
- 1多CPU/多核/多进程/多线程/并发/并行之间的关系_多核cpu是多进程吗
- 206_第六章 会话_过滤器_监听器
- 3基于PyQt5&YOLOv4-tiny的目标检测系统
- 4将数据源转换成IQueryable_list
转换成isugarqueryable - 5react antd protable内的Input输入框每次输入失去焦点_tabs input 输入字符后焦点自动没了
- 6自然智能,人工智能,机器学习和深度学习的定义和解释_自然智能与人脑智能
- 7基于springboot的仓库管理系统
- 8靶场日记-存储型xss漏洞利用_存储xss利用平台
- 9基于springboot java开发的停车场管理系统_xz202025-一套基于springboot thymeleaf的易泊车停车管理系统
- 10解决RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cp
深度强化学习——概念及算法总结
赞
踩
深度强化学习
深度强化学习相关大佬帖子总结学习,附原链接
深度强化学习——从DQN到DDPG
强化学习

智能体在完成某项任务时,如上图所示,首先通过动作A与周围环境进行交互,在动作A和环境的作用下,智能体会产生新的状态,同时环境会给出一个立即回报。如此循环下去,智能体与环境进行不断地交互从而产生很多数据。强化学习算法利用产生的数据修改自身的动作策略,再与环境交互,产生新的数据,并利用新的数据进一步改善自身的行为,经过数次迭代学习后,智能体能最终地学到完成相应任务的最优动作(最优策略)。这就是一个强化学习的过程。
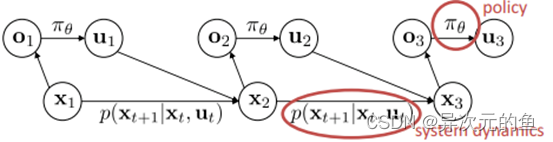
强化学习所面对的是一个连续决策过程。这一问题框架基于一个MDP过程,即马尔科夫决策过程,如上图所示。智能体面对的环境有一个状态空间X,智能体自己有一个动作空间U,智能体根据状态的观察值O来进行决策。**环境动态模型(system dynamics)**或者说转移概率描述了状态间是如何转化的,**策略(policy)**描述了智能体如何决策。
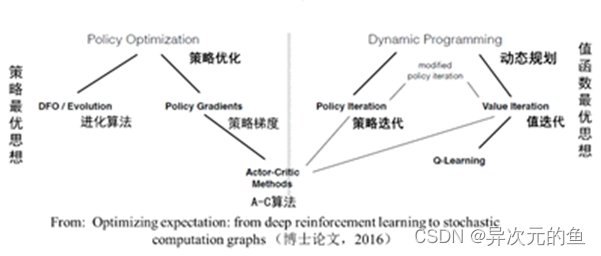
