
- 1数据结构有什么用?C语言为例_数据结构c语言版有什么用
- 2elasticsearch安装和使用ik分词器,分享Java资深架构师的成长之路_es安装ik分词器
- 3理解维度数据仓库——事实表、维度表、聚合表_什么是贴源表、维度表、事实表、汇总表
- 4Offset Explorer
- 5python音频处理_rawaudio python
- 6今日头条-实战爬虫_node爬取头条文章
- 7怎么把模糊图片变清晰?用这几个方法就够了_如何使网图变清晰
- 8【Python】【Opencv】形态学操作cv2.morphologyEx()函数详解和示例,实现腐蚀、膨胀、闭和开等运算
- 9自动化构建工具~Maven_make ant maven
- 10云计算-基础篇-vim—终端中的编辑器_云 怎样看vimconnectionid
基于Python编写的朴素贝叶斯在Mnist数据集上实现手写数字识别_使用贝叶斯模型对手写数字数据集进行数据挖掘实践
赞
踩
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
一项目简介
一、项目背景与意义
手写数字识别是计算机视觉领域的一个经典问题,旨在将手写数字图像转化为可编辑的数字形式。MNIST数据集是一个广泛使用的手写数字图像数据集,包含了大量的手写数字样本,常被用于评估各种图像识别算法的性能。朴素贝叶斯分类器是一种基于贝叶斯定理和特征条件独立假设的分类方法,虽然在手写数字识别等复杂问题上可能不如深度学习方法效果好,但其简单性和可解释性使得它仍然具有一定的研究价值。
二、数据集介绍
MNIST数据集是一个包含70,000个手写数字图像的数据集,其中60,000个样本用于训练,10,000个样本用于测试。每个样本都是一个28x28像素的灰度图像,表示一个0-9之间的手写数字。
三、技术实现
数据预处理:
读取MNIST数据集,将图像数据转换为适合朴素贝叶斯分类器处理的格式。
由于朴素贝叶斯分类器通常处理离散特征,因此需要将像素值从0-255的连续值转换为离散值(如二值化)。
