
- 1注意力机制:pytorch实现_注意力机制pytorch
- 2【OpenCV + Python】ret, frame = cap.read()返回值含义&视频读取
- 3鸿蒙开发-UI-组件-状态管理_鸿蒙 状态管理
- 4pytorch基础数据类型--tensor
- 5量子计算的飞跃!澳研究团队发明新型光量子处理器
- 6展望2024: 中国AI算力能否引爆高性能计算和大模型训练的新革命?_硬件算力平台 2024
- 7#Linux(环境变量)
- 8微信小程序 getPhoneNumber获取用户手机号
- 9YOLOv5+PaddleOCR手写签名识别_yolov5 文字识别
- 10python调用opencv拍摄一张图片并保存到本地_hx, frame = cap.read()图片保存在哪里
如何在微软Edge浏览器上一键观看高清视频?_edge浏览器 hdr视频
赞
踩
编者按:视频是当下最流行的媒体形式之一。但由于视频压缩、网络不稳定等原因,我们常常可以看到互联网上的很多视频其画面质量并不理想,尤其是在浏览器端,这极大地影响了观看体验。不过,近期微软 Edge 浏览器推出了一项新功能,一键就可以让浏览器中的视频变为高清版。这项神奇功能背后的技术秘诀是什么?今天,让我们一起来了解一下微软 Edge 视频超分辨率功能的“秘密武器”——来自微软亚洲研究院的智能视频增强工具集 DaVinci 2.0。
近期,微软 Edge 浏览器推出了一项新功能——视频超分辨率(VSR)。用户只需在 Edge 浏览器中开启 VSR 功能,就能够在浏览器端观看高清视频。即使是几十年前的360P、480P老电影,或者在网络不稳定被迫降低视频画质的情况下,用户也可以时刻享受高清体验。
VSR 功能的背后是来自微软亚洲研究院的智能化视频增强工具集“达芬奇(DaVinci)”。该功能在不占用网络带宽的情况下即可在用户端实时消除视频压缩的伪影,提高视频分辨率,从而整体提升用户浏览视频的视觉体验。

微软 Edge 视频超分辨率示例。针对低于 720P 分辨率的视频,开启 Edge 中的视频超分辨率功能,视频质量有了明显提升。
现在,就跟着微软 Edge 的节奏,让视频高清起来吧!
第一步,打开微软 Edge 浏览器;第二步,单击 Edge 地址栏中的高清图标并选择增强视频的切换开关;第三步,播放视频,享受高清体验。(注:视频超分辨率由 Edge 自动启用,用户可自行决定启用或禁用该功能)
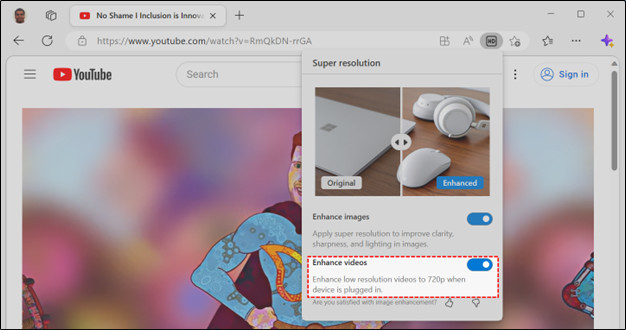
启用或禁用视频超分辨率功能的流程
*值得注意的是,受限于模型计算代价较高的限制,该功能目前仅针对具有相对高端显卡的台式机用户开放测试(需要 Edge Stable 版本不低于117,Edge Canary 版本不低于119)。同时,微软 Edge 团队也在不断努力,希望可以将该功能逐步开放给所有具有独立显卡、集成显卡的用户。
从特定视频域到开放域的挑战
据微软 Edge 团队调查,近四成用户曾表示在 Edge 浏览器观看视频时,网页上的视频质量较低,通常为 360P 或 480P,非常影响用户体验。为此,微软 Edge 团队希望与微软亚洲研究院开展合作,借助创新技术来提升 Edge 网页端所有低清视频的质量,给用户以高清体验。2022年微软亚洲研究院推出的智能视频增强工具集“达芬奇(DaVinci)”,能够实现视频超分辨率、视频插帧、压缩视频超分辨率等功能,很好的满足了微软 Edge 团队的需求。
DaVinci项目链接:https://github.com/microsoft/DaVinci