如上图所示,强化学习根据以策略为中心还是以值函数最优可以分为两大类,策略优化方法和动态规划方法。其中策略优化方法又分为进化算法和策略梯度方法;动态规划方法分为策略迭代算法和值迭代算法。策略迭代算法和值迭代算法可以用广义策略迭代方法进行统一描述。另外,强化学习算法根据策略是否是随机的,分为确定性策略强化学习和随机性策略强化学习。根据转移概率是否已知可以分为基于模型的强化学习和无模型的强化学习算法。另外,强化学习算法中的回报函数r十分关键,根据回报函数是否已知,可以分为强化学习和逆向强化学习。逆向强化学习是根据专家演示将回报函数学习出来。

策略梯度
策略梯度方法中,将策略参数化表示为,计算出关于动作的策略函数梯度,不断调整动作,靠近最优策略。策略梯度的计算公式已由相关学者推导得到,且有两种策略梯度,一是随机性策略梯度,二是确定性策略梯度。
1、随机性策略梯度:
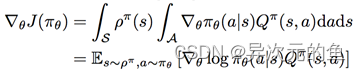
2、确定性策略梯度:
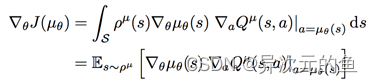
策略梯度的直观理解是调整策略函数的参数,使得其给出的动作可以获得较大的Q值。
Actor-Critic方法是一种很重要的强化学习算法,其是一种时序差分方法(TD method),结合了基于值函数的方法和基于策略函数的方法。其中策略函数为行动者(Actor),给出动作;价值函数为评价者(Critic),评价行动者给出动作的好坏,并产生时序差分信号,来指导价值函数和策略函数的更新。其框架如下图:
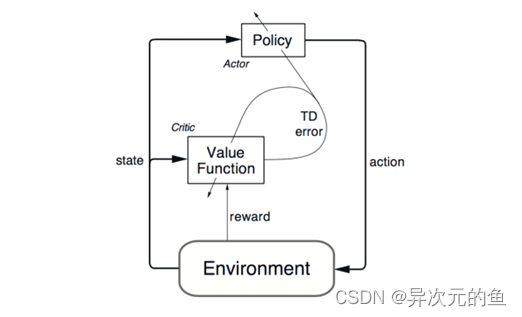
将此方法与深度学习结合的话,则是分别用两个深度网络去代表价值函数和策略函数。之后所介绍的DDPG就是基于这样一种Actor-Critic架构的深度强化学习方法。
Q-Learning
Q-Learning算法是强化学习的主要算法之一,它提供了智能体在马尔可夫环境中利用经历的动作序列选择最优动作的一种学习能力,将智能体与环境的交互过程看成一个马尔可夫决策过程(MDP),根据智能体当前所处的状态和所选择的动作,决定一个固定的状态转移概率分布、下一个状态并得到一个及时回报。目标就是找到一个策略可以最大化将来获得的报酬。
先来看Q-Learning的算法流程图:
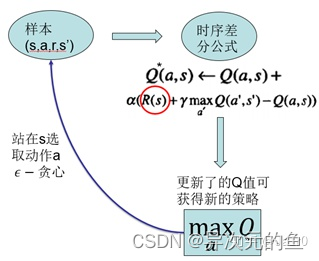
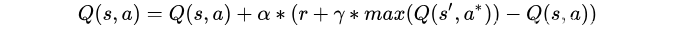