将图像数据展平为一维特征向量,以便朴素贝叶斯分类器进行处理。
特征提取:
由于MNIST数据集的图像是28x28像素的灰度图像,因此可以直接将像素值作为特征。
在某些情况下,也可以考虑使用更复杂的特征提取方法,如PCA(主成分分析)或LDA(线性判别分析),但考虑到朴素贝叶斯分类器的简单性,这里直接使用像素值作为特征。
朴素贝叶斯分类器训练:
使用Python的机器学习库(如scikit-learn)中的朴素贝叶斯分类器实现。
将预处理后的训练数据输入到朴素贝叶斯分类器中进行训练,得到模型参数。
预测与评估:
使用训练好的朴素贝叶斯分类器对测试集进行预测。
计算预测结果的准确率、精确率、召回率等指标,以评估分类器的性能。
四、项目特点与难点
项目特点:
使用了广泛使用的MNIST数据集进行手写数字识别。
采用了基于朴素贝叶斯分类器的实现方式,简单且易于理解。
通过对比实验结果,可以了解朴素贝叶斯分类器在手写数字识别任务上的性能表现。
项目难点:
朴素贝叶斯分类器假设特征之间是相互独立的,这在手写数字识别等实际问题中往往不成立,可能导致分类性能受限。
由于MNIST数据集的图像是灰度图像,且像素值范围较大(0-255),需要进行适当的预处理和特征提取才能适应朴素贝叶斯分类器的输入要求。
与深度学习方法相比,朴素贝叶斯分类器在复杂任务上的性能可能不够理想,但通过对比实验可以了解其在实际应用中的局限性。
二、功能
基于Python编写的朴素贝叶斯在Mnist数据集上实现手写数字识别
三、系统
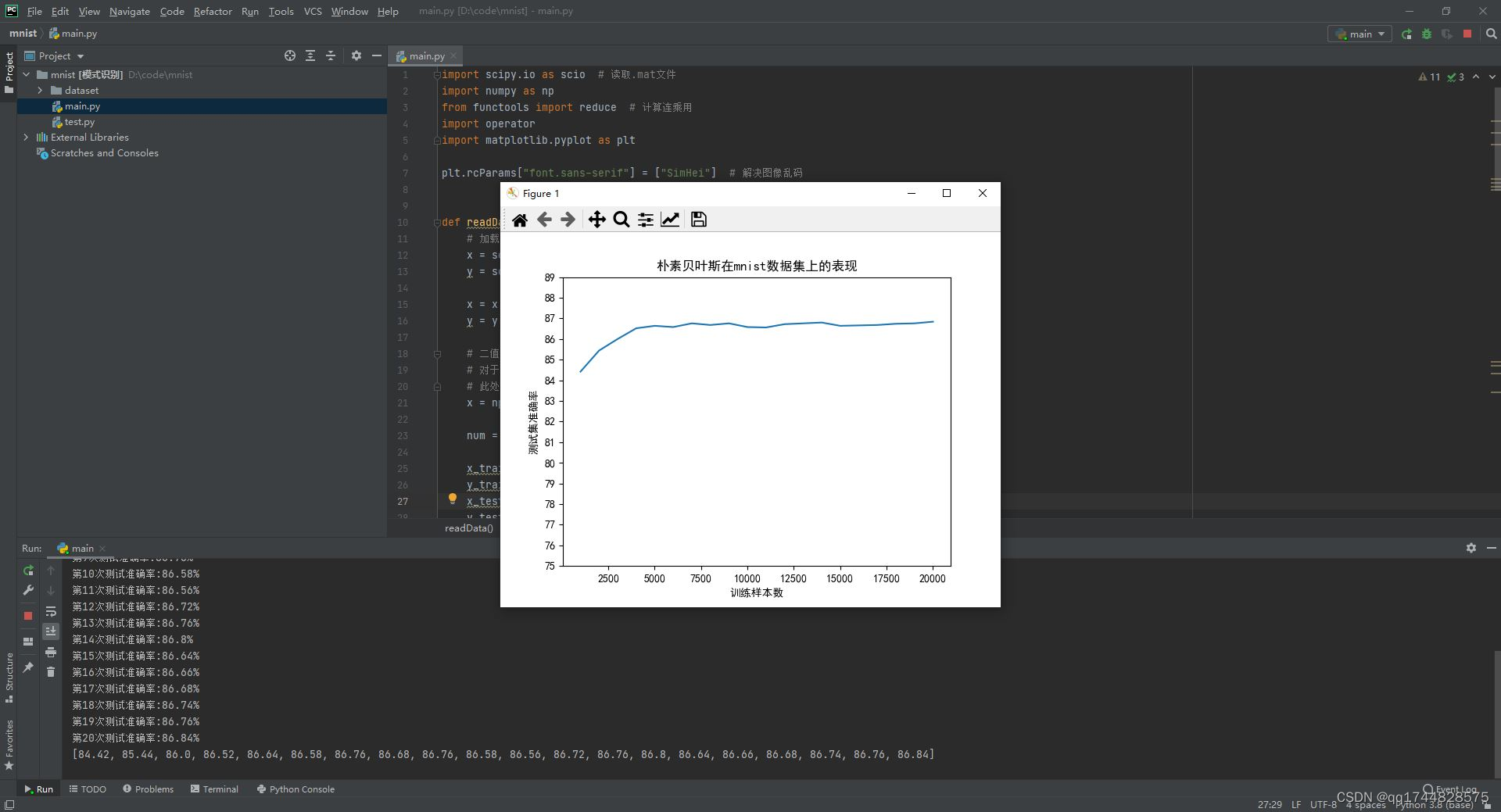
四. 总结
本项目通过使用Python和scikit-learn库实现了基于朴素贝叶斯分类器的手写数字识别系统,并在MNIST数据集上进行了实验验证。通过实验结果可以了解朴素贝叶斯分类器在手写数字识别任务上的性能表现,并与其他方法进行比较。虽然朴素贝叶斯分类器在某些复杂任务上可能不如深度学习方法效果好,但其简单性和可解释性使得它仍然具有一定的研究价值。未来可以考虑使用更复杂的特征提取方法和分类器来提高手写数字识别的准确率,并探索朴素贝叶斯分类器在其他领域的应用。

