- 1上传图片和视频在JAVA上的运用_java 实现视频上传
- 2(关闭/开启)Mac系统中Google浏览器自动升级功能_macos 开启chrome自动更新
- 3FISCO BCOS区块链平台上的智能合约压力测试指南_对区块链网络节点完成压力测试
- 4【算法讲7:积性函数(下)】⌈ 加性函数 ⌋ 与 ⌈ 积性函数 ⌋ 与 ⌈ 狄利克雷卷积 ⌋ 详细介绍_证明刘维尔函数是完全积性函数
- 5MySQL是什么
- 6C# Winform Chart控件用法1
- 7鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:List)
- 8【linux 多线程并发】多线程的控制,挂起线程暂停运行,直到唤醒线程,取消线程运行,可以设置合适的取消点属性避免不安全点被中止_线程取消点
- 9Android自定义控件:刮刮乐控件的简单实现_安卓实现刮刮乐布局完整代码
- 10上手做一个华为鸿蒙手表应用 1 - 创建项目_华为watch4应用开发
已解决Python读取20GB超大文件内存溢出报错MemoryError_python读取大文件内存溢出
赞
踩
已解决Python读取20GB超大文件内存溢出报错MemoryError
报错问题
日常数据分析工作中,难免碰到数据量特别大的情况,动不动就2、3千万行,如果直接读进 Python 内存中,且不说内存够不够,读取的时间和后续的处理操作都很费劲。最近处理文本文档时(文件约20GB大小),出现memoryError错误和文件读取太慢的问题,报错代码如下:
with open(file, 'r', encoding='utf-8') as f:
json_list = f.readlines()
- 1
