welcome to the application!"}
-
运行 FastAPI 应用程序:通过在项目目录中执行以下命令,使用 Uvicorn 启动 FastAPI 应用程序:
uvicorn main:app --reload

构建用于模型推理的 API 端点
使用 Pydantic 的 BaseModel,我们定义了InputData 类来捕获张量流 fastapi 模型的输入数据的预期格式。使用tf.keras.models.load_model,我们加载已经训练好的 TensorFlow 模型。API 端点/predict的 POST 请求已定义,并且需要 InputData 类格式的 JSON 数据。加载的模型用于在接收到请求的输入特征并将其转换为 numpy 数组后进行推理。然后响应包含预测值。
请注意,在运行此代码之前,您可能需要安装所需的依赖项,例如tensorflow和fastapi。
main.py
- from fastapi import FastAPI
- from pydantic import BaseModel
- from fastapi.responses import JSONResponse
- import tensorflow as tf
- import numpy as np
-
- app = FastAPI()
-
-
- # Request model for input data
- class InputData(BaseModel):
- sepal_length: float
- sepal_width: float
- petal_length: float
- petal_width: float
-
- # Load the trained TensorFlow model
- loaded_model = tf.keras.models.load_model('saved_model/iris_model')
-
- # API endpoint for model inference
- @app.post("/predict")
- def predict(input_data: InputData):
- # Convert input features to a numpy array
- features = np.array([
- [input_data.sepal_length, input_data.sepal_width, input_data.petal_length, input_data.petal_width]
- ])
-
- # Perform model inference
- predictions = loaded_model.predict(features)
- predicted_class = np.argmax(predictions, axis=1)[0]
-
- # Map predicted class index to class label
- class_labels = ["Setosa", "Versicolor", "Virginica"]
- predicted_label = class_labels[predicted_class]
-
- # Convert predicted class to Python integer
- predicted_class = int(predicted_class)
-
- # Create the response JSON
- response_data = {"predicted_class": predicted_class, "predicted_label": predicted_label}
-
- return JSONResponse(content=response_data)
-

处理请求和响应格式
构建 Tensorflow FastAPI 应用程序时,处理不同的请求和响应格式对于与客户端的互操作性至关重要。FastAPI 提供对各种格式的内置支持,包括JSON、表单数据和多部分文件。
API 端点 /predict 已经适当地处理各种请求和响应类型。计划将输入数据作为请求正文中的 JSON 对象发送,并使用 Tensorflow FastAPI 中的 JSONResponse 类将响应作为 JSON 对象返回。
请求格式:
- 使用 @app.post("/predict") 装饰器将端点定义为 POST 请求。
- 输入数据作为 JSON 对象在请求正文中接收。
- 输入数据根据 InputData 模型进行验证,确保所需字段(sepal_width、sepal_length、petal_length、petal_width)存在并且具有正确的数据类型。
- FastAPI 自动将请求正文 JSON 转换为 InputData 模型的实例。
响应格式:
- 使用加载的 TensorFlow 模型和输入数据执行 TensorFlow FastAPI 模型推理。
- 预测的类索引是使用np.argmax(predictions, axis=1)[0]获得的。
- 使用 class_labels 列表将预测的类索引映射到相应的类标签。
- 预测的类别索引将转换为 Python 整数。
- 使用预测的类和标签创建响应 JSON 对象。
- 使用 JSONResponse 类返回响应,该类设置适当的内容类型并返回 JSON 对象作为响应正文。
下面提到的代码将向指定的 URL 发送 POST 请求,并在请求正文中输入 JSON 数据。响应内容将打印到控制台。确保您的本地服务器正在运行并且可通过http://127.0.0.1:8000/predict访问,以使此代码正常工作。
request.py
- import requests
- import json
-
- url = "http://127.0.0.1:8000/predict"
- headers = {"Content-Type": "application/json"}
-
- input_data = {
- "sepal_length": 5.1,
- "sepal_width": 3.5,
- "petal_length": 1.4,
- "petal_width": 0.2
- }
-
- response = requests.post(url, headers=headers, json=input_data)
-
- print(response.content)
-
-
![request]

