
- 1机器学习系列(7):目标检测YOLO算法及Python实现以自动驾驶为例_yolo人脸检测python
- 2ReactNative实现弧形拖动条
- 3蓝桥杯倒计时 | 倒计时7天_piggqf
- 4java---查找算法(二分查找,插值查找,斐波那契[黄金分割查找] )-----详解 (ᕑᗢᓫ∗)˒
- 5数字反转(C++)
- 6Tomcat之Web项目部署_tomcat部署web项目
- 7「Java基础入门」Java中switch怎么使用枚举_java switch 枚举
- 8adb push/adb pull指令_adbpull指令
- 9微博数据采集,微博爬虫,微博网页解析,完整代码(主体内容+评论内容)_微博数据爬虫
- 10更改bios 卡在欢迎界面_lenovo yoga 710—14ikb 如何开启BIOS设置
Transformer网络
赞
踩
Transformer网络可以利用数据之间的相关性,最近需要用到这一网络,在此做一些记录。
1、Transformer网络概述
Transformer网络最初被设计出来是为了自然语言处理、语言翻译任务,这里解释的也主要基于这一任务展开。
在 Transformer 出现之前,递归神经网络(RNN)是自然语言处理的首选解决方案。当提供一个单词序列时,递归神经网络(RNN)将处理第一个单词,并将结果反馈到处理下一个单词的层。这使它能够跟踪整个句子,而不是单独处理每个单词。但是这种方法只能顺序的处理单词,同时对于长序列的文本无法有效处理,当两个单词距离过远时会出现梯度消失的问题。
Transformer使并行处理整个序列成为可能,从而可以将顺序深度学习模型的速度和容量扩展到前所未有的速度。其次引入了“注意机制”,可以在正向和反向的非常长的文本序列中跟踪单词之间的关系。
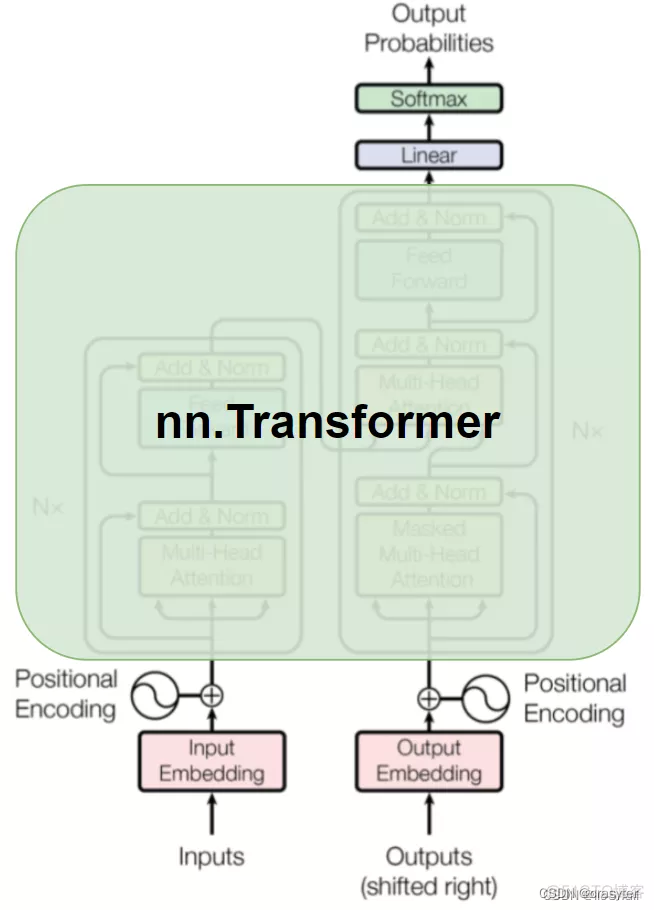
Transformer 架构是以encoder/decoder架构为基础,整体结构如下图所示,在Encoder和Decoder中都使用了Self-attention, Point-wise和全连接层。Encoder和decoder的大致结构分别如下图的左半部分和右半部分所示。
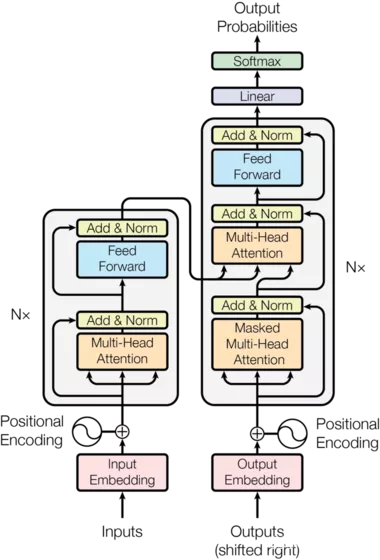
1.1 编码器
编码组件部分由N个编码器(encoder)构成,每个编码器的结构均相同(但它们不共享权重),每层有两个子层:自注意力层(self-attention) 和 全连接的前馈网络层(feed-forward)。
从编码器输入的句子首先会经过一个自注意力层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。自注意力层的输出会传递到前馈神经网络中。每个位置的单词对应的前馈神经网络都完全一样(另一种解读就是一层窗口为一个单词的一维卷积神经网络)。
每两个子层中外都套了一个残差连接(residual connections),然后是层归一化(layer normalization)。为了实现残差(输入x与输出可以直接相加),模型中的所有子层以及嵌入层都会产生维度512的输出。