然而,在将 DaVinci 算法模型应用到产品的过程中存在着不小的挑战。DaVinci 1.0 主要是针对特定领域进行的训练,有明确的训练目标;特定领域的数据分布一致,所以模型的优化过程更加容易,优化的上限也更高;而且,高质量的垂直领域的数据更易于收集,可以获得大量公开的训练数据。但进入到 Edge 应用场景下的开放域(open domain),技术难度呈指数级增加。在开放域中,视频类别众多,视觉差异较大,比如用户在 Edge 中打开的可能是包含动物、植物、建筑、车辆等众多元素在内的影视、动画、视频会议等各种不确定类型的视频。要让一个模型补充不同类别视频的细节,是 DaVinci 首先要面对的难题。
与此同时,模型的容量是否足够大,可以支撑真实场景下的大量数据,并捕捉到不同的数据模式?如何定义开放域?开放域需要包含哪些特定领域的数据?评估指标是什么?这些都是 DaVinci 模型需要克服的问题。
更适合开放域视频的超分辨率算法
DaVinci 1.0 视频超分辨率模型的目的是在从低质量(LQ)或低分辨率的对应帧预测的高质量(HQ)帧的过程中来学习映射函数。然而,为了从高质量的训练数据集生成对应的低质量/低分辨率的视频帧,现有方法大多是使用预定义的算子(如,双三次下采样,bicubic down-sampling)来模拟退化过程,得到 LQ 输入。这就限制了模型在真实视频场景上的通用性,特别是对于具有高压缩率的视频流数据。所以在 DaVinci 2.0 的视频超分辨率技术中,微软亚洲研究院的研究员们将视频压缩也纳入到模型中,并通过运行具有不同压缩策略的几个流行视频编解码器来合成 LQ-HQ 视频对,以训练模型。
同时,受到大语言模型的启发,研究员还利用自监督的 LQ-HQ 复原范式(restoration paradigm),使用来自不同类别的15万个视频片段对模型进行了预训练。通过进一步考虑来自不同编码器的视频压缩伪影类型,使得 DaVinci 模型可以显著恢复具有大范围低质量的不同视频内容。
为了进一步提高模型的视觉质量,研究员们采用两阶段训练策略。其中,第一阶段旨在恢复结构信息(如,对象的边缘和边界),第二阶段则针对高频纹理(如,树叶和毛发),使用视觉感知和生成对抗性目标进行优化。
由于当前该领域中的现有指标,如 LPIPS(Learned Perceptual Image Patch Similarity, 学习感知图像块相似度)和 FVD(Fréchet Video Distance,弗雷歇视频距离)不能完全反映人类的视觉偏好,因此研究员们构建了一个端到端流水线(pipeline),用于视频增强任务的主观评估,以便更好地了解改进后的 DaVinci 模型性能,评估它在开放域视频场景中所发挥的作用。
具体而言,就是让参与者在十个类别中标注出他们对真实场景视频数据不同方法的偏好。参与者不仅要考虑每个视频帧的静态质量,还要考虑动态质量,这对于改善用户体验尤为重要。该流水线评估方法表明,相比于浏览器中默认的双线性放大,超过90%的用户更喜欢使用 DaVinci 2.0 模型来提升视频质量。
在微软亚洲研究院与微软 Edge 团队的通力合作下,Edge 浏览器的 VSR 功能基于 DaVinci 2.0 超分辨率模型,可以提升所有不确定内容类型的视频质量,并且在不产生伪影的情况下,提高视频清晰度,为 Edge 用户提供丝滑、高清的视频体验。
从视频超分辨率到视频生成
尽管 DaVinci 1.0 并没有涉及到如此大规模的低质量数据预训练,但 DaVinci 2.0 在 Edge 浏览器中的成功应用,证明了模型具有从低质量预训练到大规模高清数据应用的高泛化能力。这也进一步促进了微软亚洲研究院研究员们将创新技术应用到更多开放域场景的探索。
“DaVinci 2.0 对视频增强功能的创新,实现了对开放域视频图像细节的补充。基于视频帧间具有本质关联的特性,DaVinci 最终实现了高清结果。接下来,我们希望对技术进行更深入的探索,最终达到从0到1的创造,”微软亚洲研究院高级研究员傅建龙表示。
在以视频为主流媒介的大趋势下,微软亚洲研究院希望未来还可以给用户提供自动生成视频、创建个性化视频内容的工具。在全方位为用户提供极致的视频观看体验的同时,也帮助用户从事更复杂、更具创造力的内容创作工作。

