
- 1pom.xml文件中的repositories,profile和distributionManagement元素_pom.xml repositories
- 2web前端期末大作业 html+css家乡旅游主题网页设计 湖北武汉家乡介绍网页设计实例_我的家乡html+css网页设计免费武汉
- 3labelImg 使用以及安装过程_labelimg安装教程
- 4cv2多图拼接_cv2图片拼接
- 5Oracle启动与关闭及常见问题_oracle startup pfile
- 6实现安装“自由化”!在Windows 11中如何绕过“您尝试安装的应用程序未通过微软验证”_win11安装的应用不是验证过的
- 7mysql导入与导出_mysql schema 导入
- 8UIButton 点击事件响应延迟 问题解决_unity 在button触发事件中延迟
- 9Spring Boot学习(二十二):@ConditionalOnProperty和@ConditionalOnExpression控制加载_@conditionalonexpression("#{systemproperties['my.p
- 10FPS游戏框架漫谈第十天
第一次美赛经历
赞
踩
我的第一次数学竞赛
背景: Wordle 是《纽约时报》目前每日提供的一个热门谜题。玩家尝试在六次或更少的尝试中猜出一个五个字母的单词来解决谜题,每次猜都会收到反馈。对于这个版本,每个猜测必须是一个实际的英语单词。不允许比赛中未识别为单词的猜测 。Wordle 继 续 受到 欢 迎 , 目 前已 有 超 过 60 种 语 言的 游 戏 版 本 。《 纽 约 时 报 》网 站对 Wordle 的说明指出,提交单词后,瓷砖的颜色会发生变化。黄色平铺表示该平铺中的字母在单词中,但它位于错误的位置。绿色平铺表示该平铺中的字母在单词中,并且位于正确的位置。灰色平铺表示该平铺中的字母根本不包含在单词中。
•报告结果的数量每天都在变化。开发一个模型来解释这种变化,并使用您的模型为 2023 年 3 月 1 日报告的结果数量创建一个预测区间。单词的任何属性是否会影响在硬模式下播放的报告分数百分比?如果是,怎么办?如果没有,为什么不呢?
•对于给定的未来解决方案单词,在未来的日期,开发一个模
型,使您能够预测报告结果的分布。换句话说,预测未来日期(1,2,3,4,5,6,X)的相关百分比。你的模型和预测有哪些不确定性?举一个具体的例子,说明你对 2023 年 3 月 1 日 EERIE 一词的预测。你对模型的预测有多自信?
•开发并总结一个模型,根据难度对解决方案单词进行分类。识别与每个分类相关的给定单词的属性。使用你的模型,EERIE 这个词有多难?讨论分类模型的准确性。
•列出并描述此数据集的一些其他有趣的功能。
……
解题思路