假设用r+γQ(s′,a∗)表示现实的回报值,Q(s,a)表示估计的回报值,则模型更新方法:新的回报 = (1- α)估计回报 + α * 现实回报。 α表示学习率,从公式中可以看出,学习率越低,机器人越在乎之前的回报,而不能积累新的回报。

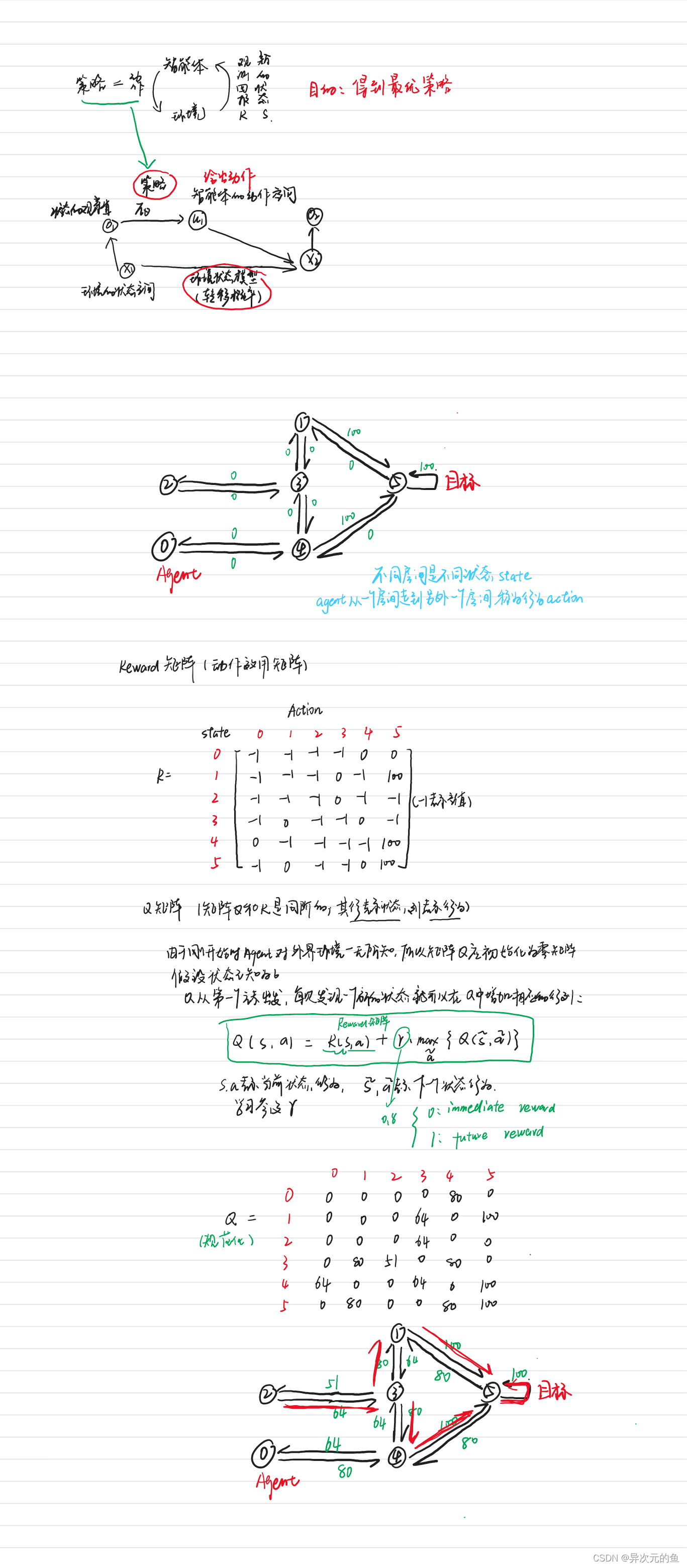
强化学习中的一个经典算法——Q Learning。首先了解一下强化学习包括什么?——状态(state)、奖励(Reward)、行为(Action)。Q-learning的目标是达到reward值最大的state。
因为在Q-Learning算法中加入一个叫做Q表的东西,Q-Learning因此命名。Q表包括一定行为下,所基于的反馈。
Q为动作效用函数(action-utility function),用于评价在特定状态下采取某个动作的优劣。它是Agent(智能体)的记忆。(行是状态,列是行为)

DQN
用一个深度网络代表价值函数,依据强化学习中的Q-Leaning,为深度网络提供目标值,对网络不断更新直至收敛。
DQN用到了两个关键技术,一是用来打破样本间关联性的样本池,二是使训练稳定性和收敛性更好的固定目标网络
DQN可以应对高维输入,但是对高维动作输出则束手无策 。
DQN是深度学习和强化学习的第一次成功结合。想要将深度学习融合进清华学习,有一些关键问题需要解决:
-
深度学习需要大量有标签的数据样本,而强化学习是智能体主动获取样本,样本稀疏且有延迟
-
深度学习要求每个样本相互之间是独立同分布的;强化学习获取的相邻样本相互互联,并不是相互独立的
若想将这两者结合,必须解决包括上面两点在内的问题。
DQN具体来说,是基于经典强化学习算法Q-Learning,用深度神经网络拟合其中的Q值的一种方法。Q-Learning算法提供给深度网络目标值,使其进行更新。
智能体采用off-policy即执行的和改进的不是同一个策略,这通过方法实现。用这种方式采样,并以在线更新的方式,每采集一个样本进行一次对Q函数的更新。更新所依据的是时序差分公式。以更新后的Q函数得到新的策略。而这种经典强化学习算法的局限性在于,无法应对高维的输入,且无法应用于大的动作空间,特别的,无法应用于连续动作输出。DQN所做的是用一个深度神经网络进行端到端的拟合,发挥深度网络对高维数据输入的处理能力。其2013年版本结构如下:
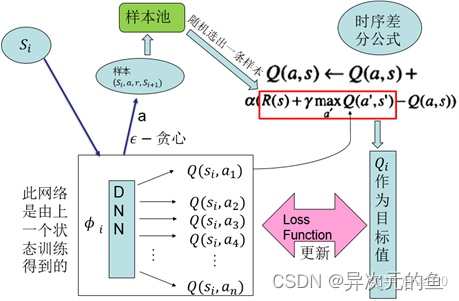
2015年的改进版本:
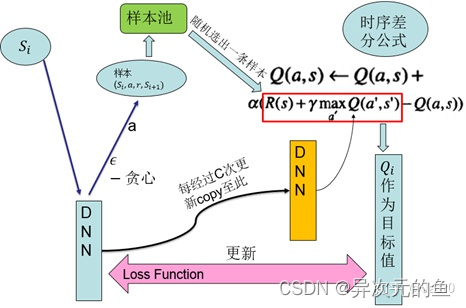