- 2
- 3
报错信息如下:
MemoryError
- 1
报错翻译
报错翻译如下:内存错误
报错原因
报错原因:
这种方式是将文件里面所有内容按行读取到一个大列表中,对于小文件,这种方式其实挺方便,但对于大文件就会出现内存可能不足的情况,报 MemoryError 错误,或者消耗掉很客观的内存资源。小伙伴按下面的方法解决任选其一即可!!!
解决方法1
pandas.read_csv参数chunksize通过指定一个分块大小(每次读取多少行)来读取大数据文件,可避免一次性读取内存不足,返回的是一个可迭代对象 TextFileReader
import pandas as pd
reader = pd.read_csv('E:\Python学习\新建文件夹\新建文本文档.txt', sep=',', chunksize=10)
for chunk in reader:
df = chunk
print(type(df), df.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
解决方法2(推荐使用)
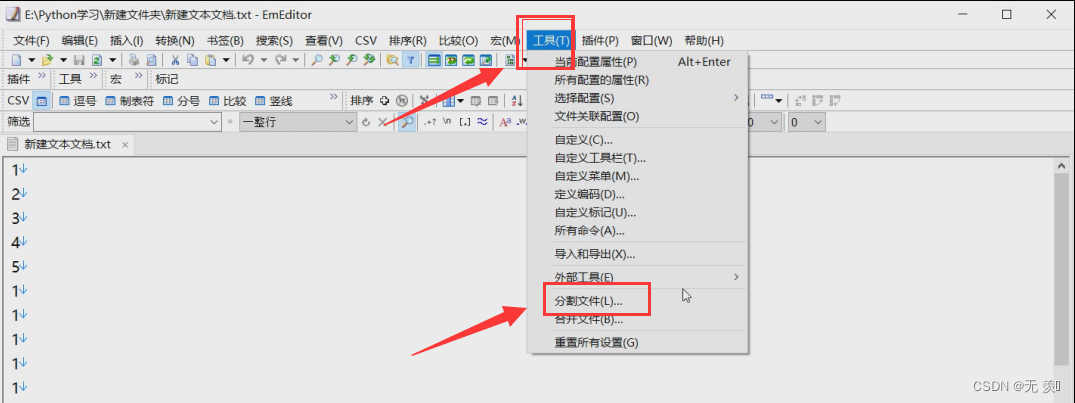
EmEditor介绍: 简单好用的文本编辑器,支持多种配置,自定义颜色、字体、工具栏、快捷键设置,可以调整行距,避免中文排列过于紧密,具有选择文本列块的功能(按ALT键拖动鼠标),并允许无限撤消、重做,总之功能多多,使用方便,是替代记事本的最佳编辑器。我使用的EmEditor的分割功能,将20G的json文件按行分割为10个小文件。
EmEditor下载地址:https://zh-cn.emeditor.com/#download
(1)安装完成后,找到工具 》 点击分割文件:
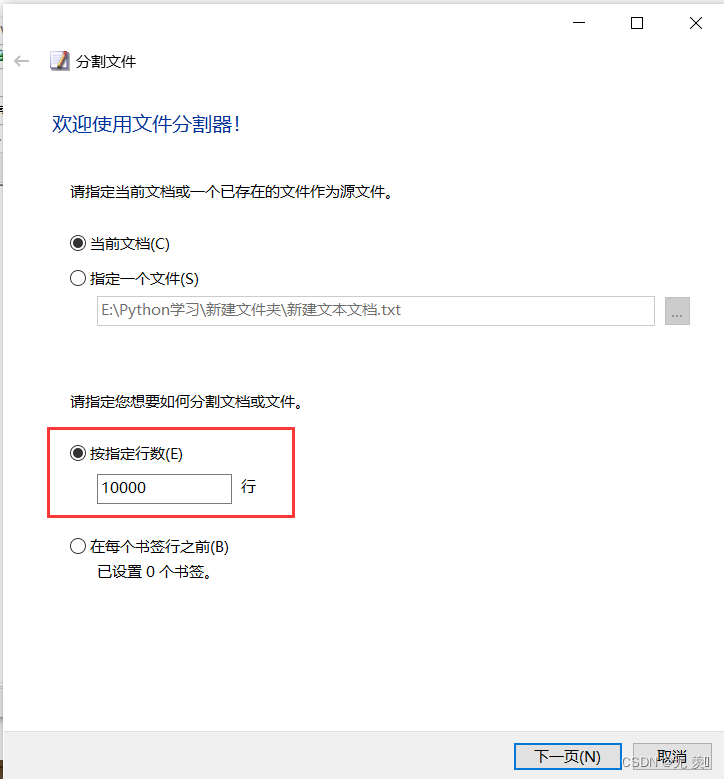
(2)指定分割的行数(以多少行分割成一个新文件),然后点击下一页:
(3)默认即可接着一直点击下一页:
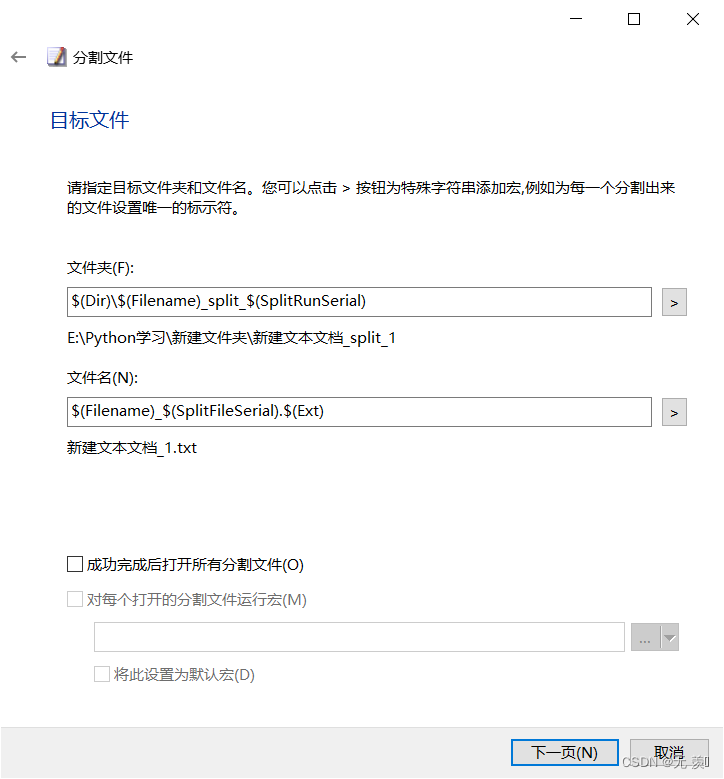
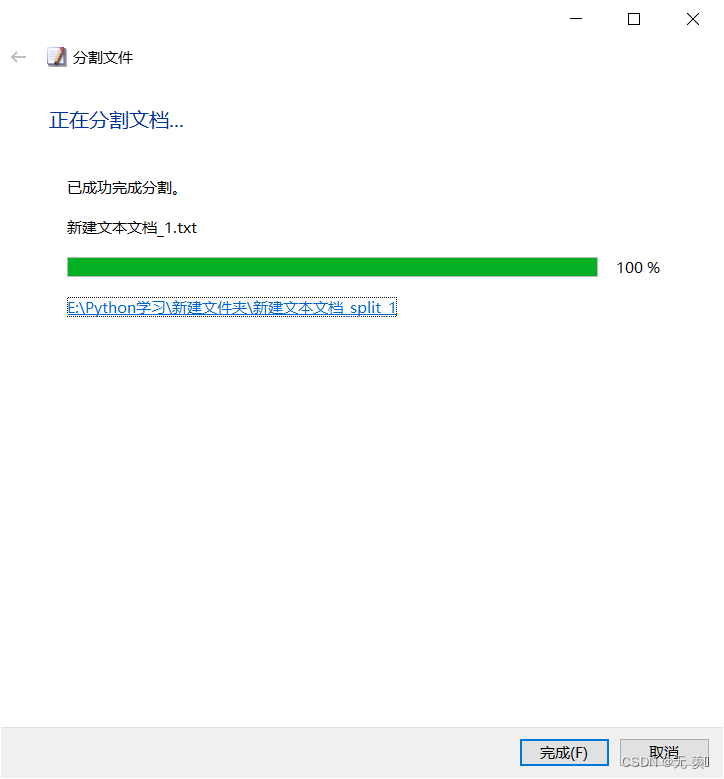
(4)分割完成,点击完成:
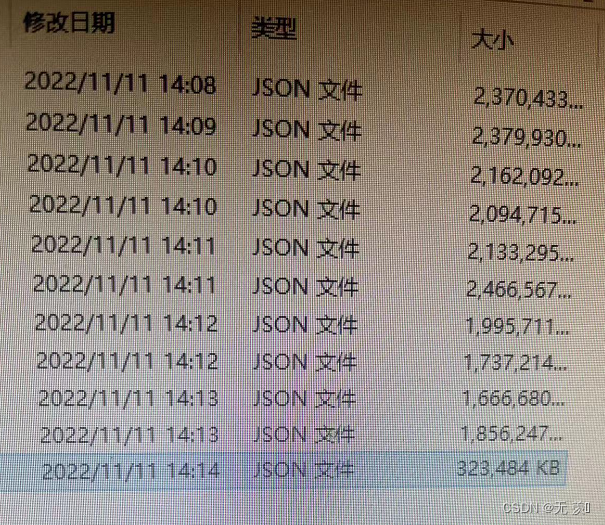
(5)找到对应的文件,把json文件分割为10小份(这个是写文章之前分割的):
以上是此问题报错原因的解决方法,欢迎评论区留言讨论是否能解决,如果有用欢迎点赞收藏文章谢谢支持,博主才有动力持续记录遇到的问题!!!
千人全栈VIP答疑群联系博主帮忙解决报错
由于博主时间精力有限,每天私信人数太多,没办法每个粉丝都及时回复,所以优先回复VIP粉丝,可以通过订阅限时9.9付费专栏《100天精通Python从入门到就业》进入千人全栈VIP答疑群,获得优先解答机会(代码指导、远程服务),白嫖80G学习资料大礼包,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
-
优点:作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会),此专栏文章是专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试!
-
专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等
-
注意:如果希望得到及时回复,和大佬们交流学习,订阅专栏后私信博主进千人VIP答疑群