我们选的是2023年的c题,因为其它题目都要数据,我和队友们找了一上午都没找到什么有用的数据,最终还是选择了提供数据的c题。感觉主要是我的问题,Python学的不够深入,爬取不了什么有用的数据,拖了团队的后腿,感谢我的队友没有嫌弃我,人间大爱。
不得不说这四天的比赛非真的常幸苦,我是负责编程的,从早上8点一直敲代码到晚上12点,数据这边改一改,那边改一改,为了保存原来的模型,我每改一次数据就要引入一个变量,导致最后变量交错复杂,时不时会报错。程序员口中常说的屎山代码大概就是这么来的,重构代码即麻烦还可能会代码运行不了,于是不断往上面加东西,加到最后就算是自己也看不懂代码了。
刚开始拿到题目,我想的是如何处理这些单词,因为单词必须要处理成数字才能让计算机理解,这样我的算法才有用,所以我们一直卡在这里,最后还是绕了个大弯来解决这个问题,因为我真的不知道怎么处理了这些单词啊。经过激烈的头脑风暴,我找到了词向量这给东西,希望它能让我攻克这个难题,但是很遗憾,深入发掘,这属于自然语言处理问题,即NLP,属于深度学习领域的,与我这个目前只会几个机器学习算法的人有天壤之别的感觉。
第一问还是我的队友用时间序列做出来的,我大受震撼,感到不可思议以及难以理解,我认为这恰恰是我们要注意的地方,其中必有大坑,只能说学识尚浅。
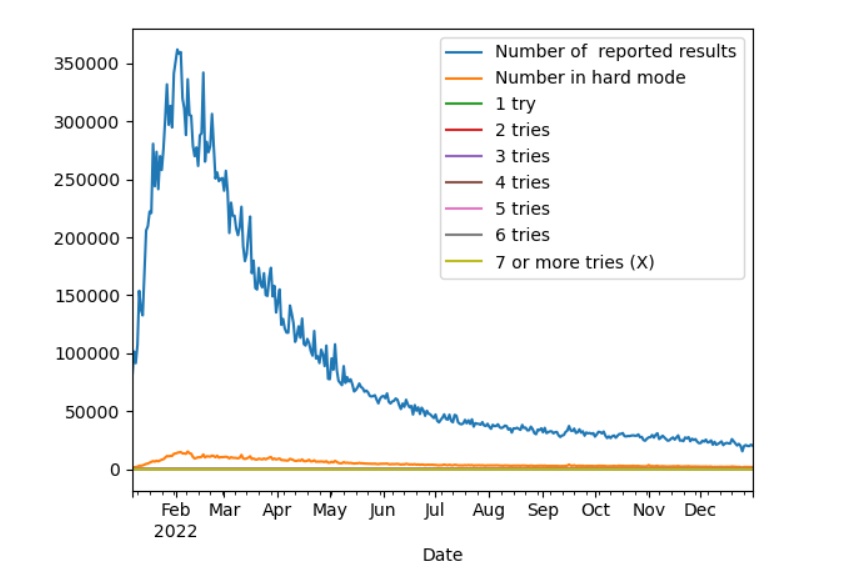
第二问叫我们预测3月1日各猜测次数的百分比,是一个多输入多输出问题。所以第二问的压力落在了我的头上,这一问可以采用神经网络,但是容易过拟合,所以有了基于遗传算法的神经网络,再次大受震撼,一方面神经网络太难了,我的能力不足以驾驭它,另一方面是神经网络不是不建议在美赛中用吗,这次它竟然能如此大放异彩。我赶紧打开B站搜索视频,争取学会它,看半小时后我就跟它说再见了,这不是我能触碰的领域。只好再次另辟蹊径,先是发现了多变量的时间序列也能解决问题,但是不会,然后是多预测回归树,但是不会,这些对我来说真的都太难了。实在是没办法了,只能用最小二乘法强行解决问题。
第三问是叫我们建立一个模型,对单词进行分类。一开始我是想从自然语言处理方面入手的,奈何实力不够,于是去网上找别的方法,希望绕过处理单词这个棘手的问题。看了几篇思路分析,我觉得可以用Kmeans先聚类,然后用随机森林测试准确度,嗯,效果很好,好的有点出奇,其中必定有什么蹊跷,但是我发现不了,论文只能这样写了,再难的我也不会。
感想
这四天的比赛是真的学到了不少东西,论文写作、排榜,流程图,各种让人感到学识不足的算法,还有各种各样的工具,比如SPASS、Matlab、SAS,发表一篇好的论文需要全方面发展,我以前觉得学完一本数就能无往不胜了,这个想法还是太天真了。我从比赛中接触到了一个新的世界,优秀的人实在是太优秀了,算法竟然还能涉及这么多的方面,掌握了几个机器学习算法的我原理连入门都没有。在最后一天的时候,看到一个用信息论求出最优开局解,又是一次惊叹,还能用这种方法。不管怎么样,第一次以这样的方式开始我还是十分满意了。

