- 1ES技术分享_es分享
- 2【正点原子STM32连载】 第四十八章 汉字显示实验 摘自【正点原子】APM32E103最小系统板使用指南
- 3Docker拉取jdk8镜像失败解决方案_docker pull java:8
- 4【CKA】考试之k8s版本升级_cka k8s版本升级
- 5基于LSTM搭建一个文本情感分类的深度学习模型:准确率往往有95%以上_情感分类精度如何提升
- 6PyCharm必备,7个实用插件助你事半功倍_pycharm插件
- 7Vue2基础(CDN方式)_vue2 cdn
- 8redhat7配置yum repos软件仓库&远程yum_loaded plugins: product-id, search-disabled-repos,
- 9基础|什么是张量、数据立体、矩阵、向量和纯数_三阶张量的矩阵表示
- 10计算机毕设项目 40个高质量SSM毕设项目分享【源码+论文】
深度学习中的优化器和学习率调整方法有哪些?_训练过程中优化器学习率怎么改变
赞
踩
嗨,各位深度学习探险家!今天我们将一起探讨深度学习中的优化器和学习率调整方法,它们是让模型“变强大”的秘密武器。让我们一起进入这神秘领域,揭开它们的奥秘!
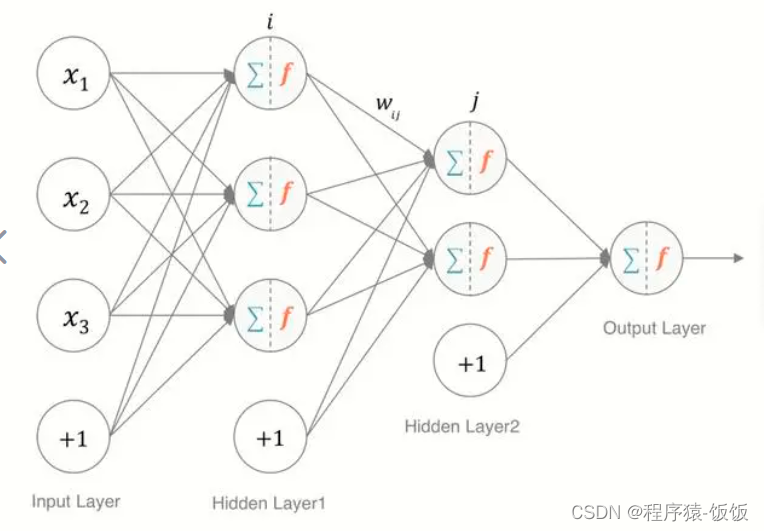
第一步:优化器
优化器是深度学习的“导航仪”,它负责调整模型的参数,使得模型能够朝着更好的方向前进。
-
随机梯度下降(SGD):这是最简单也是最经典的优化器。它在每次迭代中使用单个样本来计算梯度,并更新参数。虽然速度较快,但容易陷入局部最优点。
-
动量法(Momentum):动量法为SGD添加了一个“动量”,可以加速训练过程,避免陷入局部最优。
-
AdaGrad:AdaGrad对每个参数使用不同的学习率,根据历史梯度进行调整。它适用于处理稀疏梯度的问题。
-
RMSprop:RMSprop是AdaGrad的改进版本,通过衰减历史梯度的平方来避免学习率过小。
-
Adam:Adam结合了动量法和RMSprop的优点,被广泛应用于深度学习中。它具有快速收敛、适应性学习率等特点。
第二步:学习率调整方法
学习率是优化器的“风向标”,决定模型前进的速度和方向。但有时候学习率的选择不是那么容易。
-
固定学习率:最简单的方式就是固定学习率。但是对于复杂的模型和数据,固定学习率可能会导致训练不稳定或者陷入局部最优。
-
学习率衰减:学习率衰减是一种逐渐降低学习率的方法,通常随着训练的进行,学习率逐渐减小。常用的衰减策略有按固定步长衰减和按指数衰减等。
-
学习率预热:有时候在训练初期,学习率设置得太大会导致训练不稳定。学习率预热可以在训练的前几个epoch中逐渐增大学习率,让模型更快地找到全局最优。
-
学习率重启:学习率重启是周期性地重置学习率,以跳出局部最优,并让模型在不同的局部最优之间跳跃。


综上所述,优化器和学习率调整方法是深度学习中非常重要的一部分。选择合适的优化器和学习率调整方法,可以提高模型的训练效果,加快收敛速度,帮助模型在复杂的数据和任务中取得更好的表现。记住不同问题需要不同的优化器和学习率策略,多尝试多实践,相信你会找到最佳的组合!加油,你是最棒的!