1.2 解码器
解码组件也由N个相同的解码器堆叠而成,也有自注意力(self-attention)层和前馈(feed-forward)层。除此之外,这两个层之间还有一个注意力层,用来关注输入句子的相关部分(和seq2seq模型的注意力作用相似)。
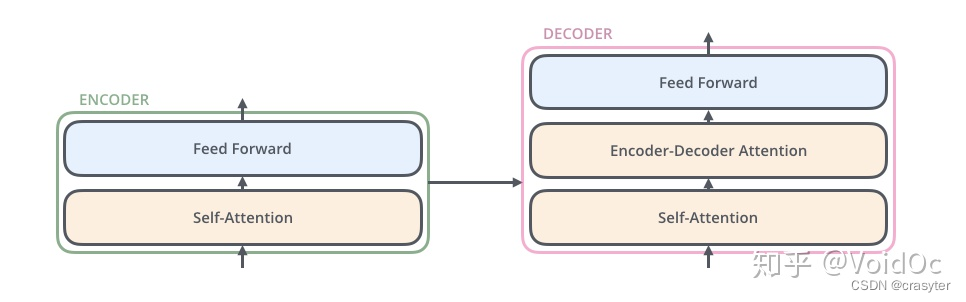
修改解码器中的Self-attention子层以防止当前位置Attend到后续位置。这种Masked的Attention是考虑到输出Embedding会偏移一个位置,确保了生成位置i的预测时,仅依赖小于i的位置处的已知输出,相当于把后面不该看到的信息屏蔽掉。
2、transformer推理训练
transformer的输入包含两部分:
inputs: 原句子对应的tokens,且是完整句子。一般0表示句子开始(),1表示句子结束(),2为填充()。填充的目的是为了让不同长度的句子变为同一个长度,这样才可以组成一个batch。在代码中,该变量一般取名src。
outputs:(shifted right) 上一个阶段的输出。虽然名字叫outputs,但是它是输入。最开始为0(),然后本次预测出“我”后,下次调用Transformer的该输入就变成 我。在代码中,该变量一般取名tgt。Transformer的输出是一个概率分布。
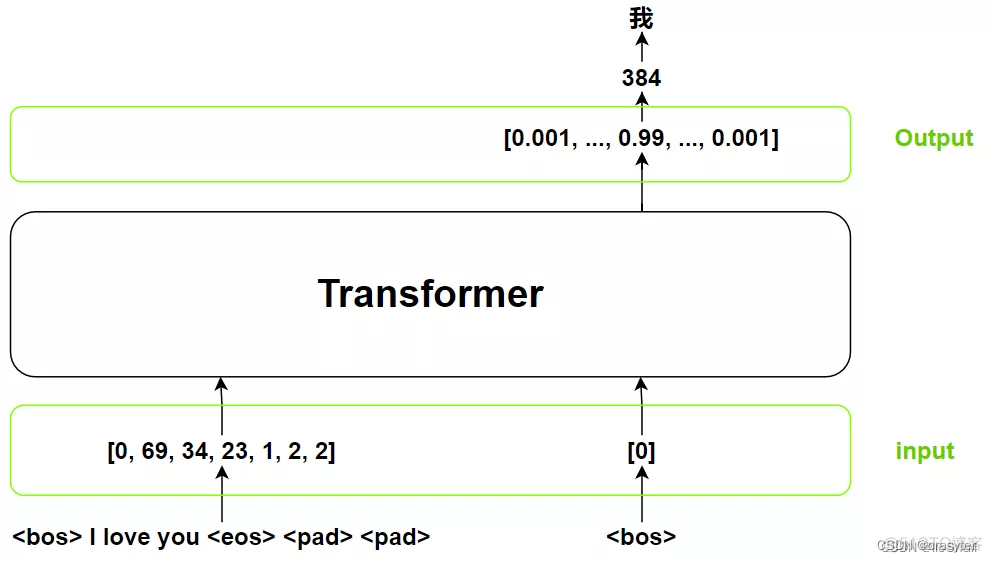
后续逐步进行推理:
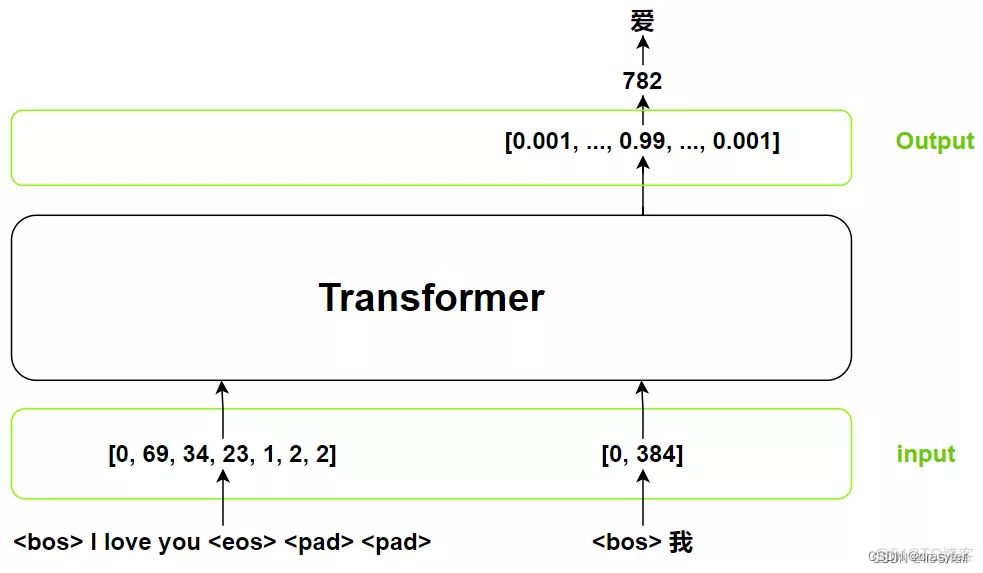
在Transformer推理时,我们是一个词一个词的输出,但在训练时这样做效率太低了,所以我们会将target一次性给到Transformer(当然,你也可以按照推理过程做),如图所示:

Transformer的训练过程和推理过程主要有以下几点异同:
源输入src相同:对于Transformer的inputs部分(src参数)一样,都是要被翻译的句子。
目标输入tgt不同:在Transformer推理时,tgt是从开始,然后每次加入上一次的输出(第二次输入为 我)。但在训练时是一次将“完整”的结果给到Transformer,这样其实和一个一个给结果上一致(可参考 该篇的Mask Attention部分)。这里还有一个细节,就是tgt比src少了一位,src是7个token,而tgt是6个token。这是因为我们在最后一次推理时,只会传入前n-1个token。举个例子:假设我们要预测 我 爱 你 (这里忽略pad),我们最后一次的输入tgt是 我 爱 你(没有),因此我们的输入tgt一定不会出现目标的最后一个token,所以一般tgt处理时会将目标句子删掉最后一个token。
输出数量变多:在训练时,transformer会一次输出多个概率分布。例如上图,我就的等价于是tgt为时的输出,爱就等价于tgt为 我时的输出,依次类推。当然在训练时,得到输出概率分布后就可以计算loss了,并不需要将概率分布再转成对应的文字。注意这里也有个细节,我们的输出数量是6,对应到token就是我 爱 你 ,这里少的是,因为不需要预测。计算loss时,我们也是要和的这几个token进行计算,所以我们的label不包含。代码中通常命名为tgt_y