其有两个关键技术:
1、样本池(experience reply):将采集到的样本先放入样本池,然后从样本池中随机选出一条样本用于对网络的训练。这种处理打破了样本间的关联,使样本间相互独立。
2、固定目标值网络(fixed Q-target):计算网络目标值需用到现有的Q值,现用一个更新较慢的网络专门提供此Q值。这提高了训练的稳定性和收敛性。
Actor-Critic结构
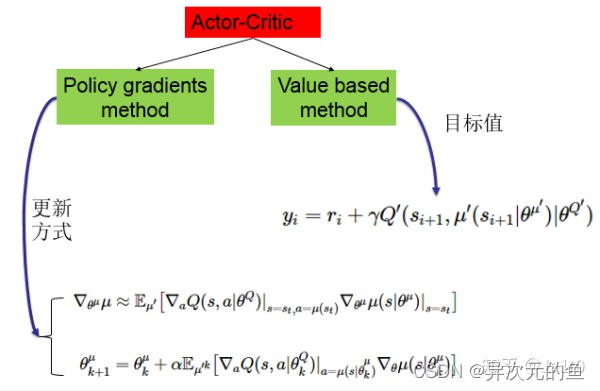
该结构包含两个网络,一个策略网络(Actor),一个价值网络(Critic)。策略网络输出动作,价值网络评判动作。两者都有自己的更新信息。策略网络通过梯度计算公式进行更新,而价值网络根据目标值进行更新。
DDPG
可以解决有着高维或连续动作空间的情境。他包含一个策略网络用来生成动作,一个价值网络用来评判动作的好坏,并吸取DQN的成功经验,同样使用了样本池和固定目标网络,是一种结合了深度网络的Actor-Critic方法
DQN是一种基于值函数的方法,基于值函数的方法难以应对的是大的动作空间,特别是连续动作情况。因为网络难以有这么多输出,且难以在这么多输出之中搜索最大的Q值。而DDPG是基于上面所讲到的Actor-Critic方法,在动作输出方面采用一个网络来拟合策略函数,直接输出动作,可以应对连续动作的输出及大的动作空间。
DDPG采用了DQN的成功经验。即采用了样本池和固定目标值网络这两项技术。也就是说这两个网络分别有一个变化较慢的副本,该变化较慢的网络提供给更新信息中需要的一些值。DDPG的整体结构如下:

DDPG方法是深度学习和强化学习的又一次成功结合,是深度强化学习发展过程中很重要的一个研究成果。其可以应对高维的输入,实现端对端的控制,且可以输出连续动作,使得深度强化学习方法可以应用于较为复杂的有大的动作空间和连续动作空间的情境
一篇文章带你了解深度神经网络
深度神经网络

【理论篇】怎样直观理解Qlearning算法
蒙地卡罗MC公式
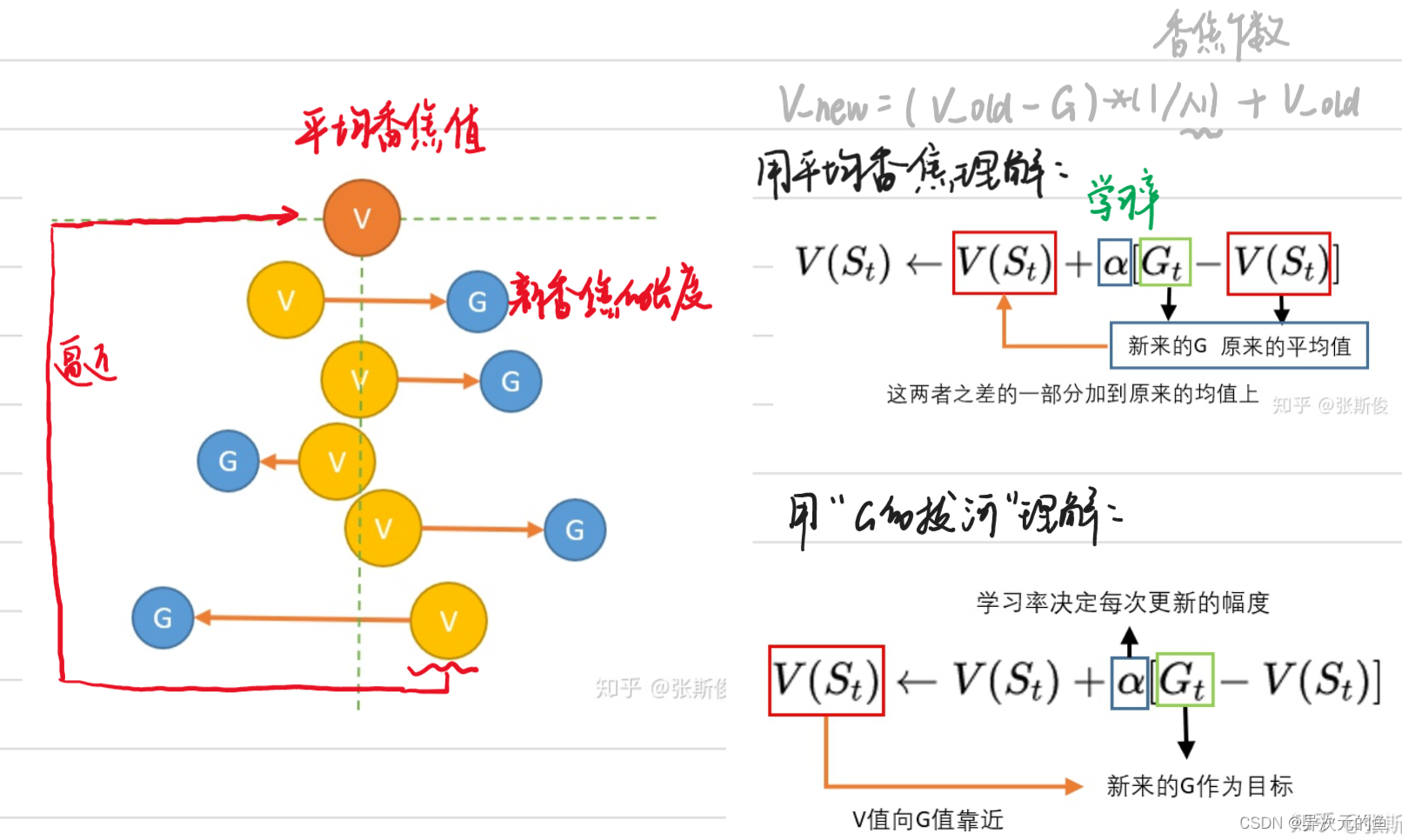
时序差分(TD)
Qleaining
三维可视化助你直观理解DQN算法【DQN理论篇】
Deep network + Qlearning = DQN
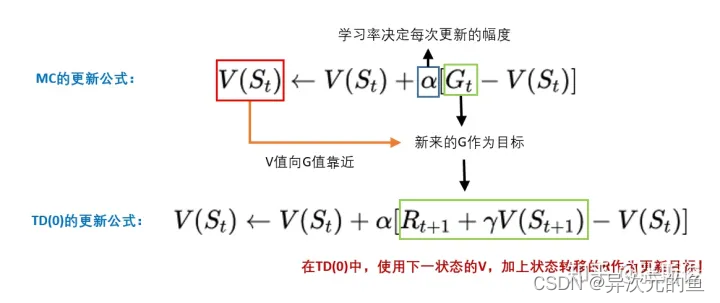
Qlearning中,我们有一个Qtable (评估动作的价值),记录着在每一个状态下,各个动作的Q值。