性能优化和可扩展性
在构建模型推理 API 时,性能优化和可扩展性是重要的考虑因素。以下是一些提高性能和可扩展性的方法:
模型优化:
优化您的 Tensorflow fastapi 模型以减少推理时间和内存使用量。模型量化、剪枝和模型压缩等技术可以帮助实现这一目标。
批量处理:
不要对每个请求进行单独的预测,而是将多个请求一起批处理并并行处理它们。这减少了开销并提高了效率,特别是在处理多个并发请求时。
异步处理: 要同时处理多个请求,请使用异步编程技术。通过同时处理更多请求,可以提高服务器的吞吐量和响应能力。
Optimize.py
- from fastapi import FastAPI
- from pydantic import BaseModel
- from fastapi.responses import JSONResponse
- import tensorflow as tf
- import numpy as np
- from concurrent.futures import ThreadPoolExecutor
- from functools import partial
- from typing import List
- import asyncio
-
-
- app = FastAPI()
-
- # Request model for input data
- class InputData(BaseModel):
- sepal_length: float
- sepal_width: float
- petal_length: float
- petal_width: float
-
- # Load the trained TensorFlow model
- loaded_model = tf.keras.models.load_model('saved_model/iris_model')
-
-
- # Batch Processing and Asynchronous Execution
- executor = ThreadPoolExecutor()
-
- @app.post("/predict-batch")
- async def predict_batch(input_data: List[InputData]):
- # Convert input features to a numpy array
- features = np.array([
- [data.sepal_length, data.sepal_width, data.petal_length, data.petal_width]
- for data in input_data
- ])
-
- # Perform model inference asynchronously
- loop = asyncio.get_running_loop()
- predictions = await loop.run_in_executor(executor, partial(loaded_model.predict, features))
-
- # Map predicted class indices to class labels
- class_labels = ["Setosa", "Versicolor", "Virginica"]
- predicted_labels = [class_labels[np.argmax(prediction)] for prediction in predictions]
-
- # Convert predicted classes to Python integers
- predicted_classes = [int(np.argmax(prediction)) for prediction in predictions]
-
- # Create the response JSON
- response_data = [
- {"predicted_class": predicted_class, "predicted_label": predicted_label}
- for predicted_class, predicted_label in zip(predicted_classes, predicted_labels)
- ]
-
- return JSONResponse(content=response_data)
-
-
-
- if __name__ == "__main__":
- uvicorn.run(app, host="0.0.0.0", port=8000)
-
-
request.py
- import requests
- import json
-
- url = "http://127.0.0.1:8000/predict-batch"
- headers = {"Content-Type": "application/json"}
-
- input_data = [
- {
- "sepal_length": 5.1,
- "sepal_width": 3.5,
- "petal_length": 1.4,
- "petal_width": 0.2
- },
- {
- "sepal_length": 6.4,
- "sepal_width": 2.8,
- "petal_length": 5.6,
- "petal_width": 2.2
- },
- # Add more input data objects as needed
- ]
-
- response = requests.post(url, headers=headers, json=input_data)
-
- print(response.content)
-

测试和监控已部署的模型
测试和监控已部署的模型对于确保其性能、可靠性和准确性至关重要。您可以按照以下步骤来测试和监控已部署的模型:
单元测试:编写单元测试来验证代码各个组件的功能,例如数据预处理、模型推理和响应处理。使用 pytest 或 unittest 等测试框架创建测试用例并运行它们来验证代码的行为。
集成测试:执行集成测试以检查应用程序不同组件之间的交互,例如 API 端点、数据序列化和模型服务。测试各种场景,包括有效和无效的输入数据,以确保您的应用程序正确处理它们。
基准测试:通过运行基准测试来评估其推理速度和资源利用率,从而衡量 Tensorflow FastAPI 模型的性能。这有助于识别任何瓶颈或需要优化的领域。ab (Apache Benchmark) 或 wrk 等工具可用于模拟多个并发请求并测量响应时间。
- import requests
- import json
- import time
-
- # Function to send test requests to the deployed model
- def test_model(endpoint, input_data):
- headers = {"Content-Type": "application/json"}
- response = requests.post(endpoint, headers=headers, json=input_data)
- return response.json()
-
- # Test your model with sample input data
- input_data = {
- "sepal_length": 5.1,
- "sepal_width": 3.5,
- "petal_length": 1.4,
- "petal_width": 0.2
- }
-
- endpoint = "http://127.0.0.1:8000/predict"
-
- # Test the model and measure response time
- start_time = time.time()
- response = test_model(endpoint, input_data)
- end_time = time.time()
-
- # Print the response and response time
- print("Response:", response)
- print("Response Time:", end_time - start_time, "seconds")
-
- # Perform load testing to measure performance under high load
- num_requests = 1000
- start_time = time.time()
-
- for _ in range(num_requests):
- response = test_model(endpoint, input_data)
-
- end_time = time.time()
- total_time = end_time - start_time
- average_response_time = total_time / num_requests
-
- # Print load testing results
- print("Total Requests:", num_requests)
- print("Total Time:", total_time, "seconds")
- print("Average Response Time:", average_response_time, "seconds")
-

我们有一个test_model函数,它将 POST 请求发送到已部署模型的端点并以 JSON 形式返回响应。我们使用此函数通过测量单个请求的响应时间来测试模型的性能,并执行负载测试以模拟高请求负载。
该代码还演示了如何通过定期测试模型并记录相关指标来监控模型。
结论
- FastAPI 是一个用于构建 API 的强大框架,提供高性能和可扩展性。
- 在构建用于 TensorFlow fastapi 模型推理的 API 时,正确处理请求和响应格式非常重要。
- 将经过训练的 TensorFlow fastapi 模型加载到内存中可以在 API 请求期间进行高效的模型推理。
- 测试已部署的模型并监控其性能对于确保可靠性至关重要。