3、nn.transformer函数
pytorch提供了对应的transformer函数 nn.Transformer:
CLASS torch.nn.Transformer(d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1, activation=<function relu>,
custom_encoder=None, custom_decoder=None, layer_norm_eps=1e-05, batch_first=False,
norm_first=False, device=None, dtype=None)
- 1
- 2
- 3
- 4
对应的输入参数:
- d_model (int) – the number of expected features in the encoder/decoder inputs (default=512).Encoder和Decoder输入参数的特征维度。也就是词向量的维度。默认为512
- nhead (int) – the number of heads in the multiheadattention models (default=8).多头注意力机制中,head的数量。该值并不影响网络的深度和参数数量。默认值为8
- num_encoder_layers (int) – the number of sub-encoder-layers in the encoder (default=6). TransformerEncoderLayer的数量。该值越大,网络越深,网络参数量越多,计算量越大。默认值为6
- num_decoder_layers (int) – the number of sub-decoder-layers in the decoder (default=6). TransformerDecoderLayer的数量。该值越大,网络越深,网络参数量越多,计算量越大。默认值为6
- dim_feedforward (int) – the dimension of the feedforward network model (default=2048). Feed Forward层(Attention后面的全连接网络)的隐藏层的神经元数量。该值越大,网络参数量越多,计算量越大。默认值为2048
- dropout (float) – the dropout value (default=0.1).
- activation (Union[str, Callable[[Tensor], Tensor]]) – the activation function of encoder/decoder intermediate layer, can be a string (“relu” or “gelu”) or a unary callable. Default: relu. Feed Forward层的激活函数。取值可以是string(“relu” or “gelu”)或者一个一元可调用的函数。默认值是relu