Qtable的作用是当我们输入状态S,我们通过查表返回能够获得最大Q值的动作A。也就是我们需要找一个S-A的对应关系。
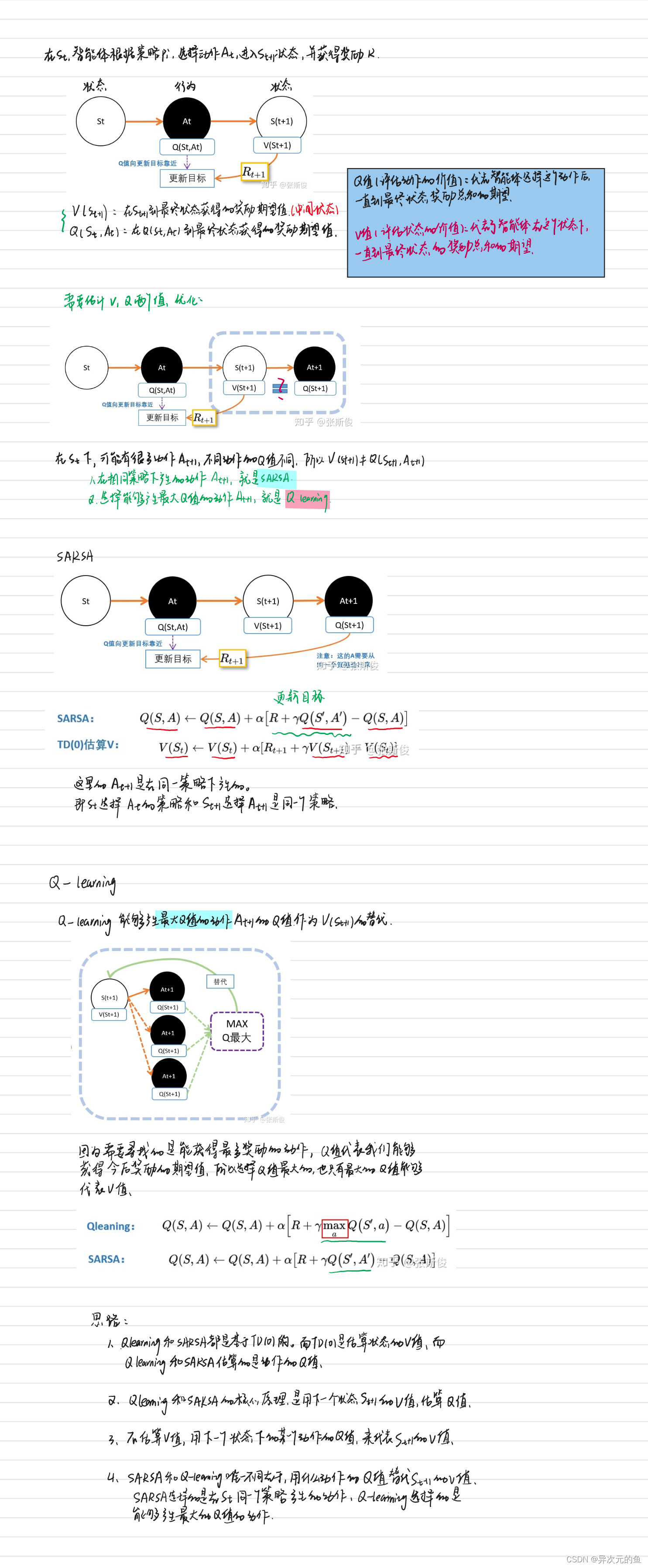
这种方式很适合格子游戏。因为格子游戏中的每一个格子就是一个状态,但在现实生活中,很多状态并不是离散而是连续的。
Qtable的作用就是找一个S-A的对应关系。所以我们就可以用一个函数F表示,我们有F(S) = A。这样我们就可以不用查表了,而且还有个好处,函数允许连续状态的表示。
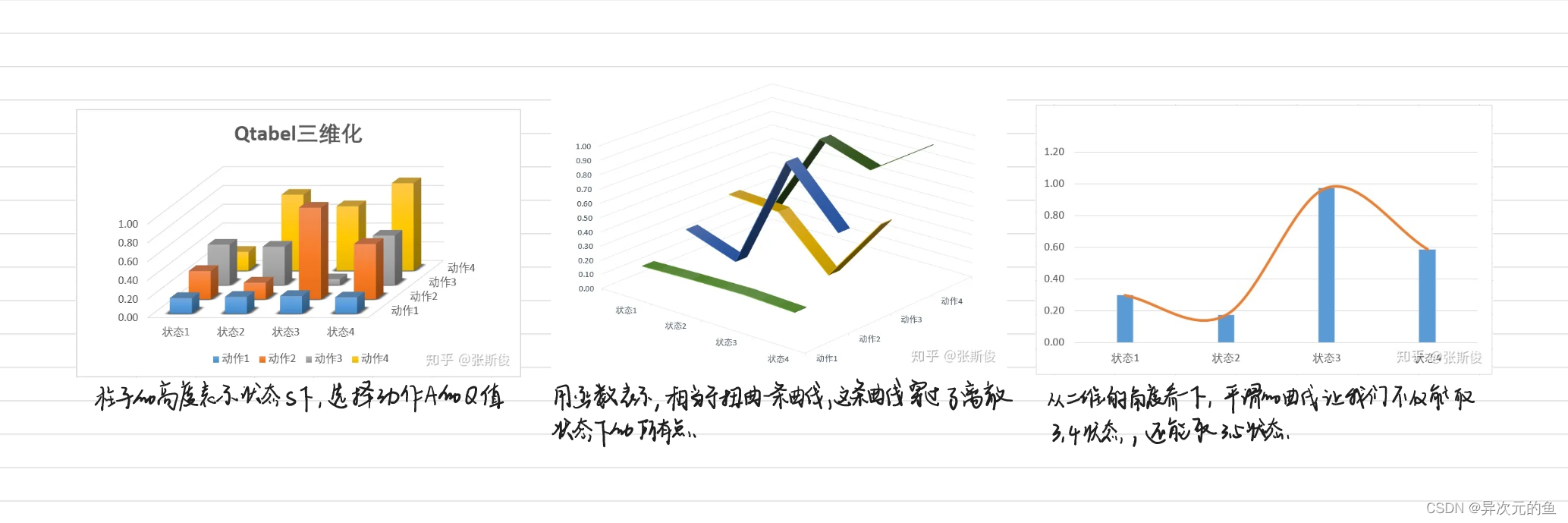
Qlearning和DQN没有根本区别。知识DQN用神经网络,也就是一个函数代替了原来的Qtable。
神经网络的目标
神经网络需要解决一个问题,就是更新目标怎么设置。
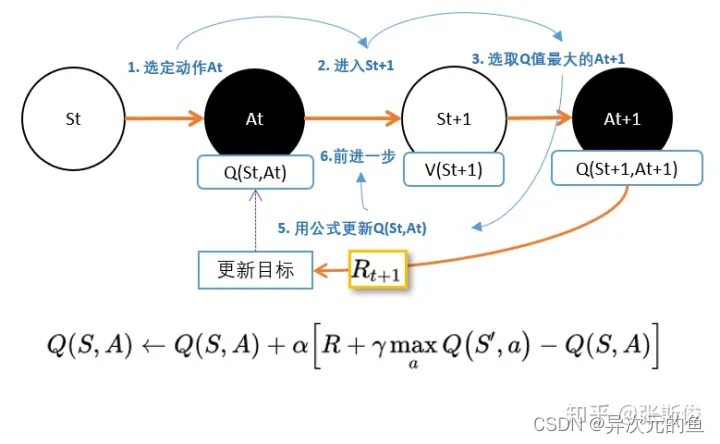
就在Qlearning一样。 还记得吗?在Qlearning,我们用下一状态St+1的最大Q值替代St+1的V值。V(St+1)加上状态转移产生的奖励R。就是Q(S,a)的更新目标。
假设我们需要更新当前状态St下的某动作A的Q值:Q(S,A),我们可以这样做:
- 执行A,往前一步,到达St+1;
- 把St+1输入Q网络,计算St+1下所有动作的Q值;
- 获得最大的Q值加上奖励R作为更新目标;
- 计算损失
- Q(S,A)相当于有监督学习中的logits
- maxQ(St+1) + R 相当于有监督学习中的lables
- 用mse函数,得出两者的loss
- 用loss更新Q网络。
即,我们用Q网络估算出来的两个相邻状态的Q值,他们之间的距离,就是一个r的距离。
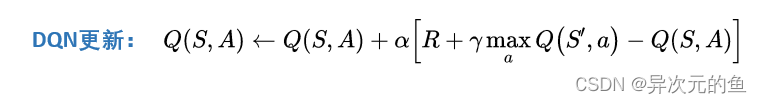
和Qlearning的公式一样
总结
- DQN就是Qlearning扔掉Qtable,换上深度神经网络。
- 解决连续性问题,如果表格不能表示,就用函数,最好的函数就是深度神经网络。
- DQN的深度网络,就像用一张布去覆盖Qlearning中的Qtable。这也是DDPG中Critic的功能。
- 和有监督学习不同,深度强化学习中,我们需要自己找更新目标。通常在马尔科夫链体系下,两个相邻状态差一个奖励r经常被利用。
一文带你理清DDPG算法(附代码及代码解释)