- custom_encoder (Optional[Any]) – custom encoder (default=None).自定义Encoder。若不想用官方实现的TransformerEncoder,可以自己实现一个。默认值为None
- custom_decoder (Optional[Any]) – custom decoder (default=None). 自定义Decoder。若不想用官方实现的TransformerDecoder,可以自己实现一个。
- layer_norm_eps (float) – the eps value in layer normalization components (default=1e-5). Add&Norm层中,BatchNorm的eps参数值。默认为1e-5
- batch_first (bool) – If True, then the input and output tensors are provided as (batch, seq, feature). Default: False (seq, batch, feature) .batch维度是否是第一个。如果为True,则输入的shape应为(batch_size, 词数,词向量维度),否则应为(词数, batch_size, 词向量维度)。默认为False。这个要特别注意,因为大部分人的习惯都是将batch_size放在最前面,而这个参数的默认值又是False,所以会报错。
- norm_first (bool) – if True, encoder and decoder layers will perform LayerNorms before other attention and feedforward operations, otherwise after. Default: False (after). 是否要先执行norm。例如,在图中的执行顺序为Attention -> Add -> Norm。若该值为True,则执行顺序变为:Norm -> Attention -> Add。
[注意]:nn.Transformer并没有包含Transformer的所有结构,需要自己实现position embedding等结构
target sequence代表多头attention当中q(查询)的序列,source sequence代表k(键值)和v(值)的序列。例如,当decoder在做self-attention的时候,target sequence和source sequence都是它本身,所以此时L=S,都是decoder编码的序列长度。
在训练时,可以直接输入所有目标句子,通过mask确保本质上是一个个输入。而在测试过程中,只能一个单词一个单词的进行输出,是串行进行的。
4、其他transformer实现
4.1 convtransformer
将向量tensor计算转换为卷积操作,但是目前只有非官方的实现,存在一些bug需要自行修改:github