DDPG,全称deep deterministic policy gradient,深度确定性策略梯度算法
DDPG和DQN
DQN是更新动作的Q值
DQN不能用于连续控制问题,因为maxQ(s’,a’)函数只能处理离散型的。
DQN用magic函数,也就是神经网络解决了Qlearning不能解决的连续状态空间问题。
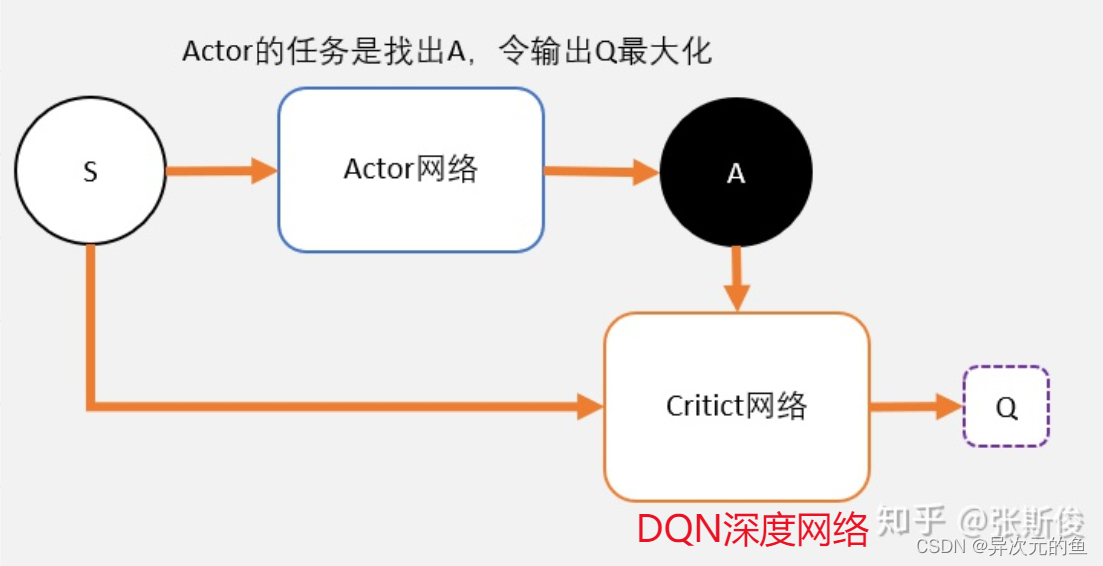
现在用一个magic函数,直接替代maxQ(s’,a’)的功能。也就是说,我们期待我们输入状态s,magic函数返回我们动作action的取值,这个取值能够让q值最大。这个就是DDPG中的Actor的功能。
DQN的深度网络,就像用一张布去覆盖Qlearning中的Qtable。这也是DDPG中Critic的功能。
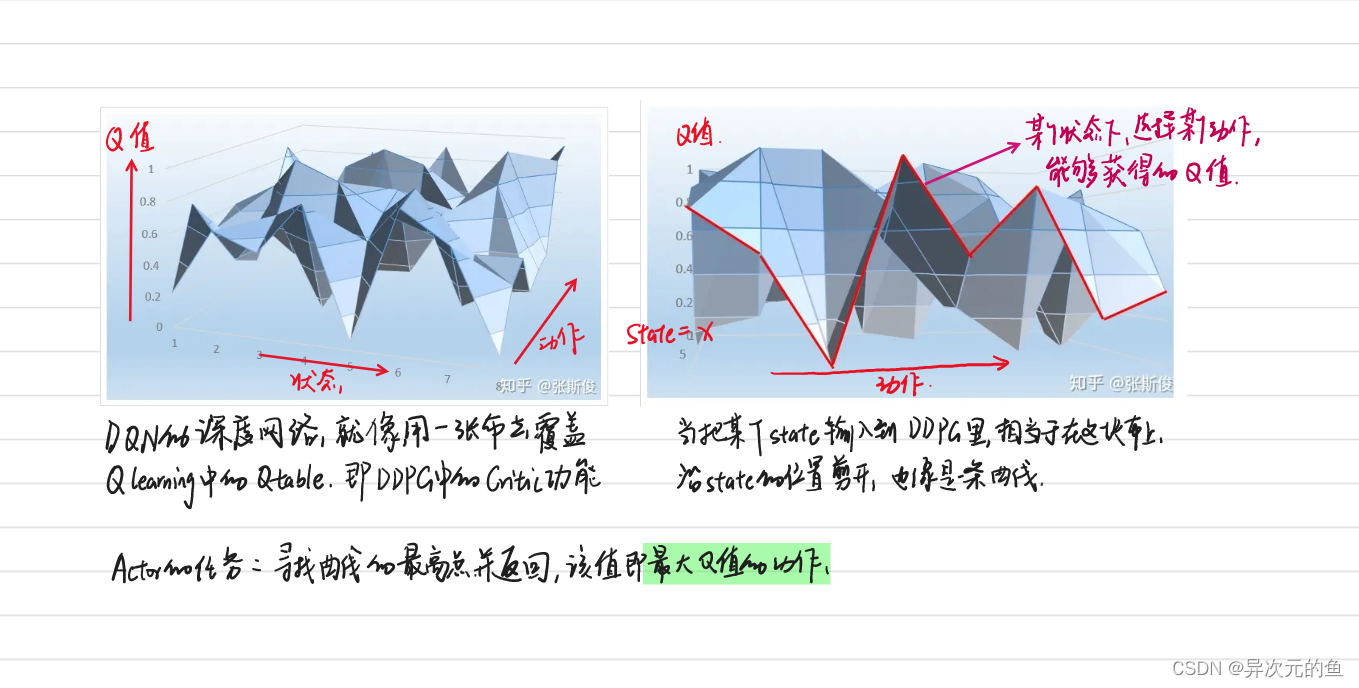
红色曲线,即在某个状态下,选择某个动作的时候,能够获得的Q值。
Actor的任务就是寻找曲线的最高点并返回,即最大Q值的动作
DDPG其实并不是PG,并没有做带权重的梯度更新。而是在梯度上升,寻找最大值。
DDPG算法
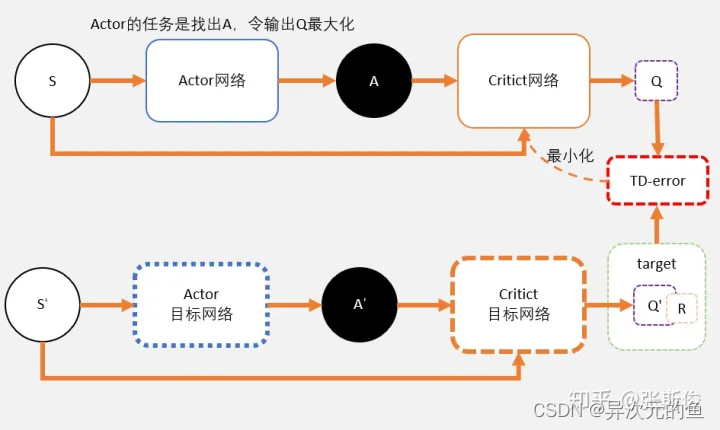
Critic
- Critic网络的作用是预估Q(评估动作的价值)
- 注意Critic的输入有两个:动作和状态,需要一起输入到Critic中;
- Critic网络的loss其还是和AC一样,用的是TD-error(时序差分)。
Actor
- Actor输出的是一个动作;
- Actor的功能是,输出一个动作A,这个动作A输入到Crititc后,能够获得最大的Q值。
- 所以Actor的更新方式和AC不同,不是用带权重梯度更新,而是用梯度上升。
和DQN一样,更新的时候如果更新目标在不断变动,会造成更新困难。所以DDPG和DQN一样,用了固定网络(fix network)技术,就是先冻结住用来求target的网络。在更新之后,再把参数赋值到target网络。
在实做的时候,我们需要4个网络。actor, critic, Actor_target, cirtic_target。
DDPG伪代码


DDPG:深度确定性策略梯度
DDPG组成
DDPG训练流程如下所示,类似于DQN,DDPG增加了策略网络(Actor)。DDPG包含两部分,一个策略网络(Actor),一个价值网络(Critic)。策略网络输出动作,价值网络评判动作。
两者都有自己的更新信息的方式。策略网络(actor)通过梯度计算公式进行更新,而价值网络(critic)根据目标值进行更新。DDPG价值网络的更新与DQN类似,这里详细说一下策略网络的更新。
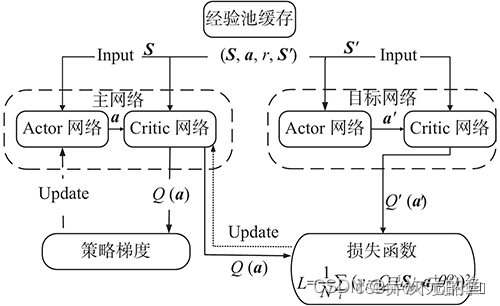
梯度更新策略
策略梯度公式:
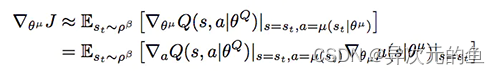
对同一个状态,我们输出了两个不同的动作a1和a2,从状态估计网络得到了两个反馈的Q值,分别是Q1和Q2,假设Q1>Q2,即采取动作a1可以得到更多的奖励。那么策略梯度的思想是什么呢?就是增加a1的概率,降低a2的概率,也就是说,Actor想要尽可能的得到更大的Q值。所以我们的Actor的损失可以简单的理解为得到的反馈Q值越大损失越小,得到的反馈Q值越小损失越大。
强化学习DQN、DDQN和Dueling DQN的原理介绍与PARL核心代码解析
强化学习DQN、DDQN和Dueling DQN的原理介绍与PARL核心代码解析
DQN
DQN的目标就是训练出一个优秀的神经网络,该神经网络的输入是s(当前所处状态state),输出的是n个Q值(n代表可选择的动作个数,输出的实际上是一个n维的向量)。这样智能体就能在每次做选择前,把当前所处状态输入神经网络后,根据神经网络的输出,选择输出中最大的Q值所对应的动作。然后智能体进入下一状态,把下一状态输入神经网络,根据神经网络的输出选择下一动作,…,如此不断循环往复,直到游戏结束。
DQN伪代码

DDQN
DDQN是Double DQN的缩写,是在DQN的基础上改进而来的。DDQN的模型结构基本和DQN的模型结构一模一样,唯一不同的就是它们的目标函数。
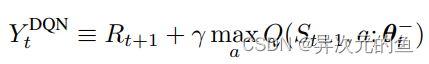
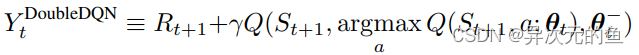
这两个target函数的区别在于DoubleDQN的最优动作选择是根据当前正在更新的Q网络的参数θt,而DQN中的最优动作选择是根据上一小节提到的target-Q网络的参数θt−。
这样做的原因是传统的DQN通常会高估Q值的大小(overestimation)。
而DDQN由于每次选择的根据是当前Q网络的参数,并不是像DQN那样根据target-Q的参数,所以当计算target值时是会比原来小一点的。(因为计算target值时要通过target-Q网络,在DQN中原本是根据target-Q的参数选择其中Q值最大的action,而现在用DDQN更换了选择以后计算出的Q值一定是小于或等于原来的Q值的)这样在一定程度上降低了overestimation,使得Q值更加接近真实值。
DDQN伪代码

Dueling DQN
Dueling DQN也是在DQN的基础上进行的改进。改动的地方是DQN神经网络的最后一层,原本的最后一层是一个全连接层,经过该层后输出n个Q值(n代表可选择的动作个数)。而Dueling DQN不直接训练得到这n个Q值,它通过训练得到的是两个间接的变量V(state value)和A(action advantage),然后通过它们的和来表示Q值。
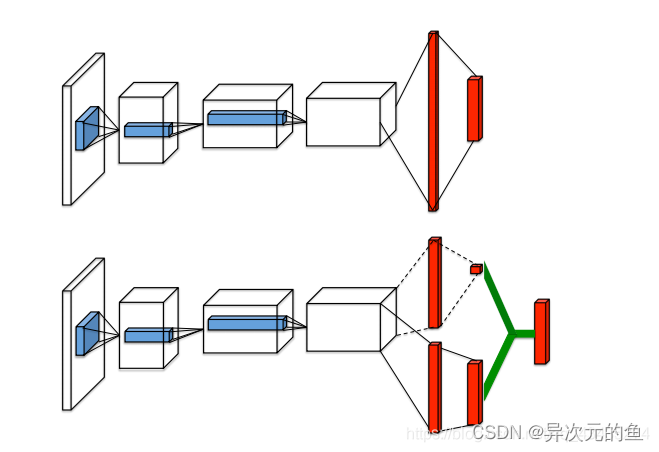
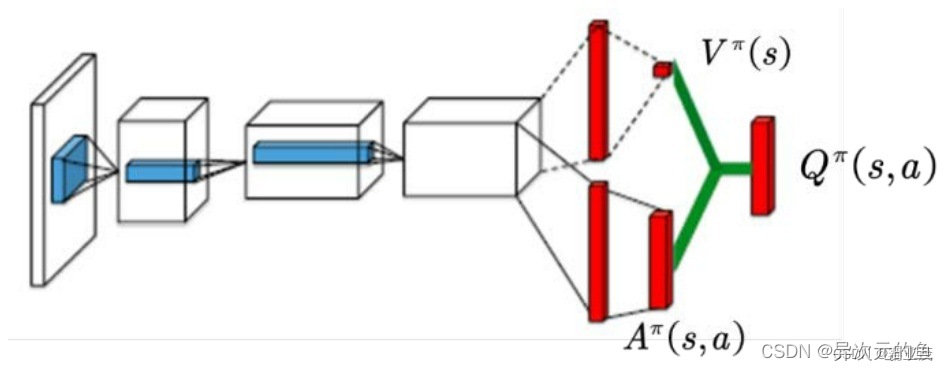
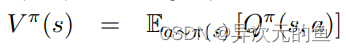
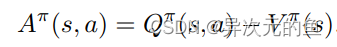
仔细想想这么拆分还是很有道理的。**V代表了在当前状态s下,Q值的平均期望(综合考虑了所有可选动作)。A代表了在选择动作a时Q值超出期望值的多少。两者相加就是实际的Q(s,a)。**就像当人看到某一游戏画面时是可以大概判断出当前局势的好坏,然后再根据每一种选择看哪一种action对当前局势增益最多。V就是当前局势,A就是对当前局势的增益。所以这样设计模型就是为了让神经网络对给定的s有一个基本的判断,在这个基础上再根据不同的action进行修正。
Dueling DQN伪代码
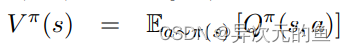
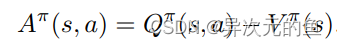
仔细想想这么拆分还是很有道理的。**V代表了在当前状态s下,Q值的平均期望(综合考虑了所有可选动作)。A代表了在选择动作a时Q值超出期望值的多少。两者相加就是实际的Q(s,a)。**就像当人看到某一游戏画面时是可以大概判断出当前局势的好坏,然后再根据每一种选择看哪一种action对当前局势增益最多。V就是当前局势,A就是对当前局势的增益。所以这样设计模型就是为了让神经网络对给定的s有一个基本的判断,在这个基础上再根据不同的action进行修正。

